NLP入门之综述阅读-基于深度学习的自然语言处理研究综述
NLP入门-综述阅读-【基于深度学习的自然语言处理研究综述】
- 基于深度学习的自然语言处理研究综述
-
- 摘要
- 0 引言
- 1 深度学习概述
-
- 卷积神经网络
- 递归神经网络
- 2 NLP应用研究进展
- 3 预训练语言模型
-
- BERT
- XLNet
- ERNIE
- 4 结束语
- 个人总结
基于深度学习的自然语言处理研究综述
2020年4月
罗枭-浙江农林大学信息工程学院
来源:智能计算机与应用-第10卷-第4期
摘要
摘要:自然语言处理的研究综述,重点介绍最新的预训练语言模型,以及总结与展望
关键词:深度学习;自然语言处理;深度神经网络;语言模型
0 引言
NLP:实现人机间通过自然语言交流,存在多义词、一词多义等问题
Deep Learning:具有强大的特征提取和学习能力,可以处理高维度稀疏数据
文章对当前深度学习在 NLP 领域的发展展开综述性讨论,详细阐述目前 NLP 的研究进展和最新的技术方法
1 深度学习概述
深度学习研究如何从数据中自动提取多层特征表示。其核心思想是通过数据驱动的方式,采用一系列的非线性变换,从原始数据中提取由底层到高层、由具体到抽象的特征。
例如:卷积神经网络CNN、递归神经网络RNN。
卷积神经网络
CNN是一种前馈神经网络,区别于其他神经网络模型,卷积运算操作赋予了CNN处理复杂图像和自然语言的特殊能力。
连接方式:局部连接和权值共享
由以下五部分组成:

1)输入层:通常是将单词或者句子表示成向量矩阵
2)卷积层:卷积层中的每一个节点输入是上一神经网络层的一部分,其目的是提取图片或者文本的不同特征
3)池化层:降低网络模型的输入维度,使神经网络具有更高的鲁棒性。常见的池化方式有最大池化和平均池化
4)全连接层:把高维转换成低维度,同时把有用的信息保留下来
5)输出层:完成分类或者预测任务
一般将学习到的高维度特征表示馈送到输出层,通 过 Softmax 函数可以计算出当前样本属于不同类别的概率。
递归神经网络
RNN具有树状层结构,网络节点按其连接顺序对输入信息进行递归的人工神经网络
RNN的基本结构包括输入层、隐藏层和输出层
与传统神经网络最大的区别在于 RNN 每次计算都会将前一词的输出结果送入下一词的隐藏层中一起训练,最后仅仅输出最后一个词的计算结果。
缺点:
1)对短期的记忆影响比较大,但对长期的记忆影响很小,无法处理很长的输入序列。
2)训练 RNN 需要极大的成本投入。
3)RNN 在反向传播时求底层的参数梯度会涉及到梯度连乘,容易出现梯度消失或者梯度爆炸。
长短时记忆网络LSTM和门控循环单元GRU在一定程度上可以解决该问题
2 NLP应用研究进展
语言建模、机器翻译、问答系统、情感分析、文本分类、阅读理解、中文分词、词性标注、命名实体
3 预训练语言模型
预训练思想的本质是模型参数不再随机初始化,而是通过语言模型进行训练。
目前 NLP 各项任务的解决思路是预训练加微调。
Word2Vec、Glove、ULMFiT、EMLo
当前最优秀的预训练语言模型是基于Transformer模型构建的。该模型是由 Vaswani 等人提出的,其是一种完全基于 Self-Attention 所构建的,是目前 NLP领域最优秀的特征提取器,不但可以并行运算而且可以捕获长距离特征依赖。
BERT
当前影响最大的预训练语言模型是基于Transformer 的双向深度语言模型—BERT。其网络结构如图所示:
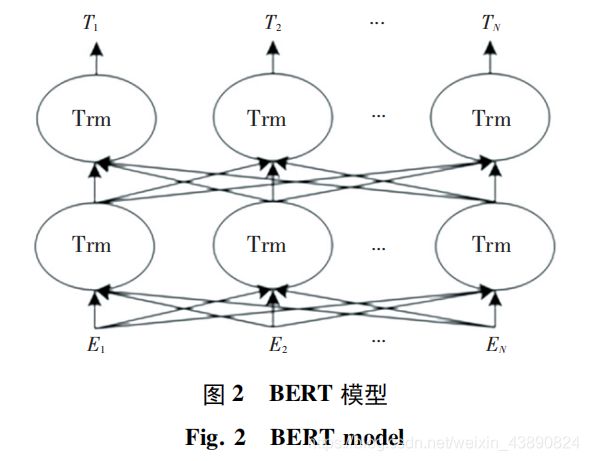
