PointRCNN论文和逐代码详解
1、前言
当前点云检测的常见方式分别有
1、将点云划分成voxel来进行检测,典型的模型有VoxelNet、SECOND等;作然而本文的作者史博士提出这种方法会出现量化造成的信息损失。
2、将点云投影到前视角或者鸟瞰图来来进行检测,包括MV3D、PIXOR、AVOD等检测模型;同时这类模型也会出现量化损失。
3、将点云直接生成伪图片,然后使用2D的方式来进行处理,这主要是PointPillar。
本文PointRCNN提出的方法,是一篇比较新颖的点云检测方法,与此前的检测模型不同,它直接根据点云分割的结果来产生候选框,并根据这些候选框的内部数据和之前的分割特征来完成物体的准确定位和分类。
论文地址:https://arxiv.org/abs/1812.04244
原论文代码地址:GitHub - sshaoshuai/PointRCNN: PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud, CVPR 2019. https://github.com/sshaoshuai/PointRCNN
https://github.com/sshaoshuai/PointRCNN
OpenPCDet代码地址:
https://github.com/open-mmlab/OpenPCDet/https://github.com/open-mmlab/OpenPCDet/
注: OpenPCDet代码仓库中的实现与原论文和原仓库的实现已经有较大的变化,本文将以OpenPCDet代码仓库为准:(史帅自己也说了)

PointRCNN在(OpenPCDet)的代码实现类结构图

主要有三个模块来实现整个网络:
第一阶段:
PointNet2MSG:对原始的点云进行编码解码操作(PointNet++)
PointHeadBox:对经过PointNet++的点云进行分类操作和box的预测
第二阶段:
PointRCNNHead:对每个roi进行精调
2、PointRCNN的网络模块解析
PointRCNN网络结构图(图来自源论文)

当前的2D检测框架可以分为一阶和二阶两种检测模型,通常一阶模型拥有更高的精度但是缺乏对生成框的调优,二阶段模块可以根据提议框进一步调整预测结果。如果直接将2维的检测模型中二阶段直接迁移到3D的检测任务上的话,是比较困难的。因为3D检测任务拥有更大的搜索空间,并且点云数据并不是密集数据。如果使用这样的方式,像AVOD那样,需要放置20-100K个anchor在3为空间中,这种做法很蠢;如果像F-PointNet那样,采用2D的检测框架首先在图片上来生成物体的proposal,然后在这个视锥内来检测3D的物体的话,确实可以极大的减少3D空间中的搜索范围,但是也会导致很多只有在3D空间下才能看到的物体因为遮挡等原因无法在图像中得以显示,造成模型的recall不高,同时该方法也极大的依赖于2D检测器的性能。
因此PointRCNN首次直接在点云数据上分割mask(这里能直接预测mask的原因主要是3D的标注框中,可以清晰的标注出来一个GTBox中有哪些点云数据,而且在自然的3D世界中,不会出现像图片里面物体重叠的情况,因此每个点云中属于前景的mask就得到了),然后在第二阶段中对每个proposal中第一阶段学习到的特征和处在proposal中的原始点云数据进行池化操作。通过将坐标系转换到canonical coordinate system(CCS)坐标系中来进一步的优化得到box和cls的结果。
3、自下而上的3D建议框生成:
3.1. 特征提取网络(PointNet2MSG)
在PointRCNN中,首先采用Multi-Scale-Grounping 的PointNet++网络来完成对点云中前背景点的分割和proposal的生成。因为标注的数据中每个GTbox就可以清晰的标注出点云中哪些属于的前景点,哪些属于背景点;显然背景点的数量肯定是比前景点的数量要多得多的。所以作者在这里采用了focal loss来解决类别不平衡的问题。
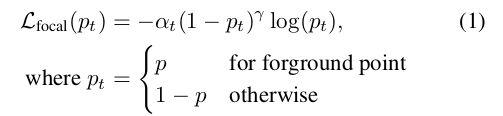
注:(alpha和gamma都与RetinaNet中设置一样,alpha为0.25,gamma为2)
原来的PointNet++网络中并没有box的regression,所以作者在这里增加了一个回归头用于前给景点生成proposal。其中这里前背景点的分割和前景点的proposal生成是同步完成的,只不过在代码实现中,只取前景点的box。请注意,这里的proposal的box生成虽然是直接从前景点的特征来生成的,但是背景点也提供了丰富的感受野信息,因为Point Cloud Encoder和Point Cloud Decoder网络在已经将点云数据进行了融合(比如PointNet++中,Decoder根据距离权重插值的方式,来反向传播点的信息)。
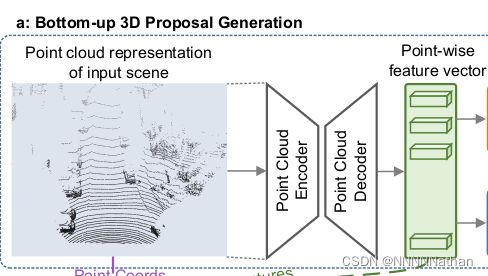
经过该上述部分处理后,得到网络中所有的前景点和前景点生成的proposal。这样就解决了在3D空间中设置大量anchor的愚蠢操作了,也就减少了proposal的搜索范围。
其中在实现的过程中,每针点云数据随机采样16384个点(如果一帧点云中点的数量少于16384,则重复采样至16384)。Point Cloud Network采用PointNet++(MSG),同时作者也表明采用其他网络也是可以的,比如PointShift、PointNet、VoxelNet with sparse conv。
PointNet++ 参数设置如下:
Encoder为4个Set-Abstraction层,每层最远点采样的个数分别是4096,1024,256,64。
Decoder为4个Feature-Probagation层,用于获得每个点的特征向量来给后面的PointHeadBox网络进行每个点的分割得到哪些点属于前景点,哪些点属于背景点。
代码在:pcdet/models/backbones_3d/pointnet2_backbone.py
class PointNet2MSG(nn.Module):
def __init__(self, model_cfg, input_channels, **kwargs):
super().__init__()
self.model_cfg = model_cfg
self.SA_modules = nn.ModuleList()
channel_in = input_channels - 3
self.num_points_each_layer = []
skip_channel_list = [input_channels - 3]
# 初始化PointNet++中的SetAbstraction
for k in range(self.model_cfg.SA_CONFIG.NPOINTS.__len__()):
mlps = self.model_cfg.SA_CONFIG.MLPS[k].copy()
channel_out = 0
for idx in range(mlps.__len__()):
mlps[idx] = [channel_in] + mlps[idx]
channel_out += mlps[idx][-1]
self.SA_modules.append(
pointnet2_modules.PointnetSAModuleMSG(
npoint=self.model_cfg.SA_CONFIG.NPOINTS[k],
radii=self.model_cfg.SA_CONFIG.RADIUS[k],
nsamples=self.model_cfg.SA_CONFIG.NSAMPLE[k],
mlps=mlps,
use_xyz=self.model_cfg.SA_CONFIG.get('USE_XYZ', True),
)
)
skip_channel_list.append(channel_out)
channel_in = channel_out
# 初始化PointNet++中的feature back-probagation
self.FP_modules = nn.ModuleList()
for k in range(self.model_cfg.FP_MLPS.__len__()):
pre_channel = self.model_cfg.FP_MLPS[k + 1][-1] if k + 1 < len(self.model_cfg.FP_MLPS) else channel_out
self.FP_modules.append(
pointnet2_modules.PointnetFPModule(
mlp=[pre_channel + skip_channel_list[k]] + self.model_cfg.FP_MLPS[k]
)
)
self.num_point_features = self.model_cfg.FP_MLPS[0][-1]
# 处理点云数据,用于得到(batch,n_points,xyz)的形式
def break_up_pc(self, pc):
batch_idx = pc[:, 0] # 经过预处理后,每个点云的第一个维度数据存放的是该点云在batch中的索引
xyz = pc[:, 1:4].contiguous() # 得到所有的点云数据
features = (pc[:, 4:].contiguous() if pc.size(-1) > 4 else None) # 得到除了xyz中的其他数据,比如intensity
return batch_idx, xyz, features
def forward(self, batch_dict):
"""
Args:
batch_dict:
batch_size: int
vfe_features: (num_voxels, C)
points: (num_points, 4 + C), [batch_idx, x, y, z, ...]
