【3D目标检测】PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud
文章目录
- 前言
-
- 摘要
- 1. 介绍
- 2. PointRCNN算法框架
-
- 2.1 Bottom-up 3D proposal generation via point cloud segmentation
- 2.2 Point cloud region pooling
- 2.3 Canonical 3D bounding box refinement
- 3. 实验细节
- 4. 实验结果
- 5. 总结
前言
1. 为什么要做这个研究?
之前的方法做3D目标检测通常都是将点云投影到BEV视图或者正面图,又或者投射到体素中,效率比较低下。
2. 实验方法是什么样的?
PointRCNN分为两个阶段:
Stage-1:
- 通过PointNet++提取全局点云的特征;
- 进行前景分割(使用Focus Loss),并从前景点回归粗粒度的bounding box;
- 在bounding box的生成中,使用bin-based方法回归损失估计bounding box的中心点;
- bin-based方法是对每个前景点都以其为原点构建X-Z坐标系,预测bounding box中心点在哪一个bin里面,再对其进行精确地残差回归。
- 基于BEV图做NMS去除冗余的bounding box,训练阶段只保留300个进入stage-2。
Stage-2:
- 扩大Stage-1输入的bounding box,保留扩大框中的点和特征;
- 将每个bounding box通过正交变换转到以自身中心为原点的local坐标系,以便更好地学习bounding box中的局部空间信息;
- 使用PointNet++的SA module提取特征,得到最后每个点的特征向量,进行置信分类和box微调;
- 同样使用bin-based方法进行proposal回归。
3. 创新与不足
- 第一个只使用原始点云的two-stage anchor free 3D目标检测模型;
- 通过语义分割获取前景点并回归proposal,避免了在整个3D空间搜索proposal;
- 使用bin-based回归loss,提高了网络的收敛速度和准确率;
- 对每个proposal使用正交转换,这样box微调阶段可以更好地学习局部空间特征;
- 不足: 大规模点云上使用PointNet++比较慢。
摘要
PointRCNN是一个用于原始点云的3D目标检测模型,整个框架由两个阶段组成:stage-1为自底向上的3D候选框生成阶段,stage-2在规范坐标下微调proposal获得最终的检测结果。不同于之前的通过RGB图像生成候选框或者将点云投射到BEV图或体素上,PointRCNN的stage-1通过将整个场景的点云分割成前景点和背景点,以自下而上地方式从点云中生成少量高质量的3D候选框。Stage-2将每个候选框的池化点转换到正交坐标系,更好地学习局部空间特征,并与stage-1学习的每个点的全局语义特征相结合,实现Box优化和置信度预测。在KITTI数据集的3D检测基准实验中表明,PointRCNN仅使用点云作为输入,结果SOTA。
论文链接:https://arxiv.org/abs/1812.04244
代码链接:https://github.com/sshaoshuai/PointRCNN
1. 介绍
由于3D目标的不规则数据格式和6自由度(DoF)搜索空间大,利用点云检测3D目标仍然面临巨大挑战。之前的方法或是将点云投影到BEV视图、正面视图,或是投射到规则的3D voxel中,而PointRCNN直接从原始点云自下而上地生成3D候选框。
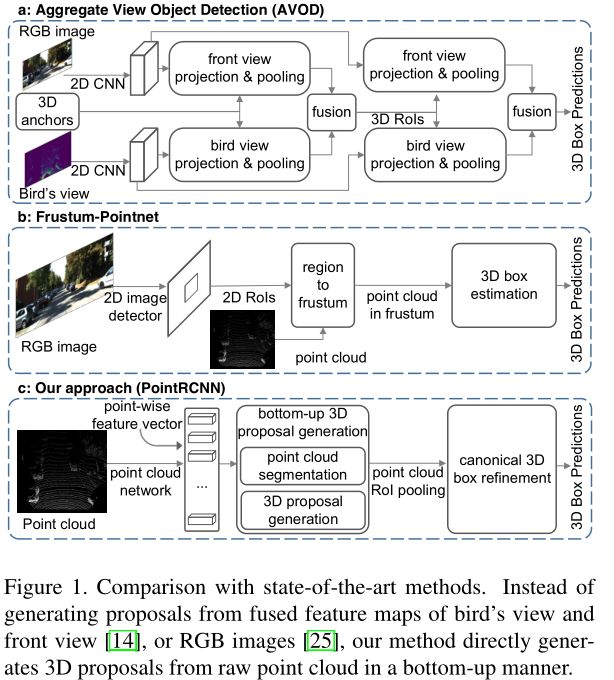
不同于2D图像,用于3D目标检测的训练数据直接为3D目标分割提供了语义掩码。基于此观测结果,PointRCNN在stage-1自下而上地生成3D候选框,利用3D bounding box 生成 ground-truth 分割掩模。Stage-1对前景点进行分割,并从分割点同时生成少量的候选框。该策略避免了以往方法在整个3D空间中使用大量的3D锚盒,节省了计算量。
