深度学习——贝叶斯神经网络
文章目录
- 前言
- 什么是贝叶斯神经网络
- How to train BNN
- BNN背后的数学原理
- pytorch实现BNN
- 参考文献
前言
本文将总结贝叶斯神经网络,首先,我将简单介绍一下什么是贝叶斯神经网络(BNN);接着我将介绍BNN是怎么训练的;然后我会介绍BNN背后的运作原理;最后,我将给出利用pytorch实现的BNN代码。
什么是贝叶斯神经网络
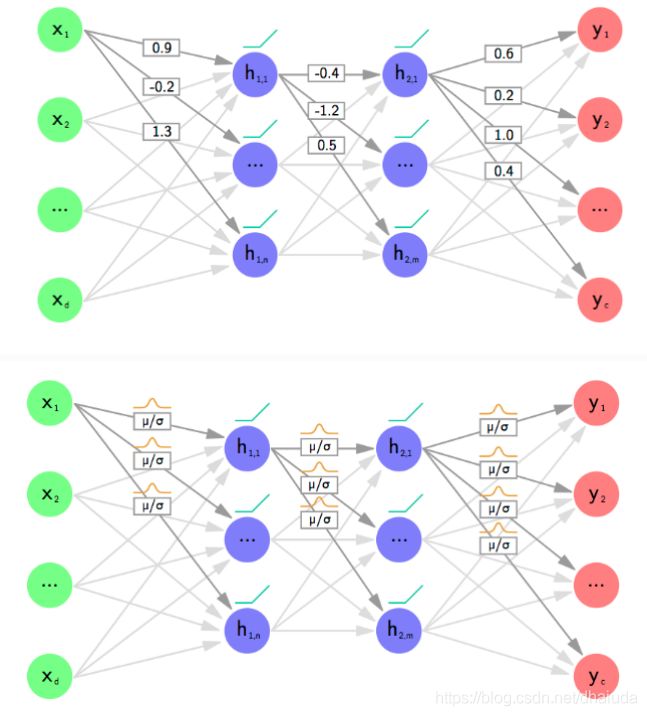
如上图,上半部分是反向传播网络,下半部分是贝叶斯神经网络。反向传播网络在优化完毕后,其权重是一个固定的值,而贝叶斯神经网络把权重看成是服从均值为 μ \mu μ,方差为 δ \delta δ的高斯分布,每个权重服从不同的高斯分布,反向传播网络优化的是权重,贝叶斯神经网络优化的是权重的均值和方差,所以贝叶斯神经网络需要优化的参数是反向传播网络的两倍。
在预测时,BNN会从每个高斯分布中进行采样,得到权重值,此时贝叶斯神经网络就相当于一个反向传播网络。也可以进行多次采样,从而得到多次预测结果,将多次预测结果进行平均,从而得到最终的预测结果(就像是ensemble模型)
How to train BNN
设训练集D为{ x i , y i x_i,y_i xi,yi}, 0 ≤ i ≤ N 0 \leq i \leq N 0≤i≤N,第 i i i个权重 w i w_i wi服从均值为 μ i \mu_i μi,方差为 δ i \delta_i δi的高斯分布, θ i \theta_i θi= { μ i , δ i } \{\mu_i,\delta_i\} {μi,δi},BNN的输出为 y p r e d y_{pred} ypred,BNN含有n个权重,则BNN的损失函数为
L ( x j ) = ∑ i = 1 n [ log q ( w i ∣ θ i ) − log p ( w i ) ] − log p ( y j ∣ W , x j ) log q ( w i ∣ θ i ) = log 1 2 π δ i − ( w i − μ i ) 2 2 δ i 2 log p ( w i ) = π ( log 1 2 π δ 1 − ( w i ) 2 2 δ 1 2 ) + ( 1 − π ) ( log 1 2 π δ 2 − ( w i ) 2 2 δ 2 2 ) log p ( y j ∣ W , x j ) = log 1 2 π δ − ( y j − y p r e d ) T δ − 1 ( y j − y p r e d ) ( 回 归 任 务 中 使 用 , 分 类 任 务 个 人 认 为 用 交 叉 熵 ) (1.0) \begin{aligned} L(x_j)&=\sum_{i=1}^n[\log q(w_i|\theta_i)-\log p(w_i)]-\log p(y_j|W,x_j)\\ \log q(w_i|\theta_i)&=\log \frac{1}{\sqrt{2\pi}\delta_i}-\frac{(w_i-\mu_i)^2}{2\delta_i^2}\\ \log p(w_i)&=\pi (\log \frac{1}{\sqrt{2\pi}\delta_1}-\frac{(w_i)^2}{2\delta_1^2})\\&+(1-\pi)(\log \frac{1}{\sqrt{2\pi}\delta_2}-\frac{(w_i)^2}{2\delta_2^2})\\ \log p(y_j|W,x_j)&=\log \frac{1}{\sqrt{2\pi}\delta}-(y_j-y_{pred})^T\delta^{-1}(y_j-y_{pred})\\&(回归任务中使用,分类任务个人认为用交叉熵)\tag{1.0} \end{aligned} L(xj)logq(wi∣θi)logp(wi)logp(yj∣W,xj)=i=1∑n[logq(wi∣θi)−logp(wi)]−logp(yj∣W,xj)=log2πδi1−2δi2(wi−μi)2=π(log2πδ11−2δ12(wi)2)+(1−π)(log2πδ21−2δ22(wi)2)=log2πδ1−(yj−ypred)Tδ−1(yj−ypred)(回归任务中使用,分类任务个人认为用交叉熵)(1.0)
BNN假设 q ( w i ∣ θ i ) q(w_i|\theta_i) q(wi∣θi), p ( w i ) p(w_i) p(wi), log p ( y j ∣ w , x j ) \log p(y_j|w,x_j) logp(yj∣w,xj)均服从高斯分布,由于中心极限定理的存在,这个假设是比较合理的。 δ 1 、 δ 2 、 δ 、 π \delta_1、\delta_2、\delta、\pi δ1、δ2、δ、π均为超参数,需要自己指定。
我们通过采样得到 w i w_i wi的具体值,从而计算1.0的各个式子。由于很难直接从 q ( w i ∣ θ i ) q(w_i|\theta_i) q(wi∣θi)采样,我们首先从标准正态分布中采样得到 ϵ i \epsilon_i ϵi,接着计算 μ i + ϵ i δ i \mu_i+\epsilon_i\delta_i μi+ϵiδi,从而得到服从 q ( w i ∣ θ i ) q(w_i|\theta_i) q(wi∣θi)分布的样本。
