ICCV2021 | TransFER:使用Transformer学习关系感知的面部表情表征
前言
人脸表情识别(FER)在计算机视觉领域受到越来越多的关注。本文介绍了一篇在人脸表情识别方向上使用Transformer来学习关系感知的ICCV2021论文,论文提出了一个TransFER模型,在几个FER基准数据集上取得了SOTA性能。
本文来自公众号CV技术指南的论文分享系列
关注公众号CV技术指南 ,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读。

Background
在过去的几十年里,面部表情识别(FER)在计算机视觉研究领域受到了越来越多的关注,因为它对于让计算机理解人类的情感并与人类进行交互具有重要意义。
尽管FER最近取得了很好的性能,但它仍然是一个具有挑战性的任务,主要原因有两个:
1)类间相似度很大。来自不同类的表达式可能只表现出一些细微的差异。如图1所示,惊讶(第1排)和愤怒(第2排)的嘴巴相似。区分它们的关键线索在于眼睛和眼睛之间的区域;

2)类内小的相似性。属于同一类别的表情可能会有截然不同的外观,不同的种族、性别、年龄和文化背景会有所不同。
现有的研究成果可以分为两类:基于全局的方法和基于局部的方法。
针对基于全局的方法,人们提出了许多损失函数来增强特征的表示能力。然而,由于这些方法使用的是全局人脸图像作为输入,它们可能会忽略一些在区分不同表情类别中起重要作用的关键人脸区域。
为了解决这一问题,人们提出了许多基于局部的方法来学习人脸不同部位的区分特征,这些方法可以分为两类:基于标志点的方法和基于注意力的方法。
一些方法在landmarks周围裁剪的面部部位提取特征。然而,有几个问题:
1)预先定义的面部作物可能不能灵活地描述局部细节,因为不同的图像可能会有所不同。这是因为人脸的重要部位可能会出现在不同的位置,特别是对于姿势变化或视点变化的人脸;
2)对于受各种挑战性因素影响的人脸,例如强烈的光照变化、较大的姿势变化和严重的遮挡,人脸标志点检测可能不准确甚至失败。因此,有必要捕捉面部重要部位,抑制无用部位。
创新思路
为了解决Background中的问题,一些方法应用了注意力机制。然而,他们可能对相似的面部部位有多余的反应,而忽略了在FER中起重要作用的其他潜在的区别性部位。这个问题对于遮挡或姿势变化较大的面部尤其严重,因为有些面部部位是看不见的。
因此,需要提取不同的局部表征来对不同的表情进行分类。即使某些局部块(patches)不可见,更多样化的局部块也可以发挥作用。同时,不同的局部块可以相互补充。
例如,如图所示,仅根据嘴巴区域(列2)很难区分惊讶(第1行)和愤怒(第2行)。我们提出的TransFER模型探索了不同的关系感知面部部位,如眼睛(第3列,第1行)和眉毛之间的区域(第3列,第2行),这有助于区分这些不同的表情。