Stage-2进行规范3D box改进,生成3D候选框后,采用点云区域池化操作将stage-1中学习到的点表示进行池化。与现有的直接估计全局盒坐标的3D方法不同,合并后的3D点被转x换为规范坐标,并与合并后的点特征以及stage-1的分割掩码相结合,学习相对坐标细化。提出了基于全箱的3D box回归损耗来生成和细化候选框。
贡献:
- 提出了一种新颖的自底向上的基于点云3D候选框生成算法,该算法将点云分割为前景对象和背景,生成少量高质量的3D候选框。从分割中学习到的点表示不仅善于生成候选框,而且对后续的box优化也有帮助。
- 提出的规范3D边界框利用了stage-1生成的高召回盒提案,并在带有高鲁棒性的基于区域的损失的规范坐标中学习优化框坐标。
- PointRCNN仅使用点云作为输入。
2. PointRCNN算法框架
2.1 Bottom-up 3D proposal generation via point cloud segmentation
2D目标检测算法中,one-stage方法通常更快,直接估计目标的边界框而没有微调;two-stage方法在第二阶段微调proposals和confidence。然而,由于3D搜索空间非常大和点云的不规则格式,直接将two-stage方法从2D拓展到3D不太合适。
AVOD在3D空间放置80-100k个anchor boxes,并在多个视图中对每个anchor池化特征生成proposals。
FPointNet从2D图像中生成2D proposals,并根据从2D区域裁剪出来的3D点估计3D boxes,但这样可能会漏掉只能从3D空间清晰观察到的物体。
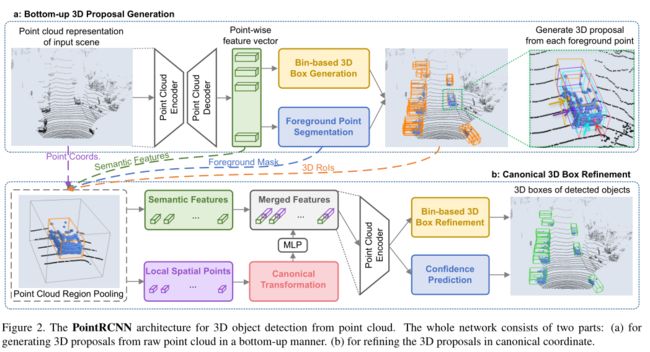
作者提出了基于全场景点云分割的3D proposals生成算法。在3D场景中,物体是自然分开的,相互没有重叠。所有3D物体的分割掩码都可以通过其3D边界框注释直接获得,即将3D框内的3D点视为前景点。该算法逐点学习特征分割原始点云,并从分割好的前景点中生成3D proposals,这样就避免了在3D空间中使用大量预定义的3D boxes,极大地限制了3D proposals生成的搜索空间,提高召回率。
Learning point cloud representations
使用多尺度分组的PointNet++作为骨干网络,也可以选择VoxelNet。
Foreground point segmentation
同时进行前景分割和3D proposals生成,考虑到主干点云网络编码的逐点特征,添加了一个用于估计前景掩码的分割头和一个用于生成3D proposals的box回归头。对于点云分割,ground-truth分割掩模由3D ground-truth box提供。对于大型户外场景,前景点的数量通常比背景点的数量要小得多。因此,作者使用焦点损失来处理类不平衡问题。焦点损失减少了简单示例的损失贡献,并加强了对纠正错误分类示例的重视。
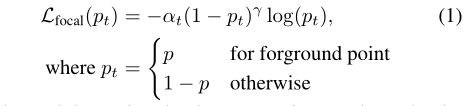
训练点云分割时,默认设置 α = 0.25 , γ = 2 \alpha=0.25, \gamma=2 α=0.25,γ=2。
Bin-based 3D bounding box generation
之前已经分割出前景点了,box回归头直接从前景点回归3D proposals位置。尽管没有从背景点回归box,但由于点云网络的感受野,这些背景点也为生成box提供了支持信息。
3D边界框在LiDAR坐标系中表示为 ( x , y , z , h , w , l , θ ) (x,y,z,h,w,l,\theta) (x,y,z,h,w,l,θ),其中(x,y,z)为物体中心位置,(h,w,l)为物体大小, θ \theta θ为物体从鸟瞰角度的方向,也就是偏航角。针对proposals中心点的定位,作者提出了bin-based方法。

