大话操作系统(13)锁
文章目录
- 互斥锁与⾃旋锁
- 读写锁
- 乐观锁与悲观锁
-
- 总结
- 死锁
-
- 死锁的概念
- 避免死锁问题的发⽣
- 总结
互斥锁与⾃旋锁
最底层的两种就是会「互斥锁和⾃旋锁」,有很多⾼级的锁都是基于它们实现的,你可以认为它们是各种锁的地基,所以我们必须清楚它俩之间的区别和应⽤。
加锁的⽬的就是保证共享资源在任意时间⾥,只有⼀个线程访问,这样就可以避免多线程导致共享数据错乱的问题。
当已经有⼀个线程加锁后,其他线程加锁则就会失败,互斥锁和⾃旋锁对于加锁失败后的处理⽅式是不⼀样的:互斥锁加锁失败后,线程会释放 CPU ,给其他线程;⾃旋锁加锁失败后,线程会忙等待,直到它拿到锁;互斥锁是⼀种「独占锁」,⽐如当线程 A 加锁成功后,此时互斥锁已经被线程 A 独占了,只要线程 A 没有释放⼿中的锁,线程 B 加锁就会失败,于是就会释放 CPU 让给其他线程,既然线程 B 释放掉了 CPU,⾃然线程 B 加锁的代码就会被阻塞。
对于互斥锁加锁失败⽽阻塞的现象,是由操作系统内核实现的。当加锁失败时,内核会将线程置为「睡眠」状态,等到锁被释放后,内核会在合适的时机唤醒线程,当这个线程成功获取到锁后,于是就可以继续执⾏。如下图:
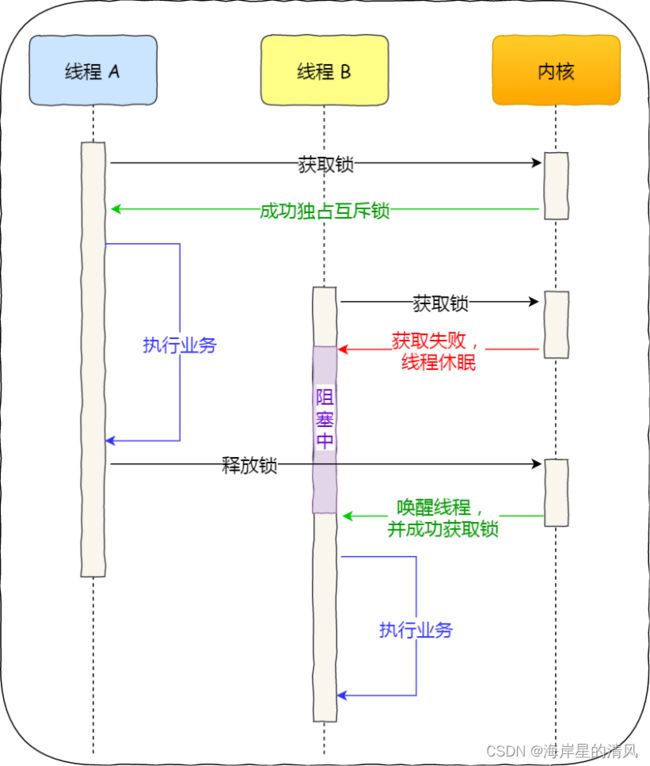
所以,互斥锁加锁失败时,会从⽤户态陷⼊到内核态,让内核帮我们切换线程,虽然简化了使⽤锁的难度,但是存在⼀定的性能开销成本。
那这个开销成本是什么呢?会有两次线程上下⽂切换的成本:
当线程加锁失败时,内核会把线程的状态从「运⾏」状态设置为「睡眠」状态,然后把 CPU 切换给其他线程运⾏;
接着,当锁被释放时,之前「睡眠」状态的线程会变为「就绪」状态,然后内核会在合适的时间,把CPU 切换给该线程运⾏。
线程的上下⽂切换的是什么?当两个线程是属于同⼀个进程,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据、寄存器等不共享的数据。
上下切换的耗时有⼤佬统计过,⼤概在⼏⼗纳秒到⼏微秒之间,如果你锁住的代码执⾏时间⽐较短,那可能上下⽂切换的时间都⽐你锁住的代码执⾏时间还要⻓。
所以,如果你能确定被锁住的代码执⾏时间很短,就不应该⽤互斥锁,⽽应该选⽤⾃旋锁,否则使⽤互斥锁。
⾃旋锁是通过 CPU 提供的 CAS 函数(Compare And Swap),在「⽤户态」完成加锁和解锁操作,不会主动产⽣线程上下⽂切换,所以相⽐互斥锁来说,会快⼀些,开销也⼩⼀些。
⼀般加锁的过程,包含两个步骤:
