Learning to Communicate with Deep Multi-Agent Reinforcement Learning
Abstract
We consider the problem of multiple agents sensing and acting in environments with the goal of maximising their shared utility. In these environments, agents must learn communication protocols in order to share information that is needed to solve the tasks. By embracing deep neural networks, we are able to demonstrate end- to-end learning of protocols in complex environments inspired by communication riddles and multi-agent computer vision problems with partial observability. We propose two approaches for learning in these domains: Reinforced Inter-Agent Learning (RIAL) and Differentiable Inter-Agent Learning (DIAL). The former uses deep Q-learning, while the latter exploits the fact that, during learning, agents can backpropagate error derivatives through (noisy) communication channels. Hence, this approach uses centralised learning but decentralised execution. Our experi- ments introduce new environments for studying the learning of communication protocols and present a set of engineering innovations that are essential for success in these domains.
我们考虑多个代理在环境中感知和行动的问题,目标是最大化其共享效用。在这些环境中,代理必须学习通信协议,以便共享解决任务所需的信息。通过采用深度神经网络,我们能够展示复杂环境中协议的端到端学习,这些环境受到通信谜语和具有部分可观察性的多智能体计算机视觉问题的启发。我们提出了两种在这些领域中学习的方法:强化的代理间学习(RIAL)和可区分的代理间学习(DIAL)。前者使用深度Q学习,而后者利用这样的事实:在学习期间,代理可以通过(嘈杂的)通信信道反向传播误差导数。因此,这种方法使用集中式学习但分散执行。我们的实验为研究通信协议的学习引入了新的环境,并提出了一系列工程创新,这些创新对于这些领域的成功至关重要。
1 Introduction
How language and communication emerge among intelligent agents has long been a topic of intense debate. Among the many unresolved questions are: Why does language use discrete structures? What role does the environment play? What is innate and what is learned? And so on. Some of the debates on these questions have been so fiery that in 1866 the French Academy of Sciences banned publications about the origin of human language.
The rapid progress in recent years of machine learning, and deep learning in particular, opens the door to a new perspective on this debate. How can agents use machine learning to automatically discover the communication protocols they need to coordinate their behaviour? What, if anything, can deep learning offer to such agents? What insights can we glean from the success or failure of agents that learn to communicate?
In this paper, we take the first steps towards answering these questions. Our approach is programmatic: first, we propose a set of multi-agent benchmark tasks that require communication; then, we formulate several learning algorithms for these tasks; finally, we analyse how these algorithms learn, or fail to learn, communication protocols for the agents.
The tasks that we consider are fully cooperative, partially observable, sequential multi-agent decision making problems. All the agents share the goal of maximising the same discounted sum of rewards. While no agent can observe the underlying Markov state, each agent receives a private observation correlated with that state. In addition to taking actions that affect the environment, each agent can also communicate with its fellow agents via a discrete limited-bandwidth channel. Due to the partial observability and limited channel capacity, the agents must discover a communication protocol that enables them to coordinate their behaviour and solve the task.
We focus on settings with centralised learning but decentralised execution. In other words, com- munication between agents is not restricted during learning, which is performed by a centralised algorithm; however, during execution of the learned policies, the agents can communicate only via the limited-bandwidth channel. While not all real-world problems can be solved in this way, a great many can, e.g., when training a group of robots on a simulator. Centralised planning and decentralised execution is also a standard paradigm for multi-agent planning [1]. For completeness, we also provide decentralised learning baselines.
To address these tasks, we formulate two approaches. The first, named reinforced inter-agent learning (RIAL), uses deep Q-learning [2] with a recurrent network to address partial observability. In one variant of this approach, which we refer to as independent Q-learning, the agents each learn their own network parameters, treating the other agents as part of the environment. Another variant trains a single network whose parameters are shared among all agents. Execution remains decentralised, at which point they receive different observations leading to different behaviour.
The second approach, which we call differentiable inter-agent learning (DIAL), is based on the insight that centralised learning affords more opportunities to improve learning than just parameter sharing. In particular, while RIAL is end-to-end trainable within an agent, it is not end-to-end trainable across agents, i.e., no gradients are passed between agents. The second approach allows real- valued messages to pass between agents during centralised learning, thereby treating communication actions as bottleneck connections between agents. As a result, gradients can be pushed through the communication channel, yielding a system that is end-to-end trainable even across agents. During decentralised execution, real-valued messages are discretised and mapped to the discrete set of communication actions allowed by the task. Because DIAL passes gradients from agent to agent, it is an inherently deep learning approach.