注意 L ( x j ) L(x_j) L(xj)是针对一个训练样本 { x i , y i } \{x_i,y_i\} {xi,yi}计算的,我们可以通过反向传播优化 θ i \theta_i θi,但是反向传播有可能使得方差 δ i \delta_i δi小于0,因此BNN对 δ i \delta_i δi进行了特殊处理,如下所示
δ i = log ( 1 + e ρ i ) \delta_i=\log(1+e^{\rho_i}) δi=log(1+eρi)
因此BNN的优化参数变为 θ i = { μ i , ρ i } \theta_i=\{\mu_i,\rho_i\} θi={μi,ρi}。
BNN背后的数学原理
神经网络用于建模分布 p ( Y ∣ X ) p(Y|X) p(Y∣X),即给定数据x,输出预测值y的分布,在分类任务中这个分布对应各个类别的概率;在回归任务中,一般认为是标准差固定的高斯分布,取均值作为预测结果。设训练集为 D D D,我们对 p ( Y ∣ X ) p(Y|X) p(Y∣X)进行如下变化
p ( Y ∣ X ) = ∫ p ( Y ∣ X , W ) p ( D ) p ( D ) d W = ∫ p ( Y ∣ X , W ) p ( W D ) p ( D ) d W = ∫ p ( Y ∣ X , W ) p ( W ∣ D ) d W = E p ( W ∣ D ) [ p ( Y ∣ X , W ) ] \begin{aligned} p(Y|X)&=\int p(Y|X,W)\frac{p(D)}{p(D)}dW\\ &=\int p(Y|X,W)\frac{p(WD)}{p(D)}dW\\ &=\int p(Y|X,W)p(W|D)dW\\ &=E_{p(W|D)}[p(Y|X,W)] \end{aligned} p(Y∣X)=∫p(Y∣X,W)p(D)p(D)dW=∫p(Y∣X,W)p(D)p(WD)dW=∫p(Y∣X,W)p(W∣D)dW=Ep(W∣D)[p(Y∣X,W)]
p ( Y ∣ X , W ) p(Y|X,W) p(Y∣X,W)表示给定权重 w w w和输入x,输出y的概率分布,其实就是神经网络。我们只需要依据训练集 D D D建模出权重的分布 p ( W ∣ D ) p(W|D) p(W∣D),就可以依据蒙特卡罗方法,采样m个服从 p ( W ∣ D ) p(W|D) p(W∣D)分布的样本,计算 1 m ∑ i = 1 m p ( Y ∣ X , W i ) \frac{1}{m}\sum_{i=1}^mp(Y|X,W_i) m1∑i=1mp(Y∣X,Wi),即可得到 p ( Y ∣ X ) p(Y|X) p(Y∣X)。
可是 p ( W ∣ D ) p(W|D) p(W∣D)往往难以计算,因此BNN使用变分估计,利用一个分布 q ( W ∣ θ ) q(W|\theta) q(W∣θ)来逼近 p ( W ∣ D ) p(W|D) p(W∣D),利用KL散度度量 q ( W ∣ θ ) q(W|\theta) q(W∣θ)、 p ( W ∣ D ) p(W|D) p(W∣D)两个分布之间的相似性,则有
K L ( q ( W ∣ θ ) ∣ ∣ p ( W ∣ D ) ) = ∫ q ( W ∣ θ ) log q ( W ∣ θ ) p ( W ∣ D ) d W = ∫ q ( W ∣ θ ) [ log q ( W ∣ θ ) − log p ( D ∣ W ) p ( W ) p ( D ) ] d W = ∫ q ( W ∣ θ ) [ log q ( W ∣ θ ) − log p ( D ∣ W ) − log p ( W ) + log p ( D ) ] d W = E q ( W ∣ θ ) [ log q ( W ∣ θ ) ] − E q ( w ∣ θ ) [ log q ( D ∣ W ) ] − E q ( W ∣ θ ) [ log q ( W ) ] + log p ( D ) \begin{aligned} KL(q(W|\theta)||p(W|D))&=\int q(W|\theta)\log\frac{q(W|\theta)}{p(W|D)}dW\\ &=\int q(W|\theta)[\log q(W|\theta)-\log \frac{p(D|W)p(W)}{p(D)}]dW\\ &=\int q(W|\theta)[\log q(W|\theta)-\log p(D|W)-\\&\log p(W)+\log p(D)]dW\\ &=E_{q(W|\theta)}[\log q(W|\theta)]-E_{q(w|\theta)}[\log q(D|W)]-\\&E_{q(W|\theta)}[\log q(W)]+\log p(D) \end{aligned} KL(q(W∣θ)∣∣p(W∣D))=∫q(W∣θ)logp(W∣D)q(W∣θ)dW=∫q(W∣θ)[logq(W∣θ)−logp(D)p(D∣W)p(W)]dW=∫q(W∣θ)[logq(W∣θ)−logp(D∣W)−logp(W)+logp(D)]dW=Eq(W∣θ)[logq(W∣θ)]−Eq(w∣θ)[logq(D∣W)]−Eq(W∣θ)[logq(W)]+logp(D)