第⼀步,查看锁的状态,如果锁是空闲的,则执⾏第⼆步;第⼆步,将锁设置为当前线程持有;
CAS 函数就把这两个步骤合并成⼀条硬件级指令,形成原⼦指令,这样就保证了这两个步骤是不可分割的,要么⼀次性执⾏完两个步骤,要么两个步骤都不执⾏。
使⽤⾃旋锁的时候,当发⽣多线程竞争锁的情况,加锁失败的线程会「忙等待」,直到它拿到锁。这⾥的「忙等待」可以⽤ while 循环等待实现,不过最好是使⽤ CPU 提供的 PAUSE 指令来实现「忙等待」,因为可以减少循环等待时的耗电量。
⾃旋锁是最⽐较简单的⼀种锁,⼀直⾃旋,利⽤ CPU 周期,直到锁可⽤。需要注意,在单核 CPU 上,需要抢占式的调度器(即不断通过时钟中断⼀个线程,运⾏其他线程)。否则,⾃旋锁在单 CPU 上⽆法使⽤,因为⼀个⾃旋的线程永远不会放弃 CPU。
⾃旋锁开销少,在多核系统下⼀般不会主动产⽣线程切换,适合异步、协程等在⽤户态切换请求的编程⽅式,但如果被锁住的代码执⾏时间过⻓,⾃旋的线程会⻓时间占⽤ CPU 资源,所以⾃旋的时间和被锁住的代码执⾏的时间是成「正⽐」的关系,我们需要清楚的知道这⼀点。
⾃旋锁与互斥锁使⽤层⾯⽐较相似,但实现层⾯上完全不同:当加锁失败时,互斥锁⽤「线程切换」来应对,⾃旋锁则⽤「忙等待」来应对。
它俩是锁的最基本处理⽅式,更⾼级的锁都会选择其中⼀个来实现,⽐如读写锁既可以选择互斥锁实现,也可以基于⾃旋锁实现。
读写锁
读写锁从字⾯意思我们也可以知道,它由「读锁」和「写锁」两部分构成,如果只读取共享资源⽤「读锁」加锁,如果要修改共享资源则⽤「写锁」加锁。
所以,读写锁适⽤于能明确区分读操作和写操作的场景。
读写锁的⼯作原理是:当「写锁」没有被线程持有时,多个线程能够并发地持有读锁,这⼤⼤提⾼了共享资源的访问效率,因为「读锁」是⽤于读取共享资源的场景,所以多个线程同时持有读锁也不会破坏共享资源的数据。
但是,⼀旦「写锁」被线程持有后,读线程的获取读锁的操作会被阻塞,⽽且其他写线程的获取写锁的操作也会被阻塞。
所以说,写锁是独占锁,因为任何时刻只能有⼀个线程持有写锁,类似互斥锁和⾃旋锁,⽽读锁是共享锁,因为读锁可以被多个线程同时持有。
知道了读写锁的⼯作原理后,我们可以发现,读写锁在读多写少的场景,能发挥出优势。
另外,根据实现的不同,读写锁可以分为「读优先锁」和「写优先锁」。
读优先锁期望的是,读锁能被更多的线程持有,以便提⾼读线程的并发性,它的⼯作⽅式是:当读线程 A先持有了读锁,写线程 B 在获取写锁的时候,会被阻塞,并且在阻塞过程中,后续来的读线程 C 仍然可以成功获取读锁,最后直到读线程 A 和 C 释放读锁后,写线程 B 才可以成功获取写锁。如下图:

