cs231n计算机视觉课程笔记
P2
- 目标识别
- PASCAL 数据集
- 一个ImageNet(1500w—4000w、22000类)
P3
- 2012: AlexNet 7-8 层
2014:VGG网络 19层
2015:残差网络152层 - 1998 LeCun CNN诞生用于数字识别,2012才开始流行的原因:计算能力、标签↑
P4 图像分类-数据驱动方法
- 计算机眼中的图像:一大堆数字:800*600的像素,每个像素由三个值表示(红、绿、蓝)
- 问题:语义鸿沟存在于人类定义的语义概念与计算机实际看到的像素值之间。
- challenge:视点变化/照明/变形/遮挡/图片背景混乱(background clutter:要识别的物体纹理颜色和背景很像)/类内差异(intraclass variation)
- 数据驱动方法
- 收集图像和标签的数据集
- 使用 ML 训练分类器
- 在新图像上评估分类器
- 两个函数
def train(images, labels): #接收图片和标签,输出模型 return modeldef predict(model, test_images): #接收一个模型,对图片种类进行预测 return test_labels
Nearest Neighbor(最近邻)
Dataset: CIFAR10 (10类*5w张)
Distance Metric to compare images
- L1 距离(曼哈顿距离): 对图片中的单个像素进行比较
d 1 ( I 1 , I 2 ) = ∑ p ∣ I 1 p − I 2 p ∣ d_1(I_1,I_2)=\sum_p\left|I_1^p-I_2^p\right| d1(I1,I2)=∑p∣I1p−I2p∣
import numpy as np
class NearestNeighbor:
def __init__(self):
pass
def train(self, X, y):
'''X is N x D where each row is an example. Yis 1-d of size N '''
# 只需存储训练数据
self.Xtr = X
self.ytr = y
def predict(self X):
'''X is N x D where each row is an example wish to predict label for '''
num_test = X.shape[0]
# lets make sure that the output type matches the input type
Ypred = np.zeros(num_test, dtype = self.ytr.dtype)
# loop over all test rows
for i in xrange(num_test):
# find the nearest training image to the i*th test image
# using the L1 distance (sum of absolute value differences)
distances = np.sum(np.abs(self.Xtr - X[i,:]), axis = 1) # using broadcast
min_index = np.argmin(distances) # get the index with smallest distance
Ypred[i] = self.ytr[min_index] # predict the label of the nearest example
return Ypred

p5 图像分类 K-最近邻算法(KNN)
K-Nearest Neighbors(不只寻找最近的点)
- Distance Metric:
L1(Manhattan) distance(曼哈顿)
L2(Euclidean) distance(欧式距离): d 2 ( I 1 , I 2 ) = ∑ p ( I 1 p − I 2 p ) 2 d_2(I_1,I_2 )=\sqrt{\sum_p(I^p_1-I^p_2)^2} d2(I1,I2)=∑p(I1p−I2p)2
比较: L1 取决于坐标轴的选择,用于输入的特征向量,向量中的一些值有一些重要意义的情况;L2不受坐标轴影响,用于只是某个空间中的一个通用向量的情况。
hyperparameters(超参数): 无法从数据中学习,也不能只通过在训练/测试集上的表现来选择,比如K、distance Metric。
- 正确做法:
1.将数据分为train, validation(验证), test sets:选择在验证集上表现最好的,然后才算是完成了调试,最后用于测试集,结果表示算法在未见的新数据上表现如何。
2.交叉验证。多用于小数据集,将训练集分成很多份,每一份轮流做验证集
problem (KNN不常用于图像分类)
1.运算时间长;
2.向量化的距离函数/L2距离不适合表示图像之间视觉的相似度;
3.维度灾难。
# assume we have Xtr_rows, Ytr, Xte_rows, Yte as before
# recall Xtr_rows is 50,000 x 3072 matrix
Xval_rows = Xtr_rows[:1000, :] # take first 1000 for validation
Yval = Ytr[:1000]
Xtr_rows = Xtr_rows[1000:, :] # keep last 49,000 for train
Ytr = Ytr[1000:]
# find hyperparameters that work best on the validation set
validation_accuracies = []
for k in [1, 3, 5, 10, 20, 50, 100]:
# use a particular value of k and evaluation on validation data
nn = NearestNeighbor()
nn.train(Xtr_rows, Ytr)
# here we assume a modified NearestNeighbor class that can take a k as input
Yval_predict = nn.predict(Xval_rows, k = k)
acc = np.mean(Yval_predict == Yval)
print 'accuracy: %f' % (acc,)
# keep track of what works on the validation set
validation_accuracies.append((k, acc))
P6-线性分类(属于参数分类的一种)
- CNN(卷积神经网络 convolutional neural network)只关注图像
RNN(循环神经网络 recurrent neural network)只关注语言 - 函数:f(x,W) = Wx + b:
x:input data; W:parameters or weights; b:bias vector
W:告诉我们那个像素对那个分类有多少影响
b:不与训练数据交互,只给一些数据独立的针对一类的偏好值,比如在数据集不平衡时,数量更多的那类偏差元素比其他的高,给一个数据独立缩放比例及每个类的偏移量 - 线性分类≈模板匹配方法
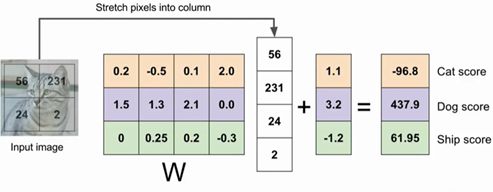
- 问题: 每个类别只能学习一个模板; hard cases: 多模态数据; 奇偶数问题
p7 损失函数和优化损失函数
Loss function(损失函数)
-
度量一个模型的好坏: L = 1 N ∑ i L i ( f ( x i , W ) , y i ) L=\frac{1}{N}\sum_iL_i(f(x_i,W),y_i) L=N1∑iLi(f(xi,W),yi)l
-
Multiclass SVM loss(多分类SVM损失函数):
- SVM loss:
L i = ∑ j ≠ y i { 0 i f s y i ≥ s j + 1 s j − s y i + 1 o t h e r w i s e = ∑ j ≠ y i m a x ( 0 , s i − s y i + 1 ) L_i=\sum_{j\not=y_i}\left\{\begin{array}{l} 0 &if\quad s_{y_i}\ge s_j+1 \\s_j-s_{y_i}+1 &otherwise\end{array}\right.\\ \quad =\sum_{j\not=y_i}max(0,s_i-s_{y_i}+1) Li=j=yi∑{0sj−syi+1ifsyi≥sj+1otherwise=j=yi∑max(0,si−syi+1) - SVM 损失函数希望正确类别 y i y_i yi 的分数比错误类别分数大很多。
- hinge loss(合页损失函数)

def L_i_vectorized(x, y, W): scores = W.dot(x) margins = np.maximum(0, scores - scores[y] + 1) margins[y] = 0 loss_i = np.sum(margins) return loss_i正则化(regularization):减轻模型复杂度,防止过拟合(over-fitting)
L= 1 N ∑ i L i ( f ( x i , W ) , y i ) + λ R ( W ) \frac{1}{N}\sum_iL_i(f(x_i,W),y_i)+\lambda R(W) N1∑iLi(f(xi,W),yi)+λR(W) (数据丢失项+正则项, λ \lambda λ 作为超参数平衡这两项)
- 常用正则化类型:
- L2 regularization(欧氏范数的权重向量W): R ( W ) = ∑ k ∑ l W k , l 2 R(W) = \sum_k\sum _l W^2_{k,l} R(W)=∑k∑lWk,l2
对权重向量的欧氏范数进行惩罚,将影响分散到所有 x 上,而不仅取决于某些特定元素(过度拟合),更加能传递出x中不同元素值的影响,更多考虑W整体分布 - L1 regularization: R ( W ) = ∑ k ∑ l ∣ W k , l ∣ R(W) = \sum_k\sum _l |W_{k,l}| R(W)=∑k∑l∣Wk,l∣
在矩阵W中鼓励稀疏,度量的方式可能是非零元素的个数 - 弹性网络正则化(L1 + L2): R ( W ) = ∑ k ∑ l β W k , l 2 + ∣ W k , l ∣ R(W) = \sum_k\sum _l \beta W_{k,l}^2+ |W_{k,l}| R(W)=∑k∑lβWk,l2+∣Wk,l∣
- SVM loss:
-
Softmax loss(Multinomial Logistic Regression多项逻辑斯蒂回归):
- 在深度学习中使用更广泛,相比多项SVM损失,会给最后的得分一些额外的含义:分数经过softmax function转化处理后,得到概率分布: P ( Y = k ∣ X = x i ) = e s k ∑ j e s j P(Y=k|X=x_i)=\frac{e^{s_k}}{\sum_je^{s_j}} P(Y=k∣X=xi)=∑jesjesk
- 最小化正确类的负对数似然——最大似然估计: L i = − l o g P ( Y = y i ∣ X = x i ) = − s i + l o g ∑ j e j s L_i=-logP(Y=y_i|X=x_i)=-s_i+log\sum_je^s_j Li=−logP(Y=yi∣X=xi)=−si+log∑jejs
- 实际问题:数值稳定性:
使用归一化技巧: e s k ∑ j e s j = C e s k C ∑ j e s j = e s k + l o g C ∑ j e s j + l o g C \frac{e^{s_k}}{\sum_je^{s_j}}=\frac{Ce^{s_k}}{C\sum_je^{s_j}}=\frac{e ^{s_k+logC}}{\sum_je^{s_j+logC}} ∑jesjesk=C∑jesjCesk=∑jesj+logCesk+logC,其中 C C C 的常见选择是设置 l o g C = − m a x j s j logC=-max_js_j logC=−maxjsj(移动向量 s s s 内的值,使最大值为零。)
optimazation(优化)
- 感知形状、倾斜,哪条路可以让我走到最下面?多元情况的导数:梯度,偏导数组成的向量,指向函数最大的增加方向,梯度减小指向函数最大减小的方向`
- 梯度下降
# Vanilla Gradient Descent
While True:
Weights_grad=evaluate_gradient(loss_fun,data,weights)
Weights+= - step_size * weights_grad
(**步长(学习率):超参数**,每次计算梯度时在那个方向前进多少距离)
- 随机梯度下降
# Vanilla Minibatch Gradient Descent
While True:
Data_batch = sample_training_data(data,256)
Weights_grad=evaluate_gradient(loss_fun,data_batch,weights)
Weights+= - step_size * weights_grad
图像特征
- 使用适当的特征表示比将原始像素放入分类器要好得多:计算图片的各种特征代表,然后将不同的特征向量合到一块得到图像的特征表述,输入分类器
- 颜色直方图
- 定向梯度直方图
- 词袋
P8 神经网络-反向传播
Computational graphs (计算图)用来表示任意函数
-
Back Propagation(BP):递归调用链式法则求出每个变量的梯度,从后往前计算所有梯度,可以找到L在W方向上的梯度
-
具体算法:在每一个节点上计算我们所需要的本地梯度,然后跟踪这个梯度,在BP中我们接收从上游传回来的这个梯度值,乘以本地梯度值从而得到要传回连接点的值,每个梯度的元素代表这个特定元素对最终函数影响的大小
-
sigmoid函数: σ ( x ) = 1 1 + e − x \sigma(x)=\frac{1}{1+e^{-x}} σ(x)=1+e−x1 , d σ ( x ) d x = ( 1 − σ ( x ) ) σ ( x ) \frac{d\sigma(x) }{dx}=(1-\sigma(x))\sigma(x) dxdσ(x)=(1−σ(x))σ(x)
-
反向传播过程中的模式:
- Add gate:梯度分配器
- Max gate:梯度路由器
- Mul gate:梯度切换器
- Copy gate:梯度加法器
class ComputationalGraph(object):
#...
