目标检测模型发展概览R-CNN系列、YOLO V3(V1、v2)
摘要
目标检测目前应用广泛,国内很多算法工程师都是在做这方面工作的。目标检测发展可以看成是从单一单目标到多个多目标的过程。在算法方面也是从最初的机器学习方法到传统机器学习与深度学习算法结合,再到现在的全深度学习框架。
YOLO算法系列目前已经到了V5阶段(V4、V5我还没看),而且YOLO模型在工业应用方面可以说是最常用最万能的检测模型了。我们思考一个目标检测解决方法时,总是会先考虑YOLO能不能在这里用上。忘了…本文是原理篇,感谢您的阅读。
感觉直接说YOLO有点突兀,直接说V3不说V1 V2也突兀。所以就开始慢慢侃吧。
一、小猫图的说明
来上一张很常见的小猫图片:

目标检测最开始呢,当然是识别我这样一幅图片里有没有我想要的那个物体(Cat),有的话就输出为1,没有就是0。所以我们把这样一个问题看作是图片分类的问题。进阶一下:可是我不只是想要知道有没有,我还想知道在哪里。所以呢我们在分类基础上增加了一个回归目标框的问题。当然这是对单个目标。
再后来,我还想要找到这副图片里的其他物体(Dog and Duck…),那我就是要多目标检测了,在加上上面的定位问题。这里就比较复杂起来了。最难的是:我现在不仅仅要得出一个框,我要图片里的所以我想要的物体,并且我要把他们分割出来。猫就是猫类,狗是狗类。这样还不够的呢?我还想要他知道这是什么品种的猫,波斯,橘猫等等。。。哇! 你想想,这样是不是太难了。
不过现在我们已经可以做到上面的所有任务了。算法方面呢,就是一个层次递进的过程。
我们知道将图片输入侦测模型,模型只能提取到每个像素点的信息和这样一个分布信息。对于RGB图像,输入网络的是一个3个维度的由(0-255)组成的矩阵。我们构建的模型,就是找出这样的矩阵中存在目标物体的矩阵,并且输出对应的物体类型,和位置信息。这是一个看似最简单不过的过程。而所有的机器学习、深度学习算法也都是在做这样一个事情。
最简单的一个过程:我们利用CNN去学习这样的图像信息,通过给某类物体的标签和坐标值让他拟合出最佳的一套权重参数。在后续的推理过程中,利用这套权重参数和CNN模型就能达到预测类似物体的目的。
二、传统方法
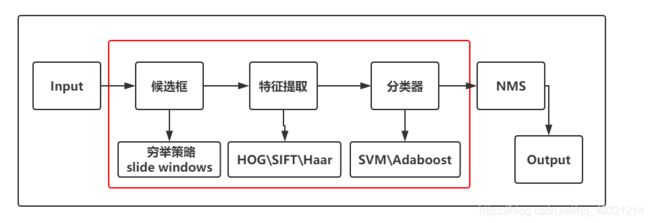
机器学习方法中的传统方法:通过使用选择性搜索、构建特征提取器和分类器的方式得到输出。
选择性搜索:Selective Search 通过在原图上滑动一个窗口,得出建议框位置。
特征提取器:HOG、SIFT、Haar等。
分类器:SVM、Adaboost等。