Our empirical study shows that these methods can solve our benchmark tasks, often discovering elegant communication protocols along the way. To our knowledge, this is the first time that either differentiable communication or reinforcement learning (RL) with deep neural networks have succeeded in learning communication protocols in complex environments involving sequences and raw input images1. The results also show that deep learning, by better exploiting the opportunities of centralised learning, is a uniquely powerful tool for learning communication protocols. Finally, this study advances several engineering innovations, outlined in the experimental section, that are essential for learning communication protocols in our proposed benchmarks.
智能代理人之间的语言和沟通如何长期以来一直是激烈争论的话题。许多尚未解决的问题包括:为什么语言使用离散结构?环境扮演什么角色?什么是天生的,学到了什么?等等。关于这些问题的一些辩论非常激烈,以至于1866年法国科学院禁止出版有关人类语言起源的出版物。
近年来机器学习的快速发展,特别是深度学习,为这场辩论的新视角打开了大门。代理如何使用机器学习自动发现协调其行为所需的通信协议?什么,如果有的话,深度学习可以提供给这些代理商?我们可以从学习沟通的代理人的成功或失败中获得什么见解?
在本文中,我们迈出了回答这些问题的第一步。我们的方法是程序化的:首先,我们提出一组需要通信的多代理基准测试任务;然后,我们为这些任务制定了几种学习算法;最后,我们分析了这些算法如何学习或无法学习代理的通信协议。
我们考虑的任务是完全合作的,部分可观察的,顺序的多智能体决策问题。所有代理人都有共同的目标,即最大化相同的折扣金额。虽然没有代理可以观察到基础马尔可夫状态,但每个代理都会收到与该状态相关的私人观察。除了采取影响环境的行动之外,每个代理还可以通过离散的有限带宽信道与其代理进行通信。由于部分可观察性和有限的信道容量,代理必须发现一种通信协议,使其能够协调其行为并解决任务。
我们专注于集中学习但分散执行的设置。换句话说,代理之间的通信在学习期间不受限制,这通过集中式算法来执行;但是,在执行学习策略期间,代理只能通过有限带宽信道进行通信。虽然并非所有现实问题都能以这种方式解决,但是很多人可以例如在模拟器上训练一组机器人时。集中规划和分散执行也是多智能体规划的标准范例[1]。为了完整起见,我们还提供分散的学习基准。
为了解决这些任务,我们制定了两种方法。第一个名为强化的代理间学习(RIAL),使用深度Q学习[2]和循环网络来解决部分可观察性问题。在这种方法的一个变体中,我们将其称为独立的Q学习,每个代理都学习他们自己的网络参数,将其他代理视为环境的一部分。另一种变体训练单个网络,其参数在所有代理之间共享。执行仍然是分散的,此时他们会收到导致不同行为的不同观察结果。
第二种方法,我们称之为可区分的代理间学习(DIAL),其基础是集中式学习提供更多机会来改善学习,而不仅仅是参数共享。特别是,虽然RIAL在代理中是端到端可训练的,但它不是跨代理的端到端可训练的,即代理之间没有传递梯度。第二种方法允许实值消息在集中学习期间在代理之间传递,从而将通信动作视为代理之间的瓶颈连接。结果,可以通过通信信道推送梯度,从而产生即使跨代理也可以端到端训练的系统。在分散执行期间,实值消息被离散化并映射到任务允许的离散通信动作集。因为DIAL从代理到代理传递渐变,所以它是一种固有的深度学习方法。
我们的实证研究表明,这些方法可以解决我们的基准任务,通常会发现优雅的通信协议。据我们所知,这是第一次无差异通信或强化学习(RL)与深度神经网络成功地学习了涉及序列和原始输入图像的复杂环境中的通信协议1。结果还表明,通过更好地利用集中学习的机会,深度学习是学习通信协议的独特强大工具。最后,本研究推进了实验部分概述的几项工程创新,这些创新对于我们提出的基准测试中的学习通信协议至关重要。
2 Related Work
Research on communication spans many fields, e.g. linguistics, psychology, evolution and AI. In AI, it is split along a few axes: a) predefined or learned communication protocols, b) planning or learning methods, c) evolution or RL, and d) cooperative or competitive settings.