def forward(inputs):
# 1. pass inputs to input gates...
# 2. forward the computational graph:
for gate in self.graph.nodes_topologically_sorted():
gate.forward()
return loss # the final gate in the graph outputs the loss
def backward():
for gate in reversed(self.graph.nodes_topologically_sorted()):
gate.backward()
return inputs_gradients
P9 神经网络 Neural Network
- 神经网络是将一些简单的函数以分层的方式堆叠起来,以组成更复杂的非线性函数
- s = W 2 m a x ( 0 , W 1 x ) s=W_2max(0,W_1x) s=W2max(0,W1x)
- 非线性层很重要: ReLU… (why?),每一个隐藏层是一个向量一组神经元的集合,利用矩阵乘法计算神经元的值,全连接层的前向传递对应于一个矩阵乘法,然后是一个偏置偏移和一个激活函数。
P11 卷积神经网络 Convolutional Neural Network
- 全连接层:在向量上进行操作,将图片的所有像素展开得到向量,将向量和权重矩阵相乘,得到激活值(activation)即这一层的输出
- 卷积层:可保全空间结构(不用展开成长向量),权重是一些小的卷积核(filters),将此卷积核在整个图像上滑动,计算出每一个空间区域的点积结果
- Filters(很小一个空间区域):将输入量扩展至完全,遍历所有通道(full depth)每个卷积核(filter)产生一个激活图(activation maps),深度(depth)等于过滤器的数量。较低层的过滤器:边缘等低级特征; 中层过滤器:更复杂的特征,如角点和斑点等。
- 总体架构:经过CONV、RELU、POOL层后得到卷积层输出,然后用全连接层连接所有的卷积输出,并用其获得一个最终的分值函数
- Output size: (N - F) / stride + 1 (N:input dimension(输入维度)、F:filter size、stride:滑动步幅)
- 零填充:采用零填充边界来得到最后想要的大小(跟之前一样大): (N - F + 2P) / stride + 1 。因为如果有很多层,激活图会不断缩小最后变得很小,会丢失一定信息。
P12 视觉之外的卷积神经网络
- 5x5 filter = 5x5 receptive field(感受野 )
卷积层 vs 全连接层 :只与图像的一个局部区域发生关联 vs 全连接层是与全体输入量发生关联 - 池化层(POOL ):
- 目的:使生成的表示尽量小,参数会更少。
- 工作:对输入进行空间上的降采样处理,只做平面上的不做深度方向的池化处理。
- 常用方法为最大池化:有一个卷积核的大小(filter size)=要池化处理的区域大小,然后滑过整个区域(like卷积),一般步长会设置为没有任何重叠的情况,不做点积,取其中的最大值(看成这组卷积核在图像任意区域受激程度的表示)
- Fully connected layer(全连接层FC)
将卷积层的输出矩阵直接拉平与朴素神经网络相连接 - 典型结构: *[(CONV - RELU)*N - POOL]*M - (FC - RELU)K, SOFTMAX
CONV RELU重复N次,每次做一个池化,然后来到全连接层,最后用softmax得到类别分数(N is usually up yo 5, M is large, 0<=K<=2)
P13 Activation Functions(激活函数)
卷积层/全连接层的结果输入一个激活函数/非线性单元
-
Sigmoid:
- σ ( x ) = 1 / ( 1 + e x ) \sigma(x)=1/(1+e^x) σ(x)=1/(1+ex)
- 将数字压缩到范围 [0,1],可以看成为神经元的饱和放电率
- problem:
1.饱和神经元使梯度消失(当x远离0时);
2.它的输出不是以零为中心的。 当一个神经元的输入始终为正时, w w w上的梯度都是正或负,导致梯度更新效率低下(这里没太懂)
3. 使用了指数函数,计算开销大
-
tanh(x)
- 将数字压缩为 [-1,1]
- Tanh 是一个缩放的 sigmoid: t a n h ( x ) = 2 σ ( 2 x ) − 1 tanh(x)=2\sigma(2x)-1 tanh(x)=2σ(2x)−1,以零为中心,但饱和时梯度消失
-
ReLU (Rectified Linear Unit) BEST!
- f ( x ) = m a x ( 0 , x ) f(x)=max(0,x) f(x)=max(0,x)
- 不会饱和(在+区域)
- 计算效率非常高(没有指数)
- 与实践中的 sigmoid/tanh 相比,大大加快了随机梯度下降的收敛速度
- 比 sigmoid 在生物学上更合理
- problem:
- 非零中心输出
- 当 x<=0 时梯度消失:dead ReLU。 所以人们喜欢用轻微的正偏置来初始化 ReLU 神经元。
-
Leaky ReLU (Good)
-
f ( x ) = m a x ( 0.1 x , x ) f(x)=max(0.1x, x) f(x)=max(0.1x,x)
-
没有任何饱和机制,梯度不会消失
-
-
Parametric ReLU(参数整流器 PReLU)
- f ( x ) = m a x ( α x , x ) f(x)=max(\alpha x,x) f(x)=max(αx,x)
- 作为反向传播要学习 的一个参数 α \alpha α
-
ELU (指数线性单元)
- f ( x ) = { x i f x > 0 α ( e x p ( x ) 1 ) i f x ≤ 0 f(x)= \left\{\begin{array}{lrc}x&if&x>0\\\alpha(exp(x)_1)&if&x\leq0\end{array}\right. f(x)={xα(exp(x)1)ififx>0x≤0
-
All benefits of ReLU
- 平均输入接近0
- 与 Leaky ReLU 相比,负饱和状态增加了对噪声的一些鲁棒性
-
SELU (Scaled Exponential Linear Units)
-
Maxout Neuron (Good)(最大神经元)
- f = m a x ( w 1 T x + b 1 , w 2 T + b 2 ) f=max(w_1^Tx+b_1,w_2^T+b_2) f=max(w1Tx+b1,w2T+b2)
- Generalizes ReLU and Leaky ReLU
- 线性制度:不会饱和/死亡
- 问题:参数数量加倍
Data Preprocessing(数据预处理)
-
零中心化:
X -= np.mean(x, axis = 0)
一般对于图像做零均值化的预处理(为了加快收敛)- 减去平均图像:AlexNet
- 减去每个通道的平均值:VGGNet
-
归一化:
X /= np.std(X, axis = 0)
所有特征都在相同值域内,且这些特征的贡献相同 -
任何预处理统计数据(例如数据均值)只能在训练数据上计算,然后应用于验证/测试数据
-
PCA and Whitening(白化)一般不会用
-
# Assume input data matrix X of size [N x D] X -= np.mean(X, axis = 0) # zero-center the data (important) cov = np.dot(X.T, X) / X.shape[0] # get the data covariance matrix U,S,V = np.linalg.svd(cov) # SVD factorization Xrot = np.dot(X, U) # decorrelate the data """ Using PCA: Xrot_reduced = np.dot(X, U[:,:100]) # Xrot_reduced becomes [N x 100] """ # whiten the data: # divide by the eigenvalues (which are square roots of the singular values) Xwhite = Xrot / np.sqrt(S + 1e-5)
-
-
初始化网络权值
-
参数对称问题:如果使用相同的值初始化所有权重,它们的梯度将完全相同并且行为相同
- 初始化太小:激活为零,梯度也为零,没有学习
- 初始化太大:激活饱和,梯度为零,没有学习
- 初始化恰到好处:所有层的激活分布很好,学习进展顺利
- 小随机数(但不适合深度网络,所有的激活值会变成零)
- Xavier 初始化:
W = np.random.randn(Din, Dout) / np.sqrt(Din) - Kaiming 初始化:由于 ReLU 杀死一半神经元,
W = np.random.randn(Din, Dout) / np.sqrt(Din / 2) - 将偏差初始化为零是可能且常见的,因为不对称性破坏是由权重中的小随机数提供的。
P14
某一层的输入均值不为0,方差不为1,该层网络权值矩阵的微小摄动就会造成该层输出的巨大摄动,所以进行中心化和归一化。
批量归一化
在网络的每一层输入的时候,又插入了一个归一化层,也就是先做一个归一化处理,然后再进入网络的下一层
思路:获得输入计算小批量均值,计算方差,然后进行归一化,然后还有额外的缩放和平移因子,从而改进了真个网络的梯度流,有更高的鲁棒性,可以在更广范围内的学习率和不同初始值下工作
- 为每个维度(逐元素)独立计算经验均值和方差(对于每个小批量)
- 归一化: x ^ ( k ) = x ( k ) − E [ x ( k ) ] V a r [ x ( k ) ] \hat{x}^{(k)}=\frac{x^{(k)}-E[x^{(k)}]}{\sqrt{Var[x^{(k) }]}} x^(k)=Var[x(k)]x(k)−E[x(k)]
E [ x ( k ) ] E[x^{(k)}] E[x(k)]指的是每一批训练数据神经元 x ( k ) x^{(k)} x(k)的平均值;分母就是每一批数据神经元 x ( k ) x^{(k)} x(k)激活度的标准差 - 完成归一化后需要进行额外的缩放操作,因为所学习到的特征分布被破坏,进行重构恢复:
缩放和平移: y ^ = γ ( k ) x ^ ( k ) + β ( k ) \hat{y}=\gamma ^{(k)}\hat{x}^{(k)}+\beta ^{(k)} y^=γ(k)x^(k)+β(k)
网络可以学习: γ ( k ) = V a r [ x ( k ) ] β ( k ) = E [ x ( k ) ] \gamma ^{(k)}=\sqrt{Var[x^{(k)}]}\ \ \ \ \beta^{(k)}=E[x^{(k)}] γ(k)=Var[x(k)] β(k)=E[x(k)] - 在 FC 或 Conv 层之后和非线性之前插入(Conv层:在每个激活图中会有一个均值和一个标准差,将在批处理的所有实例中进行归一化)
- 在测试时,使用训练期间的平均值(?)