对于每一个分割出的前景点,都对其X-Z坐标系构建一个网格,单方向搜索范围为S,每一格等长为 δ \delta δ,这样就可以初步预测中心点在哪一个bin里面,再对其进行精确地残差回归。Y轴由于比较扁平,因此可以直接使用smooth L1 loss回归。

( x ( p ) , y ( p ) , z ( p ) ) (x^{(p)},y^{(p)},z^{(p)}) (x(p),y(p),z(p))是感兴趣的前景点的坐标;
( x p , y p , z p ) (x^p,y^p,z^p) (xp,yp,zp)对应物体的中心坐标;
b i n x ( p ) , b i n z ( p ) bin_x^{(p)},bin_z^{(p)} binx(p),binz(p)是X、Z轴上的ground-truth bin;
r e s x ( p ) , r e s z ( p ) res_x^{(p)},res_z^{(p)} resx(p),resz(p)是在被分配的bin中做进一步定位微调的ground-truth残差;
C是归一化的bin长度。
训练及损失函数
在实验过程中,对于基于bin的预测参数 x、z、 θ \theta θ,首先选择置信度最高的bin中心点,再使用smooth L1 loss回归长宽高和y值。在训练时,采用0.85 IoU的NMS去除BEV图上的proposals,只保留前300进入stage-2的模型(测试的时候只保留前100)。
不同的训练损失项下的整个3D边界框的回归损失 L r e g L_{reg} Lreg可表示为:
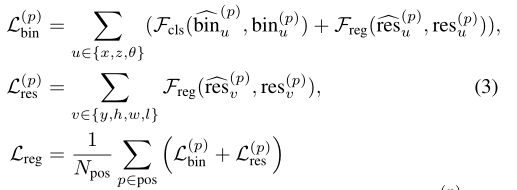
N p o s N_{pos} Npos是前景点的数量;
b i n u ^ ( p ) , r e s u ^ ( p ) \widehat{bin_u}^{(p)},\widehat{res_u}^{(p)} binu (p),resu (p)是前景点p的被预测的bin分配和残差;
b i n u ( p ) , r e s u ( p ) bin_u^{(p)},res_u^{(p)} binu(p),resu(p)是上面已经计算过的ground-truth对象;
F c l s F_{cls} Fcls是分类的交叉熵损失;
F r e g F_{reg} Freg是smooth L1 loss。
2.2 Point cloud region pooling
扩大3D proposals
对于每个3D proposals, 放大一定的大小得到一个新的3D框,获取更多的context信息。
b i = ( x i , y i , z i , h i , w i , l i , θ i ) b_i=(x_i,y_i,z_i,h_i,w_i,l_i,\theta_i) bi=(xi,yi,zi,hi,wi,li,θi)
to b i e = ( x i , y i , z i , h i + η , w i + η , l i + η , θ i ) b^e_i=(x_i,y_i,z_i,h_i+\eta,w_i+\eta,l_i+\eta,\theta_i) bie=(xi,yi,zi,hi+η,wi+η,li+η,θi)
η \eta η是一个用来放大box的大小的固定值。
判断点是否在扩大的边界框内
对于每个点p,若在扩大框内,则该点及其特征会被保留用来微调 b i b_i bi。
内部点p的特征包括:3D坐标 ( x ( p ) , y ( p ) , z ( p ) ) ∈ R 3 (x^{(p)},y^{(p)},z^{(p)}) \in \R^3 (x(p),y(p),z(p))∈R3、激光反射强度 r ( p ) ∈ R 3 r^{(p)}\in\R^3 r(p)∈R3,来自stage-1的预测分割掩码 m ( p ) ∈ { 0 , 1 } m^{(p)}\in\{0,1\} m(p)∈{0,1}和点特征表示 f ( p ) ∈ R c f^{(p)}\in\R^c f(p)∈Rc。