因此,应该在全局范围内探索不同局部块(patches)之间的关系,突出重要的块(patches),抑制无用的块(patches)。
为了实现上述两个目标,论文提出了TransFER模型来学习不同关系感知的FER局部表示。
首先,提出了随机丢弃注意力图的多注意丢弃算法(Multi-Attention Dropping, MAD)。通过这种方式,推动模型去探索除最具区分性的局部斑块之外的综合局部斑块,自适应地聚焦于不同的局部斑块。当某些部位因姿势变化或遮挡而不可见时,此方式特别有用。
其次,Vision Transformer(VIT)适用于FER,称为VIT-FER,用于对多个局部块之间的连接进行建模。由于采用全局范围对每个局部块进行增强,充分挖掘了多个局部块之间的互补性,提高了识别性能。
第三,多头自我注意(multi-head self-attention)使VIT能够在不同位置共同关注来自不同信息子空间的特征。然而,由于没有明确的指导,可能会建立冗余关系。为解决这一问题,提出了随机丢弃一个自我注意的多头自我注意丢弃(Multi-head Self-Attention Dropping, MSAD)方法。在这种情况下,如果放弃了self-attention,模型就被迫从其他地方学习有用的关系。因此,不同局部块之间的丰富关系被挖掘出来,从而使FER受益。
结合新的MAD和MSAD模块,提出了最终的体系结构,称为TransFER。如图所示,与VIT-FER基线(列2)相比,TransFER定位更多样化的关系局部表示(列3),从而区分这些不同的表达式。它在几个FER基准上达到了SOTA性能,显示了它的有效性。
Contribution
1.应用VIT自适应地刻画面部不同部位之间的关系,称为VIT-FER,展示了VIT-FER对FER的有效性。这是探索Transformers并研究关系感知(relation-aware)的局部块对FER的重要性的第一次努力。
2.引入多头自注意丢弃算法(MSAD),随机删除自我注意模块,迫使模型学习不同局部块之间的丰富关系。
3.设计了一种多注意丢弃算法(MAD)来消除注意图,推动模型从最具区分度之外的每个面部部位提取全面的局部信息。
4.在几个具有挑战性的数据集上的实验结果表明了提出的TransFER模型的有效性和实用性。
TransFER
TransFER的总体架构如图所示,它主要由茎(stem) CNN、局部CNN和多头自我注意丢弃(MSAD)组成。茎CNN用于提取特征图。这里采用IR-50,因为它具有很好的通用性。
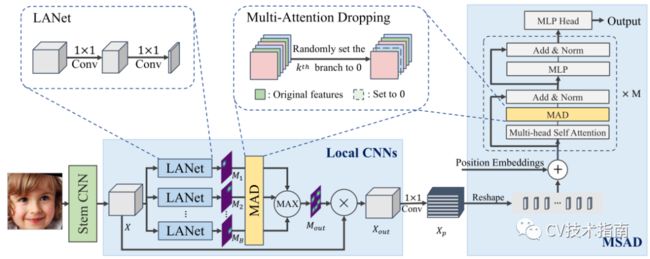
Local CNN
如前所述,在给定面部图像的情况下,首先使用茎CNN来提取特征图。然后,利用多空间注意力自动捕获局部块。然而,如果没有适当的指导,不能保证全面的辨别性面部部位被定位。如果模型只关注少数有区别的面部部分,当这些部分难以识别或完全遮挡时,FER会受到性能下降的影响,特别是对于姿势变化较大或遮挡较强的人脸。为了解决这一问题,开发了局部CNN来提取由MAD引导的各种局部特征。框架如上图所示,主要由三个步骤组成,具体如下。