- 过程传导公式:
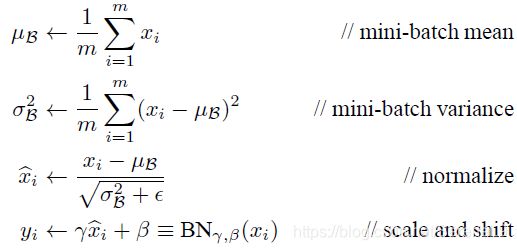 好处:
好处: - 改善通过网络的梯度流
- 允许更高的学习率,更快的收敛
- 减少对初始化的强烈依赖
- 作为正则化的一种形式
- 归一化: x ^ ( k ) = x ( k ) − E [ x ( k ) ] V a r [ x ( k ) ] \hat{x}^{(k)}=\frac{x^{(k)}-E[x^{(k)}]}{\sqrt{Var[x^{(k) }]}} x^(k)=Var[x(k)]x(k)−E[x(k)]
- 源码实现
m = K.mean(X, axis=-1, keepdims=True)#计算均值
std = K.std(X, axis=-1, keepdims=True)#计算标准差
X_normed = (X - m) / (std + self.epsilon)#归一化
out = self.gamma * X_normed + self.beta#重构变换
观察学习过程
-
预处理数据:零均值处理
-
选择架构
-
优化前的完整性检查:
- 在偶然表现中寻找正确的损失。 初始化网络进行前向传播,确保在使用小参数初始化时获得预期的损失。 最好先单独检查数据丢失(所以将正则化强度设置为零)
- 作为第二次健全性检查,增加正则化强度应该会增加损失
- 完美拟合一小部分数据。 在对完整数据集进行训练之前,尝试对数据的一小部分(例如 20 个示例)进行训练,并确保可以实现零成本。在这个实验中最好将正则化设置为零,为了观察是否能将训练损失降为0。
-
开始训练
- 应该监控的数量:损失、训练/验证准确率、更新幅度的比率、ConvNets 中的第一层权重
-
首先调整的参数:学习率
从小的正则化开始,找到使损失下降的学习率:[1e-3, 1e-5]- 如果损失没有变化,则说明学习率太低,但是准确率可能会变化,因为所有权重参数在朝正确方向轻微移动; 如果损失为 NaN,则意味着高学习率
- 如果训练准确率和验证准确率差距很大,那就是过拟合(增加正则化或者获取更多数据); 如果没有间隙,这意味着您可以增加模型容量
- 如果准确率还在上升,需要训练更长时间
-
提前停止:当验证损失开始上升时
-
超参数优化
-
学习率、更新类型、网格结构、隐藏层数量和深度、正则化、学习率衰减、模型大小
-
交叉验证
-
分阶段交叉验证:
-
从粗到细搜索:
- 第一阶段:只需要几个 epoch 就可以大致了解参数的工作原理(范围很广;1-5 个 epoch)
- 第二阶段:更长的运行时间,精细搜索(必要时重复;10-20 epochs)
-
采用对数来优化效果会更好:在一些区间用10的幂次进行采样而非均匀采样,因为学习率是乘以梯度更新,具有乘法效应
learning_rate = 10 ** uniform(-6, 1) -
-
但是一些参数是在原始比例中搜索的:
dropout = uniform(0,1) -
随机搜索有时比网格搜索更好
-
确保最佳值不在搜索区间的边缘
-
跟踪权重更新/权重大小的比率:大约 0.001
-
P15
更好的优化
-
SGD的问题(随机梯度下降):
- 最大梯度和最小梯度的最大比值可以相当大,在某一个维度上前进速度很慢,敏感度很低,在另一个维度上非常敏感,尤其是在高维问题中,导致SGD中的zig-zag path
- 局部最小值/鞍点(在高维更常见)
-
SGD + Momentum(非常小的方差):带动量的SGD
思想:保持一个不随时间变化的速度,并将梯度估计添加到这个速度上,然后在这个速度的方向上步进,摩擦系数可以对其衰减(滚下山的球在下降时速度变快,到了局部最小值的时候虽然没梯度但是还有速度)-
v ( t + 1 ) = ρ v t + ∇ f ( x t ) v_{(t+1)}=\rho v_t+\nabla f(x_t) v(t+1)=ρvt+∇f(xt) x t + 1 = x t − α v t + 1 x_{t+1}=x_t-\alpha v_{t+1} xt+1=xt−αvt+1
-
vx = 0 while True: dx = compute_gradient(x) vx = rho * vx + dx x -= learning_rate * vx -
速度就像梯度的运行平均值,rho 给出“摩擦系数”([0.5, 0.9, 0.95, 0.99])
-
速度和梯度加权和(矢量合成),可以克服梯度估计中的一些噪声
-
-
SGD + Nesterov Momentum:
- 带动量的SGD和Nesterov动量的不同:Nesterov有校正因子的存在,不会那么剧烈的越过局部极小值点
- v t + 1 = ρ v t − α ∇ f ( x t + ρ v t ) v_{t+1}=\rho v_t-\alpha \nabla f(x_t+\rho v_t) vt+1=ρvt−α∇f(xt+ρvt) x t + 1 = x t + v t + 1 x_{t+1}=x_t+v_{t+1} xt+1=xt+vt+1
- v t + 1 = ρ v t − α ∇ f ( x ~ t ) v_{t+1}=\rho v_t-\alpha \nabla f(\widetilde x_t) vt+1=ρvt−α∇f(x t) x ~ t + 1 = x ~ t + v t + 1 + ρ ( v t + 1 − v t ) \widetilde x_{t+1}=\widetilde x_t+v_{t+1}+\rho (v_{t+1}-v_t) x t+1=x t+vt+1+ρ(vt+1−vt) , x ~ t = x t + ρ v t \widetilde x_t=x_t+\rho v_t x t=xt+ρvt
-
dx = compute_gradient(x) old_v = v v = rho * v - learning_rate * dx x += -rho * old_v + (1 + rho) * v
-
AdaGrad算法——另一种常见的优化策略
-
grad_squared = 0 while True: dx = compute_gradient(x) grad_squared += dx * dx x -= learning_rate * dx / (np.sqrt(grad_squared) + 1e-7)
-
设置全局学习率之后,每次通过,全局学习率逐参数的除以历史梯度平方和的平方根,使得每个参数的学习率不同。
起到的效果是在参数空间更为平缓的方向,会取得更大的进步(因为平缓,所以历史梯度平方和较小,对应学习下降的幅度较小),并且能够使得陡峭的方向变得平缓,从而加快训练速度。
-
根据每个维度的历史平方和添加梯度的元素级缩放
-
步长会越来越小,凸问题时这个特征的效果很好,因为接近极值点时速度会慢下来最后达到收敛
-
RMSProp(AdaGrad变体 考虑到步长越来越小在非凸问题效果不好)
让平方梯度按照一定比率下降-
grad_squared = 0 while True: dx = compute_gradient(x) grad_squared = decay_rate * grad_squared + (1 - decay_rate) * dx * dx x -= learning_rate * dx / (np.sqrt(grad_squared) + 1e-7)
-
-
Adam
结合体! 更新第一动量(梯度加权和)和第二动量(梯度平方的动态近似值)的估计值,使用第一动量的值,除以第二动量/第二动量的平方根,类似于RMSProp+动量。-
first_moment = 0 second_moment = 0 for t in range(num_iterations): dx = compute_gradient(x) first_moment = beta1 * first_moment + (1 - beta1) * dx # Momentum second_moment = beta2 * second_moment + (1 - beta2) * dx * dx # RMSProp first_unbias = first_moment / (1 - beta1 ** t) # t is your iteration counter going from 1 to infinity second_unbias = second_moment / (1 - beta2 ** t) # bias correction x -= learning_rate * first_moment / (np.sqrt(second_moment) + 1e-8) # AdaGrad/RMSProp
-
-
一般可以使用 beta1 = 0.9、beta2 = 0.999 和 learning_rate = 1e-3 或 5e-4
-
可能会初始化的时候得到很大的步长,因此构造第一和第二动量的无偏估计来做每一步更新,通过使用当前时间步t
-
Adam 使用 平方梯度和动量的指数加权平均 (EWA)
-
学习率
- 学习率随时间衰减:
- 步长衰减:每隔几个 epoch 将学习率衰减一半。 在实践中可能会看到的一种启发式方法是在以固定学习率训练时观察验证错误,并在验证错误停止改善时将学习率降低一个常数(例如 0.5)。
- 指数衰减: α = α 0 e − k t \alpha = \alpha_0e^{-kt} α=α0e−kt,其中 α 0 , k \alpha _0 , k α0,k 是超参数, t t t 是迭代次数(也可以使用纪元单位)
- 余弦衰减: α t = 1 2 α 0 ( 1 + c o s ( t π / T ) ) \alpha_t=\frac{1}{2}\alpha_0(1+cos(t\pi /T)) αt=21α0(1+cos(tπ/T))
- 线性衰减: α t = α 0 ( 1 − t / T ) \alpha_t=\alpha_0(1-t/T) αt=α0(1−t/T)
- 逆sqrt: α t = α 0 / t \alpha_t=\alpha_0/\sqrt t αt=α0/t
- 1/t 衰减: α = α 0 / ( 1 + k t ) \alpha = \alpha_0/(1+kt) α=α0/(1+kt)
- 开始不衰减,观察损失曲线,找到需要衰减的地方
- 热身:高初始学习率可以让损失爆炸; 在前 5000 次迭代中从 0 线性增加学习率可以防止这种情况
- 如果将batch size增加N,初始学习率也增加N
?????下面有一段看不懂!
