【论文阅读】Deep multi-path convolutional neural network joint with salient region attention for facial。。。
论文阅读笔记
- 引言
-
- 网络结构
-
- 实验结果
引言
引言部分其实没说什么,就提了一句:如果我们用权重去衡量 “每个patch” 或 “某些区域”在表情识别任务中的重要性的话会更好。比如微笑表情其实和嘴角区域的关系更大,可以给这个区域赋予更高的权重;额头区域在微笑表情的判别任务中似乎没有太重要,所以可以给这个区域赋予更低的权重。
网络结构
网络结构分为3部分:VGG- Face、SERD、MPVS-Net。
首先上两个网络整体图
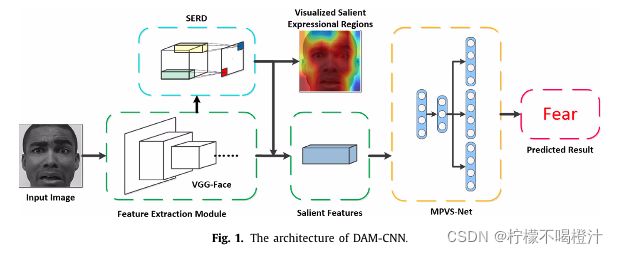
接下来介绍每个部分的功能:
(1)VGG- Face:16层卷积层、5个池化层、三个全连接层。本文用微调后的VGG- face作为主干网络来提取特征,特征输出维度为512 * 7 * 7
(2)SERD:先上图,结合图来介绍
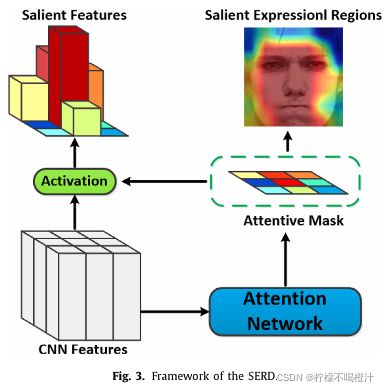
SERD接收VGG- Face输出的特征图作为输入,然后生成一张权重掩膜,说白了就是用一层卷积层(对!SERD只是一层卷积操作!)卷积VGG- Face的输出,然后再用tanh(*)激活函数激活一下下。
注意1:此处用的是1 * 1卷积,原文是这么说的:1 * 1卷积可以让掩膜里每个位置上的元素都能代表其在原特征图中对应位置元素的重要性(毕竟空间上的位置关系一一对应嘛)。
注意2:因为用的是tanh(*)激活函数,所以SERD的输出权重都在(-1,1)之间,作者认为权值为负的都代表冗余特征,应该丢弃;权值为正的都代表与表情相关的特征,应该保留。
![]()
那是咋丢弃、咋保留的呢?接下来看好
作者先将SERD输出的权重掩膜M与VGG-Face的输出相乘,得到加权后的特征图,然后用ReLu激活加权后的特征图,(对! 就是强行把小于零的值 “舍弃” )
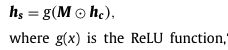
作者还设计了一个正则Loss函数来约束掩膜中的权值分布,第一项让掩膜更加稀疏,第二项让掩膜给与表情相关的区域分配更高的权值,作者后面做了实验证明这个Loss是真的有用。

然后作者将VGG - face与SERD相结合,构成VGG - SERD模型,并训练VGG - SERD模型以让其适应表情识别任务,训练过程中用到了两个Loss函数,一个是交叉熵损失,另一个是刚刚上面提到的正则Loss函数。

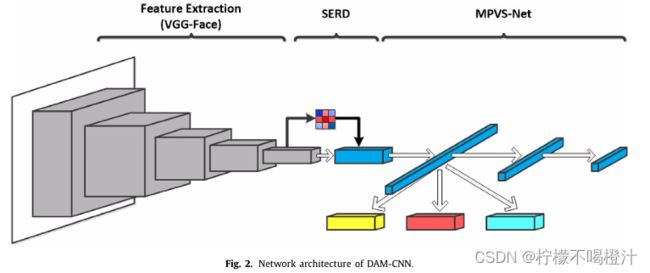
(3)MPVS-Net
通过(2)中的VGG- SERD模块处理后,其实网络已经学会丢弃一些冗余特征了,但是,由于每个人的身份、肤色、性别等属性的不同,VGG- SERD模块依旧会包含一些多样的信息。这里说的多样是指:即使是同一个表情,VGG- SERD模块也会提取出不同的特征向量,这就导致即使是同一个表情也会有误判的情况出现,因为代表这种表情的特征种类太多了,网络学不全。比如绯红女巫的笑和我的笑就很不同,她笑的比我好看,肤色还比我白,虽然我俩都笑,但是区别很大,这种表情的表现差异跟身份有关。
所以MPVS-Net的目的是让网络学习到深层次的泛化特征,具体一点,就是说不管你输入哪个人种、性别、肤色的人的微笑,网络都能识别正确,因为网络已经学到了微笑的超级无敌精髓特征,这种特征能够代表各式各样的微笑(不同身份、肤色、性别的微笑)。
MPVS-Net由三部分组成:Multi-Path-Autoencoder(MAPE)以及两层全连接层。
文章将上述VGG - SERD模型的全连接层替换成MPVS-Net,这样构成的网络名字叫DAM- CNN。
MPVS-Net最重要的就是MPAE,它的结构如下图所示:
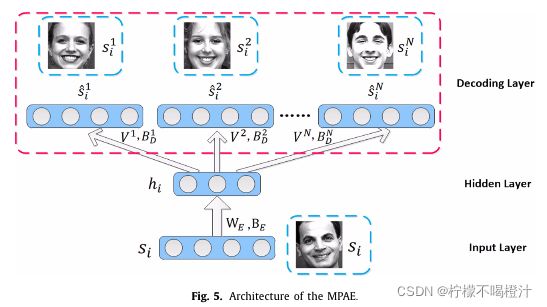
MPAE共包含三层:输入层、编码层和多头解码层。
这部分的目的,通俗来讲,就是比如说,输入一张小红的笑脸,通过编码和解码后,可以重构出小黑、小华、小丽的笑脸。输入输出有一个共性:都是一样的表情类别;输入输出有一个不同之处:虽然是同一类表情,但是表达形式不一样。
通过这样的编码和解码,作者希望编码器能够学到适应各种变体的高级特征,MPAE的具体实现步骤如下公式所示(我认为这里他用的都是全连接层,图里画的也像全连接层):

