文章来源 | 恒源云社区
原文地址 | 从零训练一个超越预训练的 NLP 模型
原文作者 | Mathor
欢迎欢迎,热烈欢迎
社区大佬回归啦~
我又可以愉快的搬运文章了!
都让开,我要开始搬运啦。正文开始:
\
本文基于Arxiv上的一篇论文NLP From Scratch Without Large-Scale Pretraining: A Simple and Efficient Framework,清华的几位研究者提出一种任务驱动的语言模型TLM(Task-driven Language Modeling)。不需要大规模的预训练,从零训练一个大模型也能取得SOTA的效果,源码在yaoxingcheng/TLM
INTRODUCTION
作者首先指出,从零开始对RoBERTa-Large进行预训练,需要\( 4.36\times 10^{21} \) FLOPs (Floating Point Operations Per second),大约相当于1000张拥有32G显存的V100显卡运行一天,而训练GPT-3的要求是RoBERTa-Large的50倍。一般的组织根本不可能有这么大的算力,我们顶多是拿别预训练好的模型在自己的下游任务上微调,整个过程称为Pretraining-Finetuning
TLM: TASK-DRIVEN LANGUAGE MODELING
论文中,作者提出一种替代Pretraining-Finetuning这种传统范式的方法,目的是效率更高、算力要求更低的同时几乎不损失性能。具体来说,TLM主要基于两个关键的想法:首先,人类掌握一项任务只需要世界上的一小部分知识(例如学生即便是为考试做准备,也只需要查看世界上所有书籍中某一本里的几个章节);其次,在有监督的标记数据上进行训练,比在无标记数据上优化语言模型更有效
基于上述动机,TLM使用任务数据作为Query,检索一般语料库中的一个小子集。随后,用检索到的数据和任务数据共同优化监督任务和语言建模任务(MLM)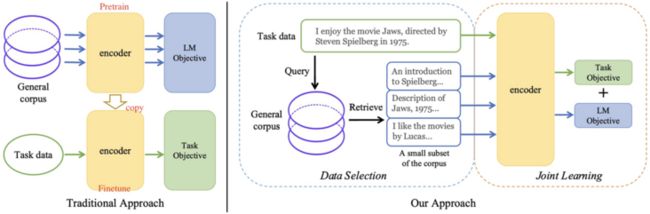
形式化地描述,给定一个通用的语料库\( \mathcal{D}={d_i}_i \),其中\( d_i \)是一篇文档;给定一系列有监督数据\( \mathcal{T}={(x_i, y_i}_i \),其中\( x_i \)是一条文本数据,\( y_i\in \mathcal{Y} \)是标签。我们的目标是训练一个模型\( f \)去估计分类的条件概率\( f(x)=\hat{p}(y\mid x) \)
作者提到,他们的方法是很容易扩展到所有NLP任务的,但是这里仅专注于分类任务
TLM主要由两个重要步骤组成:
- 将有监督数据(task data)作为查询,将通用语料库中的数据检索出来
- 对task data进行监督任务,对通用语料库中检索出来的数据进行语言建模任务。将这两个任务联合起来共同作为优化目标,从而达到从零训练一个模型的目的
Retrieve From General Corpus
这部分主要讲述究竟如何从通用语料库中检索(Retrieve)出数据。对于task data中的每个样本\( x_i\in \mathcal{T} \),我们利用BM25算法从语料库中检索出一系列文档\( S_i = {\tilde{d}_ {i,1},\tilde{d}_{i,2},…} \)。集合\( S_i \)中保存的是与样本\( x_i \)最接近的top-\( K \)个文档。对于每个task data,我们都可以找出一系列文档,最后将这些文档全部取并集\( S = \cup_iS_i \)。很明显,检索出的数据\( S \)仅是原始语料库\( \mathcal{D} \)中的一小部分