通过分割掩码 m ( p ) m^{(p)} m(p)来区分扩大框中的是前景点还是背景点,点特征 f ( p ) f^{(p)} f(p)用于分割和生成proposals,然后消除没有内部点的proposals。
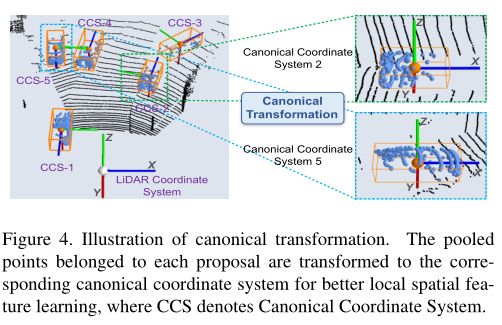
2.3 Canonical 3D bounding box refinement
如图2所示,每个proposal的池化点及其特征都被喂入stage-2中,用来微调3D框的位置及其前景目标置信度。
Canonical transformation(正交变换)
利用正交变换转换到每个proposal的local坐标系,一个3D proposal的正交坐标系表示:
- 坐标系的中心点是proposal的center;
- X ′ , Z ′ X^{'},Z^{'} X′,Z′轴平行于地平面, X ′ X^{'} X′轴指向proposals的heading方向, Z ′ Z^{'} Z′轴垂直于 X ′ X^{'} X′轴;
- Y ′ Y^{'} Y′轴与LiDAR坐标系保持一致;
proposal内的点p都从原来的坐标转换为local坐标系 p ~ \tilde{p} p~,这样box优化阶段可以更好地学习每个proposal的局部空间特征,学习的方法同stage-1一样,也是利用PointNet++的结构结合bin-based的方式,把回归问题转换为分类问题。
Feature learning for box proposal refinement
微调子网络的组成
微调子网络结合了已转换的局部空间点特征 p ~ \tilde{p} p~及其来自stage-1的全局语义特征 f ( p ) f^{(p)} f(p)。
正则变换的缺陷和解决方法
正则变换能够实现鲁棒的局部空间特征学习,但会丢失每个对象的深度信息。例如,由于LiDAR传感器扫描的时候,远处的物体通常比附近的物体拥有更少的点。为了补偿深度信息的丢失,将到传感器的距离 d ( p ) = ( x ( p ) ) 2 + ( y ( p ) ) 2 + ( z ( p ) ) 2 d^{(p)}=\sqrt{(x^{(p)})^2+(y^{(p)})^2+(z^{(p)})^2} d(p)=(x(p))2+(y(p))2+(z(p))2纳入点p的特征中。
微调方法
对于每个proposal,首先将其关联点的局部空间特征 p ~ \tilde{p} p~和额外特征 [ r ( p ) , m ( p ) , d ( p ) ] [r^{(p)}, m^{(p)},d^{(p)}] [r(p),m(p),d(p)]concate后经过几个全连接层,将它们的局部特征编码为与stage-1得到的全局特征 f ( p ) f^{(p)} f(p)相同的维数。然后将局部特征和全局特征concate起来,用PointNet++的SA module提取特征,得到最后每个点的特征向量,进行置信分类和box微调。
Losses for box proposal refinement
采用类似stage-1的bin-based方法来优化proposal。如果gt box和proposal的IoU>0.55,则将该gt box分配给3D box proposal来学习box微调。
3D proposals和相应的3D gt box都被转换成正交坐标系,因此,
3D proposal: b i = ( x i , y i , z i , h i , w i , l i , θ i ) b_i=(x_i,y_i,z_i,h_i,w_i,l_i,\theta_i) bi=(xi,yi,zi,hi,wi,li,θi)
to b ~ i = ( 0 , 0 , 0 , h i , w i , l i , 0 ) \tilde{b}_i=(0,0,0,h_i,w_i,l_i,0) b~i=(0,0,0,hi,wi,li,0);
