A neural probabilistic language model(附完整源码)
I am a slow walker, but I never walk backwards.
我走得很慢, 但我从不后退。
------- 林肯
In this blog, we will discuss the paper “A neural probabilistic language model” published in 2003 which is a attempt to build a neural network to learn the joint probability function of sequences of words in a language.
In this paper, Bengio et al. proposed a neural network model which learns simultaneously a distributed representation for each word along with the probability function for word sequences, expressed in terms of these representations. Generalization is obtained because a sequence of words that has never been seen before gets high probability if it is made of words that are similar to words forming an already seen sentence.
Although training such a large model with millions of parameters within a reasonable time is itself a difficult challenge, it significantly improves the ability of statistical language model and achieved a state-of-the-art level.
This paper is divided into six main sections, and the overview is as follows:
- Introduction
- A Neural Model
- Parallel Implementation
- Experimental Results
- Extensions and Future Work
- Conclusion
The introduction section explains the fundamental problem called the curse of dimensionality which makes the language modeling training more difficult. Meanwhile, n-gram model is discussed concisely in this part and the basic formula is as follows:
P ^ ( w 1 T ) = ∏ t = 1 T P ^ ( w t ∣ w 1 t − 1 ) P ^ ( w t ∣ w 1 t − 1 ) ≈ P ^ ( w t ∣ w t − n + 1 t − 1 ) \hat{P}(w_1^T)=\prod_{t=1}^T\hat{P}(w_t|w_1^{t-1}) \\ \hat{P}(w_t|w_1^{t-1})\approx\hat{P}(w_t|w_{t-n+1}^{t-1}) P^(w1T)=t=1∏TP^(wt∣w1t−1)P^(wt∣w1t−1)≈P^(wt∣wt−n+1t−1)
The author is convinced that there is much more information in the sequence that immediately precedes the word to predict than just the identity of the previous couple of words and this model doesn’t take advantage of syntactic and semantic similarity between words.
Considering that words are discrete random variables, the proposed approach associates each word in the vocabulary with a distributed word feature vector (a real-valued vector in R m \mathbb{R}^m Rm) and expresses the joint probability function of word sequences in terms of the feature vectors of these words in the sequence. The objective of the proposed model called NNLM is to learn simultaneously the word feature vectors and the parameters of that probability function. The probability function is expressed as a product of conditional probabilities of the next word given the previous ones and its parameters can be tuned iteratively in order to maximize the log-likelihood of the training data using stochastic gradient ascent algorithm (in my experiment, I adopt SGD instead using Pytorch).
In the second part, the neural network architecture is illustrated in detail. Meanwhile, the formula of the model is as follows:
y = b + W x + U t a n h ( d + H x ) P ^ ( w t ∣ w t − 1 , . . . w t − n + 1 ) = e y w t ∑ i e y i y = b + Wx + Utanh(d + Hx) \\ \hat{P}(w_t|w_{t-1}, ...w_{t-n+1}) = \frac{e^{y_{w_t}}}{\sum_{i}e^{y_i}} y=b+Wx+Utanh(d+Hx)P^(wt∣wt−1,...wt−n+1)=∑ieyieywt
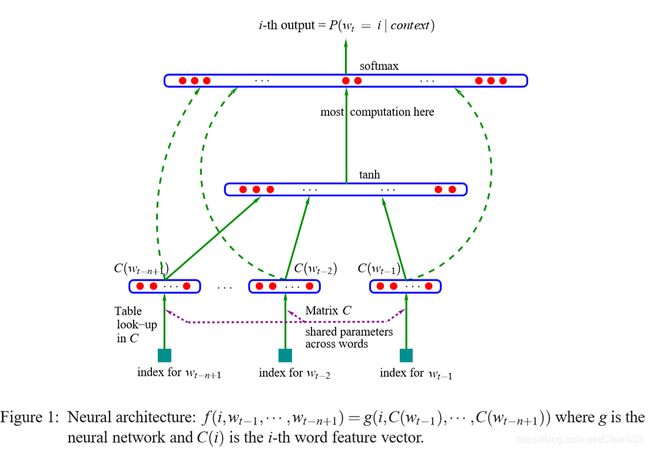
The y i y_i yi are the unnormalized log-probabilities for each output word i i i computed with parameters b b b, W W W, U U U, d d d and H H H.