Returns:
batch_dict:
encoded_spconv_tensor: sparse tensor
point_features: (N, C)
"""
# batch_size
batch_size = batch_dict['batch_size']
# (batch_size * 16384, 5)
points = batch_dict['points']
# 得到每个点云的batch索引,和所有的点云的xyz、intensity数据
batch_idx, xyz, features = self.break_up_pc(points)
# 创建一个全0的xyz_batch_cnt,用于存放每个batch中总点云个数是多少
xyz_batch_cnt = xyz.new_zeros(batch_size).int()
for bs_idx in range(batch_size):
xyz_batch_cnt[bs_idx] = (batch_idx == bs_idx).sum()
# 在训练的过程中,一个batch中的所有的点云的中点数量需要相等,
assert xyz_batch_cnt.min() == xyz_batch_cnt.max()
# shape :(batch_size, 16384, 3)
xyz = xyz.view(batch_size, -1, 3)
# shape : (batch_size, 1, 16384)
features = features.view(batch_size, -1, features.shape[-1]).permute(0, 2, 1).contiguous() \
if features is not None else None
# 定义一个用来存放经过PointNet++的数据结果,用于后面PointNet++的feature back-probagation层
l_xyz, l_features = [xyz], [features]
# 使用PointNet++中的SetAbstraction模块来提取点云的数据
for i in range(len(self.SA_modules)):
"""
最远点采样的点数
NPOINTS: [4096, 1024, 256, 64]
# BallQuery的半径
RADIUS: [[0.1, 0.5], [0.5, 1.0], [1.0, 2.0], [2.0, 4.0]]
# BallQuery内半径内最大采样点数(MSG)
NSAMPLE: [[16, 32], [16, 32], [16, 32], [16, 32]]
# MLPS的维度变换
# 其中[16, 16, 32]表示第一个半径和采样点下的维度变换,
[32, 32, 64]表示第二个半径和采样点下的维度变换,以下依次类推
MLPS: [[[16, 16, 32], [32, 32, 64]],
[[64, 64, 128], [64, 96, 128]],
[[128, 196, 256], [128, 196, 256]],
[[256, 256, 512], [256, 384, 512]]]
"""
"""
param analyze:
li_xyz shape:(batch, sample_n_points, xyz_of_centroid_of_x)
li_features shape:(batch, channel, Set_Abstraction)
detail:
1、li_xyz shape:(batch, 4096, 3), li_features shape:(batch, 32+64, 4096)
2、li_xyz shape:(batch, 1024, 3), li_features shape:(batch, 128+128, 1024)
3、li_xyz shape:(batch, 256, 3), li_features shape:(batch, 256+256, 256)
4、li_xyz shape:(batch, 64, 3), li_features shape:(batch, 512+512, 64)
"""
li_xyz, li_features = self.SA_modules[i](l_xyz[i], l_features[i])
l_xyz.append(li_xyz)
l_features.append(li_features)
# PointNet++中的feature back-probagation层,从已经知道的特征中,通过距离插值的方式来计算出上一个点集中未知点的特征信息
"""
其中:
i=[-1, -2, -3, -4]
以-1为例:
unknown的特征是上一层点集中所有的点的坐标,known是当前已知特征的点的坐标,feature是对应的特征
在已经知道的点中,找出三个与之最近的三个不知道的点,然后对这三个点根据距离计算插值,
得到插值结果(bacth, 1024, 256),再将插值得到的特征和上一层计算的特征在维度上进行
拼接的得到(bacth, 1024+512, 256),并进行一个mlp(代码实现中用的1*1的卷积完成)操作
来进行降维得到上一层的点的特征,(bacth,512, 256)。这样就将深层的信息,传递回去了。
"""
for i in range(-1, -(len(self.FP_modules) + 1), -1):
unknown = l_xyz[i - 1]
known = l_xyz[i]
unknow_feats = l_features[i - 1]
known_feats = l_features[i]
res = self.FP_modules[i](
unknown, known, unknow_feats, known_feats
) # (B, C, N)
l_features[i - 1] = res
# l_features[i - 1] = self.FP_modules[i](
# l_xyz[i - 1], l_xyz[i], l_features[i - 1], l_features[i]
# ) # (B, C, N)
"""
经过PointNet++的feature back-probagation处理后,
l_feature的结果是
[
[batch, 128, 16384],
[batch, 256, 4096],
[batch, 512, 1024],
[batch, 512, 256],
[batch, 1024, 64],
]
"""
# 将反向回传得到的原始点云数据进行维度变换 (batch, 128, 16384)--> (batch, 16384, 128)
point_features = l_features[0].permute(0, 2, 1).contiguous() # (B, N, C)
# 得到的结果存放入batch_dict (batch, 16384, 128) --> (batch * 16384, 128)
batch_dict['point_features'] = point_features.view(-1, point_features.shape[-1])
# (batch * 16384, 1) (batch * 16384, 3) 变回输入的形式
batch_dict['point_coords'] = torch.cat((batch_idx[:, None].float(), l_xyz[0].view(-1, 3)), dim=1)
return batch_dict
3.2. Bin-based 3D Bbox generation(论文)
在激光雷达坐标系中,一个3D的Bbox可以表示为 (x, y, z, l, w, h, θ),xyz是该Bbox的中心在雷达坐标系的中心,lwh是该Bbox的长宽高,θ是物体在BEV视角下的旋转角度。
在对点进行box生成的时候,只需要对前景点的box进行回归操作。虽然没有对背景点进行回归操作,但是在PointNet++的反向回传中,背景点也为这些前景点提供了丰富的感受野信息。
Bin-based Localization(图来自原论文)
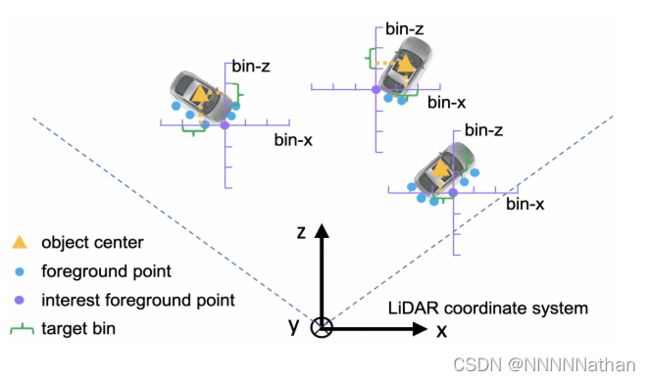
在论文中作者使用的是Bin-based的box位置估计,就是将原来只需要回归残差的方式变成了,分类和回归,什么意思呢?如果直接对一个残差进行回归的话,就只需要让一个box预测的偏移量与该box编码的值越来越小就可以,但是这里转换成了前景点与之对应的GT在哪个bin的分类问题和在该bin中对剩余部分的回归问题。可以看上图。计算的目标公式如下:

其中x^p是GT的中心坐标,x^(p)是当前前景点的原点。S是搜索范围,论文中设置为3m,![]() 为bin的大小,设置为0.5m。C是bin的长度用来进行归一化操作。
为bin的大小,设置为0.5m。C是bin的长度用来进行归一化操作。
那么这设置的话到GT的偏移就变成了由第N个bin的分类问题和第N个bin中residual regression的回归问题。论文中作者说这种方式要比直接使用L1损失函数计算的回归进度更高。
对于高度上的预测,直接使用了SmoothL1来回归之间的残差,因为高度上的变化没有这么大。
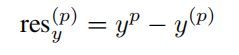
同时,对于角度的预测,也采用了基于bin的方式,将2pi分成n个bins,并分类GT在哪个bin中,和对应分类bin中的residual regression回归。
这里的box生成中使用的物体的长宽高是直接根据整体数据集中每个类别的长宽高的平局数值。并在编码box时候,直接使用该数据进行编码。
总体的损失记为:
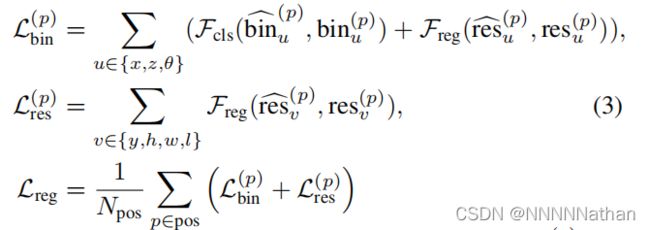
其中Npos是前景点的总个数,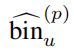 和
和  是前景点预测的结果
是前景点预测的结果![]() 和
和![]() 是GT的编码结果。Fcls代表了cross-entropy classifification loss、Freg代表了smoothL1 loss。
是GT的编码结果。Fcls代表了cross-entropy classifification loss、Freg代表了smoothL1 loss。
在推理阶段,这个bin-base的预测中,只需要找到拥有最高预测置信度的bin,并加上残差的预测结果就可以。其它的参数只需要将预测的数值加上初始数值就可以。
代码中所有的box回归(第一阶段的box生成和第二阶段的ROI优化)都采用了bin-based的方法。该方法的内容实现与原论文代码仓库中的内容相同,但是在OpenPCDet中,史帅的实现并没有采用基于bin-base的方法,而是直接使用了smoothL1来进行预测;同时角度的预测也从bin-based的方式变成了residual-cos-based的方法。这里统一以PCDet为准,后续不再赘述。
详情可以看这个issue:https://github.com/open-mmlab/OpenPCDet/issues/255
3.2. 代码中box的生成(PointHeadBox)
好了说回正文,本博客已OpenPCDet代码仓库的代码为基础,进行解析,这里已实际的代码来进行解析。
3.2.1. 每个点的类别和box预测
经过PointNet++后,网络得到的point feature输出为(batch * 16384, 128),接下来就需要对每个点都进行分类和回归操作。
代码在:pcdet/models/dense_heads/point_head_box.py
def forward(self, batch_dict):
"""
Args:
batch_dict:
batch_size:
point_features: (N1 + N2 + N3 + ..., C) or (B, N, C)
point_features_before_fusion: (N1 + N2 + N3 + ..., C)
point_coords: (N1 + N2 + N3 + ..., 4) [bs_idx, x, y, z]
point_labels (optional): (N1 + N2 + N3 + ...)