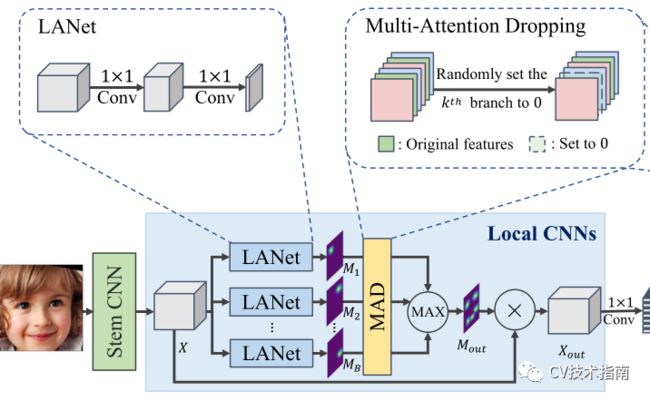
首先,生成多注意力图。X∈R(h×w×c)表示输入特征图,其中h、w和c分别表示特征图的高度、宽度和数量。由于LANet允许模型自动定位重要的面部部位,因此它在多个局部分支中使用,如上图所示。LANet由两个1×1卷积层组成。第一层1x1卷积输出c/r特征图,其中缩减率用于降低特征图的维数,后继的RELU层用于增强非线性。第二层将特征图数目减少到1,并通过Sigmoid函数(记为ASMI)生成关注图。假设存在B个LANet分支,则生成注意图[M1,M2,...,MB],其中Mi∈R(h×w×1)。
其次,MAD迫使多个局部分支探索不同的有用面部部位。一般来说,它接受几个数据分支作为输入,并通过将此分支中的值设置为零(不更改输入形状)随机删除一个分支。因此,MAD将注意力图作为输入,随机将一个注意力图设置为零,并输出注意力图。第三,将多个注意力图聚合在一起,生成一个注意力图。具体地说,使用基于元素的最大值操作来聚合多个关注图。
最后,将Mout与原始特征图X逐元素相乘。因此,原始特征图中的不重要区域被抑制,反之亦然。
Multi-Attention Dropping
Dropout是为了防止神经网络过拟合而提出的。它将特征向量或特征地图调整为输入。在训练过程中,输入的一些元素被随机设置为零,概率为来自伯努利分布的样本。如果有多个通道,则每个通道将独立归零。
受此启发,针对FER任务提出了一种类似丢弃的操作,称为多注意丢弃。与标准Dropout算法相比,本文提出的MAD算法采用一组特征映射(或向量)作为输入,并将每个特征映射作为一个整体来处理。
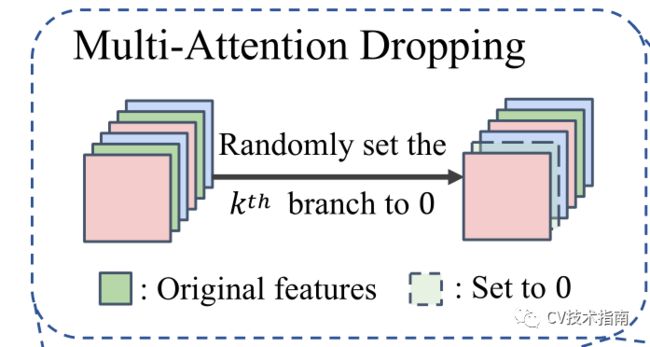
如图所示,在训练过程中,从完全设置为零的均匀分布中选择一个特征图。根据概率p执行丢弃操作。删除的特征图将不会在以下图层中激活。因此,这是一种类似丢弃的停止梯度操作,该操作可以引导局部CNN探索不同的、具有区分性的面部部位。因此,可以定位均匀分布的面部部位,从而产生有利于FER的全面的局部表示。
Multi-head Self-Attention Dropping
多头自注意丢弃(MSAD)主要由一个在每个多头自我注意模块后面注入MAD的transformer encoder和一个MLP分类头组成,就像vision transformer(VIT)那样。
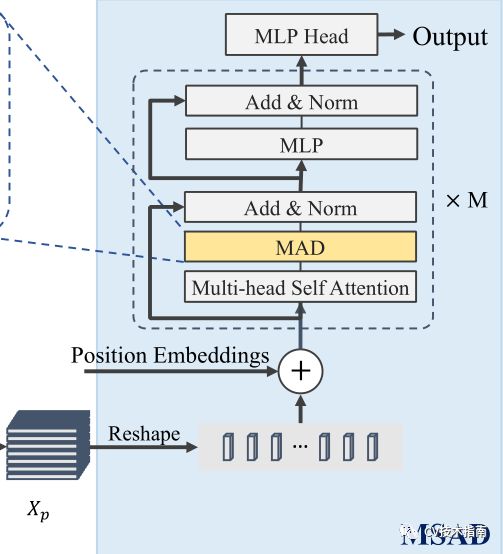
经过局部CNN后,生成包含不同局部块信息的特征图Xout ∈ R(h×w×c)。为了捕捉多个局部块之间的丰富关系,使用了包含M个编码块的Transformer。由图所示,由于此处除了在Multi-head Self Attention后添加了MAD模块以外, Transformer Encoder的结构基本没变,因此这里不多介绍。
Conclusion
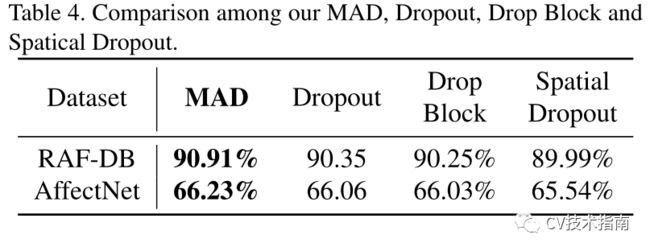
MAD与Dropout、Drop Block、Spatial Dropout的比较
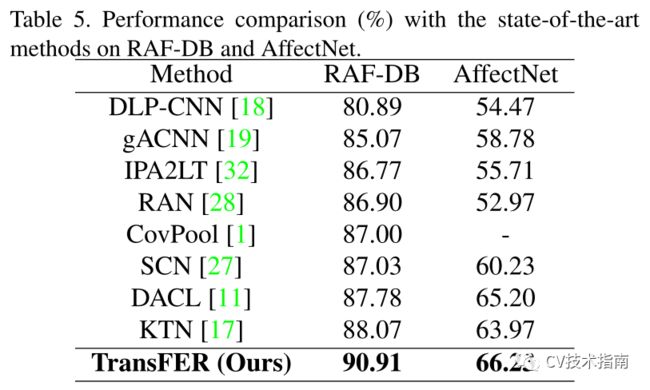
TransFER与其它SOTA模型的比较
注意可视化在来自AffectNet数据集的一些示例面部图像上的不同表情。
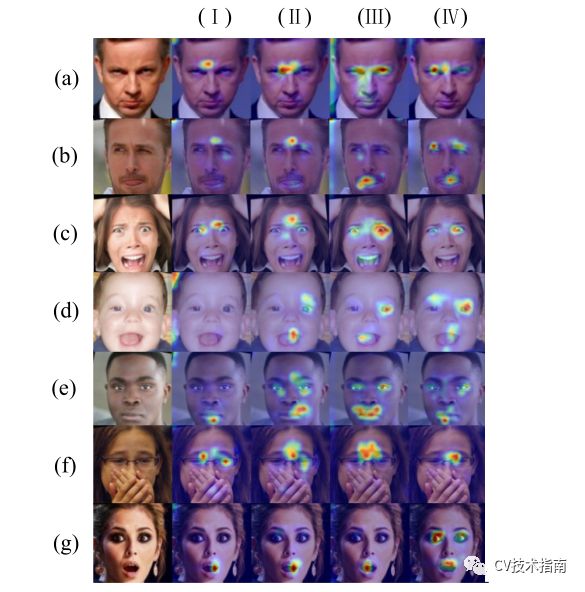
(A)-(G)分别表示愤怒、厌恶、恐惧、快乐、中性、悲伤和惊讶。(I)-(Iv)表示表1中的四种训练策略,(I)表示基准策略,(Ii)表示使用局部CNN而不使用MAD进行训练,(Iii)表示使用局部CNN和MAD进行训练,以及(Iv)表示TransFER,使用局部CNN和MSAD进行训练。在应用MAD和MSAD之后,整个框架可以专注于更具区分性的面部区域。
欢迎关注公众号 CV技术指南 ,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读。
在公众号中回复关键字 “技术总结”可获取公众号原创技术总结文章的汇总pdf。

其它文章
2021-视频监控中的多目标跟踪综述
统一视角理解目标检测算法:最新进展分析与总结
NeurIPS 2021 | LoveDA:面向遥感语义分割与迁移学习的新开源数据集
图像修复必读的 10 篇论文 | Anchor-free目标检测论文汇总
给模型加入先验知识的常见方法总结 | 谈CV领域审稿
全面理解目标检测中的anchor | 实例分割综述总结综合整理版
小目标检测的一些问题,思路和方案 | 小目标检测常用方法总结
HOG和SIFT图像特征提取简述 | OpenCV高性能计算基础介绍
CVPR2021 | SETR: 使用 Transformer 从序列到序列的角度重新思考语义分割
经典论文系列 | 缩小Anchor-based和Anchor-free检测之间差距的方法:自适应训练样本选择
目标检测中回归损失函数总结
深度学习模型大小与模型推理速度的探讨
视频目标检测与图像目标检测的区别
CV算法工程师的一年工作经验与感悟
单阶段实例分割综述 | 语义分割综述 | 多标签分类概述
视频理解综述:动作识别、时序动作定位、视频Embedding
资源分享 | SAHI:超大图片中对小目标检测的切片辅助超推理库
从CVPR 2021的论文看计算机视觉的现状
2021年小目标检测最新研究综述
如何使用 TensorFlow 量化神经网络
Siamese network总结 | 计算机视觉入门路线
Batch Size对神经网络训练的影响
论文创新的常见思路总结 | 卷积神经网络压缩方法总结