BM25算法是2009年提出的,由于年代太过久远,包括我也都是第一次听说,网上看了几篇博客之后发现其实并不复杂,因此顺便总结在此。具体来说,BM25是信息索引领域用来计算q句子与文档d之间的相似度得分的经典算法,它的公式如下:
其中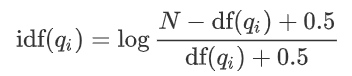
按照变量出现的顺序从前往后:
- \( q_i \)是句子\( q \)中的第\( i \)个单词
- \( \text{tf}(q_i,d) \)是单词\( q_i \)在文档\( d \)中出现的次数,即词频
- \( k _ 1 \) > \( 0 \)是一个超参数。一般取\( k_1=2 \)
- 0<\( b \)<1是另一个超参数,它是决定使用文档长度这个信息的比例,当\( b=1 \)时,文档长度这个信息就完全被用于权衡词的权重;当\( b=0 \)时,不使用文档长度这个信息。一般取\( b=0.75 \)
- \( |d| \)是文档\( d \)的的长度
- \( L_{\text{avg}} \)是所有文档的平均长度
- \( N \)是所有文档的数量
- \( \text{df}(q_i) \)表示包含了\( q_i \)这个单词的文档个数
这种检索算法是任务无关的(task free),因为它仅依赖于文本\( x \),而不依赖于标签\( y \)。此外,BM25检索算法也并不依赖于特定领域数据,一般的通用语料即可。基本的BM25算法就是如此,网上有很多对于BM25算法的变形,引入了更多超参数等,这里不过多赘述,有兴趣的读者自行查询学习即可
实际上如果是我来做相似度匹配的话,可能会用到连续的向量表示,然后通过计算向量的余弦相似度这种常规做法,不过作者也提到了,将一个文档或者一个句子准确的编码为同维度的向量是很困难的,除非使用基于神经网络的方法,不论是基础的Word2vec,还是基于BERT的模型。但这就违背了他们的初衷,他们希望整个过程要尽可能的简单、效率高,而且使用一个预训练好的BERT模型来提取向量,似乎有些作弊的感觉,因为他们的原意就是不使用预训练模型
Joint Training
给定内部和外部数据,我们使用如下损失函数从零训练一个语言模型\( f \)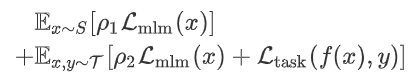
前面提到的监督任务即\( \mathcal{L} _ {\text{task}(f(x),y)} \),例如分类任务的交叉熵损失;语言建模任务即\( L_{mlm} (x) \),也就是masked language modeling loss
其中,\( \rho _1 \)和\( \rho_2 \)是两个超参数,并且从论文后面的超参数设置来看,\( \rho_1,\rho_2 \)非常大,至少是三位数级别的。模型\( f \)的网络架构与BERT相同,使用[CLS]位置的输出进行分类。当然了,TLM也适用于其他的模型架构以及非分类任务
如果只看上面的损失,实际上就是我们常见的多任务,但接下来才是重点,作者在训练的时候分了两个阶段。第一阶段,我们将one batch内部数据(task data)与\( \rho_1 \) batch外部数据交错进行小批量随机梯度下降,此时的任务是MLM;第二阶段,\( \rho_1,\rho_2 \)均被设置为0,很明显此时是在内部数据上做有监督任务
RESULT