传统方法:在原图上滑动窗口这点类似卷积过程的滑动窗口,但是由于通过选择性搜索,这种方式得出的建议框一般多达1-2k个,再逐一使用特征提取器提取特征,再使用分类器分类,最后使用NMS去过滤重复候选框。缺点便是:算法冗余严重、检测速度很慢、效果平平。
三、深度学习加传统方法
1、Regions with CNN
论文:https://arxiv.org/pdf/1311.2524v5 .pdf
开辟:
传统的滑动窗口方法和回归框;使用了ROI 。
如图示流程:
1、使用选择性搜索的输出得到~2k个 ROI(感兴趣区域);
2、Warp候选区域为同一Size;
3、将Warped regions输入卷积神经网络后;
4、使用Linear Regression输出Bounding box的偏移量;
5、使用SVMs对Regions进行分类。
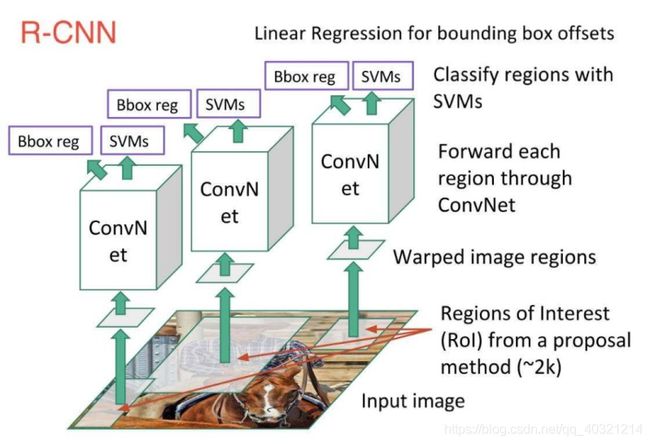
缺陷:每个框CNN提特征+SVM分类(卷积过程耗时、未全部抛弃机器学习算法)
2、SPP-Net
论文:https://arxiv.org/pdf/1406.4729v4.pdf
开辟:取代Crop/Warp操作为空间金字塔池化,使得对于神经网络有全连接层输出时的输入图像size可以是不固定的。也改善了Crop/Warp的形变问题。

流程:
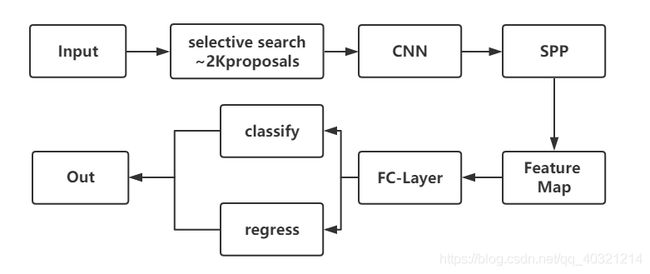
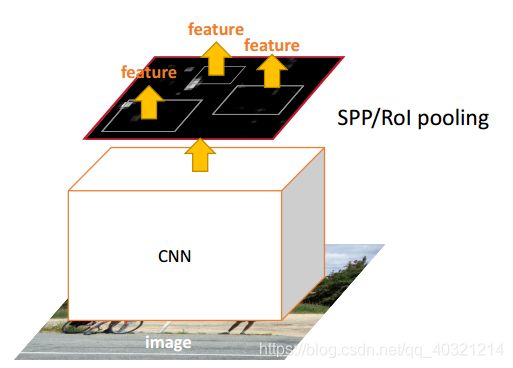
关于SPP-Net 翻译及解释。
3、Fast RCNN
论文:https://arxiv.org/pdf/1504.08083v2 .pdf
以上R-CNN和SPP-Net的缺陷在此论文中概括为:
1、训练是一个多阶段的过程;
2、训练在空间和时间上成本高;
3、检测速度慢。
开辟:
训练方面:是单一阶段,使用多任务损失;更新所有网络层;
使用ROI Pooling,SVM替换为Softmax分类;
可以达到实时检测!
流程:
输入图像和多个感兴趣区域(ROIS)被输入到全卷积网络中。每个ROI集合成一个固定大小的特征映射,然后通过完全连接层(FCS)映射到一个特征向量。该网络每个ROI有两个输出向量:Softmax概率和每类bounding-box回归偏移量。
其中的ROI层是SPP的特例,只使用了1个金字塔级别的池化。

缺陷:选择性搜索无法GPU运算,耗时很多,有~2K个候选框,冗余。
4、Faster RCNN