Given the topic of our paper, we focus on related work that deals with the cooperative learning of communication protocols. Out of the plethora of work on multi-agent RL with communication, e.g., [4–8], only a few fall into this category. Most assume a pre-defined communication protocol, rather than trying to learn protocols. One exception is the work of Kasai et al. [8], in which tabular Q-learning agents have to learn the content of a message to solve a predator-prey task with communication. Another example of open-ended communication learning in a multi-agent task is given in [9]. Here evolutionary methods are used for learning the protocols which are evaluated on a similar predator-prey task. Their approach uses a fitness function that is carefully designed to accelerate learning. In general, heuristics and handcrafted rules have prevailed widely in this line of research. Moreover, typical tasks have been necessarily small so that global optimisation methods,
such as evolutionary algorithms, can be applied. The use of deep representations and gradient- based optimisation as advocated in this paper is an important departure, essential for scalability and further progress. A similar rationale is provided in [10], another example of making an RL problem end-to-end differentiable.
Finally, we consider discrete communication channels. One of the key components of our methods is the signal binarisation during the decentralised execution. This is related to recent research on fitting neural networks in low-powered devices with memory and computational limitations using binary weights, e.g. [11], and previous works on discovering binary codes for documents [12].
对通信的研究涉及许多领域,例如语言学,心理学,进化和人工智能。在AI中,它沿着几个轴分开:a)预定义或学习的通信协议,b)规划或学习方法,c)演化或RL,以及d)协作或竞争设置。
鉴于我们的论文主题,我们专注于处理通信协议的合作学习的相关工作。在具有通信的多代理RL的大量工作中,例如[4-8],只有少数属于此类别。大多数人假设使用预定义的通信协议,而不是尝试学习协议。一个例外是Kasai等人的工作。 [8],其中表格Q学习代理必须学习消息的内容,以通过通信解决捕食者 - 猎物任务。在[9]中给出了多代理任务中开放式通信学习的另一个例子。这里使用进化方法来学习在类似捕食者 - 猎物任务上评估的协议。他们的方法使用精心设计的健身功能来加速学习。一般来说,启发式和手工制作的规则在这一系列研究中占据了广泛的地位。而且,典型的任务必然很小,所以全局优化方法,
例如进化算法,可以应用。本文提出的深度表示和基于梯度的优化的使用是一个重要的出发点,对于可扩展性和进一步的进展至关重要。在[10]中提供了类似的基本原理,这是使RL问题端对端可微分的另一个例子。
最后,我们考虑离散通信渠道。我们方法的关键组成部分之一是分散执行期间的信号二进制化。这与最近关于在具有存储器和使用二进制权重的计算限制的低功率设备中拟合神经网络的研究有关,例如, [11],以前的工作是发现文档的二进制代码[12]。
3 Background


4 Setting
In this work, we consider RL problems with both multiple agents and partial observability. All the agents share the goal of maximising the same discounted sum of rewards Rt. While no agent can observe the underlying Markov state st, each agent receives a private observation oa correlated to st. In each time-step, the agents select an environment action u ∈ U that affects the environment, and a communication action m ∈ M that is observed by other agents but has no direct impact on the environment or reward. We are interested in such settings because it is only when multiple agents and partial observability coexist that agents have the incentive to communicate. As no communication protocol is given a priori, the agents must develop and agree upon such a protocol to solve the task.
Since protocols are mappings from action-observation histories to sequences of messages, the space of protocols is extremely high-dimensional. Automatically discovering effective protocols in this space remains an elusive challenge. In particular, the difficulty of exploring this space of protocols is exacerbated by the need for agents to coordinate the sending and interpreting of messages. For example, if one agent sends a useful message to another agent, it will only receive a positive reward if the receiving agent correctly interprets and acts upon that message. If it does not, the sender will be discouraged from sending that message again. Hence, positive rewards are sparse, arising only when sending and interpreting are properly coordinated, which is hard to discover via random exploration.
We focus on settings with centralised learning but decentralised execution. In other words, com- munication between agents is not restricted during learning, which is performed by a centralised algorithm; however, during execution of the learned policies, the agents can communicate only via the limited-bandwidth channel. While not all real-world problems can be solved in this way, a great many can, e.g., when training a group of robots on a simulator. Centralised planning and decentralised execution is also a standard paradigm for multi-agent planning [1, 18].