⽽写优先锁是优先服务写线程,其⼯作⽅式是:当读线程 A 先持有了读锁,写线程 B 在获取写锁的时候,会被阻塞,并且在阻塞过程中,后续来的读线程 C 获取读锁时会失败,于是读线程 C 将被阻塞在获取读锁的操作,这样只要读线程 A 释放读锁后,写线程 B 就可以成功获取读锁。如下图:
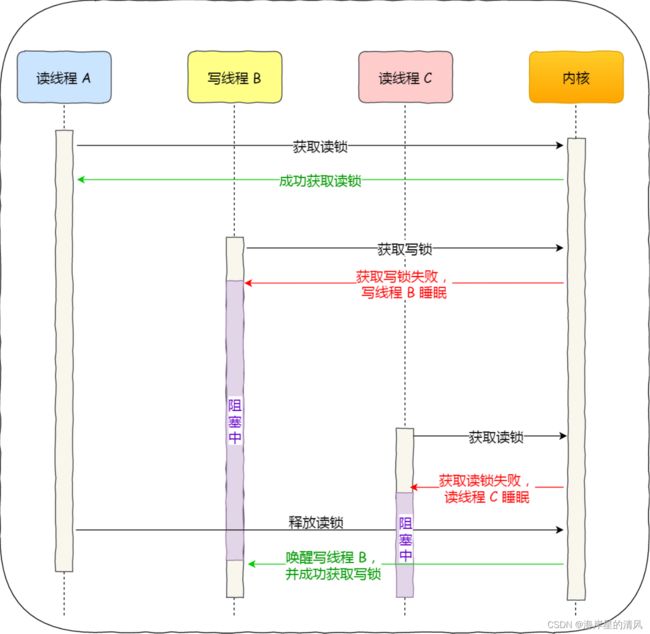
读优先锁对于读线程并发性更好,但也不是没有问题。我们试想⼀下,如果⼀直有读线程获取读锁,那么写线程将永远获取不到写锁,这就造成了写线程「饥饿」的现象。
写优先锁可以保证写线程不会饿死,但是如果⼀直有写线程获取写锁,读线程也会被「饿死」。
既然不管优先读锁还是写锁,对⽅可能会出现饿死问题,那么我们就不偏袒任何⼀⽅,搞个「公平读写锁」。
公平读写锁⽐较简单的⼀种⽅式是:⽤队列把获取锁的线程排队,不管是写线程还是读线程都按照先进先出的原则加锁即可,这样读线程仍然可以并发,也不会出现「饥饿」的现象。
互斥锁和⾃旋锁都是最基本的锁,读写锁可以根据场景来选择这两种锁其中的⼀个进⾏实现。
乐观锁与悲观锁
前⾯提到的互斥锁、⾃旋锁、读写锁,都是属于悲观锁。
悲观锁做事⽐较悲观,它认为多线程同时修改共享资源的概率⽐较⾼,于是很容易出现冲突,所以访问共享资源前,先要上锁。
那相反的,如果多线程同时修改共享资源的概率⽐较低,就可以采⽤乐观锁。
乐观锁做事⽐较乐观,它假定冲突的概率很低,它的⼯作⽅式是:先修改完共享资源,再验证这段时间内有没有发⽣冲突,如果没有其他线程在修改资源,那么操作完成,如果发现有其他线程已经修改过这个资源,就放弃本次操作。
放弃后如何重试,这跟业务场景息息相关,虽然重试的成本很⾼,但是冲突的概率⾜够低的话,还是可以接受的。
可⻅,乐观锁的⼼态是,不管三七⼆⼗⼀,先改了资源再说。另外,你会发现乐观锁全程并没有加锁,所以它也叫⽆锁编程。
这⾥举⼀个场景例⼦:在线⽂档。
我们都知道在线⽂档可以同时多⼈编辑的,如果使⽤了悲观锁,那么只要有⼀个⽤户正在编辑⽂档,此时其他⽤户就⽆法打开相同的⽂档了,这⽤户体验当然不好了。
那实现多⼈同时编辑,实际上是⽤了乐观锁,它允许多个⽤户打开同⼀个⽂档进⾏编辑,编辑完提交之后才验证修改的内容是否有冲突。
怎么样才算发⽣冲突?这⾥举个例⼦,⽐如⽤户 A 先在浏览器编辑⽂档,之后⽤户 B 在浏览器也打开了相同的⽂档进⾏编辑,但是⽤户 B ⽐⽤户 A 提交改动,这⼀过程⽤户 A 是不知道的,当 A 提交修改完的内容时,那么 A 和 B 之间并⾏修改的地⽅就会发⽣冲突。