由于 log p ( D ) \log p(D) logp(D)为已知分布,所以只需要最小化
E q ( W ∣ θ ) [ log q ( W ∣ θ ) ] − E q ( W ∣ θ ) [ log q ( D ∣ W ) ] − E q ( W ∣ θ ) [ log q ( W ) ] (2.0) E_{q(W|\theta)}[\log q(W|\theta)]-E_{q(W|\theta)}[\log q(D|W)]-E_{q(W|\theta)}[\log q(W)]\tag{2.0} Eq(W∣θ)[logq(W∣θ)]−Eq(W∣θ)[logq(D∣W)]−Eq(W∣θ)[logq(W)](2.0)
一般训练集由标签Y和数据X两部分组成,故有
E q ( W ∣ θ ) [ log q ( D ∣ W ) ] = E q ( W ∣ θ ) [ log q ( X , Y ∣ W ) ] = E q ( W ∣ θ ) [ log q ( W X Y ) q ( W ) ] = E q ( W ∣ θ ) [ log q ( Y ∣ W X ) p ( W X ) q ( W ) ] = E q ( W ∣ θ ) [ log q ( Y ∣ W X ) p ( W ) p ( X ) q ( W ) ] ( w 与 X 相 互 独 立 ) = E q ( W ∣ θ ) log q ( Y ∣ W , X ) ] + p ( X ) (3.0) \begin{aligned} E_{q(W|\theta)}[\log q(D|W)]&=E_{q(W|\theta)}[\log q(X,Y|W)]\\ &=E_{q(W|\theta)}[\log\frac{ q(WXY)}{q(W)}]\\ &=E_{q(W|\theta)}[\log\frac{q(Y|WX)p(WX)}{q(W)}]\\ &=E_{q(W|\theta)}[\log\frac{q(Y|WX)p(W)p(X)}{q(W)}](w与X相互独立)\\ &=E_{q(W|\theta)}\log q(Y|W,X)]+p(X)\tag{3.0} \end{aligned} Eq(W∣θ)[logq(D∣W)]=Eq(W∣θ)[logq(X,Y∣W)]=Eq(W∣θ)[logq(W)q(WXY)]=Eq(W∣θ)[logq(W)q(Y∣WX)p(WX)]=Eq(W∣θ)[logq(W)q(Y∣WX)p(W)p(X)](w与X相互独立)=Eq(W∣θ)logq(Y∣W,X)]+p(X)(3.0)
由于 p ( X ) p(X) p(X)为一个已知分布,将3.0代入2.0,优化目标变为
E q ( W ∣ θ ) [ log q ( W ∣ θ ) ] − E q ( W ∣ θ ) [ log q ( Y ∣ W , X ) ] − E q ( W ∣ θ ) [ log q ( W ) ] (4.0) E_{q(W|\theta)}[\log q(W|\theta)]-E_{q(W|\theta)}[\log q(Y|W,X)]-E_{q(W|\theta)}[\log q(W)]\tag{4.0} Eq(W∣θ)[logq(W∣θ)]−Eq(W∣θ)[logq(Y∣W,X)]−Eq(W∣θ)[logq(W)](4.0)
给定一个训练数据 { x j , y j } \{x_j,y_j\} {xj,yj},对4.0使用蒙特卡罗法则可得
∑ i = 1 m log q ( W i ∣ θ ) − ∑ i = 1 m log q ( y j ∣ W i , x j ) − ∑ i = 1 m log q ( W i ) (5.0) \sum_{i=1}^m\log q(W_i|\theta)-\sum_{i=1}^m\log q(y_j|W_i,x_j)-\sum_{i=1}^m\log q(W_i)\tag{5.0} i=1∑mlogq(Wi∣θ)−i=1∑mlogq(yj∣Wi,xj)−i=1∑mlogq(Wi)(5.0)
假设5.0的m=1,BNN含有n个权重,第i个权重为 w i w_i wi,第i个权重的高斯分布参数为 θ i = { μ i , δ i } \theta_i=\{\mu_i,\delta_i\} θi={μi,δi},则有