在这项工作中,我们考虑了多个代理和部分可观察性的RL问题。所有代理人都有共同的目标,即最大化相同的折扣总和Rt。虽然没有代理可以观察到基础马尔可夫状态st,但每个代理都接收到与st相关的私人观察。在每个时间步骤中,代理选择影响环境的环境动作u∈U,以及由其他代理观察但对环境或奖励没有直接影响的通信动作m∈M。我们对这样的设置感兴趣,因为只有当多个代理和部分可观察性共存时,代理才有动力进行交流。由于没有先验地给出通信协议,因此代理必须开发并同意这样的协议来解决该任务。
由于协议是从动作观察历史到消息序列的映射,协议的空间是非常高维的。在这个领域自动发现有效的协议仍然是一个难以捉摸的挑战。特别是,由于需要代理协调消息的发送和解释,因此探索协议空间的难度加剧了。例如,如果一个代理向另一个代理发送有用的消息,则只有在接收代理正确解释并对该消息进行操作时,它才会收到肯定的奖励。如果没有,则不鼓励发件人再次发送该消息。因此,积极的奖励是稀疏的,只有在发送和解释得到适当协调时才会产生,这很难通过随机探索发现。
我们专注于集中学习但分散执行的设置。换句话说,代理之间的通信在学习期间不受限制,这通过集中式算法来执行;但是,在执行学习策略期间,代理只能通过有限带宽信道进行通信。虽然并非所有现实问题都能以这种方式解决,但是很多人可以例如在模拟器上训练一组机器人时。集中规划和分散执行也是多智能体规划的标准范例[1,18]。
5 Methods
In this section, we present two approaches for learning communication protocols.
5.1 Reinforced Inter-Agent Learning


Figure 1: In RIAL (a), all Q-values are fed to the action selector, which selects both environment and communication actions. Gradients, shown in red, are computed using DQN for the selected action and flow only through the Q-network of a single agent. In DIAL (b), the message ma bypasses the action selector and instead is processed by the DRU (Section 5.2) and passed as a continuous value to the next C-network. Hence, gradients flow across agents, from the recipient to the sender. For simplicity, at each time step only one agent is highlighted, while the other agent is greyed out.
Parameter Sharing. RIAL can be extended to take advantage of the opportunity for centralised learning by sharing parameters among the agents. This variation learns only one network, which is
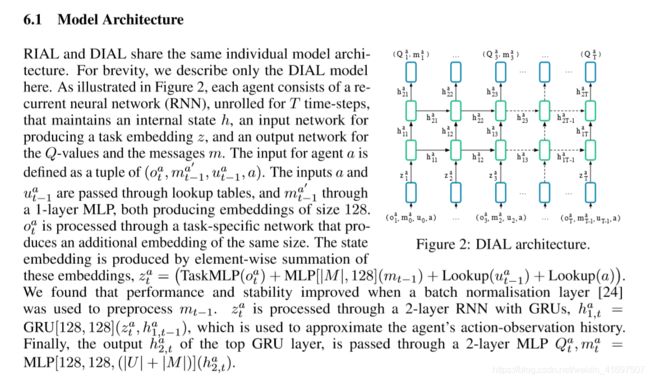
used by all agents. However, the agents can still behave differently because they receive different observations and thus evolve different hidden states. In addition, each agent receives its own index a as input, allowing them to specialise. The rich representations in deep Q-networks can facilitate the learning of a common policy while also allowing for specialisation. Parameter sharing also dramatically reduces the number of parameters that must be learned, thereby speeding learning.
图1:在RIAL(a)中,所有Q值都被馈送到动作选择器,动作选择器选择环境和通信动作。以红色显示的梯度使用DQN计算所选操作,并仅通过单个代理的Q网络流动。在DIAL(b)中,消息ma绕过动作选择器,而是由DRU处理(第5.2节),并作为连续值传递给下一个C网络。因此,梯度流经代理,从接收者到发送者。为简单起见,在每个时间步骤仅突出显示一个代理,而另一个代理显示为灰色。
参数共享。通过在代理之间共享参数,可以扩展RIAL以利用集中学习的机会。这种变化只能学习一个网络
由所有代理商使用。然而,代理仍然可以表现不同,因为它们接收不同的观察结果,从而演变出不同的隐藏状态。此外,每个代理都接收自己的索引a作为输入,允许它们专门化。深层Q网络中丰富的表示可以促进学习共同政策,同时也允许专业化。参数共享还大大减少了必须学习的参数数量,从而加快了学习速度。

5.2 Differentiable Inter-Agent Learning
While RIAL can share parameters among agents, it still does not take full advantage of centralised learning. In particular, the agents do not give each other feedback about their communication actions. Contrast this with human communication, which is rich with tight feedback loops. For example, during face-to-face interaction, listeners send fast nonverbal queues to the speaker indicating the level of understanding and interest. RIAL lacks this feedback mechanism, which is intuitively important for learning communication protocols.