- 学习率随时间衰减:
-
一阶优化:使用梯度形式线性逼近,并逐步最小化逼近
-
二阶优化:使用梯度和Hessian形成二次逼近,并逐步逼近逼近的最小值
- θ ∗ = θ 0 − H − 1 ∇ θ J ( θ 0 ) \theta^* = \theta_0-H^{-1}\nabla_{\theta}J(\theta_0) θ∗=θ0−H−1∇θJ(θ0)
- 无学习率
- 计算 Hessian 的成本非常高
- 寻求近似逆 Hessian 的拟牛顿方法(BGFS 最受欢迎)
- L-BFGS(二阶优化器):不形成/存储完整的逆 Hessian 并且在整批中运行良好(较少的随机数据),如果能够承受整个批次的更新而且没什么随机性就可以用这个。
- 二阶逼近的方法对随机的情况处理的不多,在非凸问题上也表现的不好
如何减少训练和测试之间的误差差距?
- 模型集成(model ensembles)
- 训练多个独立模型并在测试时平均它们的结果:不巨大却固定的提升
- 相同的模型,不同的初始化
- 在交叉验证期间发现的顶级模型
- 在训练期间使用单个模型的多个快照,通过不同的学习率,忽快忽慢,模型会收敛到目标函数不同的区域
- 在测试时使用参数向量的移动平均值
- Polyak平均:训练模型时对不同时刻的每个模型参数求指数衰减平均值,从而得到网络训练中一个比较平滑的集成模型,之后使用这些平滑衰减的平均后的模型参数
- 训练多个独立模型并在测试时平均它们的结果:不巨大却固定的提升
P16 正则化(三种)
-
L1、L2、最大范数
-
Dropout:对正则化神经网络有很大帮助,需要更长的训练时间,但收敛后模型鲁棒性更好
-
在每次正向传递中,随机将一些神经元设置为零(将激活函数置零)
-
避免了特征间的相互适应
-
丢弃概率是一个超参数:常见为0.5
-
p = 0.5 def train_step(X): # forward pass for 3-layer neural network H1 = np.maximum(0, np.dot(W1, X) + b1) U1 = np.random.rand(*H1.shape) < p # first dropout mask H1 *= U1 # drop! H2 = np.maximum(0, np.dot(W2, H1) + b2) U2 = np.random.rand(*H2.shape) < p # first dropout mask H2 *= U2 # drop! out = np.dot(W3, H2) + b3 def predict(X): # ensembke forward pass H1 = np.maximum(0, no.dot(W1, X) + b1) * p H2 = np.maximum(0, no.dot(W2, X) + b2) * p # scale at test-time out = np.dot(W3, H2) + b3 -
可以解释为在单个模型中进行模型集成:在一个子网络中用所有神经元的子集进行运算,每一种可能的dropout方式可以产生一个不同的子网络,每个二元掩码是一个模型( 2 N 2^N 2N 模型)
-
Dropout 使输出随机化(训练): y = f W ( x , z ) y=f_W(x,z) y=fW(x,z)
-
在测试时:(消除随机性)通过一些积分来边缘化随机性。???
- y = f ( x ) = E z [ f ( x , z ) ] = ∫ p ( z ) f ( x , z ) d z y=f(x)=E_z[f(x,z)]=\int p(z)f(x,z)dz y=f(x)=Ez[f(x,z)]=∫p(z)f(x,z)dz
- 想要近似积分:在测试时,没有任何随机性,用输出乘以 dropout 概率(简易地局部逼近)??
-
-
反转 dropout:测试时候注重效率,消除乘法,则使用整个权重矩阵,但是在训练时除以p??
-
p = 0.5 def train_step(X): # forward pass for 3-layer neural network H1 = np.maximum(0, np.dot(W1, X) + b1) U1 = (np.random.rand(*H1.shape) < p) / p # first dropout mask H1 *= U1 # drop! H2 = np.maximum(0, np.dot(W2, H1) + b2) U2 = (np.random.rand(*H2.shape) < p) / p # first dropout mask H2 *= U2 # drop! out = np.dot(W3, H2) + b3 def predict(X): # ensembke forward pass H1 = np.maximum(0, no.dot(W1, X) + b1) * p H2 = np.maximum(0, no.dot(W2, X) + b2) * p # scale at test-time out = np.dot(W3, H2) + b3
-
-
batch normalization的作用相同:**在训练时添加噪声或随机性,并在测试时抵消掉它们,使用一些基于全局估计地正则化 **,但是相比dropout,BN没有控制机制(??)
-
数据增强(在不改变标签的情况下转换数据):另一种符合范式的策略,对网络有正则化效果,训练时增加了某种随机性,测试时又淡化
- 随机作物和规模
- 训练:样本随机裁剪/规模
- 测试:评估一些固定的裁剪图像来抵消随机性
- 色彩抖动(color jittering)(随机大小的对比度和亮度)
- 随机混合/组合:平移、旋转、拉伸、剪切、镜头扭曲……
- 随机作物和规模
-
DropConnect:随机将权重矩阵的一些值归零
-
部分最大池化
-
随机深度:训练时随机从网络中丢弃部分层,测试时用全部网络
-
小分类数据集的剪切/混合
一般用batch normalization就行,如果不够就加dropout之类的
P17 迁移学习
- 过拟合的原因之一是没有足够的数据,希望得到一个大的网络,但是在小数据集上很容易过拟合,迁移学习就可以实现:不需要超大样本集训练CNN.