log q ( W ∣ θ ) = log q ( w 1 w 2 . . . w n ∣ θ 1 θ 2 . . . θ n ) = log q ( w 1 w 2 . . . w n θ 1 θ 2 . . . θ n ) q ( θ 1 θ 2 . . . θ n ) = log q ( w 1 θ 1 ) q ( w 2 θ 2 ) . . . . q ( w n θ n ) q ( θ 1 θ 2 . . . θ n ) ( w i θ i 之 间 相 互 独 立 ) = log q ( w 1 θ 1 ) q ( w 2 θ 2 ) . . . . q ( w n θ n ) q ( θ 1 ) q ( θ 2 ) . . . q ( θ n ) ( θ i 之 间 相 互 独 立 ) = ∑ i = 1 n log q ( w i ∣ θ i ) (6.0) \begin{aligned} \log q(W|\theta)=&\log q(w_1w_2...w_n|\theta_1\theta_2...\theta_n)\\&=\log \frac{q(w_1w_2...w_n\theta_1\theta_2...\theta_n)}{q(\theta_1\theta_2...\theta_n)}\\ &=\log\frac{q(w_1\theta_1)q(w_2\theta_2)....q(w_n\theta_n)}{q(\theta_1\theta_2...\theta_n)}(w_i\theta_i之间相互独立)\\ &=\log\frac{q(w_1\theta_1)q(w_2\theta_2)....q(w_n\theta_n)}{q(\theta_1)q(\theta_2)...q(\theta_n)}(\theta_i之间相互独立)\\ &=\sum_{i=1}^n\log q(w_i|\theta_i)\tag{6.0} \end{aligned} logq(W∣θ)=logq(w1w2...wn∣θ1θ2...θn)=logq(θ1θ2...θn)q(w1w2...wnθ1θ2...θn)=logq(θ1θ2...θn)q(w1θ1)q(w2θ2)....q(wnθn)(wiθi之间相互独立)=logq(θ1)q(θ2)...q(θn)q(w1θ1)q(w2θ2)....q(wnθn)(θi之间相互独立)=i=1∑nlogq(wi∣θi)(6.0)
由于 w i w_i wi相互独立,则有
log q ( W ) = ∑ i = 1 n log q ( w i ) (7.0) \log q(W)=\sum_{i=1}^n\log q(w_i)\tag{7.0} logq(W)=i=1∑nlogq(wi)(7.0)
在m=1的情况下,将式6.0、7.0代入4.0可得
∑ i = 1 n [ log q ( w i ∣ θ i ) − log p ( w i ) ] − log p ( y j ∣ W , x j ) (8.0) \sum_{i=1}^n[\log q(w_i|\theta_i)-\log p(w_i)]-\log p(y_j|W,x_j)\tag{8.0} i=1∑n[logq(wi∣θi)−logp(wi)]−logp(yj∣W,xj)(8.0)
8.0即1.0,至此,BNN的损失函数推导完毕,剩下一个采样问题,W服从 p ( W ∣ θ ) p(W|\theta) p(W∣θ)分布,由于每个权重都服从一个高斯分布,且各个权重之间相互独立,所以 p ( W ∣ θ ) p(W|\theta) p(W∣θ)是一个独立多元正态分布,独立多元正态分布由多个正态分布相乘得到,将各个正态分布中采样得到的样本点组合在一起得到的样本点将服从独立多元正态分布,所以采样时,权重 w i w_i wi的样本点只需从 q ( w i ∣ θ i ) q(w_i|\theta_i) q(wi∣θi)采样即可(写程序时可以直接从独立多元正态分布中采样,这里如此表述只是为了方便理解)。
pytorch实现BNN
本节实现的BNN为一个单隐藏层神经网络,其输入大小为1,输出大小为1。用于拟合函数 − x 4 + 3 x 2 + 1 -x^4 + 3x^2 + 1 −x4+3x2+1进行回归预测
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Normal
import numpy as np
# BNN层,类似于BP网络的Linear层,与BP网络类似,一层BNN层由weight和bias组成,weight和bias都具有均值和方差
class Linear_BBB(nn.Module):
"""
Layer of our BNN.
"""
def __init__(self, input_features, output_features, prior_var=1.):
"""
Initialization of our layer : our prior is a normal distribution
centered in 0 and of variance 20.
"""
# initialize layers
super().__init__()
# set input and output dimensions
self.input_features = input_features
self.output_features = output_features
# initialize mu and rho parameters for the weights of the layer
self.w_mu = nn.Parameter(torch.zeros(output_features, input_features))