服务端要怎么验证是否冲突了呢?通常⽅案如下:由于发⽣冲突的概率⽐较低,所以先让⽤户编辑⽂档,但是浏览器在下载⽂档时会记录下服务端返回的⽂档版本号;当⽤户提交修改时,发给服务端的请求会带上原始⽂档版本号,服务器收到后将它与当前版本号进⾏⽐较,如果版本号⼀致则修改成功,否则提交失败。
实际上,我们常⻅的 SVN 和 Git 也是⽤了乐观锁的思想,先让⽤户编辑代码,然后提交的时候,通过版本号来判断是否产⽣了冲突,发⽣了冲突的地⽅,需要我们⾃⼰修改后,再重新提交。
乐观锁虽然去除了加锁解锁的操作,但是⼀旦发⽣冲突,重试的成本⾮常⾼,所以只有在冲突概率⾮常低,且加锁成本⾮常⾼的场景时,才考虑使⽤乐观锁。
总结
开发过程中,最常⻅的就是互斥锁的了,互斥锁加锁失败时,会⽤「线程切换」来应对,当加锁失败的线程再次加锁成功后的这⼀过程,会有两次线程上下⽂切换的成本,性能损耗⽐较⼤。
如果我们明确知道被锁住的代码的执⾏时间很短,那我们应该选择开销⽐较⼩的⾃旋锁,因为⾃旋锁加锁失败时,并不会主动产⽣线程切换,⽽是⼀直忙等待,直到获取到锁,那么如果被锁住的代码执⾏时间很短,那这个忙等待的时间相对应也很短。
如果能区分读操作和写操作的场景,那读写锁就更合适了,它允许多个读线程可以同时持有读锁,提⾼了读的并发性。根据偏袒读⽅还是写⽅,可以分为读优先锁和写优先锁,读优先锁并发性很强,但是写线程会被饿死,⽽写优先锁会优先服务写线程,读线程也可能会被饿死,那为了避免饥饿的问题,于是就有了公平读写锁,它是⽤队列把请求锁的线程排队,并保证先⼊先出的原则来对线程加锁,这样便保证了某种线程不会被饿死,通⽤性也更好点。
互斥锁和⾃旋锁都是最基本的锁,读写锁可以根据场景来选择这两种锁其中的⼀个进⾏实现。
另外,互斥锁、⾃旋锁、读写锁都属于悲观锁,悲观锁认为并发访问共享资源时,冲突概率可能⾮常⾼,所以在访问共享资源前,都需要先加锁。
相反的,如果并发访问共享资源时,冲突概率⾮常低的话,就可以使⽤乐观锁,它的⼯作⽅式是,在访问共享资源时,不⽤先加锁,修改完共享资源后,再验证这段时间内有没有发⽣冲突,如果没有其他线程在修改资源,那么操作完成,如果发现有其他线程已经修改过这个资源,就放弃本次操作。
但是,⼀旦冲突概率上升,就不适合使⽤乐观锁了,因为它解决冲突的重试成本⾮常⾼。
不管使⽤的哪种锁,我们的加锁的代码范围应该尽可能的⼩,也就是加锁的粒度要⼩,这样执⾏速度会⽐较快。再来,使⽤上了合适的锁,就会快上加快了。
死锁
死锁的概念
在多线程编程中,我们为了防⽌多线程竞争共享资源⽽导致数据错乱,都会在操作共享资源之前加上互斥锁,只有成功获得到锁的线程,才能操作共享资源,获取不到锁的线程就只能等待,直到锁被释放。