3D ground-truth box: b i g t = ( x i g t , y i g t , z i g t , h i g t , w i g t , l i g t , θ i g t ) b_i^{gt}=(x_i^{gt},y_i^{gt},z_i^{gt},h_i^{gt},w_i^{gt},l_i^{gt},\theta_i^{gt}) bigt=(xigt,yigt,zigt,higt,wigt,ligt,θigt)
to b ~ i g t = ( x i g t − x i , y i g t − y i , z i g t − z i , h i g t , w i g t , l i g t , θ i g t − θ i ) \tilde{b}_i^{gt}=(x_i^{gt} - x_i,y_i^{gt}- y_i,z_i^{gt}- z_i,h_i^{gt},w_i^{gt},l_i^{gt},\theta_i^{gt}-\theta_i) b~igt=(xigt−xi,yigt−yi,zigt−zi,higt,wigt,ligt,θigt−θi)。
Stage-2的loss整体为:
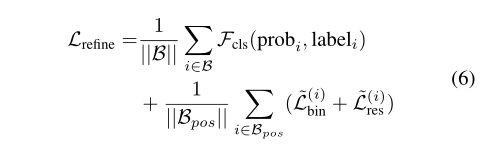
B B B是来自stage-1的3D proposals集合;
B p o s B_{pos} Bpos存放了positive的回归proposals;
p r o b i prob_i probi是估算的 b i ~ \tilde{b_i} bi~的置信度;
l a b e l i label_i labeli是对应的label;
L ~ b i n ( i ) , L ~ r e s ( i ) \tilde{L}_{bin}^{(i)},\tilde{L}_{res}^{(i)} L~bin(i),L~res(i)和公式3相似,但是用的是上面提到的通过 b ~ i g t , b i ~ \tilde{b}_i^{gt},\tilde{b_i} b~igt,bi~计算的新结果。
最后,通过BEV视图上NMS IoU>0.01去除重叠的proposal。
3. 实验细节
网络结构
Stage-1的输入是16384个点,采用PointNet++,经过4次SA层(多尺度分组)提取特征,采样个数为[4096, 1024, 256, 64],然后经过4次FP层获得逐点特征向量进行分割和proposal生成;
Stage-2的输入是每个proposal的合并区域随机抽取的512个点,采用3次SA(单尺度分组),采样个数为[128, 32, 1],生成单个特征向量,用于目标置信度分类和proposal位置优化。
Stage-1(car)
- 选择ROI(Region of Interest)的时候在原前景分割的基础上向外扩0.2m;
- bin-based的中心点预测时,单方向搜索范围S=3m,箱子大小 δ \delta δ=0.5m;
- 偏航角预测n=12;
- epoch=200,batch size=16,learning rate=0.002。
Stage-2(car)
- Box置信度的输出:IoU>0.6为正例,IoU<0.45为负例;
- 角回归的输出:IoU>0.55;
- bin-based参数:S=1.5m, δ \delta δ=0.5m,旋转角为10°;
- epoch=50,batch size=256,learning rate=0.002
数据增强
随机翻转,[0.95,1.05]放缩比例因子,绕Y轴旋转[-10°,10°]。
4. 实验结果

5. 总结
PointRCNN是一个two-stage的3D detection模型。模型分为两个阶段,Stage-1先使用PointNet++作为主干网络,分割出前景点,生成少量粗粒度的3D proposal;Stage-2进一步优化proposal。将这些bounding box通过正交变换转换到自己的局部坐标系下,再使用PointNet++学习局部特征,完成优化。