self.w_rho = nn.Parameter(torch.zeros(output_features, input_features))
#initialize mu and rho parameters for the layer's bias
self.b_mu = nn.Parameter(torch.zeros(output_features))
self.b_rho = nn.Parameter(torch.zeros(output_features))
#initialize weight samples (these will be calculated whenever the layer makes a prediction)
self.w = None
self.b = None
# initialize prior distribution for all of the weights and biases
self.prior = torch.distributions.Normal(0,prior_var)
def forward(self, input):
"""
Optimization process
"""
# sample weights
# 从标准正态分布中采样权重
w_epsilon = Normal(0,1).sample(self.w_mu.shape)
# 获得服从均值为mu,方差为delta的正态分布的样本
self.w = self.w_mu + torch.log(1+torch.exp(self.w_rho)) * w_epsilon
# sample bias
# 与sample weights同理
b_epsilon = Normal(0,1).sample(self.b_mu.shape)
self.b = self.b_mu + torch.log(1+torch.exp(self.b_rho)) * b_epsilon
# record log prior by evaluating log pdf of prior at sampled weight and bias
# 计算log p(w),用于后续计算loss
w_log_prior = self.prior.log_prob(self.w)
b_log_prior = self.prior.log_prob(self.b)
self.log_prior = torch.sum(w_log_prior) + torch.sum(b_log_prior)
# record log variational posterior by evaluating log pdf of normal distribution defined by parameters with respect at the sampled values
# 计算 log p(w|\theta),用于后续计算loss
self.w_post = Normal(self.w_mu.data, torch.log(1+torch.exp(self.w_rho)))
self.b_post = Normal(self.b_mu.data, torch.log(1+torch.exp(self.b_rho)))
self.log_post = self.w_post.log_prob(self.w).sum() + self.b_post.log_prob(self.b).sum()
# 权重确定后,和BP网络层一样使用
return F.linear(input, self.w, self.b)
class MLP_BBB(nn.Module):
def __init__(self, hidden_units, noise_tol=.1, prior_var=1.):
# initialize the network like you would with a standard multilayer perceptron, but using the BBB layer
super().__init__()
# 输入为1,输出为1,只含有一层隐藏层的BNN
self.hidden = Linear_BBB(1,hidden_units, prior_var=prior_var)
self.out = Linear_BBB(hidden_units, 1, prior_var=prior_var)
self.noise_tol = noise_tol # we will use the noise tolerance to calculate our likelihood
def forward(self, x):
# again, this is equivalent to a standard multilayer perceptron
# 激活函数选用sigmoid
x = torch.sigmoid(self.hidden(x))
x = self.out(x)
return x
def log_prior(self):