To address this limitation, we propose differentiable inter-agent learning (DIAL). The main insight behind DIAL is that the combination of centralised learning and Q-networks makes it possible, not only to share parameters but to push gradients from one agent to another through the communication channel. Thus, while RIAL is end-to-end trainable within each agent, DIAL is end-to-end trainable across agents. Letting gradients flow from one agent to another gives them richer feedback, reducing the required amount of learning by trial and error, and easing the discovery of effective protocols.
DIAL works as follows: during centralised learning, communication actions are replaced with direct connections between the output of one agent’s network and the input of another’s. Thus, while the task restricts communication to discrete messages, during learning the agents are free to send real-valued messages to each other. Since these messages function as any other network activation, gradients can be passed back along the channel, allowing end-to-end backpropagation across agents.
虽然RIAL可以在代理之间共享参数,但它仍然没有充分利用集中式学习。特别是,代理商不会互相提供有关其通信行为的反馈。将此与人类交流相比较,人类交流富有紧密的反馈循环。例如,在面对面互动期间,听众向发言者发送快速非语言队列,表明理解和兴趣的程度。 RIAL缺乏这种反馈机制,这对学习通信协议非常重要。
为了解决这一局限,我们提出了可区分的代理间学习(DIAL)。 DIAL背后的主要见解是,集中式学习和Q网络的结合使得不仅可以共享参数,而且可以通过通信渠道将梯度从一个代理推送到另一个代理。因此,虽然RIAL在每个代理中都是端到端可训练的,但DIAL可以跨代理进行端到端的训练。让渐变从一个代理流向另一个代理可以为他们提供更丰富的反馈,通过反复试验减少所需的学习量,并简化有效协议的发现。
DIAL的工作原理如下:在集中式学习期间,通信动作被一个代理网络的输出与另一个网络的输入之间的直接连接所取代。因此,虽然任务将通信限制为离散消息,但在学习期间,代理可以自由地向彼此发送实值消息。由于这些消息可以像任何其他网络激活一样运行,因此可以沿着通道传回梯度,从而允许跨代理进行端到端反向传播。

6 Experiments
In this section, we evaluate RIAL and DIAL with and without parameter sharing in two multi-agent problems and compare it with a no-communication shared parameters baseline (NoComm). Results presented are the average performance across several runs, where those without parameter sharing (-
NS), are represented by dashed lines. Across plots, rewards are normalised by the highest average reward achievable given access to the true state (Oracle).
In our experiments, we use an -greedy policy with = 0.05, the discount factor is γ = 1, and the target network is reset every 100 episodes. To stabilise learning, we execute parallel episodes in batches of 32. The parameters are optimised using RMSProp with momentum of 0.95 and a learning rate of 5 ×10−4. The architecture makes use of rectified linear units (ReLU), and gated recurrent units (GRU) [20], which have similar performance to long short-term memory [21] (LSTM) [22, 23]. Unless stated otherwise we set σ = 2, which was found to be essential for good performance. We intent to published the source code online.
在本节中,我们在两个多代理问题中使用和不使用参数共享来评估RIAL和DIAL,并将其与无通信共享参数基线(NoComm)进行比较。所呈现的结果是几次运行的平均性能,其中没有参数共享的那些( -
NS),用虚线表示。在整个情节中,奖励通过获得真实状态(Oracle)可实现的最高平均奖励来标准化。
在我们的实验中,我们使用-greedy策略= 0.05,折扣因子为γ= 1,目标网络每100集重置一次。为了稳定学习,我们以32个批次执行并行剧集。使用RMSProp优化参数,动量为0.95,学习率为5×10-4。该架构利用整流线性单元(ReLU)和门控循环单元(GRU)[20],它们具有与长短期记忆相似的性能[21](LSTM)[22,23]。除非另有说明,否则我们设置σ= 2,这被认为是良好性能所必需的。我们打算在线发布源代码。
6.2 SwitchRiddle
The first task is inspired by a well-known riddle described as follows: “One hundred prisoners have been newly ushered into prison. The warden tells them that starting tomorrow, each of them will be placed in an isolated cell, unable to communicate amongst each other. Each day, the warden will choose one of the prisoners uniformly at random with replacement, and place him in a central interrogation room containing only a light bulb with a toggle switch. The prisoner will be able to observe the current state of the light bulb. If he wishes, he can toggle the light bulb. He also has the option of announcing that he believes all prisoners have visited the interrogation room at some point in time. If this announcement is true, then all prisoners are set free, but if it is false, all prisoners are executed. The warden leaves and the prisoners huddle together to discuss their fate. Can they agree on a protocol that will guarantee their freedom?” [25].