论文:https://arxiv.org/pdf/1506.01497v3.pdf
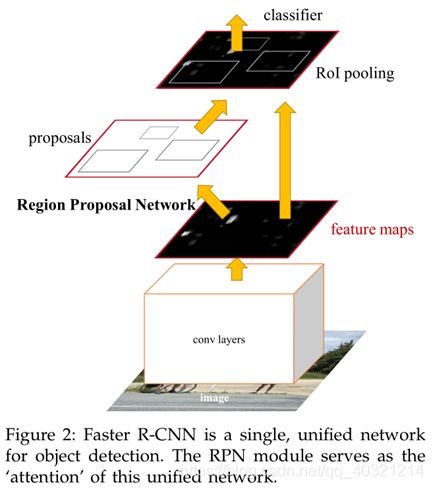
开辟:RPN代替选择性搜索直接预测出候选区域建议框,限定在300个;二是产生建议窗口的CNN和目标检测的CNN共享;引入Anchor box概念。
RPN:
1、在feature map上滑动窗口
2、 建一个神经网络用于物体分类+框位置的回归
3、 滑动窗口的位置提供了物体的大体位置信息
4、 框的回归提供了框更精确的位置
流程:
Faster-RCNN把整张图片送入CNN,进行特征提取;
在最后一层卷积feature map上生成region proposal(通过RPN),每张图片大约300个建议窗口;
通过RoI pooling层(其实是单层的SPP layer)使得每个建议窗口生成固定大小的feature map;
继续经过两个全连接层(FC)得到特征向量。特征向量经由各自的FC层,得到两个输出向量, 第一个是分类,使用softmax,第二个是每一类的bounding box回归。
利用SoftMax Loss和Smooth L1 Loss对分类概率和边框回归(Bounding Box Regression)联合训练。
所以我们可以看出来:Faster-RCNN = RPN(区域生成网络)+ Fast-RCNN
缺陷:网络有四个损失函数,优化比较耗时。
5、系列总结

我们可以看出,传统的机器学习方法是逐步被深度学习方法取代的,随之而来的也是更快更准的网络模型。
四、深度学习方法
1、YOLO V1
论文:https://arxiv.org/pdf/1506.02640v5 .pdf
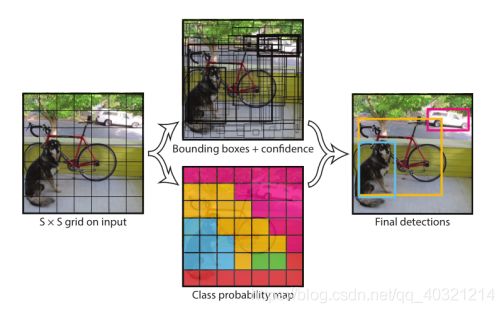
开辟:Anchor Box (锚框)、One-Stage端到端的思想、Grid Cell (格子)
流程:实现输入的图片大小W,H都是32的倍数,v1中是7倍即 224*244大小。那么图上的SXS就是S=7,这49个格子每一个格子负责预测一个物体。经过CNN输出后,得到一部分是每个格子预测出的Bounding boxes和置信度,还有一个关于每个格子存在哪种物体的一个7X7的图。经过NMS操作后得到输出结果。
下面解释一下:
Anchor Box:在侦测图像中的这条狗,我们希望用一个竖着的长方形去框它,但是这个框怎么得到呢?一种方法是,网络输出一组坐标就是这个框;另外一种,我根据先验条件,狗可以坐着的(竖着的长方形),趴着的(横着的长方形)。那么我先给网络2个anchor box(W=50,H=100或者W=100,H=50),网络就根据这个box去图像中找物体。这样能保证的是,模型不会去瞎找了,不会去遍历每一种box。当然,这是在YOLO里面。