# calculate the log prior over all the layers
return self.hidden.log_prior + self.out.log_prior
def log_post(self):
# calculate the log posterior over all the layers
return self.hidden.log_post + self.out.log_post
# 计算loss
def sample_elbo(self, input, target, samples):
# we calculate the negative elbo, which will be our loss function
#initialize tensors
outputs = torch.zeros(samples, target.shape[0])
log_priors = torch.zeros(samples)
log_posts = torch.zeros(samples)
log_likes = torch.zeros(samples)
# make predictions and calculate prior, posterior, and likelihood for a given number of samples
# 蒙特卡罗近似
for i in range(samples):
outputs[i] = self(input).reshape(-1) # make predictions
log_priors[i] = self.log_prior() # get log prior
log_posts[i] = self.log_post() # get log variational posterior
log_likes[i] = Normal(outputs[i], self.noise_tol).log_prob(target.reshape(-1)).sum() # calculate the log likelihood
# calculate monte carlo estimate of prior posterior and likelihood
log_prior = log_priors.mean()
log_post = log_posts.mean()
log_like = log_likes.mean()
# calculate the negative elbo (which is our loss function)
loss = log_post - log_prior - log_like
return loss
def toy_function(x):
return -x**4 + 3*x**2 + 1
# toy dataset we can start with
x = torch.tensor([-2, -1.8, -1, 1, 1.8, 2]).reshape(-1,1)
y = toy_function(x)
net = MLP_BBB(32, prior_var=10)
optimizer = optim.Adam(net.parameters(), lr=.1)
epochs = 2000
for epoch in range(epochs): # loop over the dataset multiple times
optimizer.zero_grad()
# forward + backward + optimize
loss = net.sample_elbo(x, y, 1)
loss.backward()
optimizer.step()
if epoch % 10 == 0:
print('epoch: {}/{}'.format(epoch+1,epochs))
print('Loss:', loss.item())
print('Finished Training')
samples = 100
x_tmp = torch.linspace(-5,5,100).reshape(-1,1)
y_samp = np.zeros((samples,100))
for s in range(samples):
y_tmp = net(x_tmp).detach().numpy()
y_samp[s] = y_tmp.reshape(-1)
print("test result:",np.mean(y_samp, axis = 0))
参考文献
1、独立多元高斯分布
2、Variational inference in Bayesian neural networks
3、贝叶斯神经网络 BNN
4、浅析贝叶斯神经网络(Based on Variational Bayesian)
5、Bayesian Neural Networks:贝叶斯神经网络
如果您想了解更多有关深度学习、机器学习基础知识,或是java开发、大数据相关的知识,欢迎关注我们的公众号,我将在公众号上不定期更新深度学习、机器学习相关的基础知识,分享深度学习中有趣文章的阅读笔记。
如果您对增量学习感兴趣,欢迎关注我们的公众号,我将不定期在公众号上更新增量学习文章相关的阅读笔记