把从大数据集中训练出的提取特征的能力用到感兴趣的小数据集:
1.很少的数据:修改从最后一层的特征到最后的分类输出之间的全连接层,重新随机初始化这部分矩阵,训练一个线性分类器(只训练最后一层,在数据上收敛)
2.数据稍微充裕;微调(fine tuning)整个网络,更新权值
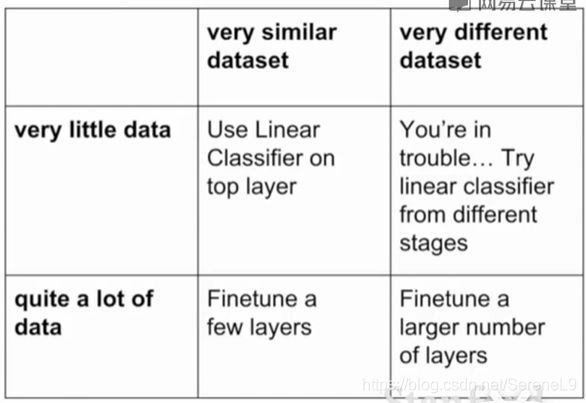
P18 深度学习软件
-CPU vs GPU
-Deep Learning Frameworks
-Caffe
-TensorFlow
-PyTorch
Hardware and software
GPU(graphics card图形卡)
-
与CPU相比:更多核心,但每个核心慢很多,能执行的操作更少,擅长做并行任务:矩阵乘法
-
CUDA:在GPU上直接执行的类C代码
-
OpenCL:可在GPU、AMD、CPU上运行
-
流式多处理器:FP32 核心、Tensor 核心(4x4 矩阵)
-
TensorFlow中 可以把计算划分为两个阶段:1.定义计算图;2.实际运行计算图并输入数据
Pytorch
明确定义了三层结构,张量对象就像Numpy,只是一种最基本的数组,与深度学习无关
PyTorch 张量 ≈ TensorFlow Numpy array(看成Numpy+GPU)
变量 ≈ 张量 变量 占位符(都算一个节点)
模 ≈ tf.slim tf.layersr,sonnet
更倾向于针对所有问题的架构:T是一个很稳妥的选择,适应所有环境、场景
只写研究性代码,选择P,P适合科研,
-
Autograd
-
Requires_grad = True -
Loss.backward()
-
-
梯度被累加到 w1.grad 和 w2.grad 中,图被破坏
- 将梯度设置为零:
w1.grad.zero_() w2.grad.zero_()- 使用优化器更新参数和零梯度:
optimizer.step() optimizer.zero_grad()
-
可以定义新函数,但是pytorch还是一步步创建计算图(数值不稳定)
- 通过子类化函数定义新的 autograd 运算符,定义向前和向后
class Sigmoid(torch.autograd.Function): @staticmethod def forward(): @staticmethod def backward(): def sigmoid(x): return Sigmoid.apply(x)- 只向图中添加一个节点
-
模块
- 将模块定义为 torch.nn.Module 子类
class TwoLayerNet(torch.nn.Module): def __init__(self, D_in, H, D_out): super(TwoLayerNet, self).__init__(): # ... def forward(self, x): # ... # no need to define backward - autograd will handle it -
按顺序堆叠组件的多个实例:
model = torch.nn.Sequential() -
预训练模型:torchvision
-
动态计算图:
-
构建图和计算图同时发生
-
在前向传递期间使用常规 Python 控制流
-
-
应用:依赖于输入的模型结构(RNN)
-
静态计算图:
- 构建描述我们计算的计算图
- 在每次迭代中重用相同的图
@torch.jit.script # python function compiled to a graph when it is defined
| Static | Dynamic | |
|---|---|---|
| Optimization | Framework can optimize the graph before it runs | None |
| Serialization | Once the graph is built, can serialize it and run it without the code (tarin model in Python, deploy in C++) | Graph building and execution are intertwined, so always need to keep code around (RNN) |
| Debugging | Lots of indirection - can be hard to debug, benchmark, etc | The code u write is the code that runs. Easy to reason about, debug |
P19 CNN架构
Net Architecture
-
一些索引:
-
内存:KB =(输出元素的数量)*(每个元素的字节数)/ 1024 = (C * H’ * W’) * 4 [对于 32 位浮点] / 1024
-
参数:权重数 =(权重shape)+(偏置shape) = C’ * C * H * W + C’
-
浮点运算次数(flop:乘法+加法)=(输出元素的数量)*(每个输出元素的操作数)= (C’ * H’ * W’) * (C * H * W)
-
AlexNet (2012)
(卷积层-池化层-归一化层-卷积层… 全连接层)
- 模型拆分到两个 GPU
- 大部分内存使用在早期的卷积层
- 几乎所有参数都在 fc 层
- 大多数浮点运算发生在卷积层
ZFNet (2013)
- AlexNet的基础上对超参进行了改变
- AlexNet 和 ZFNet 的架构都是通过反复试验设置的(手工设计)
VGG (2014)
-
很深的网络 很小的卷积核(小的话可以尝试更深的网络和更多的卷积核)
-
大多数内存在前面的卷积层,大量的参数在后面的全连接层(因为有很多密切的连接)
-
不需要局部响应归一化
-
VGG Design rules:
- 所有 conv 都是 3x3 stride 1 pad 1
- 所有最大池都是 2x2 步长 2
- After pool, double #channels
-
Have 5 conv stages:
- conv-conv-pool
- conv-conv-pool
- conv-conv-pool
- conv-conv-conv-[conv]-pool
- conv-conv-conv-[conv]-pool (VGG19 have 4 conv in stage 4 and 5)
-
两个 3x3 conv 与单个 5x5 conv 具有相同的感受野,但参数更少,计算量更少。 另外,通过插入 ReLU,两个 3x3 conv 可以具有更多的非线性
-
每个空间分辨率的卷积层通过加倍通道并将其空间分辨率减半进行相同的计算
GoogLeNet (2014)
-
类似于VGGNet
-
效率创新,高效计算
-
干网络在开始时积极地对输入进行下采样
-
没有全连接层,参数量小很多
-
Inception 模块:具有并行分支的本地单元,在整个网络中重复多次,高效计算(局部网络拓扑)
- 对进入相同层的相同输入 并行应用不同类别的滤波(filter)操作,然后串联输出,保留了相同尺寸但增加了深度。
- 尝试所有大小的内核而不是将其设置为超参数
- 使用 1x1 瓶颈层在需要消耗昂贵运算力的 conv(卷积层) 之前降低特征图的维度,减小深度。
关于inception和1×1卷积参考
-
使用全局平均池化来折叠空间维度,并使用一个线性层来产生类分数
-
辅助分类器:BN后不再需要使用它
ResNet (2015)(超级深!)
- 问题:更深的网络比浅的网络表现更差
- 假设:更深的网络更难优化,不学习恒等函数来模拟浅层模型
- 解决方案:只需从较浅的模型中复制学习到的层并将附加层设置为身份映射。
- 每层都尝试学习一些所需函数的底层映射,残差块的输入只是传输进来的输入,用我们的层去拟合想要的残差H(X)-X代替H(X),残差块互相堆叠对于一个堆积层结构(几层堆积而成)当输入为x时其学习到的特征记为H(x) ,现在我们希望其可以学习到残差F(x)=H(x)-x,这样其实原始的学习特征是F(x)+x。之所以这样是因为残差学习相比原始特征直接学习更容易。当残差为0时,此时堆积层仅仅做了恒等映射,至少网络性能不会下降,实际上残差不会为0,这也会使得堆积层在输入特征基础上学习到新的特征,从而拥有更好的性能。残差学习的结构如图所示。这有点类似与电路中的“短路”,所以是一种短路连接(shortcut connection)。
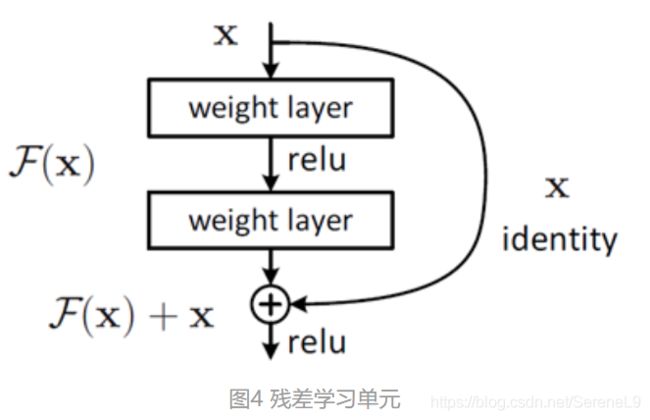
-
更改网络,以便轻松学习具有额外层的身份函数
-
剩余块:
- Basic block: two 3x3 conv
- Bottleneck block: 1x1 conv(降低到更小的深度) + 3x3 conv + 1x1 conv(恢复到原来的深度)
- Pre-action block:ReLU inside残差 -> 可以通过将 Conv 权重设置为零来学习真实身份函数
-
网络分为像 VGG 一样的阶段:每个阶段的第一个块将分辨率减半(使用 stride-2 conv)并将通道数加倍
-
使用与 GoogLeNet 相同的主动词干在应用残差块之前对 inout 进行 4x 下采样
-
使用全局平均池
-
改进 ResNets:ResNeXt(组卷积)
循环神经网络(Recurrent Neural Network)
RNN:处理序列