Here is my implementation of the model:
# hyperparameters
m = 2 # dimension of word vector
n_step = 2 # num of preceding words
h = 10 # hidden size
# md
class NNLM(nn.Module):
def __init__(self):
super(NNLM, self).__init__()
self.C = nn.Embedding(V, m)
self.H = nn.Parameter(torch.randn(h, n_step * m), requires_grad=True)
self.d = nn.Parameter(torch.zeros(h), requires_grad=True)
self.W = nn.Parameter(torch.randn(V, n_step * m), requires_grad=True)
self.b = nn.Parameter(torch.zeros(V), requires_grad=True)
self.U = nn.Parameter(torch.randn(V, h), requires_grad=True)
def forward(self, input):
# input -> B x n_step
x = self.C(input).view(-1, n_step * m) # B x (n_step x m)
hidden_out = torch.tanh(x.matmul(self.H.transpose(0, 1)) + self.d) # B x h
output = x.matmul(self.W.transpose(0, 1)) + self.b + hidden_out.matmul(self.U.transpose(0, 1)) # B x V
return output
The number of free parameters is ∣ V ∣ ( 1 + n m + h ) + h ( 1 + ( n − 1 ) m ) |V|(1 + nm + h) + h(1 + (n-1)m) ∣V∣(1+nm+h)+h(1+(n−1)m). Obviously, the dominating factor is ∣ V ∣ ( n m + h ) |V|(nm + h) ∣V∣(nm+h). Note that if the vocabulary size, i. e. ∣ V ∣ |V| ∣V∣, is huge, the hidden-to-output computational cost will be extremely expensive which is significantly improved in the work of Mikolov et al.
Section 3 explores the parallel implementation of the model using CPU which is now replaced by GPU acceleration. Part 4 compares the neural network with an interpolated or smoothed trigram model and other state-of-the-art n-gram models: back-off n-gram models. The main result is that significantly better results can be obtained when using the neural network in comparison with the best of the n-grams. Section 5 describes extensions to the model described above, and directions for future work. In the last section, Bengio et al. said that they believed the main reason for these improvements is that the proposed approach allows to take advantage of the learned distributed representation to fight the curse of dimensionality with its own weapons: each training sentence informs the model about a combinatorial number of other sentences.
From my perspective, the greatest contribution of the work presented here is that it replaced “tables of conditional probabilities” by more compact and smoother representations based on distributed representation that can accommodate far more conditioning variables.
The complete code is shown as bellow:
import torch
import torch.nn as nn
import torch.optim as optimizer
import torch.utils.data as Data
sentences = ['i like cat', 'i love coffee', 'i hate milk']
sentences_list = " ".join(sentences).split() # ['i', 'like', 'cat', 'i', 'love'. 'coffee',...]
vocab = list(set(sentences_list))
word2idx = {w: i for i, w in enumerate(vocab)}
idx2word = {i: w for i, w in enumerate(vocab)}
V = len(vocab)
def make_data(sentences):
input_data = []
target_data = []
for sen in sentences:
sen = sen.split() # ['i', 'like', 'cat']
input_tmp = [word2idx[w] for w in sen[:-1]]
target_tmp = word2idx[sen[-1]]
input_data.append(input_tmp)
target_data.append(target_tmp)
return input_data, target_data
input_data, target_data = make_data(sentences)
input_data, target_data = torch.LongTensor(input_data), torch.LongTensor(target_data)
dataset = Data.TensorDataset(input_data, target_data)
loader = Data.DataLoader(dataset, 2, True)
# parameters
m = 2
n_step = 2
h = 10
class NNLM(nn.Module):
def __init__(self):
super(NNLM, self).__init__()
self.C = nn.Embedding(V, m)
self.H = nn.Parameter(torch.randn(h, n_step * m), requires_grad=True)
self.d = nn.Parameter(torch.zeros(h), requires_grad=True)
self.W = nn.Parameter(torch.randn(V, n_step * m), requires_grad=True)
self.b = nn.Parameter(torch.zeros(V), requires_grad=True)
self.U = nn.Parameter(torch.randn(V, h), requires_grad=True)
def forward(self, input):
# input -> B x n_step
x = self.C(input).view(-1, n_step * m) # B x (n_step x m)
hidden_out = torch.tanh(x.matmul(self.H.transpose(0, 1)) + self.d) # B x h
output = x.matmul(self.W.transpose(0, 1)) + self.b + hidden_out.matmul(self.U.transpose(0, 1)) # B x V
return output
model = NNLM().cuda()
optimizer = optimizer.Adam(model.parameters(), lr=1e-3)
criterion = nn.CrossEntropyLoss()
for epoch in range(1, 5000 + 1):
for batch_x, batch_y in loader:
optimizer.zero_grad()
# batch_x -> B x n_step
# batch_y -> B
batch_x = batch_x.cuda()
batch_y = batch_y.cuda()
pred = model(batch_x) # B x V
loss = criterion(pred, batch_y)
if epoch % 1000 == 0:
print("epoch:{}, loss:{}".format(epoch, loss.item()))
loss.backward()
optimizer.step()
pred = model(input_data.cuda()).max(1, keepdim=True)[1] # B x 1
print([idx2word[idx] for idx in pred])
print([idx2word[idx.item()] for idx in pred.squeeze()]) # ['cat', 'coffee', 'milk']