第一项任务的灵感来自于一个众所周知的谜语:“100名囚犯新入狱。 监狱长告诉他们,从明天开始,他们每个人都将被置于一个孤立的牢房中,无法彼此沟通。 每天,监狱长会随意选择其中一名囚犯随意更换,并将他安置在一个中央审讯室,里面只有一个带拨动开关的灯泡。 囚犯将能够观察灯泡的当前状态。 如果他愿意,他可以切换灯泡。 他还可以选择宣布他相信所有囚犯都在某个时间点访问了审讯室。 如果这个公告属实,那么所有囚犯都被释放,但如果是假的,所有囚犯都被处决。 监狱长离开,囚犯挤在一起讨论他们的命运。 他们能否同意一项保证其自由的议定书?“[25]。


Experimental results.
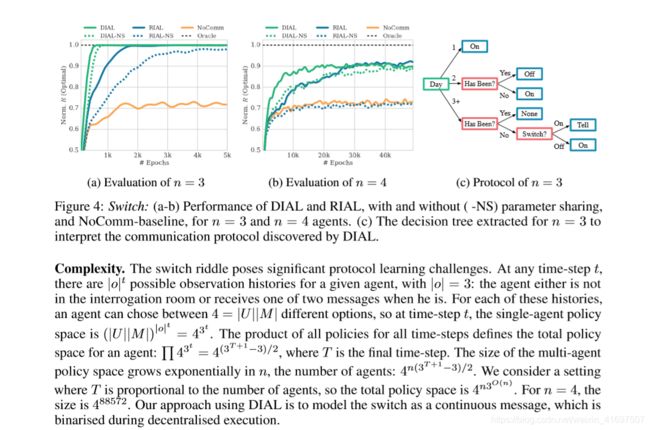
Figure 4(a) shows our results for n = 3 agents. All four methods learn an optimal policy in 5k episodes, substantially outperforming the NoComm baseline. DIAL with param- eter sharing reaches optimal performance substantially faster than RIAL. Furthermore, parameter sharing speeds both methods. Figure 4(b) shows results for n = 4 agents. DIAL with parameter sharing again outperforms all other methods. In this setting, RIAL without parameter sharing was unable to beat the NoComm baseline. These results illustrate how difficult it is for agents to learn the same protocol independently. Hence, parameter sharing can be crucial for learning to communicate. DIAL-NS performs similarly to RIAL, indicating that the gradient provides a richer and more robust source of information.
We also analysed the communication protocol discovered by DIAL for n = 3 by sampling 1K episodes, for which Figure 4© shows a decision tree corresponding to an optimal strategy. When a prisoner visits the interrogation room after day two, there are only two options: either one or two prisoners may have visited the room before. If three prisoners had been, the third prisoner would have finished the game. The other options can be encoded via the “On” and “Off” position respectively.
图4(a)显示了n = 3种药剂的结果。所有四种方法都在5k集中学习最优策略,大大优于NoComm基线。具有参数共享的DIAL比RIAL快得多地达到最佳性能。此外,参数共享可加速这两种方法。图4(b)显示n = 4种试剂的结果。具有参数共享的DIAL再次优于所有其他方法。在此设置中,没有参数共享的RIAL无法击败NoComm基线。这些结果说明了代理人独立学习相同协议的难度。因此,参数共享对于学习交流至关重要。 DIAL-NS的表现与RIAL类似,表明梯度提供了更丰富,更强大的信息来源。
我们还通过采样1K集分析了DIAL针对n = 3发现的通信协议,其中图4(c)示出了对应于最优策略的决策树。当囚犯在第二天后访问审讯室时,只有两种选择:一两个囚犯可能曾经访问过这个房间。如果有三名囚犯,第三名囚犯将完成比赛。其他选项可分别通过“开”和“关”位置编码。
6.3 MNIST Games
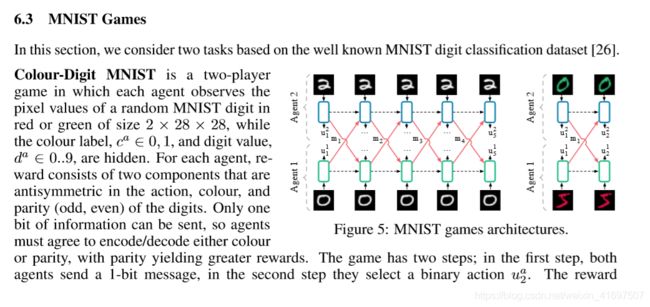

Architecture. The input processing network is a 2-layer MLP TaskMLP(|c|×28×28), 128, 128. Figure 5 depicts the generalised setting for both games. Our experimental evaluation showed improved training time using batch normalisation after the first layer.