Grid Cell:把正方形图像划分为格子(Grid)。给图像划分格子的目的是什么呢?在一幅特定大小的图像里面,我们已经知道的是,图像里的东西就那几样,不会特别多,所以按照32的像素去划分。那我们把按32个像素去把图像分成SxS大小的格子后。每个格子去预测该格子所在区域的一个物体,例如蓝色格子预测了狗。只要我这个格子预测了某个物体,我就对这个格子进行下一步的计算去回归坐标和置信度。
One-Stage:一幅图像经过网络后直接输出预测框的方式。Two-stage目标检测:比如Faster R-CNN,会先生成一些候选区域(region proposals),再经过网络等去输出预测框。
详解:
输入448x448x3 ,经过GoogleNet输出4096x1的向量,经过FC\Reshape后的得到7x7x30的特征图。7x7是代表了H,W=7的特征图,反算回原图时需要乘以整个网络的总步长,这里的总步长=448/7=64=2^6,说明原图像在网络里经过了6次步长为2的下采样(卷积)。每一个7x7的格里都有一个长为30的向量。其中前2x5个值中的2为:两个anchor box类型,5代表每个anchor box里的(x,y,w,h,cls),后面20个值是一个One-Hot形式的向量,代表这是哪类物体。注意,这里对图像预测了20个类别的物体,所以为20。anchor box只使用了两个所以为2。当我们给需要给4个锚框和预测4类物体时。这里的原本7x7x30的输出应该为:7x7x(4x5+4)= 7x7x24。
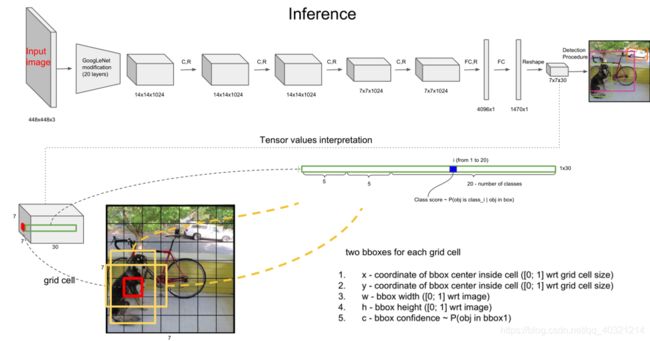
这里还有一个点比较重要。上图中的预测中的x和y是对应grid cell的。而w,h是对应原图像的宽和高的一个偏移量。
关于x,y:特征图大小为7730时,比如每第4*5个30长的向量代表了,第4,5的那个格子中对应的物体(30)的两种锚框尺寸对应的两组坐标、置信度和20个类别的One-Hot向量。这里的x,y是中心点关于所在的这个Grid Cell(0,0)的位置。
关于w,h:是对应原图的w,h的一个预测值。V1中的损失函数使用开根号的方式对W,H进行了压缩,使网络更好的回归。
损失函数:其中蓝色框类是网络对该Grid Cell中有无物体的目标函数,其余部分是对该Grid Cell存在物体时中心点,宽高,置信度的目标函数。