BERT是由多层双向Transformer解码器构成,主要包括2个不同大小的版本: 基础版本有12层Transformer,每个Transformer中的多头注意力层是12个,隐藏层大小为768; 加强版有24层Transformer,每个Transformer中的多头注意力层是24个,隐藏层大小为 1024。由此可见深而窄的模型效果要优于浅而宽的模型。目前 BERT 在机器翻译、文本分类、文本相似性、阅读理解等多个任务中都有优异的表现。BERT模型的训练方式包括2种:
1)采用遮盖单词的方式。将训练语料中的80%的单词用[MASK]替换,如 my dog is hairy—> my dog is [MASK]。还有 10%的单词进行随机替换,如 my dog is hairy—> my dog is banana。剩下10%则保持句子内容不变。
2)采用预测句子下一句的方式。将语料中的语句分为A和B,B中的 50%的句子是A中的下一句,另外的50%则是随机的句子。
通过上述2种方式训练得到通用语言模型,然后利用微调的方法进行下游任务,如文本分类、机器翻译等任务。较比以前的预训练模型,BERT 可以捕获真正意义上的双向上下文语义。
缺点:在训练模型时,使用大量的[MASK]会影响模型效果,而且每个批次只有 15%的标记被预测,因此 BERT 在训练时的收敛速度较慢。此外由于在预训练过程和生成过程不一致,导致在自然语言生成任务表现不佳,而且 BERT 无法完成文档级别的 NLP 任务,只适合于句子和段落级别的任务。
XLNet
XLNet是一种广义自回归的语言模型,是基于Transformer-XL而构建的。
Transformer的缺点:
- 字符之间的最大依赖距离受输入长度的限制。
- 对于输入文本长度超过 512 个字符时,每个段都是从头开始单独训练,因此使训练效率下降,影响模型性能。
针对以上2个缺点,Transformer-XL引入 了 2 个解决方法: 分割循环机制 ( Division Recurrence Mechanism) 和 相对位置编码 ( Relative Positional Encoding) 。Transformer -XL 的测试速度更快,可以捕获更长的上下文长度。
通过 XLNet训练得到语言模型后,可以用于下游相关任务,如阅读理解,基于 XLNet 得到的结果已经远超人类水平,在文本分类、机器翻译等任务中取得了优异的效果。
ERNIE
无论是 BERT 还是 XLNet 语言模型,在英文语料中表现都很优异,但在中文语料中效果一般, ERNIE则是以中文语料训练得出一种语言模型。 ERNIE 是一种知识增强语义表示模型,其在语言推断、语义相似度、命名实体识别、文本分类等多个NLP 中文任务上都有优异表现。ERNIE 在处理中文语料时,通过对预测汉字进行建模,可以学习到更大语义单元的完整语义表示。

模型结构主要包括 2 个模块,下层模块的文本编码器( T-Encoder) 主要负责捕获来自输入标记的基本词汇和句法信息,上层模块的知识编码器( K-Encoder) 负责从下层获取的知识信息集成到文本信息中,以便能够将标记和实体的异构信息表示成一个统一的特征空间中。
ERNIE 模型通过建立海量数据中的实体概念等先验语义知识,学习完整概念的语义表示,即在训练模型时采用遮盖单词的方式通过对词和实体概念等语义单词进行遮盖,使得模型对语义知识单元的表示更贴近真实世界。
总体来说,ERNIE 模型通过对实体概念知识的学习来学习真实世界的完整概念语义表示,使得模型对实体概念的学习和推理能力更胜一筹,其次通过对训练语料的扩充,尤其是引入了对话语料使得模型的语义表示能力更强。
4 结束语
本文主要对深度学习中的卷积神经网络和递归神经网络做了简单介绍,阐述了目前 NLP 领域各个任务的研究进展。当前 NLP 的研究重点是预训练语言模型,因此详细介绍 BERT、XLNet 和 ERNIR3种模型。
个人总结
感觉也就那样吧…
万事开头难!冲吧!上学人!
没有困难的工作,只有勇敢的狗勾!