每一个RNN有一个小小的循环核心单元,RNN有一个内部隐藏态(internal hidden state)会在每次读取新输入x时更新,然后这一隐藏态会在模型下一次读取输入时将结果反馈至模型,让RNN在每一时步都能给出输出,在RNN中,有隐藏向量,可能每一步都会更新一些向量。
- 循环过程的计算公式:

其中f函数依赖权重W
-
共享权重:在每个时间戳使用相同的权重矩阵 W,即相同的函数f
-
最终的隐层状态做决策(整合了序列中包含的所有情况)

-
vanilla RNN (最简单的函数式)
- h t = t a n h ( W h h h t − 1 + W x h x t ) h_t=tanh(W_{hh}h_{t-1}+W_{xh}x_t) ht=tanh(Whhht−1+Wxhxt)
- y t = W h y h t y_t=W_{hy}h_t yt=Whyht
- h 0 h_0 h0 要么设置为全 0,要么学习它
-
Seq2seq
- 语言建模(递归神经网络领域)
- 让神经网络在一定程度上学会生成自然语言
- 将输入以one-hot编码的向量形式输入
- 过程: 前向整个序列计算损失,(得到不满意的结果,使用Softmax损失函数来度量对预测结果的不满意程度)后向整个序列计算梯度(输入一个字母,会产生一个基于词库中所有的字母得分的分布,训练阶段用这个分布去输出一个结果,用Softmax将得分转换成一个概率分布)
- 模型生成序列的过程:基于上一个时间步内预测得到的概率分布,在下一个时间步内生成一个新的字母
- 沿时间的截断反向传播方法:前向计算若干步子序列的损失值,然后沿这个子序列反向传播误差,并计算梯度更新参数,重复上述操作会得到网络中一些隐藏状态(从第一批数据得到的),然后计算下一批,使用这些隐藏状态,所以前向计算过程是相同的,但是根据第二批数据反向传播误差
-
图像标注模型(image captioning model)
- CNN处理图像,然后使用来自模型末端的4096维向量,用这个向量概述整个图像的内容,然后给出一些特殊的开始记号告诉模型开始生成文字,一旦采样到特殊停止标记(ends token)就停止生成
-
VQA
- CNN和RNN连接起来得到的模型
- 将自然语言序列作为输入,设想针对输入问题的每个元素建立递归神经网络,将输入的问题概括为一个向量,然后用CNN将图像概括为一个向量,将图像向量和输入问题的向量结合(直接连接然后粘贴进全连接层中,更高级一点:在向量之间做乘法),通过RNN变成预测答案的概率分布
-
带有自然语言标题的图像的数据集:COCO
-
Vanilla RNN 梯度流
-
计算到 h 0 h_0 h0 的梯度包含 W 和重复 tanh 的许多因素(几乎总是 < 1):爆炸/消失梯度,要关注权重矩阵最大的奇异值,>1会爆炸,<1会梯度消失
- Explodin Gradients解决办法:梯度截断(gradient clipping) -> 如果梯度L2范数大于阈值,就将其剪断并做除法,则缩放梯度
grad_norm = np.sum(grad * grad) if grad_norm > threshold: grad *= (threshold / grad_norm)- Vanishing Gradients解决办法: 换一个更复杂的RNN结构(也是使用LSTM的原因)
LSTM——长短期记忆网络:递归神经网络一种更高级的递归结构
-
用来缓解梯度消失和梯度爆炸的问题,获取更好的梯度流动。相比普通的RNN,LSTM能够在更长的序列中有更好的表现。
-
每个时间步维持两个隐藏状态:ht(隐藏状态),ct(单元状态:保留在LSTM内部的隐藏状态,并不会完全暴露到外部),
-
c t = f ⊙ c t − 1 + i ⊙ g c_t=f\odot c_{t-1}+i\odot g ct=f⊙ct−1+i⊙g
h t = o ⊙ t a n h ( c t ) h_t=o\odot tanh(c_t) ht=o⊙tanh(ct)
-
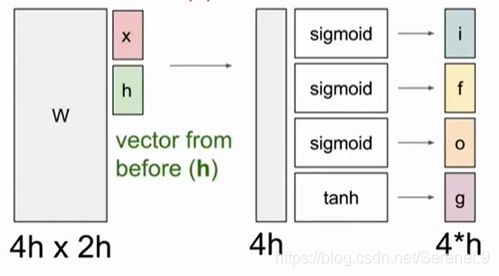
过程:使用四个门来更新单元状态ct,然后将这些单元状态作为参数计算下一个时间步中的隐藏状态。LSTM中要做的第一件事:将前一时刻的隐藏状态ht和当前输入向量xt堆叠到一起,然后乘很大的权重矩阵w得到四个不同的门向量,每个门向量的大小和隐状态都一样。计算了单元状态ct后,通过更新过的单元状态计算隐状态ht
-
i: 输入门,LSTM要接受多少新的输入信息
-
f: 遗忘门,要遗忘多少之前的单元记忆
-
o: 输出门,要展示多少信息给外部
-
g: gate gate, 要写多少信息到输入单元
-
这四个门都用了不同的非线性函数ifo:sigmoid,输出[0,1],g:tanh 输出[-1,1]
-
在单元状态内部可以保留/遗忘之前的状态,在每个时间步中,可以给单元状态的每个元素±x(x≤1),可以把单元状态的每个元素看作小的标量计数器,每个时间步只能自增/自减
-
-
LSTM如图所示:

-
梯度流:
- 从 c t c_t ct 到 c t − 1 c_{t-1} ct−1 的反向传播仅元素乘以 f f f (遗忘门)(在 [-1,1] 之间),进行的是矩阵元素相乘而不是矩阵相乘
- 不间断的梯度流(类似于 ResNet)(高速公路 这里没懂)
- 允许更好地控制梯度值,使用合适的遗忘门参数更新
- 通过 f、i、g、o 门添加:更好地平衡梯度值
- LSTM 使 RNN 更容易保存多个时间步长的信息(如果 f = 1,i = 0,则该单元格的信息将无限期保存)
- LSTM 不保证没有消失/爆炸梯度,但它为模型学习长距离依赖关系提供了一种更简单的方法
- 初始化遗忘门的偏置参数,使其成为达到某种程度的正数(?)
Seq2seq:
- 多对一(编码器): h t = f W ( x t , h t − 1 ) h_t=f_W(x_t,h_{t-1}) ht=fW(xt,ht−1)
- 初始解码器状态 s 0 s_0 s0
- 上下文向量 c c c(通常 c = h t c=h_t c=ht)
- 一对多(解码器): s t = g U ( y t − 1 , h t − 1 , c ) s_t=g_U(y_{t-1},h_{t-1},c) st=gU(yt−1,ht−1,c)
- 通过固定大小的向量限制输入序列
Attention (注意力模型)
允许模型引导它们的注意到图像的不同部分,给每个图片中特殊的地方都用一个向量表示,把这个模型向前运行时,除了在每一步中采样,也会产生一个分布,即在图像中它想要看的位置,图像位置的分布可以看成一种模型在训练过程中应该关注哪里的张量,会在生成每个图片标题单词时在图像中转移注意力
- 对齐分数: e t , i = f a t t ( s t − 1 , h i ) e_{t,i}=f_{att}(s_{t-1},h_i) et,i=fatt(st−1,hi)( f a t t f_{att} fatt 是一个 MLP(多层感知机))
- 标准化对齐分数以获得注意力权重(使用 Softmax): ∑ i a t , i = 1 , 0 < a t , i < 1 \sum_ia_{t,i}=1, 0
- 计算上下文向量作为隐藏状态的线性组合: c t = ∑ i a t , i h i c_t=\sum_ia_{t,i}h_i ct=∑iat,ihi
- 在解码器上使用上下文向量: s t = g U ( y t − 1 , c t , s t − 1 ) s_t=g_U(y_{t-1},c_t,s_{t-1}) st=gU(yt−1,ct,st−1)
- 使用 RNN 和注意力的图像字幕:解码器的每个时间步使用不同的上下文向量,查看输入图像的不同部分
- 解码器不使用 h i h_i hi 形成有序序列的事实 - 它只是将它们视为无序集合 { h i } \{h_i\} {hi}
- X, Attend, and Y: Show, attend, and tell/read
- 注意层:
- 输入:
1.查询向量: Q Q Q(Shape: N Q × D Q N_Q \times D_Q NQ×DQ)(多个查询向量)
2. 输入向量: X X X(形状: N X × D X N_X\times D_X NX×DX)
3.相似度函数:scaled dot product而不是 f a t t f_{att} fatt(大的相似度会导致softmax饱和并给出消失的梯度)
- 输入:
对抗性机器学习
-
机器学习模型可以被对手攻击
-
攻击示例:输入扰动
- 目标:找到一个小的扰动 δ i \delta_i δi 使得 f ( x i + δ i ) ≠ f ( x i ) f(x_i+\delta_i)\neq f(x_i) f(xi+δi)=f(xi)(非目标)
- 扰动小到人眼可能察觉不到
-
对抗性输入攻击
- 白盒攻击
- 黑盒攻击:对手可以查询模型,但无法访问其内部结构(权重等)
- 对于有针对性的攻击,减少到目标标签的距离并与梯度相反
-
训练期间的数据中毒攻击
-
逃避攻击
可视化和理解
-
mnist数据集: 0-9之间的手写数字构成的
-
MIT数据集:200中不同的场景类别
-
第一个卷积层的卷积核:寻找有向边(明暗线条)、相反的颜色…
-
最后一层
- 近邻法:在由卷积神经网络计算的4096维特征空间(特性:捕捉图像的语义内容)中计算近邻
- 降维:PCA、t-SNE(t-分布邻域嵌入:深度学习中常用的可视化特征的非线性降维方法)
-
可视化激活:最大程度激活的图像块(activating patches)?