缺陷:V1作为开篇之作引入很多新思想和方法,其中可以优化的是:anchor box 是人为给的两种,网络模型有改进空间,损失函数改进等。
2、SSD
论文:https://arxiv.org/pdf/1512.02325v5 .pdf
开辟:SSD结合YOLO的回归思想以及Faster R-CNN的anchor机制通过召回率,提高对小物体的检测。
特征图大小与对应图像上物体的大小关系:在88的特征图上,相同大小的锚框可以框出小物体,在44的特征图上,可以框出较大的物体。随着特征图变小,可以侦测的物体变大。
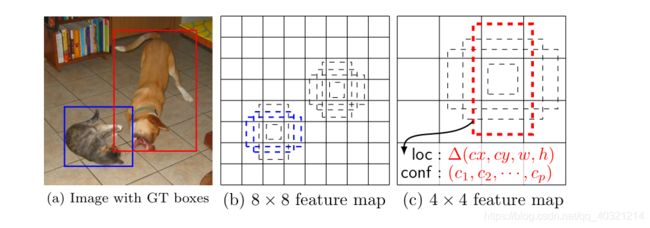
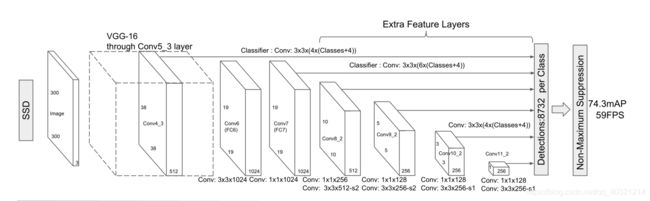
网络模型:
随着在VGG-16上的多次卷积,特征图的大小逐渐变小,SSD选择将前面每层的特征图都保留下来,在最后一层拼接起来。这样使得前面的层能侦测最小的物体,最后面的层能侦测最大的物体。
3、YOLO V2
论文:https://arxiv.org/pdf/1612.08242v1 .pdf
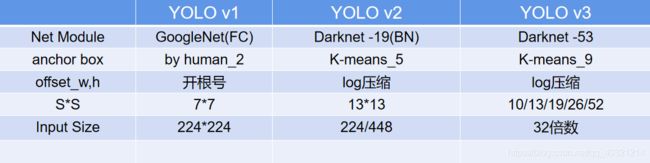
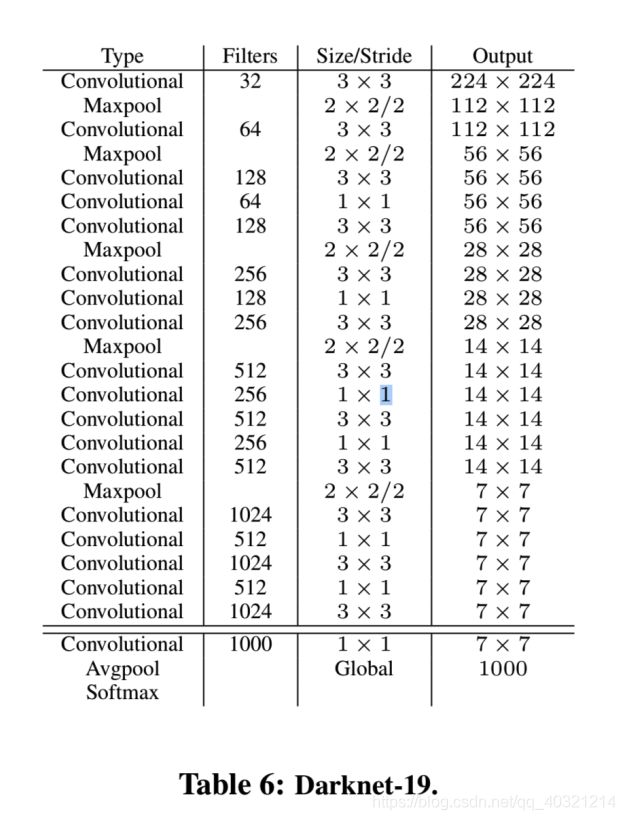
改进:在V1基础上,网络模型更换为DarkNet19,对锚框进行了K-means聚类生成5类,使用Grid Cell Offset。
对损失函数改进为:将预测出的中心点坐标通过Sigmoid输出,将标签的W,H通过log函数压缩。
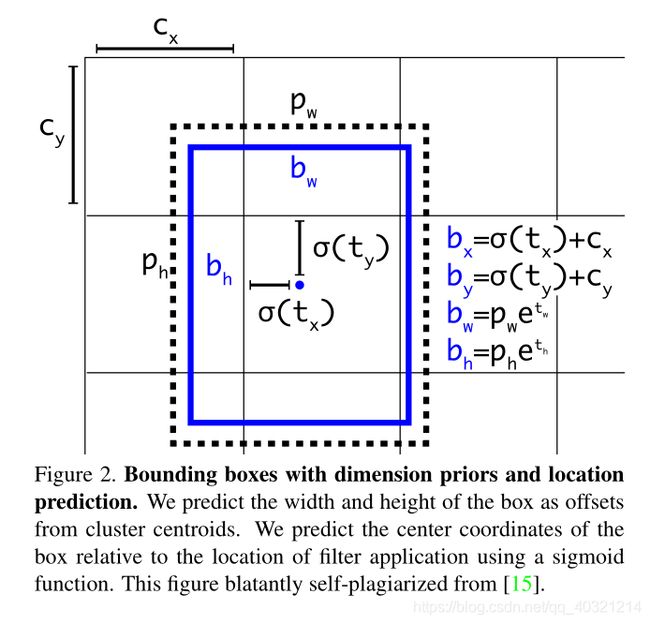
缺点:没有用SSD的Extra Feature Layers思想,DarkNet19中池化效果不好。
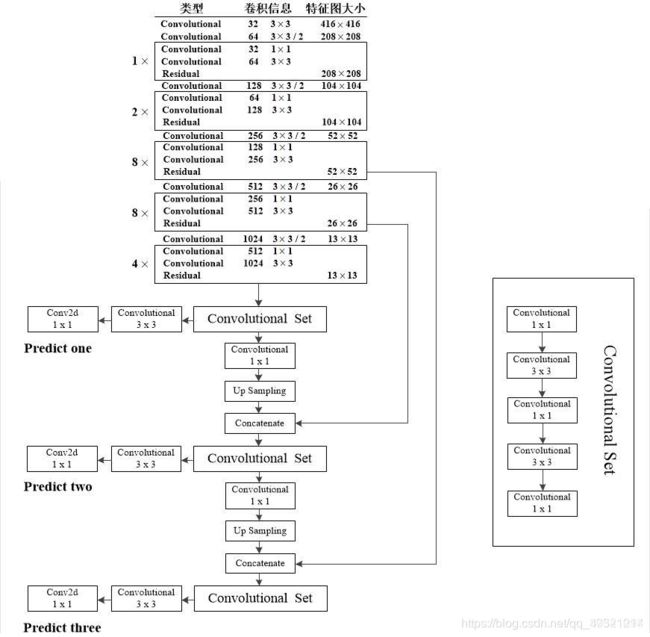
4、YOLO V3
论文:https://pjreddie.com/media/files/papers/YOLOv3.pdf
改进:在V2基础上,网络模型更换为DarkNet53采样ResNet结构,K-means聚类生成9类,引入了SSD思想。出现混合类(包含关系)时:不可用Softmax,用 BCEWithLogitsLoss,来执行多标签分类。
YOLO系列总结:
YOLO系列缺点:对非常规物体侦测效果差,鲁棒性差;对靠近的物体和小物体侦测效果不好;训练时间长。
And So On
YOLO V4、V5有机会再写下。
DarkNet19:
YOLO DarkNet53: