人工智能实践Tensorflow2.0 第五章--6.八股法搭建ResNet18网络--北京大学慕课
第五章–卷积神经网络基础–八股法搭建ResNet18网络
本讲目标:
介绍八股法搭建ResNet18网络的流程。参考视频。
八股法搭建ResNet18网络
- 1.ResNet18网络介绍
-
- 1.1-网络分析
- 2.六步法训练ResNet18网络
-
- 2.1六步法回顾
- 2.2完整代码
- 2.3输出结果
1.ResNet18网络介绍
1.1-网络分析
借鉴点:引入了层间残差跳连,引入前方信息,减少梯度消失,使神经网络层数增加成为可能。

ResNet的作者何凯明在cifar10数据集上做了个实验。他发现,56层卷积网络的错误率要高于20卷积网络的错误率。他认为单纯堆叠神经网络的层数,会使神经网络模型退化,以至于后面的特征丢失了前面特征的原本模样。于是他用了一根跳连线,将前面的特征直接接到了后面,如下图所示:

使输出H(x)包含了堆叠卷积的非线性输出F(x)和跳过这两层堆叠卷积,直接连过来的恒等映射x,让他们对应的元素相加,这一操作有效的缓解了神经网络堆叠导致的退化。使得神经网络可以朝着更深的层级发展。
ResNet 即深度残差网络,通过对残差结构的运用,ResNet 使得训练数百层的网络成为了可能,从而具有非常强大的表征能力.
注:
Inception块中的“+”是沿深度方向叠加(千层蛋糕层数叠加)
ResNet块中的“+”是特征图对应元素值相加(矩阵值相加)
ResNet块中有两种情况:
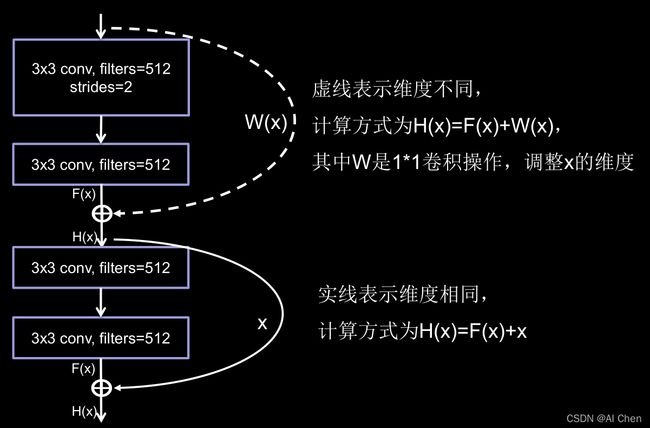
一种情况用图中的实线表示,这种情况中,两层堆叠卷积没有改变特征图的维度,也就是他们特征图的个数,高、宽和深度都相同,可以直接将F(x)和x相加。
另一种情况用图中的虚线表示,这种情况中两层堆叠卷积改变了特征图的维度,需要借助1*1的卷积调整x的维度,使w(x)与F(x)维度一致。
即一种在堆叠卷积后维度相同,另一种是在堆叠卷积前后维度不同。
1x1卷积操作可通过步长改变特征图尺寸,通过卷积核个数改特征图深度。
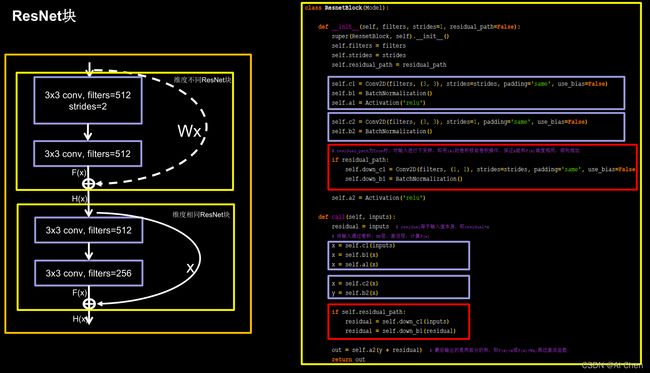
下面的程序由上图中左边的橙色快堆叠而成。
2.六步法训练ResNet18网络
2.1六步法回顾
import
train,test
model=tf.keras.Sequantial()/ class
model.compile
model.fit
model.summary
2.2完整代码
import tensorflow as tf
import os
import numpy as np
from matplotlib import pyplot as plt
from tensorflow.keras.layers import Conv2D, BatchNormalization, Activation, MaxPool2D, Dropout, Flatten, Dense
from tensorflow.keras import Model
np.set_printoptions(threshold=np.inf)
cifar10 = tf.keras.datasets.cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
class ResnetBlock(Model):
def __init__(self, filters, strides=1, residual_path=False):
super(ResnetBlock, self).__init__()
self.filters = filters
self.strides = strides
self.residual_path = residual_path
self.c1 = Conv2D(filters, (3, 3), strides=strides, padding='same', use_bias=False)
self.b1 = BatchNormalization()
self.a1 = Activation('relu')
self.c2 = Conv2D(filters, (3, 3), strides=1, padding='same', use_bias=False)
self.b2 = BatchNormalization()
# residual_path为True时,对输入进行下采样,即用1x1的卷积核做卷积操作,保证x能和F(x)维度相同,顺利相加
if residual_path:
self.down_c1 = Conv2D(filters, (1, 1), strides=strides, padding='same', use_bias=False)
self.down_b1 = BatchNormalization()
self.a2 = Activation('relu')
def call(self, inputs):
residual = inputs # residual等于输入值本身,即residual=x
# 将输入通过卷积、BN层、激活层,计算F(x)
x = self.c1(inputs)
x = self.b1(x)
x = self.a1(x)
x = self.c2(x)
y = self.b2(x)
if self.residual_path:
residual = self.down_c1(inputs)
residual = self.down_b1(residual)
out = self.a2(y + residual) # 最后输出的是两部分的和,即F(x)+x或F(x)+Wx,再过激活函数
return out
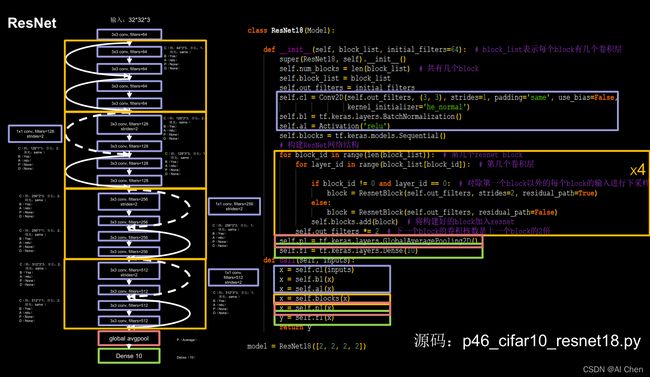
class ResNet18(Model):
def __init__(self, block_list, initial_filters=64): # block_list表示每个block有几个卷积层
super(ResNet18, self).__init__()
self.num_blocks = len(block_list) # 共有几个block
self.block_list = block_list
self.out_filters = initial_filters
self.c1 = Conv2D(self.out_filters, (3, 3), strides=1, padding='same', use_bias=False)
self.b1 = BatchNormalization()
self.a1 = Activation('relu')
self.blocks = tf.keras.models.Sequential()
# 构建ResNet网络结构
for block_id in range(len(block_list)): # 第几个resnet block
for layer_id in range(block_list[block_id]): # 第几个卷积层
if block_id != 0 and layer_id == 0: # 对除第一个block以外的每个block的输入进行下采样
block = ResnetBlock(self.out_filters, strides=2, residual_path=True)
else:
block = ResnetBlock(self.out_filters, residual_path=False)
self.blocks.add(block) # 将构建好的block加入resnet
self.out_filters *= 2 # 下一个block的卷积核数是上一个block的2倍
self.p1 = tf.keras.layers.GlobalAveragePooling2D()
self.f1 = tf.keras.layers.Dense(10, activation='softmax', kernel_regularizer=tf.keras.regularizers.l2())
def call(self, inputs):
x = self.c1(inputs)
x = self.b1(x)
x = self.a1(x)
x = self.blocks(x)
x = self.p1(x)
y = self.f1(x)
return y
model = ResNet18([2, 2, 2, 2])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
checkpoint_save_path = "./checkpoint/ResNet18.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True)
history = model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1,
callbacks=[cp_callback])
model.summary()
# print(model.trainable_variables)
file = open('./weights.txt', 'w')
for v in model.trainable_variables:
file.write(str(v.name) + '\n')
file.write(str(v.shape) + '\n')
file.write(str(v.numpy()) + '\n')
file.close()
############################################### show ###############################################
# 显示训练集和验证集的acc和loss曲线
acc = history.history['sparse_categorical_accuracy']
val_acc = history.history['val_sparse_categorical_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
2.3输出结果
Epoch 1/5
This message will be only logged once.
1/1563 [..............................] - ETA: 0s - loss: 3.3310 - sparse_categorical_accuracy: 0.0625WARNING:tensorflow:Callbacks method `on_train_batch_end` is slow compared to the batch time (batch time: 0.0087s vs `on_train_batch_end` time: 0.0140s). Check your callbacks.
1563/1563 [==============================] - 43s 27ms/step - loss: 1.9394 - sparse_categorical_accuracy: 0.2222 - val_loss: 1.7778 - val_sparse_categorical_accuracy: 0.2746
Epoch 2/5
1563/1563 [==============================] - 34s 22ms/step - loss: 1.5630 - sparse_categorical_accuracy: 0.3810 - val_loss: 1.5641 - val_sparse_categorical_accuracy: 0.4195
Epoch 3/5
1563/1563 [==============================] - 34s 22ms/step - loss: 1.2803 - sparse_categorical_accuracy: 0.5446 - val_loss: 1.1285 - val_sparse_categorical_accuracy: 0.6119
Epoch 4/5
1563/1563 [==============================] - 35s 22ms/step - loss: 1.0500 - sparse_categorical_accuracy: 0.6436 - val_loss: 1.4434 - val_sparse_categorical_accuracy: 0.5569
Epoch 5/5
1563/1563 [==============================] - 34s 22ms/step - loss: 0.9020 - sparse_categorical_accuracy: 0.6990 - val_loss: 0.9089 - val_sparse_categorical_accuracy: 0.6919
Model: "vg_g16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) multiple 1792
_________________________________________________________________
batch_normalization (BatchNo multiple 256
_________________________________________________________________
activation (Activation) multiple 0
_________________________________________________________________
conv2d_1 (Conv2D) multiple 36928
_________________________________________________________________
batch_normalization_1 (Batch multiple 256
_________________________________________________________________
activation_1 (Activation) multiple 0
_________________________________________________________________
max_pooling2d (MaxPooling2D) multiple 0
_________________________________________________________________
dropout (Dropout) multiple 0
_________________________________________________________________
conv2d_2 (Conv2D) multiple 73856
_________________________________________________________________
batch_normalization_2 (Batch multiple 512
_________________________________________________________________
activation_2 (Activation) multiple 0
_________________________________________________________________
conv2d_3 (Conv2D) multiple 147584
_________________________________________________________________
batch_normalization_3 (Batch multiple 512
_________________________________________________________________
activation_3 (Activation) multiple 0
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 multiple 0
_________________________________________________________________
dropout_1 (Dropout) multiple 0
_________________________________________________________________
conv2d_4 (Conv2D) multiple 295168
_________________________________________________________________
batch_normalization_4 (Batch multiple 1024
_________________________________________________________________
activation_4 (Activation) multiple 0
_________________________________________________________________
conv2d_5 (Conv2D) multiple 590080
_________________________________________________________________
batch_normalization_5 (Batch multiple 1024
_________________________________________________________________
activation_5 (Activation) multiple 0
_________________________________________________________________
conv2d_6 (Conv2D) multiple 590080
_________________________________________________________________
batch_normalization_6 (Batch multiple 1024
_________________________________________________________________
activation_6 (Activation) multiple 0
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 multiple 0
_________________________________________________________________
dropout_2 (Dropout) multiple 0
_________________________________________________________________
conv2d_7 (Conv2D) multiple 1180160
_________________________________________________________________
batch_normalization_7 (Batch multiple 2048
_________________________________________________________________
activation_7 (Activation) multiple 0
_________________________________________________________________
conv2d_8 (Conv2D) multiple 2359808
_________________________________________________________________
batch_normalization_8 (Batch multiple 2048
_________________________________________________________________
activation_8 (Activation) multiple 0
_________________________________________________________________
conv2d_9 (Conv2D) multiple 2359808
_________________________________________________________________
batch_normalization_9 (Batch multiple 2048
_________________________________________________________________
activation_9 (Activation) multiple 0
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 multiple 0
_________________________________________________________________
dropout_3 (Dropout) multiple 0
_________________________________________________________________
conv2d_10 (Conv2D) multiple 2359808
_________________________________________________________________
batch_normalization_10 (Batc multiple 2048
_________________________________________________________________
activation_10 (Activation) multiple 0
_________________________________________________________________
conv2d_11 (Conv2D) multiple 2359808
_________________________________________________________________
batch_normalization_11 (Batc multiple 2048
_________________________________________________________________
activation_11 (Activation) multiple 0
_________________________________________________________________
conv2d_12 (Conv2D) multiple 2359808
_________________________________________________________________
batch_normalization_12 (Batc multiple 2048
_________________________________________________________________
activation_12 (Activation) multiple 0
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 multiple 0
_________________________________________________________________
dropout_4 (Dropout) multiple 0
_________________________________________________________________
flatten (Flatten) multiple 0
_________________________________________________________________
dense (Dense) multiple 262656
_________________________________________________________________
dropout_5 (Dropout) multiple 0
_________________________________________________________________
dense_1 (Dense) multiple 262656
_________________________________________________________________
dropout_6 (Dropout) multiple 0
_________________________________________________________________
dense_2 (Dense) multiple 5130
=================================================================
Total params: 15,262,026
Trainable params: 15,253,578
Non-trainable params: 8,448
_________________________________________________________________