gt_boxes (optional): (B, M, 8)
Returns:
batch_dict:
point_cls_scores: (N1 + N2 + N3 + ..., 1)
point_part_offset: (N1 + N2 + N3 + ..., 3)
"""
# False
if self.model_cfg.get('USE_POINT_FEATURES_BEFORE_FUSION', False):
point_features = batch_dict['point_features_before_fusion']
else:
point_features = batch_dict['point_features'] # 从字典中每个点的特征 shape (batch * 16384, 128)
""" 点分类的网络详情
Sequential(
(0): Linear(in_features=128, out_features=256, bias=False)
(1): BatchNorm1d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Linear(in_features=256, out_features=256, bias=False)
(4): BatchNorm1d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): Linear(in_features=256, out_features=3, bias=True)
)
"""
# 对每个点进行分类 (batch * 16384, num_class)
point_cls_preds = self.cls_layers(point_features)
""" 点生成proposal的网络详情,其中这里作者使用了residual-cos-based来编码θ,也就是角度被 (cos(∆θ), sin(∆θ))来编码,所以最终回归的参数是8个
Sequential(
(0): Linear(in_features=128, out_features=256, bias=False)
(1): BatchNorm1d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Linear(in_features=256, out_features=256, bias=False)
(4): BatchNorm1d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): Linear(in_features=256, out_features=8, bias=True)
)
"""
# 点回归proposal (batch * 16384, box_code_size)
point_box_preds = self.box_layers(point_features)
# 从每个点的分类预测结果中,取出类别预测概率最大的结果 (batch * 16384, num_class) --> (batch * 16384, )
point_cls_preds_max, _ = point_cls_preds.max(dim=-1)
# 将类别预测分数经过sigmoid激活后放入字典中
batch_dict['point_cls_scores'] = torch.sigmoid(point_cls_preds_max)
# 将点的类别预测结果和回归结果放入字典中
ret_dict = {'point_cls_preds': point_cls_preds,
'point_box_preds': point_box_preds}
# 如果在训练模式下,需要根据GTBox来生成对应的前背景点,用于点云的前背景分割,给后面计算前背景分类loss
if self.training:
targets_dict = self.assign_targets(batch_dict)
# 将一个batch中所有点的GT类别结果放入字典中 shape (batch * 16384)
ret_dict['point_cls_labels'] = targets_dict['point_cls_labels']
# 将一个batch中所有点的GT_box编码结果放入字典中 shape (batch * 16384) shape (batch * 16384, 8)
ret_dict['point_box_labels'] = targets_dict['point_box_labels']
# 训练和预测都需要生成第一阶段的proposal 然后给第二阶段来refine
if not self.training or self.predict_boxes_when_training:
# 生成预测的box
point_cls_preds, point_box_preds = self.generate_predicted_boxes(
# 所有点的xyz坐标(batch*16384, 3)
points=batch_dict['point_coords'][:, 1:4],
# 所有点的预测类别(batch*16384, 3)
point_cls_preds=point_cls_preds,
# 所有点的box预测(batch*16384, 8)
point_box_preds=point_box_preds
)
batch_dict['batch_cls_preds'] = point_cls_preds # 所有点的类别预测结果 (batch * 16384, 3)
batch_dict['batch_box_preds'] = point_box_preds # 所有点的回归预测结果 (batch * 16384, 7)
batch_dict['batch_index'] = batch_dict['point_coords'][:, 0] # 所有点的在batch中的索引 (batch * 16384, )
batch_dict['cls_preds_normalized'] = False # loss计算中,是否需要对类别预测结果进行normalized
# 第一阶段生成的预测结果放入前向传播字典
self.forward_ret_dict = ret_dict
return batch_dict3.2.2. 前背景点target assignment(loss计算)
对每个点进行分类后可以得到 point_cls_preds_max,维度是(batch * 16384, num_class),并取出每个类别的最大值并进行sigmoid激活,得到 point_cls_scores,维度是(batch * 16384, )。然后进行target assignment。
target assignment的时候需要对每个GT的长宽高都延长0.2米,并将这些处于边缘0.2米的点的target设置为-1,不计算分类损失。原因是为了提高点云分割的健壮性,因为,3D的GTBox会有小的变化。
代码在:pcdet/models/dense_heads/point_head_box.py
def assign_targets(self, input_dict):
"""
Args:
input_dict:
point_features: (N1 + N2 + N3 + ..., C)
batch_size:
point_coords: (N1 + N2 + N3 + ..., 4) [bs_idx, x, y, z]
gt_boxes (optional): (B, M, 8)
Returns:
point_cls_labels: (N1 + N2 + N3 + ...), long type, 0:background, -1:ignored
point_part_labels: (N1 + N2 + N3 + ..., 3)
"""
# 得到每个点的坐标 shape(bacth * 16384, 4),其中4个维度分别是batch_id,x,y,z
point_coords = input_dict['point_coords']
# 取出gt_box,shape (batch, num_of_GTs, 8),
# 其中维度8表示 x, y, z, l, w, h, heading, class_id
gt_boxes = input_dict['gt_boxes']
# 确保维度正确
assert gt_boxes.shape.__len__() == 3, 'gt_boxes.shape=%s' % str(gt_boxes.shape)
assert point_coords.shape.__len__() in [2], 'points.shape=%s' % str(point_coords.shape)
batch_size = gt_boxes.shape[0]
# 在训练的过程中,需要忽略掉点云中离GTBox较近的点,因为3D的GTBox也会有扰动,
# 所以这里通过将每一个GT_box都在x,y,z方向上扩大0.2米,
# 来检测哪些点是属于扩大后才有的点,增强点云分割的健壮性
extend_gt_boxes = box_utils.enlarge_box3d(
gt_boxes.view(-1, gt_boxes.shape[-1]), extra_width=self.model_cfg.TARGET_CONFIG.GT_EXTRA_WIDTH
).view(batch_size, -1, gt_boxes.shape[-1])
"""
assign_stack_targets函数完成了一批数据中所有点的前背景分配,
并为每个前景点分配了对应的类别和box的7个回归参数,xyzlwhθ
"""
targets_dict = self.assign_stack_targets(
points=point_coords, gt_boxes=gt_boxes, extend_gt_boxes=extend_gt_boxes,
set_ignore_flag=True, use_ball_constraint=False,
ret_part_labels=False, ret_box_labels=True
)
return targets_dictself.assign_stack_targets()函数用于完成一批数据中点云的前背景分配和前景点云的每个类别的平均anchor大小和GTbox编码操作 代码在:pcdet/models/dense_heads/point_head_template.py
def assign_stack_targets(self, points, gt_boxes, extend_gt_boxes=None,
ret_box_labels=False, ret_part_labels=False,
set_ignore_flag=True, use_ball_constraint=False, central_radius=2.0):
"""
Args:
points: (N1 + N2 + N3 + ..., 4) [bs_idx, x, y, z]
gt_boxes: (B, M, 8)
extend_gt_boxes: [B, M, 8]
ret_box_labels: True
ret_part_labels: Fasle
set_ignore_flag: True
use_ball_constraint: False
central_radius:
Returns:
point_cls_labels: (N1 + N2 + N3 + ...), long type, 0:background, -1:ignored
point_box_labels: (N1 + N2 + N3 + ..., code_size)
"""
assert len(points.shape) == 2 and points.shape[1] == 4, 'points.shape=%s' % str(points.shape)
assert len(gt_boxes.shape) == 3 and gt_boxes.shape[2] == 8, 'gt_boxes.shape=%s' % str(gt_boxes.shape)
assert extend_gt_boxes is None or len(extend_gt_boxes.shape) == 3 and extend_gt_boxes.shape[2] == 8, \
'extend_gt_boxes.shape=%s' % str(extend_gt_boxes.shape)
assert set_ignore_flag != use_ball_constraint, 'Choose one only!'
# 得到一批数据中batch_size的大小,以方便逐帧完成target assign
batch_size = gt_boxes.shape[0]
# 得到一批数据中所有点云的batch_id
bs_idx = points[:, 0]
# 初始化每个点云的类别,默认全0; shape (batch * 16384)
point_cls_labels = points.new_zeros(points.shape[0]).long()
# 初始化每个点云预测box的参数,默认全0; shape (batch * 16384, 8)
point_box_labels = gt_boxes.new_zeros((points.shape[0], 8)) if ret_box_labels else None
# None
point_part_labels = gt_boxes.new_zeros((points.shape[0], 3)) if ret_part_labels else None
# 逐帧点云数据进行处理
for k in range(batch_size):
# 得到一个mask,用于取出一批数据中属于当前帧的点
bs_mask = (bs_idx == k)
# 取出对应的点shape (16384, 3)
points_single = points[bs_mask][:, 1:4]
# 初始化当前帧中点的类别,默认为0 (16384, )
point_cls_labels_single = point_cls_labels.new_zeros(bs_mask.sum())
"""
points_single : (16384, 3) --> (1, 16384, 3)
gt_boxes : (batch, num_of_GTs, 8) --> (当前帧的GT, num_of_GTs, 8)
box_idxs_of_pts : (16384, ),其中点云分割中背景为-1, 前景点指向GT中的索引,
例如[-1,-1,3,20,-1,0],其中,3,20,0分别指向第0个、第3个和第20个GT
"""
# 计算哪些点在GTbox中, box_idxs_of_pts
box_idxs_of_pts = roiaware_pool3d_utils.points_in_boxes_gpu(
points_single.unsqueeze(dim=0), gt_boxes[k:k + 1, :, 0:7].contiguous()
).long().squeeze(dim=0)
# mask 表明该帧中的哪些点属于前景点,哪些点属于背景点;得到属于前景点的mask
box_fg_flag = (box_idxs_of_pts >= 0)
# 是否忽略在enlarge box中的点 True
if set_ignore_flag:
# 计算哪些点在GTbox_enlarge中
extend_box_idxs_of_pts = roiaware_pool3d_utils.points_in_boxes_gpu(
points_single.unsqueeze(dim=0), extend_gt_boxes[k:k + 1, :, 0:7].contiguous()
).long().squeeze(dim=0)
# 前景点
fg_flag = box_fg_flag
# ^为异或运算符,不同为真,相同为假,这样就可以得到真实GT enlarge后的的点了
ignore_flag = fg_flag ^ (extend_box_idxs_of_pts >= 0)
# 将这些真实GT边上的点设置为-1 loss计算时,不考虑这类点
point_cls_labels_single[ignore_flag] = -1
elif use_ball_constraint:
box_centers = gt_boxes[k][box_idxs_of_pts][:, 0:3].clone()
box_centers[:, 2] += gt_boxes[k][box_idxs_of_pts][:, 5] / 2
ball_flag = ((box_centers - points_single).norm(dim=1) < central_radius)
fg_flag = box_fg_flag & ball_flag
else:
raise NotImplementedError
# [box_idxs_of_pts[fg_flag]]取出所有点中属于前景的点,
# 并为这些点分配对应的GT_box shape (num_of_gt_match_by_points, 8)
# 8个维度分别是x, y, z, l, w, h, heading, class_id
gt_box_of_fg_points = gt_boxes[k][box_idxs_of_pts[fg_flag]]
# 将类别信息赋值给对应的前景点 (16384, )
point_cls_labels_single[fg_flag] = 1 if self.num_class == 1 else gt_box_of_fg_points[:, -1].long()
# 赋值点的类别GT结果到的batch中对应的帧位置
point_cls_labels[bs_mask] = point_cls_labels_single
# 如果该帧中GT的前景点的数量大于0
if ret_box_labels and gt_box_of_fg_points.shape[0] > 0:
# 初始化该帧中box的8个回归参数,并置0
# 此处编码为(Δx, Δy, Δz, dx, dy, dz, cos(heading), sin(heading)) 8个
point_box_labels_single = point_box_labels.new_zeros((bs_mask.sum(), 8))
# 对属于前景点的box进行编码 得到的是 (num_of_fg_points, 8)
# 其中8是(Δx, Δy, Δz, dx, dy, dz, cos(heading), sin(heading))
fg_point_box_labels = self.box_coder.encode_torch(
gt_boxes=gt_box_of_fg_points[:, :-1], points=points_single[fg_flag],
gt_classes=gt_box_of_fg_points[:, -1].long()
)
# 将每个前景点的box信息赋值到该帧中box参数预测中
# fg_point_box_labels: (num_of_GT_matched_by_point,8)
# point_box_labels_single: (16384, 8)
point_box_labels_single[fg_flag] = fg_point_box_labels
# 赋值点的回归编码结果到的batch中对应的帧位置
point_box_labels[bs_mask] = point_box_labels_single
# False
if ret_part_labels:
point_part_labels_single = point_part_labels.new_zeros((bs_mask.sum(), 3))
transformed_points = points_single[fg_flag] - gt_box_of_fg_points[:, 0:3]
transformed_points = common_utils.rotate_points_along_z(
transformed_points.view(-1, 1, 3), -gt_box_of_fg_points[:, 6]
).view(-1, 3)
offset = torch.tensor([0.5, 0.5, 0.5]).view(1, 3).type_as(transformed_points)
point_part_labels_single[fg_flag] = (transformed_points / gt_box_of_fg_points[:, 3:6]) + offset
point_part_labels[bs_mask] = point_part_labels_single
# 将每个点的类别、每个点对应box的7个回归参数放入字典中
targets_dict = {
# 将一个batch中所有点的GT类别结果放入字典中 shape (batch * 16384)
'point_cls_labels': point_cls_labels,
# 将一个batch中所有点的GT_box编码结果放入字典中 shape (batch * 16384) shape (batch * 16384, 8)
'point_box_labels': point_box_labels,
# None
'point_part_labels': point_part_labels
}
return targets_dict其中GTbox和anchor的编码操作中使用了数据集上每个类别的平均长宽高为anchor的大小来完成编码。
这里对角度的编码采用了residual-cos-based,用角度的 torch.cos(rg), torch.sin(rg)来编码GT的heading数值。
代码在:pcdet/utils/box_coder_utils.py
class PointResidualCoder(object):
def __init__(self, code_size=8, use_mean_size=True, **kwargs):
super().__init__()
self.code_size = code_size
self.use_mean_size = use_mean_size
if self.use_mean_size:
self.mean_size = torch.from_numpy(np.array(kwargs['mean_size'])).cuda().float()
assert self.mean_size.min() > 0
def encode_torch(self, gt_boxes, points, gt_classes=None):
"""
Args:
gt_boxes: (N, 7 + C) [x, y, z, dx, dy, dz, heading, ...]
points: (N, 3) [x, y, z]
gt_classes: (N) [1, num_classes]
Returns:
box_coding: (N, 8 + C)
"""
# 每个gt_box的长宽高不得小于 1*10^-5,这里限制了一下
gt_boxes[:, 3:6] = torch.clamp_min(gt_boxes[:, 3:6], min=1e-5)
# 这里指torch.split的第二个参数 torch.split(tensor, split_size, dim=) split_size是切分后每块的大小,
# 不是切分为多少块!,多余的参数使用*cags接收。dim=-1表示切分最后一个维度的参数
xg, yg, zg, dxg, dyg, dzg, rg, *cgs = torch.split(gt_boxes, 1, dim=-1)
# 上面分割的是gt_box的参数,下面分割的是每个点的参数
xa, ya, za = torch.split(points, 1, dim=-1)
# True 这里使用基于数据集求出的每个类别的平均长宽高
if self.use_mean_size:
# 确保GT中的类别数和长宽高计算的类别是一致的
assert gt_classes.max() <= self.mean_size.shape[0]
"""
各类别的平均长宽高
车: [3.9, 1.6, 1.56],
人: [0.8, 0.6, 1.73],
自行车: [1.76, 0.6, 1.73]
"""
# 根据每个点的类别索引,来为每个点生成对应类别的anchor大小 这个anchor来自于数据集中该类别的平均长宽高
point_anchor_size = self.mean_size[gt_classes - 1]
# 分割每个生成的anchor的长宽高
dxa, dya, dza = torch.split(point_anchor_size, 1, dim=-1)
# 计算每个anchor的底面对角线距离
diagonal = torch.sqrt(dxa ** 2 + dya ** 2)
# 计算loss的公式,Δx,Δy,Δz,Δw,Δl,Δh,Δθ
# 以下的编码操作与SECOND、Pointpillars中一样
# 坐标点编码
xt = (xg - xa) / diagonal
yt = (yg - ya) / diagonal
zt = (zg - za) / dza
# 长宽高的编码
dxt = torch.log(dxg / dxa)
dyt = torch.log(dyg / dya)
dzt = torch.log(dzg / dza)
# 角度的编码操作为 torch.cos(rg)、torch.sin(rg) #
else:
xt = (xg - xa)
yt = (yg - ya)
zt = (zg - za)
dxt = torch.log(dxg)
dyt = torch.log(dyg)
dzt = torch.log(dzg)
cts = [g for g in cgs]
# 返回时,对每个GT_box的朝向信息进行了求余弦和正弦的操作
return torch.cat([xt, yt, zt, dxt, dyt, dzt, torch.cos(rg), torch.sin(rg), *cts], dim=-1)得到的结果用于后面loss计算中,计算第一阶段的前背景点分类和前景点的box回归。
targets_dict = {
# 将一个batch中所有点的GT类别结果放入字典中 shape (batch * 16384)
'point_cls_labels': point_cls_labels,
# 将一个batch中所有点的GT_box编码结果放入字典中 shape (batch * 16384) shape (batch * 16384, 8)
'point_box_labels': point_box_labels,
# None
'point_part_labels': point_part_labels
}3.2.3. 第一阶段中的proposal生成
根据point_coords,point_cls_preds和point_box_preds来生成前景点的proposal。
代码在:pcdet/models/dense_heads/point_head_template.py
def generate_predicted_boxes(self, points, point_cls_preds, point_box_preds):
"""
Args:
points: (N, 3) 每个点的实际坐标
point_cls_preds: (N, num_class) 每个点类别的预测结果
point_box_preds: (N, box_code_size) 每个点box的回归结果
Returns:
point_cls_preds: (N, num_class)
point_box_preds: (N, box_code_size)
"""
# 得到所有点预测类别最大值的索引 (batch*16384, 3) --> (batch*16384, )
_, pred_classes = point_cls_preds.max(dim=-1)
# 根据预测的点解码其对应的box
# 第一阶段中 point_box_preds (batch * 16384, 7) 7个特征代表了 x, y, z, l, w, h, Θ
# point_box_preds (batch * 16384, 8) 8个特征代表了 x, y, z, l, w, h, cos(Θ), sin(Θ)##
point_box_preds = self.box_coder.decode_torch(point_box_preds, points, pred_classes + 1)
# 返回所有anchor的预测类别,和对应类别生成的anchor
return point_cls_preds, point_box_predsproposal的解码操作根据在数据集上每个类别的平均长宽高完成解码操作。
在代码在:pcdet/utils/box_coder_utils.py
def decode_torch(self, box_encodings, points, pred_classes=None):
"""
Args:
box_encodings: (N, 8 + C) [x, y, z, dx, dy, dz, cos, sin, ...]
points: [x, y, z]
pred_classes: (N) [1, num_classes]
Returns:
"""
# 这里指torch.split的第二个参数 torch.split(tensor, split_size, dim=) split_size是切分后每块的大小,
# 不是切分为多少块!,多余的参数使用*cags接收。dim=-1表示切分最后一个维度的参数
xt, yt, zt, dxt, dyt, dzt, cost, sint, *cts = torch.split(box_encodings, 1, dim=-1)
# 得到每个点在点云中实际的坐标位置
xa, ya, za = torch.split(points, 1, dim=-1)
# True 这里使用基于数据集求出的每个类别的平均长宽高
if self.use_mean_size:
# 确保GT中的类别数和长宽高计算的类别是一致的
assert pred_classes.max() <= self.mean_size.shape[0]
# 根据每个点的类别索引,来为每个点生成对应类别的anchor大小
point_anchor_size = self.mean_size[pred_classes - 1]
# 分割每个生成的anchor的长宽高
dxa, dya, dza = torch.split(point_anchor_size, 1, dim=-1)
# 计算每个anchor的底面对角线距离
diagonal = torch.sqrt(dxa ** 2 + dya ** 2)
# loss计算中anchor与GT编码的运算:g表示gt,a表示anchor
# ∆x = (x^gt − xa^da)/diagonal --> x^gt = ∆x * diagonal + x^da
# 下同
xg = xt * diagonal + xa
yg = yt * diagonal + ya
zg = zt * dza + za
# ∆l = log(l^gt / l^a)的逆运算 --> l^gt = exp(∆l) * l^a
# 下同
dxg = torch.exp(dxt) * dxa
dyg = torch.exp(dyt) * dya
dzg = torch.exp(dzt) * dza
# 角度的解码操作为 torch.atan2(sint, cost) #
else:
xg = xt + xa
yg = yt + ya
zg = zt + za
dxg, dyg, dzg = torch.split(torch.exp(box_encodings[..., 3:6]), 1, dim=-1)
# 根据sint和cost反解出预测box的角度数值
rg = torch.atan2(sint, cost)
cgs = [t for t in cts]
return torch.cat([xg, yg, zg, dxg, dyg, dzg, rg, *cgs], dim=-1)最终生成的proposal结果是:
# 所有点的类别预测结果 (batch * 16384, 3)
batch_dict['batch_cls_preds'] = point_cls_preds
# 所有点的回归预测结果 (batch * 16384, 7)
batch_dict['batch_box_preds'] = point_box_preds
# 所有点的在batch中的索引 (batch * 16384, )
batch_dict['batch_index'] = batch_dict['point_coords'][:, 0]
# loss计算中,是否需要对类别预测结果进行normalized
batch_dict['cls_preds_normalized'] = False4、点云区域池化(根据proposal选取ROI):
在获得了3DBbox的proposal之后,重点变聚焦在如何优化box的位置和朝向。为了学习到更加细致的proposal特征,PointRCNN中通过池化的方式,将每个proposal中的点的特征和内部的点进行池化操作。
4.1. ROI获取
训练阶段保留类别置信度最高的512个proposal,NMS_thresh为0.8;
测试阶段保留类别置信度最高的100个proposal,NMS_thresh为0.85
注意:
1、NMS都是无类别NMS,不考虑不同类别的物体会出现在3维空间中同一个地方
2、原论文在训练时是300个proposal
3、原论文中使用的是基于BEV视角的oriented IOU,这里是3D IOU
代码在:pcdet/models/roi_heads/roi_head_template.py
def proposal_layer(self, batch_dict, nms_config):
"""
Args:
batch_dict:
batch_size:
batch_cls_preds: (B, num_boxes, num_classes | 1) or (N1+N2+..., num_classes | 1)
batch_box_preds: (B, num_boxes, 7+C) or (N1+N2+..., 7+C)
cls_preds_normalized: indicate whether batch_cls_preds is normalized
batch_index: optional (N1+N2+...)
nms_config:
Returns:
batch_dict:
rois: (B, num_rois, 7+C)
roi_scores: (B, num_rois)
roi_labels: (B, num_rois)
"""
if batch_dict.get('rois', None) is not None:
return batch_dict
# 得到batch_size
batch_size = batch_dict['batch_size']
# 得到每一批数据的box预测结果 shape :(batch * 16384, 7)
batch_box_preds = batch_dict['batch_box_preds']
# 得到每一批数据的cls预测结果 shape :(batch * 16384, 3)
batch_cls_preds = batch_dict['batch_cls_preds']
# 用0初始化所有的rois shape : (batch, 512, 7) 训练时为512个roi,测试时为100个roi
rois = batch_box_preds.new_zeros((batch_size, nms_config.NMS_POST_MAXSIZE, batch_box_preds.shape[-1]))
# 用0初始化所有的roi_score shape : (batch, 512) 训练时为512个roi,测试时为100个roi
roi_scores = batch_box_preds.new_zeros((batch_size, nms_config.NMS_POST_MAXSIZE))
# 用0初始化所有的roi_labels shape : (batch, 512) 训练时为512个roi,测试时为100个roi
roi_labels = batch_box_preds.new_zeros((batch_size, nms_config.NMS_POST_MAXSIZE), dtype=torch.long)
# 逐帧计算rois
for index in range(batch_size):
if batch_dict.get('batch_index', None) is not None:
assert batch_cls_preds.shape.__len__() == 2
# 得到所有属于当前帧点的mask
batch_mask = (batch_dict['batch_index'] == index)
else:
assert batch_dict['batch_cls_preds'].shape.__len__() == 3
batch_mask = index
# 得到当前帧点的box预测结果和对应的cls预测结果 box :(16384, 7); cls :(16384, 3)
box_preds = batch_box_preds[batch_mask]
cls_preds = batch_cls_preds[batch_mask]
# 取出每个点类别预测的最大数值和最大数值所对应的索引 cur_roi_scores: (16384, )
cur_roi_scores, cur_roi_labels = torch.max(cls_preds, dim=1)
if nms_config.MULTI_CLASSES_NMS:
raise NotImplementedError
else:
# 进行无类别的nms操作 selected为经过NMS操作后被留下来的box的索引,selected_scores为被留下来box的最大类别预测分数
selected, selected_scores = class_agnostic_nms(
box_scores=cur_roi_scores, box_preds=box_preds, nms_config=nms_config
)
# 从所有预测结果中选取经过nms操作后得到的box存入roi中
rois[index, :len(selected), :] = box_preds[selected]
# 从所有预测结果中选取经过nms操作后得到的box对应类别分数存入roi中
roi_scores[index, :len(selected)] = cur_roi_scores[selected]
# 从所有预测结果中选取经过nms操作后得到的box对应类别存入roi中
roi_labels[index, :len(selected)] = cur_roi_labels[selected]
# 处理结果,成字典形式并返回
batch_dict['rois'] = rois # 将生成的proposal放入字典中 shape (batch, num_of_roi, 7)
batch_dict['roi_scores'] = roi_scores # 将每个roi对应的类别置信度放入字典中 shape (batch, num_of_roi)
batch_dict['roi_labels'] = roi_labels + 1 # 将每个roi对应的预测类别放入字典中 shape (batch, num_of_roi)
batch_dict['has_class_labels'] = True if batch_cls_preds.shape[-1] > 1 else False # True
batch_dict.pop('batch_index', None)
return batch_dict其中无类别NMS操作代码在:pcdet/models/model_utils/model_nms_utils.py
def class_agnostic_nms(box_scores, box_preds, nms_config, score_thresh=None):
# 1.首先根据置信度阈值过滤掉部过滤掉大部分置信度低的box,加速后面的nms操作
src_box_scores = box_scores
if score_thresh is not None:
# 得到类别预测概率大于score_thresh的mask
scores_mask = (box_scores >= score_thresh)
# 根据mask得到哪些anchor的类别预测大于score_thresh-->anchor类别
box_scores = box_scores[scores_mask]
# 根据mask得到哪些anchor的类别预测大于score_thresh-->anchor回归的7个参数
box_preds = box_preds[scores_mask]
# 初始化空列表,用来存放经过nms后保留下来的anchor
selected = []
# 如果有anchor的类别预测大于score_thresh的话才进行nms,否则返回空
if box_scores.shape[0] > 0:
# 这里只保留最大的K个anchor置信度来进行nms操作,
# k取min(nms_config.NMS_PRE_MAXSIZE, box_scores.shape[0])的最小值
box_scores_nms, indices = torch.topk(box_scores, k=min(nms_config.NMS_PRE_MAXSIZE, box_scores.shape[0]))
# box_scores_nms只是得到了类别的更新结果;
# 此处更新box的预测结果 根据tokK重新选取并从大到小排序的结果 更新boxes的预测
boxes_for_nms = box_preds[indices]
# 调用iou3d_nms_utils的nms_gpu函数进行nms,
# 返回的是被保留下的box的索引,selected_scores = None
# 根据返回索引找出box索引值
keep_idx, selected_scores = getattr(iou3d_nms_utils, nms_config.NMS_TYPE)(
boxes_for_nms[:, 0:7], box_scores_nms, nms_config.NMS_THRESH, **nms_config
)
selected = indices[keep_idx[:nms_config.NMS_POST_MAXSIZE]]
if score_thresh is not None:
# 如果存在置信度阈值,scores_mask是box_scores在src_box_scores中的索引,即原始索引
original_idxs = scores_mask.nonzero().view(-1)
# selected表示的box_scores的选择索引,经过这次索引,
# selected表示的是src_box_scores被选择的box索引
selected = original_idxs[selected]
return selected, src_box_scores[selected]最终得到的结果是:
rois:shape (batch, num_of_roi, 7)包含了每个roi在3D空间的位置和大小
roi_scores:shape (batch, num_of_roi)包含了每个roi置信度分数
roi_labels:shape (batch, num_of_roi)包含了每个roi对应的类别
4.2. ROI与GT的target assignment
4.2.1. ROI采样(样本均衡)
给PointRCNNHead网络进行学习时候,需要完成roi之间的类别均衡。前面提出了512个roi。但是只会采样128个ROI给PointRCNNHead网络进行学习。其中一共要采样3种不同类型的ROI
简单的前景样本:ROI与GT的3D IOU大于0.55(采样64个,不够有多少个用多少个)
简单的背景样本:ROI与GT的3D IOU小于0.1
困难的背景样本:ROI与GT的3D IOU大于0.1小于0.55
注:前景如果采样64个,背景也采样64个;如果前景没有64个,那么采样背景到总共128个ROI。
同时难背景的在所有背景中的采样比为 0.8。 不够用简单背景补充。
代码在:pcdet/models/roi_heads/target_assigner/proposal_target_layer.py
def sample_rois_for_rcnn(self, batch_dict):
"""
Args:
batch_dict:
batch_size:
rois: (B, num_rois, 7 + C)
roi_scores: (B, num_rois)
gt_boxes: (B, N, 7 + C + 1)
roi_labels: (B, num_rois)
Returns:
"""
batch_size = batch_dict['batch_size']
# 第一阶段生成的每个roi的位置和大小 (batch, num_of_roi, 7) 点云坐标系中的 xyzlwhθ
rois = batch_dict['rois']
# 第一阶段预测的每个roi的类别置信度 roi_score (batch, num_of_roi)
roi_scores = batch_dict['roi_scores']
# 第一阶段预测的每个roi的类别 roi_score (batch, num_of_roi)
roi_labels = batch_dict['roi_labels']
# gt_boxes (batch, num_of_GTs, 8) (x, y, z, l, w, h, heading, class)
gt_boxes = batch_dict['gt_boxes']
code_size = rois.shape[-1] # box编码个数:7
# 初始化处理结果的batch矩阵,后续将每帧处理的结果放入此处。batch_rois (batch, 128, 7)
batch_rois = rois.new_zeros(batch_size, self.roi_sampler_cfg.ROI_PER_IMAGE, code_size)
# batch_gt_of_rois (batch, 128, 8)
batch_gt_of_rois = rois.new_zeros(batch_size, self.roi_sampler_cfg.ROI_PER_IMAGE, code_size + 1)
# batch_gt_of_rois (batch, 128)
batch_roi_ious = rois.new_zeros(batch_size, self.roi_sampler_cfg.ROI_PER_IMAGE)
# batch_roi_scores (batch, 128)
batch_roi_scores = rois.new_zeros(batch_size, self.roi_sampler_cfg.ROI_PER_IMAGE)
# batch_roi_labels (batch, 128)
batch_roi_labels = rois.new_zeros((batch_size, self.roi_sampler_cfg.ROI_PER_IMAGE), dtype=torch.long)
# 逐帧处理
for index in range(batch_size):
# 得到当前帧的roi,gt,和对应roi的预测类别和置信度
cur_roi, cur_gt, cur_roi_labels, cur_roi_scores = \
rois[index], gt_boxes[index], roi_labels[index], roi_scores[index]
k = cur_gt.__len__() - 1
# 从GT中取出结果,因为之前GT中以一个batch中最多的GT数量为准,其他不足的帧中,在最后填充0数据。这里消除填充的0数据
while k > 0 and cur_gt[k].sum() == 0:
k -= 1
cur_gt = cur_gt[:k + 1] # (num_of_GTs, 8)
cur_gt = cur_gt.new_zeros((1, cur_gt.shape[1])) if len(cur_gt) == 0 else cur_gt
# 进行iou匹配的时候,只有roi的预测类别与GT相同时才会匹配该区域的roi到该区域的GT上
if self.roi_sampler_cfg.get('SAMPLE_ROI_BY_EACH_CLASS', False):
# 其中max_overlaps包含了每个roi和GT的最大iou数值,gt_assignment得到了每个roi对应的GT索引
max_overlaps, gt_assignment = self.get_max_iou_with_same_class(
rois=cur_roi, roi_labels=cur_roi_labels,
gt_boxes=cur_gt[:, 0:7], gt_labels=cur_gt[:, -1].long()
)
else:
iou3d = iou3d_nms_utils.boxes_iou3d_gpu(cur_roi, cur_gt[:, 0:7]) # (M, N)
max_overlaps, gt_assignment = torch.max(iou3d, dim=1)
# sampled_inds包含了从前景和背景采样的roi的索引
# """此处的背景采样不是意义上的背景,而是那些iou与GT小于0.55的roi,对这些roi进行采样"""
sampled_inds = self.subsample_rois(max_overlaps=max_overlaps)
# 将当前帧中被选取的roi放入batch_rois中 cur_roi[sampled_inds] shape :(len(sampled_inds), 7)
batch_rois[index] = cur_roi[sampled_inds]
# 将当前帧中被选取的roi的类别放入batch_roi_labels中
batch_roi_labels[index] = cur_roi_labels[sampled_inds]
# 将当前帧中被选取的roi与GT的最大iou放入batch_roi_ious中
batch_roi_ious[index] = max_overlaps[sampled_inds]
# 将当前帧中被选取的roi的类别最大预测分数放入batch_roi_scores中
batch_roi_scores[index] = cur_roi_scores[sampled_inds]
# 将当前帧中被选取的roi的GTBox参数放入batch_gt_of_rois shape (batch, 128, 8)
batch_gt_of_rois[index] = cur_gt[gt_assignment[sampled_inds]]
# 返回一帧中选取的roi预测的box参数、roi对应GT的box、roi和GT的最大iou、roi的类别预测置信度、roi的预测类别
return batch_rois, batch_gt_of_rois, batch_roi_ious, batch_roi_scores, batch_roi_labelsself.get_max_iou_with_same_class()函数完成了相同类别直接的最大 IOU匹配。
代码在:pcdet/models/roi_heads/target_assigner/proposal_target_layer.py
def get_max_iou_with_same_class(rois, roi_labels, gt_boxes, gt_labels):
"""
Args:
rois: (N, 7)
roi_labels: (N)
gt_boxes: (N, )
gt_labels:
Returns:
"""
"""
:param rois: (N, 7)
:param roi_labels: (N)
:param gt_boxes: (N, 8)
:return:
"""
# (512, )用于存储所有roi与GT的最大iou数值
max_overlaps = rois.new_zeros(rois.shape[0])
# (512, )用于存储所有roi与GT拥有最大iou的GT索引
gt_assignment = roi_labels.new_zeros(roi_labels.shape[0])
# 逐类别进行匹配操作
for k in range(gt_labels.min().item(), gt_labels.max().item() + 1):
# 取出预测结果属于当前类别的roi mask
roi_mask = (roi_labels == k)
# 得到当前GTs中属于当前类别mask
gt_mask = (gt_labels == k)
# 如果当前的预测结果有该类别并且GTs中也有该类别
if roi_mask.sum() > 0 and gt_mask.sum() > 0:
cur_roi = rois[roi_mask] # 根据mask索引roi中当前处理的类别 shape :(num_of_class_specified_roi, 7)
# 根据mask索引当前GTs中属于当前正在处理的类别 shape :(num_of_class_specified_GT, 7)
cur_gt = gt_boxes[gt_mask]
# 得到GT中属于当前类别的索引 shape :(num_of_class_specified_GT, )
original_gt_assignment = gt_mask.nonzero().view(-1)
# 计算指定类别下 roi和GT之间的3d_iou shape : (num_of_class_specified_roi, num_of_class_specified_GT)
iou3d = iou3d_nms_utils.boxes_iou3d_gpu(cur_roi, cur_gt) # (M, N)
# 取出每个roi与当前GT最大的iou数值和最大iou数值对应的GT索引
cur_max_overlaps, cur_gt_assignment = torch.max(iou3d, dim=1)
# 将该类别最大iou的数值填充进max_overlaps中
max_overlaps[roi_mask] = cur_max_overlaps
# 将该类别roi与GT拥有最大iou的GT索引填充入gt_assignment中
gt_assignment[roi_mask] = original_gt_assignment[cur_gt_assignment]
return max_overlaps, gt_assignmentself.subsample_rois()函数完成了从512个roi中采样出128个roi。
代码在:pcdet/models/roi_heads/target_assigner/proposal_target_layer.py
def subsample_rois(self, max_overlaps):
"""此处的背景采样不是意义上的背景,而是那些iou与GT小于0.55的roi,对这些roi进行采样"""
# sample fg, easy_bg, hard_bg
# 每帧点云中最多有多少个前景roi和属于前景roi的最小thresh
fg_rois_per_image = int(np.round(self.roi_sampler_cfg.FG_RATIO * self.roi_sampler_cfg.ROI_PER_IMAGE))
fg_thresh = min(self.roi_sampler_cfg.REG_FG_THRESH, self.roi_sampler_cfg.CLS_FG_THRESH)
# 从512个roi中,找出其与GT的iou大于fg_thresh的那些roi索引
fg_inds = ((max_overlaps >= fg_thresh)).nonzero().view(-1)
# 将roi中与GT的iou小于0.1定义为简单背景,并得到在roi中属于简单背景的索引
easy_bg_inds = ((max_overlaps < self.roi_sampler_cfg.CLS_BG_THRESH_LO)).nonzero().view(
-1)
# 将roi中与GT的iou大于等于0.1小于0.55的定义为难背景,并得到在roi中属于难背景的索引
hard_bg_inds = (( max_overlaps < self.roi_sampler_cfg.REG_FG_THRESH) &
(max_overlaps >= self.roi_sampler_cfg.CLS_BG_THRESH_LO)).nonzero().view(-1)
# numel就是"number of elements"的简写。numel()可以直接返回int类型的元素个数
fg_num_rois = fg_inds.numel()
bg_num_rois = hard_bg_inds.numel() + easy_bg_inds.numel()
# 如果该帧中,前景的roi大于0,并且背景的roi也大于0
if fg_num_rois > 0 and bg_num_rois > 0:
# sampling fg 采样前景,选取fg_rois_per_image、fg_num_rois的最小数值
fg_rois_per_this_image = min(fg_rois_per_image, fg_num_rois)
# 将所有属于前景点的roi打乱,使用np.random.permutation()函数
rand_num = torch.from_numpy(np.random.permutation(fg_num_rois)).type_as(max_overlaps).long()
# 直接取前N个roi为前景,得到被选取的前景roi在所有roi中的索引
fg_inds = fg_inds[rand_num[:fg_rois_per_this_image]]
# sampling bg
# 背景采样,其中前景采样了64个,背景也采样64个,保持样本均衡,如果不够用负样本填充
bg_rois_per_this_image = self.roi_sampler_cfg.ROI_PER_IMAGE - fg_rois_per_this_image
# 其中self.roi_sampler_cfg.HARD_BG_RATIO控制了所有背景中难、简单背景的比例
bg_inds = self.sample_bg_inds(
hard_bg_inds, easy_bg_inds, bg_rois_per_this_image, self.roi_sampler_cfg.HARD_BG_RATIO
)
elif fg_num_rois > 0 and bg_num_rois == 0:
# sampling fg
rand_num = np.floor(np.random.rand(self.roi_sampler_cfg.ROI_PER_IMAGE) * fg_num_rois)
rand_num = torch.from_numpy(rand_num).type_as(max_overlaps).long()
fg_inds = fg_inds[rand_num]
bg_inds = []
elif bg_num_rois > 0 and fg_num_rois == 0:
# sampling bg
bg_rois_per_this_image = self.roi_sampler_cfg.ROI_PER_IMAGE
bg_inds = self.sample_bg_inds(
hard_bg_inds, easy_bg_inds, bg_rois_per_this_image, self.roi_sampler_cfg.HARD_BG_RATIO
)
else:
print('maxoverlaps:(min=%f, max=%f)' % (max_overlaps.min().item(), max_overlaps.max().item()))
print('ERROR: FG=%d, BG=%d' % (fg_num_rois, bg_num_rois))
raise NotImplementedError
# 将前景roi和背景roi的索引拼接在一起
sampled_inds = torch.cat((fg_inds, bg_inds), dim=0)
return sampled_indsassignment完成可以得到采样后的128个roi和对应的参数,分别是:
roi的box预测参数 batch_rois:(batch, 128, 7)
roi对应GT的box batch_gt_of_rois:(batch, 128, 8) 8为7个回归参数和1个类别
roi和GT的最大iou batch_roi_ious: (batch, 128)
roi的类别预测置信度 batch_roi_scores:(batch, 128)
roi的预测类别 batch_roi_labels:(batch, 128)
4.2.2. loss计算中分类和回归的mask生成
在进行roi和GT的匹配过程中,需要将ROI中与GT的3D IOU大于0.6的roi认为是正样本,3D IOU在0.45到0.6之间的不计算损失,小于0.45的为负样本,供给后面的PointRCNNHead分类头学习。
同时PointRCNNHead中的回归头只学习ROI和GT的3DIOU大于0.55的那部分ROI。
代码在:pcdet/models/roi_heads/target_assigner/proposal_target_layer.py
def forward(self, batch_dict):
"""
Args:
batch_dict:
batch_size:
rois: (B, num_rois, 7 + C)
roi_scores: (B, num_rois)
gt_boxes: (B, N, 7 + C + 1)
roi_labels: (B, num_rois)
Returns:
batch_dict:
rois: (B, M, 7 + C)
gt_of_rois: (B, M, 7 + C)
gt_iou_of_rois: (B, M)
roi_scores: (B, M)
roi_labels: (B, M)
reg_valid_mask: (B, M)
rcnn_cls_labels: (B, M)
"""
# roi的box参数、 roi对应GT的box、 roi和GT的最大iou、 roi的类别预测分数、 roi的预测类别
batch_rois, batch_gt_of_rois, batch_roi_ious, batch_roi_scores, batch_roi_labels = self.sample_rois_for_rcnn(
batch_dict=batch_dict
)
# regression valid mask
# 得到需要计算回归损失的的roi的mask,其中iou大于0.55也就是在self.sample_rois_for_rcnn()中定义为真正属于前景的roi
reg_valid_mask = (batch_roi_ious > self.roi_sampler_cfg.REG_FG_THRESH).long()
# classification label
# 对iou大于0.6的roi进行分类,忽略iou属于0.45到0.6之前的roi
if self.roi_sampler_cfg.CLS_SCORE_TYPE == 'cls':
batch_cls_labels = (batch_roi_ious > self.roi_sampler_cfg.CLS_FG_THRESH).long()
ignore_mask = (batch_roi_ious > self.roi_sampler_cfg.CLS_BG_THRESH) & \
(batch_roi_ious < self.roi_sampler_cfg.CLS_FG_THRESH)
# 将iou属于0.45到0.6之前的roi的类别置-1,不计算loss
batch_cls_labels[ignore_mask > 0] = -1
elif self.roi_sampler_cfg.CLS_SCORE_TYPE == 'roi_iou':
iou_bg_thresh = self.roi_sampler_cfg.CLS_BG_THRESH
iou_fg_thresh = self.roi_sampler_cfg.CLS_FG_THRESH
fg_mask = batch_roi_ious > iou_fg_thresh
bg_mask = batch_roi_ious < iou_bg_thresh
interval_mask = (fg_mask == 0) & (bg_mask == 0)
batch_cls_labels = (fg_mask > 0).float()
batch_cls_labels[interval_mask] = \
(batch_roi_ious[interval_mask] - iou_bg_thresh) / (iou_fg_thresh - iou_bg_thresh)
else:
raise NotImplementedError
"""
'rois': batch_rois, roi的box的7个参数 shape(batch, 128, 7)
'gt_of_rois': batch_gt_of_rois, roi对应的GTbox的8个参数,包含类别 shape(batch, 128, 8)
'gt_iou_of_rois': batch_roi_ious, roi个对应GTbox的最大iou数值 shape(batch, 128)
'roi_scores': batch_roi_scores, roi box的类别预测分数 shape(batch, 128)
'roi_labels': batch_roi_labels, roi box的类别预测结果 shape(batch, 128)
'reg_valid_mask': reg_valid_mask, 需要计算回归损失的roi shape(batch, 128)
'rcnn_cls_labels': batch_cls_labels 需要计算分类损失的roi shape(batch, 128)
"""
targets_dict = {'rois': batch_rois, 'gt_of_rois': batch_gt_of_rois, 'gt_iou_of_rois': batch_roi_ious,
'roi_scores': batch_roi_scores, 'roi_labels': batch_roi_labels,
'reg_valid_mask': reg_valid_mask,
'rcnn_cls_labels': batch_cls_labels}
return targets_dict最终得到的结果是:
'rois': roi的box的7个预测参数 shape(batch, 128, 7) 'gt_of_rois': roi对应的GTbox的8个参数,包含类别 shape(batch, 128, 8) 'gt_iou_of_rois': roi个对应GTbox的最大iou数值 shape(batch, 128) 'roi_scores': roi box的类别预测分数 shape(batch, 128) 'roi_labels': roi box的类别预测结果 shape(batch, 128) 'reg_valid_mask': 需要计算回归损失的roi mask shape(batch, 128) 'rcnn_cls_labels': 需要计算分类损失的roi mask shape(batch, 128)
4.2.3. target转换到CCS坐标系(Canonical Coordinate System)
PointRCNNHead对proposal的box精调是在CCS坐标系中进行的,而刚刚被选中的的ROI对应的GT target是在OpenPCDet的点云坐标系中,因此需要将GT Box变换到每个ROI自身的CCS坐标系中,坐标系变换包括了坐标系的平移和旋转。
同时这里在变换坐标系时候,需要注意,如果一个ROI和对应的GT的IOU大于0.55,那么这两个box的角度偏差只会在正负45度内。
代码在:pcdet/models/roi_heads/roi_head_template.py
def assign_targets(self, batch_dict):
# 从字典中取出当前batch-size大小
batch_size = batch_dict['batch_size']
# with torch.no_grad():,强制之后的内容不进行计算图构建。
with torch.no_grad():
"""
targets_dict={
'rois': batch_rois, roi的box的7个参数 shape(batch, 128, 7)
'gt_of_rois': batch_gt_of_rois, roi对应的GTbox的8个参数,包含类别 shape(batch, 128, 8)
'gt_iou_of_rois': batch_roi_ious, roi个对应GTbox的最大iou数值 shape(batch, 128)
'roi_scores': batch_roi_scores, roi box的类别预测分数 shape(batch, 128)
'roi_labels': batch_roi_labels, roi box的类别预测结果 shape(batch, 128)
'reg_valid_mask': reg_valid_mask, 需要计算回归损失的roi shape(batch, 128)
'rcnn_cls_labels': batch_cls_labels 计算前背景损失的roi shape(batch, 128)
}
"""
targets_dict = self.proposal_target_layer.forward(batch_dict)
rois = targets_dict['rois'] # (B, 128, 7)
gt_of_rois = targets_dict['gt_of_rois'] # (B, 128, 7 + 1)
# 从计算图中拿出来gt_of_rois并放入targets_dict
targets_dict['gt_of_rois_src'] = gt_of_rois.clone().detach()
# 进行canonical transformation变换,需要roi的xyz在点云中的坐标位置转换到以自身中心为原点
roi_center = rois[:, :, 0:3]
# 将heading的数值,由-pi-pi转到0-2pi中 弧度
roi_ry = rois[:, :, 6] % (2 * np.pi)
# 计算在经过canonical transformation变换后GT相对于以roi中心的x,y,z偏移量
gt_of_rois[:, :, 0:3] = gt_of_rois[:, :, 0:3] - roi_center
# 计算GT和roi的heading偏移量
gt_of_rois[:, :, 6] = gt_of_rois[:, :, 6] - roi_ry
# transfer LiDAR coords to local coords
# 上面完成了点云坐标系中的GT到roi坐标系的xyz方向的偏移,下面完成点云坐标系中的GT到roi坐标系的角度旋转,
# 其中点云坐标系,x向前,y向右,z向上;roi坐标系中,x朝车头方向,y与x垂直,z向上
gt_of_rois = common_utils.rotate_points_along_z(
points=gt_of_rois.view(-1, 1, gt_of_rois.shape[-1]), angle=-roi_ry.view(-1)
).view(batch_size, -1, gt_of_rois.shape[-1])
# flip orientation if rois have opposite orientation
heading_label = gt_of_rois[:, :, 6] % (2 * np.pi) # 0 ~ 2pi
opposite_flag = (heading_label > np.pi * 0.5) & (heading_label < np.pi * 1.5)
heading_label[opposite_flag] = (heading_label[opposite_flag] + np.pi) % (2 * np.pi) # (0 ~ pi/2, 3pi/2 ~ 2pi)
flag = heading_label > np.pi
heading_label[flag] = heading_label[flag] - np.pi * 2 # (-pi/2, pi/2)
# 在3D的iou计算中,如果两个box的iou大于0.55,那么他们的角度偏差只会在-45度到45度之间
heading_label = torch.clamp(heading_label, min=-np.pi / 2, max=np.pi / 2)
gt_of_rois[:, :, 6] = heading_label
targets_dict['gt_of_rois'] = gt_of_rois
return targets_dict
5. Canonical 3D建议框精调网络(PointRCNNHead):
5.1. ROI POOL
根据前面提出的proposal,为了学习细致的学习每个proposal的特征信息,并更好的优化box的回归精确度;PointRCNN将每个proposal中的3D点和这些点在经过PointNet++后对应的特征进行池化操作后并转换到CCS坐标系下进行学习。参考原文:(Using the proposed canonical coordinate system enables the box refinement stage to learn better local spatial features for each proposal)
ROI POOL前融合:
1、在对proposal进行池化的过程中,由于转换到了以每个roi自己中心做原点,那么不可避免的就损失了该点在点云中的深度信息,因此在池化之前,先为每个点加上了自己的深度信息(文中用该点在点云中的欧氏距离来完成):
![]()
![]()
2、同时还为每个点的特征加上了该点最大的类别预测置信度。来组成每个点自身的新特征。
因此得到的点的特征维度是(batch , 16384, 128+Depth+CLS_SCORE)128为每个点经过PointNet++输出的特征维度
ROI POOL融合:
1、ROI的融合过程中还在点的特征上拼接点的坐标位置:(batch , 16384, xyz+128+Depth+CLS_SCORE)
2、为每个点的特征融合该点自身的雷达反射率(reflection intensity)
3、扩大每个proposal,并将扩大后才有的点也一起进行ROI POOL操作
注:1、上述的2、3操作在OpenPCDet的实现中都没有,此处不再关注这点。
2、对于那些内部没有点的proposal,特征置0。
ROI POOL的采样点为512个,最终生成的特征为:(bacth * num_of_roi, num_sampled_points, xyz+Depth+CLS_SCORE+128)
代码在:pcdet/models/roi_heads/pointrcnn_head.py
def roipool3d_gpu(self, batch_dict):
"""
Args:
batch_dict:
batch_size:
rois: (B, num_rois, 7 + C)
point_coords: (num_points, 4) [bs_idx, x, y, z]
point_features: (num_points, C)
point_cls_scores: (N1 + N2 + N3 + ..., 1)
point_part_offset: (N1 + N2 + N3 + ..., 3)
Returns:
"""
# batch_size
batch_size = batch_dict['batch_size']
# 得到每个点云属于batch中哪一帧的mask (batch*2, )
batch_idx = batch_dict['point_coords'][:, 0]
# 得到每个点云在激光雷达中的坐标 (batch * 16384, 3)
point_coords = batch_dict['point_coords'][:, 1:4]
# 得到每个点在第一个子网络的特征数据(PointNet++)输出的结果 (batch * 16384, 128)
point_features = batch_dict['point_features']
# 得到生成的rois, (batch, num_rois, 7) num_rois训练为128,测试为100
rois = batch_dict['rois'] # (B, num_rois, 7 + C)
# 该参数用来存储一个batch中每帧点云中有多少个点,并用于匹配一批数据中每帧点的数量是否一致
batch_cnt = point_coords.new_zeros(batch_size).int()
# 确保一批数据中点的数量一样
for bs_idx in range(batch_size):
batch_cnt[bs_idx] = (batch_idx == bs_idx).sum()
assert batch_cnt.min() == batch_cnt.max()
# 得到每个点类别预测分数 (batch*2, ),并从计算图中拿出来
point_scores = batch_dict['point_cls_scores'].detach()
# 计算雷达坐标系下每个点到原点的距离,这里采用了L2范数(欧氏距离)来计算 (batch*2, )
point_depths = point_coords.norm(dim=1) / self.model_cfg.ROI_POINT_POOL.DEPTH_NORMALIZER - 0.5
# 点云中每个点在此处融合了,点的预测分数,每个点的深度信息,和每个点经过PointNet++得到的特征数据
point_features_list = [point_scores[:, None], point_depths[:, None], point_features]
# shape (batch * 16384, 130)将所有的这个特征在最后一个维度拼接在一起
point_features_all = torch.cat(point_features_list, dim=1)
# 每个点在点云中的的坐标 shape (batch * 16384, 3) --> (batch , 16384, 3)
batch_points = point_coords.view(batch_size, -1, 3)
# shape (batch * 16384, 130)--> (batch , 16384, 130)
batch_point_features = point_features_all.view(batch_size, -1, point_features_all.shape[-1])
# 不保存计算图 根据生成的proposal来池化每个roi内的特征
with torch.no_grad():
# pooled_features为(batch, num_of_roi, num_sample_points, 3 + C)
# pooled_empty_flag:(B, num_rois)反映哪些proposal中没有点在其中
pooled_features, pooled_empty_flag = self.roipoint_pool3d_layer(
batch_points, batch_point_features, rois
)
# canonical transformation (batch, num_of_roi, 3)
roi_center = rois[:, :, 0:3]
# 池化后的proposal转换到以自身ROI中心为坐标系
# (batch, num_rois, num_sampled_points, 3 + C = 133)
pooled_features[:, :, :, 0:3] -= roi_center.unsqueeze(dim=2)
# (batch, num_rois, num_sampled_points, 133) --> (batch * num_rois, num_sampled_points, 133)
pooled_features = pooled_features.view(-1, pooled_features.shape[-2], pooled_features.shape[-1])
# 上面完成平移操作后,下面完成旋转操作,使x方向朝向车头方向,y垂直于x,z向上
# (openpcdet中,x向前,y向左,z向上,x到y逆时针为正)
pooled_features[:, :, 0:3] = common_utils.rotate_points_along_z(
pooled_features[:, :, 0:3], -rois.view(-1, rois.shape[-1])[:, 6]
)
# 将proposal池化后没有点在内的proposal置0
pooled_features[pooled_empty_flag.view(-1) > 0] = 0
return pooled_features5.2. ROI精调网络
5.2.1. 特征融合
得到的pooled_features的特征为:
(bacth * num_of_roi, num_sampled_points, xyz+Depth+CLS_SCORE+128)
其中xyz,Depth,CLS_SCORE这几个都属于Local Spatial Point,128是PointNet++输出的点云语义特征。
将Local Spatial Point特征进行Canonical Transformation后进行两层的MLP操作提升维度到128维(MLP维度变换 5->128,128->128),后再与点的语义特征进行拼接,得到的特征维度变为:
(bacth * num_of_roi, 256, num_sampled_points, 1)。
之后要让拼接后的特征输入的维度信息与语义特征信息一致。再使用一个MLP操作变换维度到128即可。
注:维度变换此处都是用1*1的卷积完成。
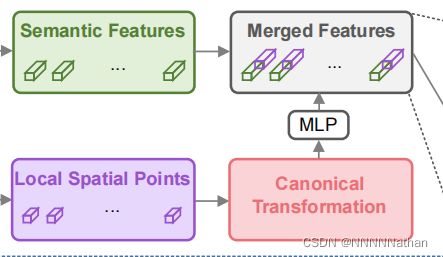
经过将局部特征和点的全局的语义特征进行融合,可以获得一个有鉴别特征向量,用于之后网络来优化roi的置信度分类和box refinement。
5.2.2. proposal refine network
对每个ROI中点的特征进行优化,直接使用了一个SSG的PointNet++网络。其中包含3个SA层。每层的group size为 128, 32, 1。并最终用最高维特征来优化该ROI的confidence classification和proposal location refinement。
def forward(self, batch_dict):
"""
Args:
batch_dict:
Returns:
"""
# 生成proposal;在训练时,NMS保留512个结果,NMS_thresh为0.8;在测试时,NMS保留100个结果,NMS_thresh为0.85
targets_dict = self.proposal_layer(
batch_dict, nms_config=self.model_cfg.NMS_CONFIG['TRAIN' if self.training else 'TEST']
)
# 在训练模式时,需要为每个生成的proposal匹配到与之对应的GT_box
if self.training:
targets_dict = self.assign_targets(batch_dict)
batch_dict['rois'] = targets_dict['rois']
batch_dict['roi_labels'] = targets_dict['roi_labels']
# (bacth * num_of_roi, num_sampled_points, 133) num_sampled_points:512
pooled_features = self.roipool3d_gpu(batch_dict) # (total_rois, num_sampled_points, 3 + C)
# (bacth * num_of_roi, 5, num_sampled_points, 1)
xyz_input = pooled_features[..., 0:self.num_prefix_channels].transpose(1, 2).unsqueeze(dim=3).contiguous()
# (bacth * num_of_roi, 128, num_sampled_points, 1) 完成canonical transformation后的mlp操作
xyz_features = self.xyz_up_layer(xyz_input)
# (bacth * num_of_roi, 128, num_sampled_points, 1)
point_features = pooled_features[..., self.num_prefix_channels:].transpose(1, 2).unsqueeze(dim=3)
# (bacth * num_of_roi, 256, num_sampled_points, 1) 将池化特征和点的特征进行拼接(Merged Features)
merged_features = torch.cat((xyz_features, point_features), dim=1)
# (bacth * num_of_roi, 128, num_sampled_points, 1) # 将拼接的特征放回输入之前的大小 channel : 256->128
merged_features = self.merge_down_layer(merged_features)
# 同之前的SA操作 进入Point Cloud Encoder
l_xyz, l_features = [pooled_features[..., 0:3].contiguous()], [merged_features.squeeze(dim=3).contiguous()]
for i in range(len(self.SA_modules)):
li_xyz, li_features = self.SA_modules[i](l_xyz[i], l_features[i])
l_xyz.append(li_xyz)
l_features.append(li_features)
# (total_rois, num_features, 1)
shared_features = l_features[-1]
# (total_rois, num_features, 1) --> (total_rois, 1)
rcnn_cls = self.cls_layers(shared_features).transpose(1, 2).contiguous().squeeze(dim=1) # (B, 1 or 2)
# (total_rois, num_features, 1) --> (total_rois, 7)
rcnn_reg = self.reg_layers(shared_features).transpose(1, 2).contiguous().squeeze(dim=1) # (B, C)
if not self.training:
batch_cls_preds, batch_box_preds = self.generate_predicted_boxes(
batch_size=batch_dict['batch_size'], rois=batch_dict['rois'], cls_preds=rcnn_cls, box_preds=rcnn_reg
)
batch_dict['batch_cls_preds'] = batch_cls_preds
batch_dict['batch_box_preds'] = batch_box_preds
batch_dict['cls_preds_normalized'] = False
else:
targets_dict['rcnn_cls'] = rcnn_cls
targets_dict['rcnn_reg'] = rcnn_reg
self.forward_ret_dict = targets_dict
return batch_dict到此为止,已经完成了PointRCNN网络的搭建和第一、第二阶段的box与GT的target assignment。对于loss计算和网络的推理内容,可以看我的这篇文章:
https://blog.csdn.net/qq_41366026/article/details/123275480https://blog.csdn.net/qq_41366026/article/details/123275480
参考文献或者文章:
1、【3D目标检测】PointRCNN深度解读 - 知乎
2、论文阅读-PointRCNN+python3.5实现_有所为,有所成长-CSDN博客_pointrcnn代码
3、https://arxiv.org/abs/1812.04244
4、The KITTI Vision Benchmark Suite
5、GitHub - open-mmlab/OpenPCDet: OpenPCDet Toolbox for LiDAR-based 3D Object Detection.