从结果上来看这种方法简直是太强了,和BERT以及RoBERTa打得有来有回,浮点计算量、数据量以及模型的参数量都比BERT或RoBERTa小很多,最关键的是他们是预训练过的,而TLM是从零开始训练的
论文核心的思想就是人类要进行某种任务之前并不需要学习整个世界的知识,而只需要学些与这个特定任务相关的知识即可。感性上来说确实是有道理的,那么实际上究竟有没有用呢?下面的对比实验证明了这一点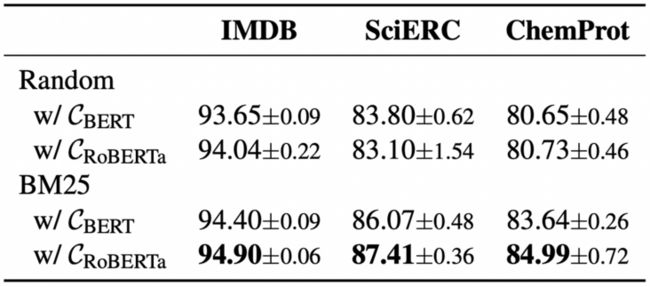
其中,\( \mathcal{C}_{BERT} \)和\( \mathcal{C}_ {RoBERTa} \)分别指的是BERT和RoBERTa当初预训练时所用的语料库,并且\( \mathcal{C}_ {RoBERTa} \)的大小是\( \mathcal{C}_{BERT} \)的十倍以上。作者分别采用Random和BM25的方式从\( \mathcal{C}_{BERT} \)和\( \mathcal{C}_ {RoBERTa} \)中检索数据,结果发现使用BM25这种有针对性的检索方法要比随机检索的效果好很多,同时因为\( \mathcal{C}_{\text{RoBERTa}} \)的数据量更大,所以检索到相似样本的可能性更大,因此它的效果在整个BM25中也是最好的。从上表我们还能看出低资源任务更依赖外部数据。IMDB是高资源任务,BM25算法比Random的提升大约只有1个点,而对于SciERC和ChemProt这种低资源任务,BM25算法比Random的提升大约有3~4个点
除此之外,top-\( K \)也是我特别关心的一个参数,下面便是作者做的一系列关于参数\( K \)的对比实验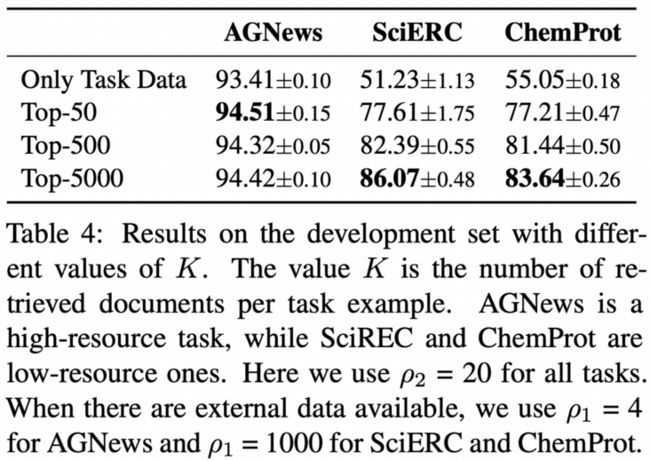
这个结果再次印证了,对于高资源的数据集,例如AGNews,实际上不需要特别多的外部资源,而对于低资源的数据集,需要很多的外部资源进行学习
BM25算法检索出来的文档真的与原样本非常相关吗?作者列了一张表展示了一部分结果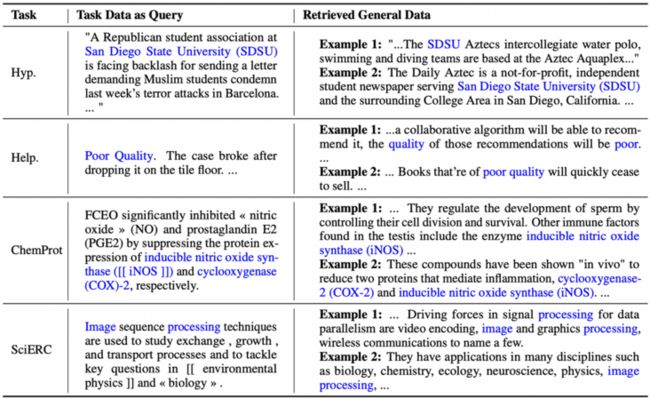
前面我提到\( \rho_1,\rho_2 \)非常大,那么到底该取多少呢?作者也做了相关的实验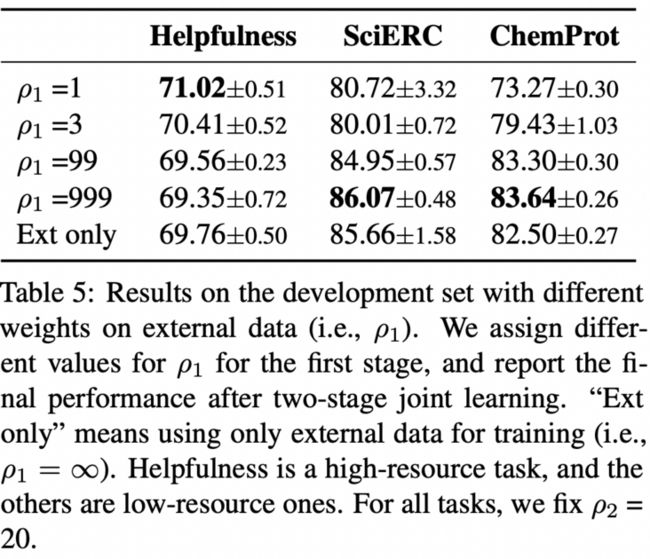
首先是\( \rho_1 \),这是控制外部数据进行MLM任务的超参数。作者发现对于高资源的数据集,例如Helpfulness,\( \rho_1 \)不需要设置的特别大,而对于低资源的数据集,\( \rho_1 \)应该要设置的稍微大一点。除此之外,如果移除内部数据,仅使用外部数据进行训练效果也不会太好,例如\( \rho_1 \approx \infty \)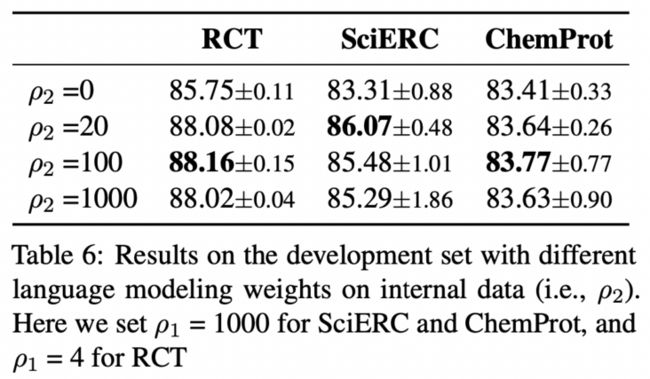
根据作者的研究(上图所示),\( \rho_2 \)设为20到1000之间的效果都还不错
我们知道TLM的训练过程是两阶段的,为了研究第二阶段(引入监督任务)对结果的影响,作者做了一个消融实验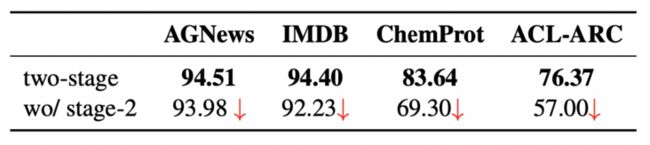
结果表明移除第二阶段训练会使得结果大幅下降,尤其是对于低资源数据集(ACL-ARC)来说更是如此
个人总结
整篇论文的思想简单,效果不俗,实验充分,目前只是挂在Arxiv上,不知道投了哪篇顶会,可能是年末的ACL吧。对于我的启发确实很多,相信大家也是如此。看完论文后我去关注了下作者的Github,后来发现原来作者是SimCES的二作,只能说很厉害了