Experimental results. Figures 6(a) and 6(b) show that DIAL substantially outperforms the other methods on both games. Furthermore, parameter sharing is crucial for reaching the optimal protocol. In multi-step MNIST, results were obtained with σ = 0.5. In this task, RIAL fails to learn, while in colour-digit MNIST it fluctuates around local minima in the protocol space; the NoComm baseline is stagnant at zero. DIAL’s performance can be attributed to directly optimising the messages in order to reduce the global DQN error while RIAL must rely on trial and error. DIAL can also optimise the message content with respect to rewards taking place many time-steps later, due to the gradient passing between agents, leading to optimal performance in multi-step MNIST. To analyse the protocol that DIAL learned, we sampled 1K episodes. Figure 6© illustrates the communication bit sent at time-step t by agent 1, as a function of its input digit. Thus, each agent has learned a binary encoding and decoding of the digits. These results illustrate that differentiable communication in DIAL is essential to fully exploiting the power of centralised learning and thus is an important tool for studying the learning of communication protocols. We provide further insights into the difficulties of learning a communication protocol for this task with RIAL compared to DIAL in the AppendixB.
建筑。输入处理网络是2层MLP TaskMLP [(| c |×28×28),128,128](oa)。图5描绘了两种游戏的通用设置。我们的实验评估显示在第一层之后使用批次标准化改善了训练时间。
实验结果。图6(a)和6(b)显示DIAL在两场比赛中都明显优于其他方法。此外,参数共享对于达到最佳协议至关重要。在多步MNIST中,获得的结果为σ= 0.5。在这项任务中,RIAL无法学习,而在彩色数字MNIST中,它在协议空间中的局部最小值附近波动; NoComm基线停滞在零。 DIAL的性能可归因于直接优化消息以减少全局DQN错误,而RIAL必须依赖于反复试验。由于代理之间的梯度传递,DIAL还可以在多个时间步之后优化消息内容,从而在多步MNIST中实现最佳性能。为了分析DIAL学习的协议,我们采样了1K集。图6(c)示出了代理1在时间步t发送的通信比特,作为其输入数字的函数。因此,每个代理已经学习了数字的二进制编码和解码。这些结果表明,DIAL中的可区分通信对于充分利用集中式学习的能力至关重要,因此是研究通信协议学习的重要工具。与附录B中的DIAL相比,我们提供了有关使用RIAL学习此任务的通信协议的困难的进一步见解。
6.4 Effect of Channel Noise

7 Conclusions
This paper advanced novel environments and successful techniques for learning communication protocols. It presented a detailed comparative analysis covering important factors involved in the learning of communication protocols with deep networks, including differentiable communication, neural network architecture design, channel noise, tied parameters, and other methodological aspects.
This paper should be seen as a first attempt at learning communication and language with deep learning approaches. The gargantuan task of understanding communication and language in their full splendour, covering compositionality, concept lifting, conversational agents, and many other important problems still lies ahead. We are however optimistic that the approaches proposed in this paper can play a substantial role in tackling these challenges.
本文提出了学习通信协议的新环境和成功技术。 它提供了详细的比较分析,涵盖了深度网络通信协议学习中涉及的重要因素,包括可区分通信,神经网络架构设计,信道噪声,绑定参数和其他方法方面。
本文应被视为通过深度学习方法学习交流和语言的第一次尝试。 理解沟通和语言的巨大任务,包括组合性,概念提升,会话代理和许多其他重要问题仍然存在。 然而,我们乐观地认为,本文提出的方法可以在应对这些挑战方面发挥重要作用。
Acknowledgements
This work was supported by the Oxford-Google DeepMind Graduate Scholarship and the EPSRC. We would like to thank Brendan Shillingford, Serkan Cabi and Christoph Aymanns for helpful comments.
References
[1] L. Kraemer and B. Banerjee. Multi-agent reinforcement learning as a rehearsal for decentralized planning.
Neurocomputing, 190:82–94, 2016.
[2] V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski, S. Petersen, C. Beattie, A. Sadik, I. Antonoglou, H. King, D. Kumaran, D. Wierstra, S. Legg, and D. Hassabis. Human-level control through deep reinforcement learning. Nature,
518(7540):529–533, 2015.