-
输入图像的哪个部分影响了神经网络内部神经元的分值
-
排除实验(exclusion experiment):过遮挡显着性:在提供给 CNN 之前屏蔽部分图像,检查预测概率有多少变化。
-
利用Salient Map(显著图):每个像素影响该图像的分类分数的程度
-
引导式反向传播:计算神经网络中某些中间值相对于图像像素的梯度
-
通过(引导)反向传播的中间特征
-
梯度上升
- 生成最大程度激活神经元的合成图像
- I ∗ = a r g m a x I f ( I ) + R ( I ) I^*=argmax_If(I)+R(I) I∗=argmaxIf(I)+R(I)
- 简单的正则化器: R ( I ) = λ ∥ I ∥ 2 2 R(I)=\lambda\parallel I\parallel^2_2 R(I)=λ∥I∥22 使图像更自然
- 图像正则化:惩罚生成图像的L2范数,一旦加入更好的正则化方法,生成图像会一点点变得更加清晰
- 定期在优化过程中对图像进行高斯模糊处理,图像会获得特殊平滑性
-
fooling image (愚弄图像)
-
特征反转
- 给定一个图像的 CNN 特征向量,找到一个新图像
1.匹配给定特征向量
2.看起来自然(图像先验正则化)
- 给定一个图像的 CNN 特征向量,找到一个新图像
-
DeepDream:基于梯度的图像优化,试图放大神经网络在图像中检测到的特征
- 在 CNN 中选择图像和图层;重复:
- Forward:计算所选层的激活
- 设置所选层的梯度等于其激活(特征值)
- 向后:计算 tmage 上的梯度
- 更新图片:: I ∗ = a r g m a x I ∑ I f i ( I ) 2 I^*=argmax_I\sum_If_i(I)^2 I∗=argmaxI∑Ifi(I)2
- 技巧:计算梯度之前抖动图片(使用正则化以使图像更加平滑)
- 随着图像在神经网络中层数的上升,可能会丢失图像真实像素的低层次信息,试图保留图像的更多语义信息
- 在 CNN 中选择图像和图层;重复:
-
纹理合成(没看懂呵呵):简单的纹理可以没有神经网络,直接从输入图像的图像块复制像素;复杂的纹理:神经网络,使用Gram 矩阵,利用卷积神经网络抽取纹理的卷积特征,得到描述符,重构输入图像的gram矩阵
-
神经风格迁移:把两张图作为输入,其中一张作为内容图像引导生成图像的主体,另一张为风格图像负责生成图像的纹理/风格,共同做特征识别,最小化内容图像的特征重构损失和风格图像的gram矩阵损失,在生成图像上执行梯度上升,特征(高级)+ Gram 重建(低级),效率很低
目标检测 (分割、定位、检测)
任务定义
分类和定位:与目标检测不同,提前知道会有一个物体是要找的
- 损失函数:softmax损失、衡量预测坐标和实际值不同的损失(L2、L1),然后在两种损失上加权求和。一般用关心的性能指标组成的矩阵来取代原本的损失值(用最终性能矩阵做交叉验证)
- addition:分类使用交叉熵损失、softmax损失、SVM margin type loss,回归问题使用L2、L1等
目标检测:对应每一张输入图像,对象数量不定
- 输入:单个 RGB 图像
- 输出:一组检测到的物体; 对于每个对象预测:(分类和定位)
- 类别标签(来自固定的、已知的类别集)
- Bouding box(边界参数:x、y、宽、高)
- 挑战
- 多个输出
- 多种类型的输出:“what”和“where”
- 大图像:检测分辨率更高
检测单个对象:(分类和定位)
- 正确标签:Softmax Loss
- 正确框:L2 损失
- 多任务损失:加权总和
检测多个对象:滑动窗口
- 分类:对象或背景(没有见过既定范畴之外的其他对象)
- Region Proposals(候选区域):采用候选区域网络,找到一小组可能覆盖所有对象的框,然后寻找图像的边界,划定闭合的限定框,应用CNN对这些备选区域分类。
R-CNN:基于区域的 CNN
- 运行区域选择网络,找到备选区域/感兴趣的区域(ROI),因为都需要通过CNN进行分类,所以要处理区域切分成固定尺寸,使之与下游网络输入相匹配。(注:区域选择是固定算法,不是自学习的)
- 根据与真实值框的重叠将每个区域提议分类为正、负或中性
- 预测边界的补偿和修正值
Fast R-CNN
- 不再按兴趣区域处理,通过卷积层ConvNet得到整个图像的高分辨率特征映射。
- 仍然使用一些固定的东西,比如选择性搜索,但不是针对备选区域切分图像的像素,而是我们想象将这些备选区域投影到这个卷积特征图上,然后从卷积特征映射提取中获取属于备选区域的卷积块,而不是直接截取备选区域。
- 对从卷积映射提取的图像块进行裁剪和调整大小:RoI Pool(兴趣区域池化层) / RoI Align(双线性插值)
- 对于反向传播必须是可微的
- 问题:改进的瓶颈为备选区域的寻找
解决:让网络做预测,在卷积层中运行整个输入图像获取特征映射,分离备选区域网络工作于卷积特征的上层
Faster R-CNN:基于候选框的方法
- 将区域的选择看成端到端的回归问题,然后对提出的区域分别进行处理
语义分割
不足:为每个像素分类,但不区分同类事物
表现较好的模型:全连接卷积网络,用张量对每个像素进行预测,给出评分,对每个像素分配损失(交叉熵损失函数)并平均化,用反向传播来训练
- 问题
- 有效感受野大小与卷积层数呈线性关系:使用 3x3 卷积层,感受野为 1 + 2L
- 高分辨率图像的卷积代价高昂
- 解决:在图像内做下采样,之后对特征做 上采样
- 下采样:最大池化/跨卷积(可学习的层)
- 上采样:
- “Unpooling”
- 最近距离去池化:在去池化区域中重复每个元素
- 钉床函数去池化:取输入放在左上角,其他的设置为0
- 最大去池化:将最大值放入记住的位置,用 0 填充
- 可学习的上采样:卷积转置(没看懂),既上采样特征图,又可学习权重
- 按输入值过滤权重并复制到输出
- 步幅给出输出和输入移动之间的比率
实例分割(物体分割)(混合语义分割和目标检测)
- 使用Mask R-CNN:将整张图片送入卷积网络中和训练好的候选框生成网络,得到训练好的候选框后,将候选框投射到卷积特征图,对齐到特征后有两个分支:1.像Faster R-CNN,预测类别分数和边界框坐标(通过回归);2.像语义分割的微型网络,对输入候选框的像素分类,确定是否属于某个物体。
- train on COCO(20w张训练图像,80个类别,平均每张图像有5-6个物体)
生成模型(无监督学习的一种)
三种:pixelRNNs和pixelCNNs、变分自编码器VAE、生成式对抗网络GAN
监督与无监督学习
-
监督学习:学习一个函数来映射 x -> y(分类、回归、对象检测、语义分割、图像字幕)
-
无监督学习:学习数据的一些底层隐藏结构(聚类、降维、特征学习、密度估计)
判别模型与生成模型
- 判别模型:
- 学习概率分布 p ( y ∣ x ) p(y|x) p(y∣x)
- 每个输入的可能标签竞争概率质量
- 不能处理不合理的输入,它必须为所有图像给出标签分布
- 应用:
- 为数据分配标签
- 特征学习(带标签)
- 生成模型:
- 学习概率分布 p ( x ) p(x) p(x)
- 所有可能的图像相互竞争概率质量
- 模型可以通过分配较小的值来拒绝不合理的输入
- 应用:
- 检测异常值
- 特征学习(无标签)
- 生成新数据的示例
- 条件生成模型:学习 p ( x ∣ y ) p(x|y) p(x∣y)
- 每个可能的标签都会引发所有图像之间的竞争
- P ( x ∣ y ) = P ( y ∣ x ) P ( y ) P ( x ) P(x|y)=\frac{P(y|x)}{P(y)}P(x) P(x∣y)=P(y)P(y∣x)P(x)
- 应用:
- 分配标签,同时拒绝异常值
- 生成以输入标签为条件的新数据
生成式建模
- 给定训练数据,从相同数据分布中生成新样本
- 使隐式表征的推断成为可能,学习隐式表征对于下游任务(可作为一般特征)很有用。
- 可以解决密度估计问题,估计训练数据的潜在分布
- 公式化为密度估计问题:
- 显式密度估计:显式定义并求解 p m o d e l ( x ) p_{model}(x) pmodel(x)
- 隐式密度估计:学习可以从 p m o d e l ( x ) p_{model}(x) pmodel(x) 中采样而无需明确定义的模型
- https://deepgenerativemodels.github.io/notes/
pixelRNNs和pixelCNNs
- 全可见信念网络,对一个密度分布显示建模
- 最大化训练数据的似然
- 定义了一个易处理的密度函数
- pixelRNN
- 一次生成一个图像像素,在左上角分层,一个接一个生成,序列中每一个对之前像素的依赖关系都会通过RNN来建模
- h x , y = f ( h x − 1 , y , h x , y − 1 , W ) h_{x,y}=f(h_{x-1,y},h_{x,y-1},W) hx,y=f(hx−1,y,hx,y−1,W)
- 缺点:序列生成在训练和推理中都很慢
- pixelCNN
- 每个像素位置有正确标注值:所期望生成的像素值
变分自动编码器
定义一个不易处理的密度函数,通过附加的隐变量Z对其建模
-
难处理的密度:优化下界
-
自编码器(常规)
- 输入:x 学习特征:z encoder:x->z(通常是神经网络)
- 使用特征通过解码器重构输入数据(相同维度、相似)
- 损失函数: ∣ ∣ x ^ − x ∣ ∣ 2 2 ||\hat x-x||^2_2 ∣∣x^−x∣∣22
- 特征需要比输入数据低维:捕捉有意义的数据变化因素的特征
- 编码器可用于初始化监督模型,比如输出类标签,用许多无标签训练数据习得很好的普适特征表征。
- 无法从学到的数据中采样新数据
-
变分自编码器(几乎没听懂- -)
- 向自编码器中加入随机因子,可以从该模型中采样从而生成新数据。
- 从原始数据中学习潜在特征 z
- 从模型中采样以生成新数据
- 对每种属性假设简单的先验 p(z),例如高斯
- 用神经网络表示 p(x|z)(类似于解码器)
- 数据的似然函数难解,无法直接优化
解决:额外定义一个编码器q(z|x),得到一个数据似然的下界。(没看懂哈哈 ) - 优点:有据可循,使查询推断成为可能;缺点:最大化似然函数下界不直接。
变分自动编码器是一种生成模型的方法,但与最先进的 (GAN) 相比,样本更模糊且质量更低
-
生成对抗网络 (GAN)
- GAN 不使用于任何显式密度函数。相反,采用博弈论的方法:通过两个玩家博弈的过程,学习从训练分布中生成。
- 问题:想要从复杂的高维训练分布中采样。正如我们所讨论的,没有直接的方法可以做到这一点!