目标重构数据是随机从训练集里抽出来的,重构数据的好坏用L2范数来评价,即下式:

MPAE的总体损失如下式,其实就是把各个头的损失加起来。
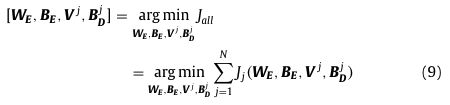
作者还做了个实验验证他VGG- SERD和MPAE确实有效。
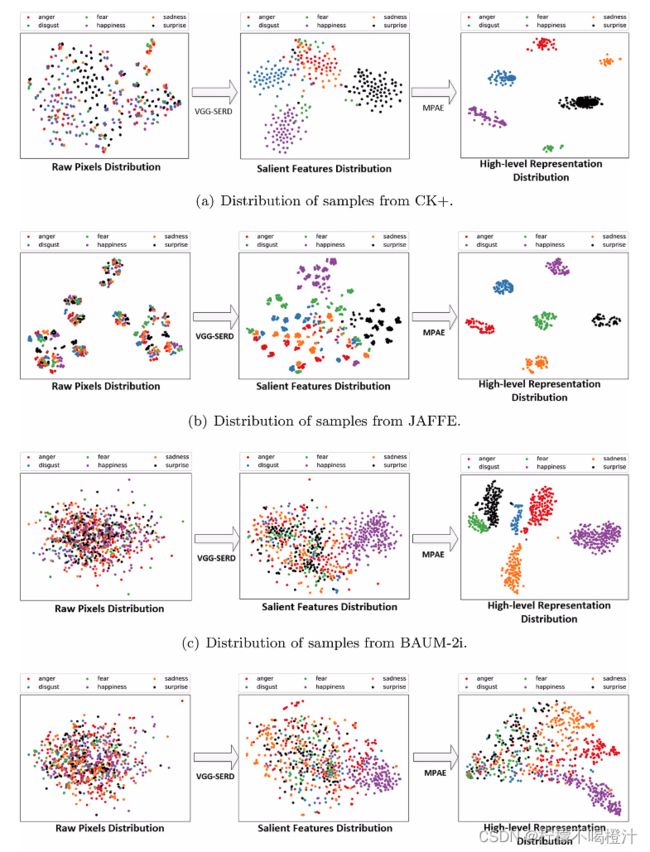
经过训练后,其实MPAE的编码层已经学会提取高级特征了,这时候在编码层的后面连接两个全连接层就可以对表情进行分类,也就是网络总结构图中画的那样啦。MPAE的编码层后连接两个全连接层的结构,作者命名为MPVS-net。
MPAE和两个全连接层的更新策略不同,两个全连接层只接收最后的表情分类损失:
MPAE接收多头编解码损失,以及最后的表情分类损失:

最后附上DAM-CNN的训练策略:两阶段训练。第一阶段:用表情图像微调VGG-SERD,直到VGG-SERD的loss收敛(VGG-SERD的loss往上翻,在上面写了)。第二阶段:去掉VGG-SERD的全连接层,接上MPVS-Net,构成DAM-CNN,当训练MPVS-Net时,VGG-SERD的参数是处于冻结状态的,在第一阶段训练VGG-SERD时,就会获得Si和Sj(也就是编码的输入,解码的target),先存起来就可以用来训练MPAE了,当MPVS-Net收敛时,第二阶段训练结束。

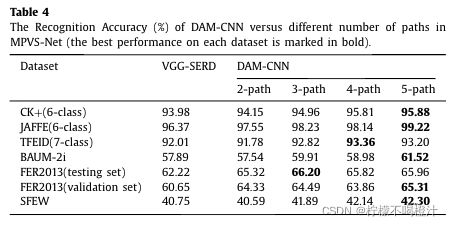
实验结果
感觉结果一般呀。。。