[3] J. N. Foerster, Y. M. Assael, N. de Freitas, and S. Whiteson. Learning to communicate to solve riddles with deep distributed recurrent q-networks. arXiv preprint arXiv:1602.02672, 2016.
[4] M. Tan. Multi-agent reinforcement learning: Independent vs. cooperative agents. In ICML, 1993.
[5] F. S. Melo, M. Spaan, and S. J. Witwicki. QueryPOMDP: POMDP-based communication in multiagent systems. In Multi-Agent Systems, pages 189–204. 2011.
[6] L. Panait and S. Luke. Cooperative multi-agent learning: The state of the art. Autonomous Agents and
Multi-Agent Systems, 11(3):387–434, 2005.
[7] C. Zhang and V. Lesser. Coordinating multi-agent reinforcement learning with limited communication. In
AAMAS, volume 2, pages 1101–1108, 2013.
[8] T. Kasai, H. Tenmoto, and A. Kamiya. Learning of communication codes in multi-agent reinforcement learning problem. In IEEE Soft Computing in Industrial Applications, pages 1–6, 2008.
[9] C. L. Giles and K. C. Jim. Learning communication for multi-agent systems. In Innovative Concepts for
Agent-Based Systems, pages 377–390. Springer, 2002.
[10] K. Gregor, I. Danihelka, A. Graves, and D. Wierstra. Draw: A recurrent neural network for image generation. arXiv preprint arXiv:1502.04623, 2015.
[11] M. Courbariaux and Y. Bengio. BinaryNet: Training deep neural networks with weights and activations constrained to +1 or -1. arXiv preprint arXiv:1602.02830, 2016.
[12] G. Hinton and R. Salakhutdinov. Discovering binary codes for documents by learning deep generative models. Topics in Cognitive Science, 3(1):74–91, 2011.
[13] R. S. Sutton and A. G. Barto. Introduction to reinforcement learning. MIT Press, 1998.
[14] A. Tampuu, T. Matiisen, D. Kodelja, I. Kuzovkin, K. Korjus, J. Aru, J. Aru, and R. Vicente. Multiagent cooperation and competition with deep reinforcement learning. arXiv preprint arXiv:1511.08779, 2015.
[15] Y. Shoham and K. Leyton-Brown. Multiagent Systems: Algorithmic, Game-Theoretic, and Logical
Foundations. Cambridge University Press, New York, 2009.
[16] E. Zawadzki, A. Lipson, and K. Leyton-Brown. Empirically evaluating multiagent learning algorithms.
arXiv preprint 1401.8074, 2014.
[17] M. Hausknecht and P. Stone. Deep recurrent Q-learning for partially observable MDPs. arXiv preprint arXiv:1507.06527, 2015.
[18] F. A. Oliehoek, M. T. J. Spaan, and N. Vlassis. Optimal and approximate Q-value functions for decentralized
POMDPs. JAIR, 32:289–353, 2008.
[19] K. Narasimhan, T. Kulkarni, and R. Barzilay. Language understanding for text-based games using deep reinforcement learning. arXiv preprint arXiv:1506.08941, 2015.
[20] K. Cho, B. van Merriënboer, D. Bahdanau, and Y. Bengio. On the properties of neural machine translation: Encoder-decoder approaches. arXiv preprint arXiv:1409.1259, 2014.
[21] S. Hochreiter and J. Schmidhuber. Long short-term memory. Neural computation, 9(8):1735–1780, 1997. [22] J. Chung, C. Gulcehre, K. Cho, and Y. Bengio. Empirical evaluation of gated recurrent neural networks on
sequence modeling. arXiv preprint arXiv:1412.3555, 2014.
[23] R. Jozefowicz, W. Zaremba, and I. Sutskever. An empirical exploration of recurrent network architectures.
In ICML, pages 2342–2350, 2015.
[24] S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In ICML, pages 448–456, 2015.
[25] W. Wu. 100 prisoners and a lightbulb. Technical report, OCF, UC Berkeley, 2002.
[26] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. Gradient-based learning applied to document recognition.
Proceedings of the IEEE, 86(11):2278–2324, 1998.
[27] M. Studdert-Kennedy. How did language go discrete? In M. Tallerman, editor, Language Origins: Perspectives on Evolution, chapter 3. Oxford University Press, 2005.
A DIAL Details
Algorithm 1 formally describes DIAL. At each time-step, we pick an action for each agent -greedily with respect to the Q-function and assign an outgoing message