毕业设计(二):基于YOLO算法的手势识别技术
YOLOv3实现原理
这篇文章是有点晚的,比我预想的要晚一个月。主要是这两个月来一直在考虑考研与工作的事,自己的事就不提了,直接进入正题。
毕业设计(一):基于YOLO算法的手势识别技术
参考文章
Darknet53网络各层参数详解
手撕yolo3系列——详解主干网络darknet53代码(详细注释)
YOLOv3 算法的详细说明
Yolo三部曲解读——Yolov3
yolov3损失函数
全网呕血整理:关于YOLO v3原理分析
YOLO算法
1、Darknet网络
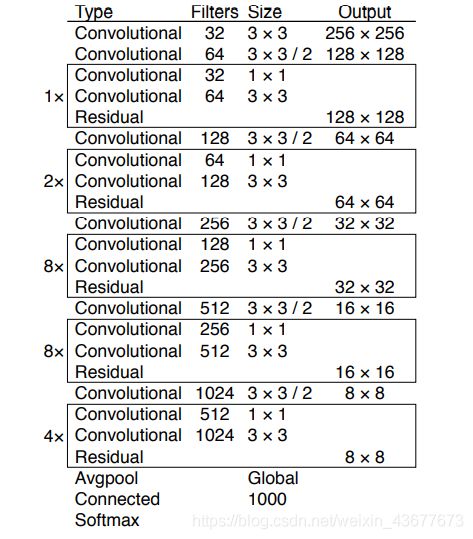
YOLOv2,其主干网络是一个Darknet-19网络,到了YOLOv3,主干网络进化为了Darknet-53网络。YOLOv3仅使用卷积层,由一系列的1x1和3x3的卷积层组成,每个卷积层后都会跟一个BN层和一个LeakyReLU层。
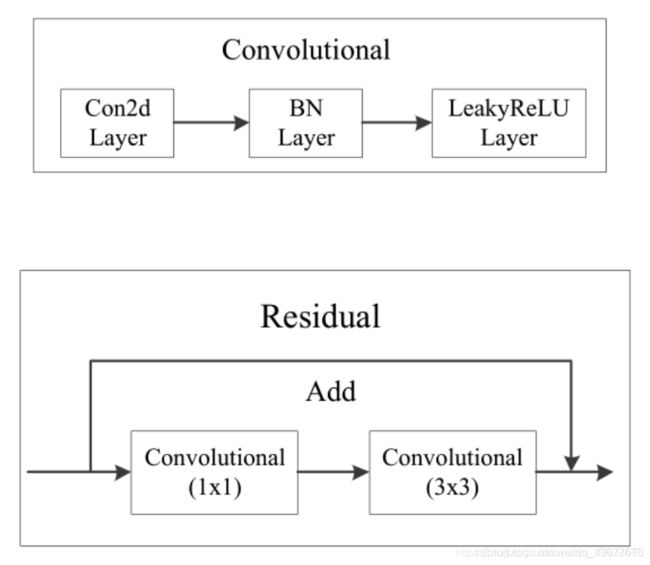
在此之前先来理解下在Darknet网络中什么是残差结构(Residual)。
残差块结构由两条支路组成,一条支路将上一层输出的feature map进行卷积等操作,另一条支路将上一层输出的feature map恒等映射,并与刚才卷积操作完的feature map进行逐元素相加,因此两条支路的通道数必须相等。也就是说发生卷积等操作的那条支路(残差路)的输出不能改变feature map的通道数。

图3对应解释了图2,一条路上的卷积操作是在1×1和3×3的Convolutional上进行。每个Convolutional包含了Conv、BN和LeakyReLU,如图2所示。这些细节在图1中没有展示出来。在图1中的1×、2×、8×等代表该模块重复1次,2次,8次。
可以将上面的三幅图与下面的图做比较一起理解。

最终会得到13×13、26×26、52×52不同的特征层大小的输出,分别对应检测大、中、小物体。随着输出的特征图的数量和尺度的变化,先验框的尺寸也需要相应的调整。YOLOv3使用k-means方法,总共聚类出9种尺寸的先验框。在COCO数据集这9个先验框是:(10x13),(16x30),(33x23),(30x61),(62x45),(59x119),(116x90),(156x198),(373x326)。