那么,当两个线程为了保护两个不同的共享资源⽽使⽤了两个互斥锁,那么这两个互斥锁应⽤不当的时候,可能会造成两个线程都在等待对⽅释放锁,在没有外⼒的作⽤下,这些线程会⼀直相互等待,就没办法继续运⾏,这种情况就是发⽣了死锁。
死锁只有同时满⾜以下四个条件才会发⽣:
互斥条件;
持有并等待条件;
不可剥夺条件;
环路等待条件;
互斥条件
互斥条件是指多个线程不能同时使⽤同⼀个资源。
⽐如下图,如果线程 A 已经持有的资源,不能再同时被线程 B 持有,如果线程 B 请求获取线程 A 已经占⽤的资源,那线程 B 只能等待,直到线程 A 释放了资源。

持有并等待条件
持有并等待条件是指,当线程 A 已经持有了资源 1,⼜想申请资源 2,⽽资源 2 已经被线程 C 持有了,所以线程 A 就会处于等待状态,但是线程 A 在等待资源 2 的同时并不会释放⾃⼰已经持有的资源 1。
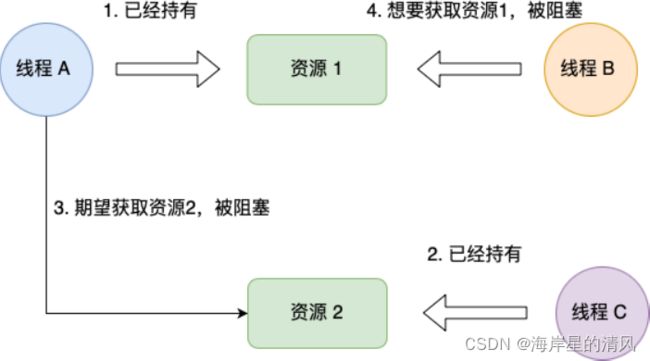
不可剥夺条件
不可剥夺条件是指,当线程已经持有了资源 ,在⾃⼰使⽤完之前不能被其他线程获取,线程 B 如果也想使⽤此资源,则只能在线程 A 使⽤完并释放后才能获取。
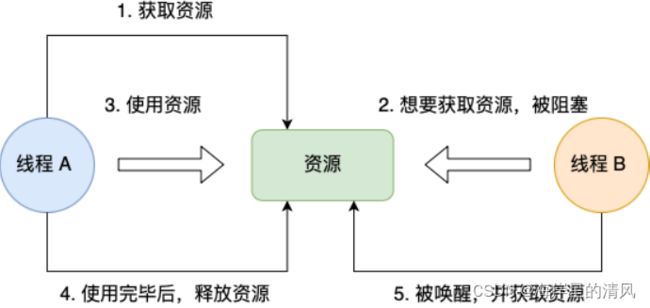
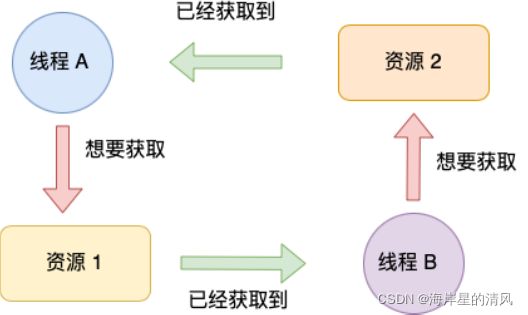
环路等待条件
环路等待条件指都是,在死锁发⽣的时候,两个线程获取资源的顺序构成了环形链。
⽐如,线程 A 已经持有资源 2,⽽想请求资源 1, 线程 B 已经获取了资源 1,⽽想请求资源 2,这就形成资源请求等待的环形图。
避免死锁问题的发⽣
前⾯我们提到,产⽣死锁的四个必要条件是:互斥条件、持有并等待条件、不可剥夺条件、环路等待条件。
那么避免死锁问题就只需要破环其中⼀个条件就可以,最常⻅的并且可⾏的就是使⽤资源有序分配法,来破环环路等待条件。
那什么是资源有序分配法呢?
线程 A 和 线程 B 获取资源的顺序要⼀样,当线程 A 是先尝试获取资源 A,然后尝试获取资源 B 的时候,线程 B 同样也是先尝试获取资源 A,然后尝试获取资源 B。也就是说,线程 A 和 线程 B 总是以相同的顺序申请⾃⼰想要的资源。
总结
简单来说,死锁问题的产⽣是由两个或者以上线程并⾏执⾏的时候,争夺资源⽽互相等待造成的。
死锁只有同时满⾜互斥、持有并等待、不可剥夺、环路等待这四个条件的时候才会发⽣。
所以要避免死锁问题,就是要破坏其中⼀个条件即可,最常⽤的⽅法就是使⽤资源有序分配法来破坏环路等待条件。
学自小林coding,侵删