- 解决方案:从简单分布中采样,例如随机噪声、分布。学习从简单分布到训练分布的变换(用神经网络表示)。因此,我们创建了一个从简单分布中提取的噪声图像,将其馈送到 NN,我们将其称为生成器网络,它应该学会将其转换为我们想要的分布。
- 训练 GAN:两个玩家:
生成器网络:尝试通过生成真实的图像来欺骗鉴别器。
鉴别器网络:尝试区分真假图像。 - 如果我们能够很好地训练鉴别器,那么我们就可以训练生成器来生成正确的图像。
- 通过minimax博弈公式联合训练这个网络
- 生成器网络的标签将为 0,真实图像为 1。
- 为了训练网络,我们将执行以下操作:
首先对判别器进行梯度上升,习得θd来达到目的:最大化目标函数,更新D: D = D + α D ∂ V ∂ D D=D+\alpha_D\frac{\partial V}{\partial D} D=D+αD∂D∂V
然后对生成器进行梯度下降以最小化目标函数,更新G: G = G − α G ∂ V ∂ G G=G-\alpha_G\frac{\partial V}{\partial G} G=G−αG∂G∂V(梯度下降)
但是由于损失函数在生成器生成了比较真实的图片时梯度才下降很快,梯度信号收到采样良好的区域支配,所以学习艰难,所以改变一下目标函数,训练G最大化KaTeX parse error: Can't use function '\(' in math mode at position 5: -log\̲(̲D(G(z))),将过程反转,最大化判别器出错的概率。这样一来,在生成样本质量不好的情况下,可以获得一个很高的梯度信号。
(交替训练,迭代)
当 p G = p d a t a p_G=p_{data} pG=pdata 时,minimax 游戏达到其全局最小值
联合训练两个网络具有挑战性,可能不稳定。选择具有更好损失情况的目标有助于培训是一个活跃的研究领域。
GAN zoo,编辑整理一整个GAN的列表(paper)
使用GAN的技巧和窍门
强化学习
深度强化学习(reinforcement learning)
- 强化学习问题涉及与环境交互的代理,该环境提供数字奖励信号:代理在环境中采取行动,可以为其行动获得奖励,目标:如何采取行动以最大限度获得奖励。
- 步骤:Environment --> State s[t]–> Agent --> Action a[t]–> Environment --> Reward r[t]+ Next state s[t+1]–> Agent --> 等等…
- 例子:机器人运动:
o目标:让机器人向前移动
o状态:关节的角度和位置
o作用:施加在关节上的扭矩
o每次 1 步直立 + 向前移动 - 可以使用马尔可夫决策过程在数学上制定 RL(强化学习)
- 马尔可夫决策过程(强化学习问题的数学表达)MDP
由 ( S, A, R, P, Y)定义,其中:
S: 一组可能的状态。
A: 一组可能的动作
R:给定的奖励分配(状态,动作)对
P:转移概率,即给定(状态,动作),表示下一个状态的转移概率分布
Y(γgamma): 折扣因子:对近期和远期奖励分配权重# How much we value rewards coming up soon verses later on. - 算法:
在时间步t=0,环境从初始状态分布p(s)中采样
然后,对于 t=0 直到完成:
代理选择操作 a[t]
环境获得奖励:R( s[t], a[t])
环境从P(s[t], a[t])采样下一个状态
代理收到奖励r[t]和下一个状态s[t+1] - 策略pi :从状态到行为的函数,它指定在每个状态下要采取的操作。
o目标:找到最佳决策pi*最大化提高配权之后的全部奖励之和:Sum(Y^t * r[t], t>0) - 用价值函数定义目前所处的状态有多好:
o状态s处的价值函数,从状态s的决策到现在的决策之后的预期累计回馈:
Vpi = Sum(Y^t * r[t], t>0) given s0 = s, pi - 用Q值函数定义一个[状态,行动]组有多好:
o状态s下采取行动a,遵守决策的期望累积奖励:
Qpi = Sum(Y^t * r[t], t>0) given s0 = s,a0 = a, pi - 最优 Q 值函数Q是从给定(状态、动作)对中可获得的最大期望累积奖励:
Q*[s,a] = Max(for all of pi on (Sum(Y^t * r[t], t>0) given s0 = s,a0 = a, pi)) - 贝尔曼方程
o重要的是RL。
o给定任何状态动作对 (s,a),其价值将是将获得的奖励r+最终进入状态的价值。
Q*[s,a] = r + Y * max Q*(s’,a’) given s,a # Hint there is no policy in the equation
o最优策略pi对应于在指定的任何状态下采取最佳行动Q - 求解最优策略:值迭代算法,使用贝尔曼方程作为迭代更新,每一步中通过试图强化bellman方程改进对Q*的近似
o由于现实世界应用中的巨大空间维度,我们将使用函数逼近器来估计Q(s,a)。例如神经网络,这称为Q 学习
o任何时候我们有一个我们无法表示的复杂函数时,我们都会使用神经网络 - Q学习
o第一个解决 RL 的深度学习算法。
o使用函数逼近器来估计动作值函数,如果函数逼近器是一个深度神经网络 => deep q-learning。
o损失函数: Q Q Q : L ( s , a ) = ( Q ( s , a ; θ ) − y s , a ; θ ) 2 L(s,a)=(Q(s,a;\theta)-y_{s,a;\theta})^2 L(s,a)=(Q(s,a;θ)−ys,a;θ)2 - 决策梯度
o解决 RL 的第二种深度学习算法。
oQ 函数的问题: Q 函数可能非常复杂。比如抓取物体的机器人具有非常高维的状态。但这个政策可以简单得多:只要闭上你的手。
o我们可以直接学习策略,例如从策略集合中找到最佳策略吗?
o策略梯度方程: (目标:找到一个最佳策略θ*,))
J ( θ ) = E r ∼ p θ [ ∑ t ≥ 0 γ t r t ] J(\theta)=E_{r\sim p_\theta}[\sum_{t\geq0}\gamma^tr_t] J(θ)=Er∼pθ[∑t≥0γtrt]- 通过最大化 θ ∗ = a r g m a x θ J ( θ ) \theta^*=arg\ max_\theta J(\theta) θ∗=arg maxθJ(θ) 找到最优策略(使用梯度上升)
o总是可以收敛,收敛到的局部最小值J(ceta),通常足够好!
oREINFORCE 算法(强化算法)是获得/预测我们最佳策略的算法(没看懂^^)
oReinforce 算法的方程和直觉:
对轨迹的未来奖励的期望:
∂ J ∂ θ = E x ∼ p θ [ ∑ t ≥ 0 ∂ ∂ θ l o g π θ ( a t ∣ s t ) ] \frac{\partial J}{\partial \theta}=E_{x\sim p_\theta}[\sum_{t\geq 0}\frac{\partial}{\partial \theta}log\pi_\ θ(a_t|s_t)] ∂θ∂J=Ex∼pθ[∑t≥0∂θ∂logπ θ(at∣st)]
o循环聚焦模型(RAM)是一种基于 REINFORCE 算法的算法,用于图像分类问题:
采取图像周围一系列“微景(glimpses)”有选择地集中在图像局部区域周围观察来建立信息。
给定一个微景,模型核心将是对这个状态建模的RNN,为了输出下一个动作使用策略参数
RAM 现在用于很多任务:包括细粒度图像识别、图像字幕和视觉问答
oAlphaGo 混合使用监督学习和强化学习,它还使用决策梯度。
斯坦福大学关于深度强化学习的好课程
关于深度强化学习的课程
关于深度强化学习的课程
深度学习课程
深度学习课程
文章
- 通过最大化 θ ∗ = a r g m a x θ J ( θ ) \theta^*=arg\ max_\theta J(\theta) θ∗=arg maxθJ(θ) 找到最优策略(使用梯度上升)
- 马尔可夫决策过程(强化学习问题的数学表达)MDP
深度学习的有效方法和硬件
趋势:如果想要高精度,需要更大(更深)的模型。
- 三个挑战
1.型号尺寸:很难部署于PC、手机、汽车
2.训练速度很慢
3.能耗巨大:对存储器的大量访问 - 解决:通过算法-硬件联动设计来提高深度学习的效率。
- 从硬件和算法的角度来看。
- 硬件
o通用硬件:CPU、GPU
o专用硬件:FPGA(可编程)、ASIC(特定用途集成电路,有固定逻辑)
数字表示:
o计算机中的数字用离散存储器表示。
o对于硬件在浮点运算中从 32 位变为 16 位,它非常好且节能。 - 高效推理算法
o修剪神经网络
想法:删除一些权重/神经元并且神经网络仍然表现相同
修剪可以应用于CNN和RNN,迭代它会达到与原始相同的精度。
算法:
a.获得训练网络。
b.评估神经元的重要性。
c.删除最不重要的神经元。
d.微调网络。
e.如果我们需要继续修剪,我们再次进入第 2 步,否则我们停止。
o权值共享
思路:把所有权重聚类,相近时用一个聚类质心表示这个数。
训练量化:可以使 k 表示在过滤器上进行聚类并减少其中的数字。通过使用它,我们还可以减少计算梯度所使用的操作数量。
剪枝+权值共享可以协同工作以减小模型的大小。
霍夫曼编码:用更多数位表示不常出现的权重,更少数位表示常出现的权重
使用剪枝+权值共享+霍夫曼编码被称为深度压缩。
SqueezeNet(神经网络模型):3*3卷积前使用通道数更少的层,没有全连接层,最后一层为全局池化。
o量化(quantization)
算法(量化权重和激活):
a.用标准浮点数训练神经网络
b.收集每一层统计信息量化权重和激活:
收集权重和激活的统计数据。
选择合适的小数点位置。
c.微调浮点数格式。
d.定点数前向传播,浮点数反向传播并更新权值。
o低秩近似
是另一种用于 CNN 的尺寸缩减算法。想法是分解conv层成两步卷积。
o二元/三元网络
用三个数字来表示 NN 中的权重,只有 -1, 0, 1 的大小会小得多。
2017年发表的新思路《朱汉毛Dally.Ternary Quantization, ICLR’17》
训练后工作。
o维诺格拉德变换(Winograd变换)
常用于实现卷积的方法,基于 3x3 WINOGRAD 卷积,其操作比普通卷积少
cuDNN 5 使用了提高速度的 WNOGRAD 卷积。
- 硬件
- 从硬件和算法的角度来看。