在yolo作者的coco数据集中,输出了13×13×255。这个255是什么意思呢?我们知道coco数据集有80类,在检测后会得到x、y、w、h和confidence score,分别对应检测物体中心点的横纵偏移量,宽高,与背景中是否有目标的置信度。这个数加起来就是85。而我们知道每个目标检测是有三个先验框,所以85×3=255。
这也就是多尺度预测。就Darknet53而言,13×13、26×26、52×52是它的三个feature map尺寸。网络接收一张(416×416)的图,经过5个步长为2的卷积来进行降采样。416 / 2ˆ5 = 13,y1输出(13×13)。从y1的倒数第二层的卷积层上采样(x2,up sampling)再与最后一个26×26大小的特征图张量连接,y2输出(26×26)。从y2的倒数第二层的卷积层上采样(x2,up sampling)再与最后一个52×52大小的特征图张量连接,y3输出(52×52)
作者最后还给出了darknet53网络与其他的比较(256×256)。

以我对Darknet53网络的理解,按100分来算,我最多也只是60及格而已,触及了一些最基本的网络知识,对于真的理解,就要去深入学习卷积网络。所以以上只是我个人通过看其他人文章所学习到的,对于Darknet53网络的理解可能不全面。
2、输出处理
2.1 先验框
使用k-means对数据集中的标签框进行聚类,得到类别中心点的9个框,作为先验框。在COCO数据集中,九个框就如上面所说的。

这幅图,学习YOLOv3的都因该很熟悉。沿用YOLO9000预测bounding box的方法,通过尺寸聚类确定anchor box。 C x C_x Cx、 C y C_y Cy是指中心点在第几网格, σ ( t x ) \sigma(t_x) σ(tx)、 σ ( t y ) \sigma(t_y) σ(ty)是中心点在一个小网格中的位置取值,为小数,使用Sigmoid函数计算。因此, b x b_x bx、 b y b_y by就是中心点在图像中的横坐标,纵坐标。先验边界框的宽度和高度为 p w p_w pw、 p h p_h ph , t x t_x tx、 t y t_y ty是每个边界框的宽高的一个系数。取对数计算是为了避免因出现负值而导致,出现负值,从而计算误差。
- 那么confidence score怎么计算呢?
confidence score = Pr(Object) * IoU
Pr(Object)代表预测框中是否有对象。有Pr(Object)=1,否则Pr(Object)=0,怎么判断呢?如果一个object的ground truth的中心点坐标在一个grid cell中,那么这个grid cell就是包含这个object,也就是说这个object的预测就由该grid cell负责。
这还有一个公式,Pr( C l a s s i Class_i Classi|Object)代表每个bounding box属于哪一类。
Pr(Object) * Pr( C l a s s i Class_i Classi|Object) = Pr( C l a s s i Class_i Classi)
因为每个grid cell都有三个先验框,所以一幅图像中会出现多个预测值,为降低算法的计算量,使用非最大抑制(Non-maximun suppression,NMS)和联合联合交叉(intersection over union, IoU)阈值来选择置信度最高的边框。
I o U = B T ∩ B P B T ∪ B P IoU=\frac{B_T \cap B_P}{B_T \cup B_P} IoU=BT∪BPBT∩BP
B T B_T BT是实际边界框, B P B_P BP是预测边界框。
这个值会进行筛选,作者设定0.5为阈值,当IoU大于0.5时,才计入统计。
按得分从高到低排序,用NMS算法去掉重复率较大的bounding box。NMS算法?首先选择得分最大的bounding box,比较它与其他bounding box的IoU(这里是再一次进行计算),如果重叠率较高(大于0.5),则进行舍弃。一轮之后再次进行,直到最后为止。
这部分的理解是我看到的一篇文章理解的,使用图解的方法来说明,很不错。
但是我现在找不到这篇文章了,只记得不是CSDN的文章,使用图解用例是汽车。
在毕设结束前我在找一找,看看能不能找到,写上来。
但是这里面也是有区别的,按照理解会分成三类,正例(positive)、负例(negative)、忽略样例(ignore)。
正例: IOU最大的预测框,即为正例,正例产生置信度loss、检测框loss、类别loss。并且只能分配给一个ground truth。例如第一个ground truth已经匹配了一个正例检测框,那么下一个ground truth,就在余下的4031个检测框中,寻找IOU最大的检测框作为正例。ground truth的先后顺序可忽略。
忽略样例:正例除外,与任意一个ground truth的IOU大于阈值(论文中使用0.5),则为忽略样例。忽略样例不产生任何loss。
负例:正例除外(与ground truth计算后IOU最大的检测框,但是IOU小于阈值,仍为正例),与全部ground truth的IOU都小于阈值(0.5),则为负例。负例只有置信度产生loss,置信度标签为0。
2.2 损失函数
在作者的论文中是没有损失函数这一部分的,但与YOLOv2的基本类似。这部分我依据网上所学来进行阐述。
先看一下YOLOv1的损失函数:

前两行看到了x,y,w,h,这就可以看出他是对坐标的误差。注意用宽和高的开根号代替原来的宽和高,这样做主要是因为相同的宽和高误差对于小的目标精度影响比大的目标要大。第三、四行表示bounding box的confidence损失,就像前面所说的,分成grid cell包含与不包含object两种情况。第五行表示预测类别的误差,注意前面的系数只有在grid cell包含object的时候才为1。
yolov2的损失函数:
只是在yolov1基础上改动了关于bbox的w和h的损失计算方式 即从
∑ i = 0 S 2 ∑ j = 0 B I i j o b j [ ( w i j − w i j ^ ) 2 ] \sum_{i=0}^ {S^2}\sum_{j=0}^{B} {I_{ij}^{obj}}[{(\sqrt{w_{i}^{j}}-\sqrt{\hat{w_{i}^{j}}})}^2] i=0∑S2j=0∑BIijobj[(wij−wij^)2]改为 ∑ i = 0 S 2 ∑ j = 0 B I i j o b j [ ( w i j − w i j ^ ) 2 + ( ( h i j − h i j ^ ) 2 ] \sum_{i=0}^ {S^2}\sum_{j=0}^{B} {I_{ij}^{obj}}[(w_{i}^{j}-\hat{w_{i}^{j}})^2+((h_{i}^{j}-\hat{h_{i}^{j}})^2] i=0∑S2j=0∑BIijobj[(wij−wij^)2+((hij−hij^)2]
YOLOv3的损失函数:
是在yolov2基础上改动的,最大的变动是分类损失换成了二分交叉熵

- I i j o b j I_{ij}^{obj} Iijobj
I i j o b j I_{ij}^{obj} Iijobj表示:第i个网格的第j个anchor box是否负责这个object,如果负责那么 I i j o b j I_{ij}^{obj} Iijobj= 1,否则为0。 负责:第i个网格的B个anchor box中与该对象的ground truth box的IOU在所有的anchor box与ground truth box的IOU中最大,那它就负责预测这个对象,因为这个形状、尺寸最符合当前这个对象,此时 I i j o b j I_{ij}^{obj} Iijobj= 1。
I i j n o o b j I_{ij}^{noobj} Iijnoobj 表示i个网格的第j个anchor box不负责该目标。- c i j ^ \hat{c_{i}^{j}} cij^
它表示真实值, c i j ^ \hat{c_{i}^{j}} cij^ 的取值是由grid cell的bounding box有没有负责预测某个对象决定的。如果负责,那么 c i j ^ \hat{c_{i}^{j}} cij^ =1,否则, c i j ^ \hat{c_{i}^{j}} cij^=0
前面在说明anchor box的时候提到每个bounding box负责预测的形状是依据与其对应的anchor box相关的,那这个anchor box与该对象的ground truth box的IOU在所有的anchor box与ground truth box的IOU中最大,那它就负责预测这个对象。
第一行可以看出是中心坐标误差,第二行是宽高坐标误差,第三第四行是置信度误差,分为obj和noobj,上面已经讨论过。但第五行是分类误差。
我也看到了另一种损失函数,不过本质上是一致的,只不过给出的公式不同罢了。

上面这些差不多就是YOLOv3算法的实现原理。在此基础上就要开始在自己电脑上配置运行,下面的一篇文章就会讲一讲代码的实现。因为我写这篇文章时是做完测试的,所以下一篇不会太晚,最快的话明天就能出来,最晚五一出来。但是自己的测试还是存在一些细小的问题,没有解决,所以下一篇只是初稿,等毕设结束就会全部结束。