平安科技从 Oracle 迁移到 UbiSQL 的实践
作者:熊浪,平安科技资深数据库架构师,在关系型和非关系型分布式数据库技术领域具有丰富的经验,担任平安集团去 O 分布式项目经理,负责分布式数据库选型和架构设计工作。
平安科技是平安集团旗下科技解决方案专家,践行“科技赋能金融、科技驱动生态”的企业使命,赋能集团金融服务、医疗健康、汽车服务、智慧城市生态圈建设,致力于成为国际领先的科技公司。
UbiSQL 简介
UbiSQL 这个词对大家来说可能比较陌生,UbiSQL 是平安集团内部打造的分布式数据库产品,代码基于 TiDB,完全兼容 TiBD 4.0 版本。在 TiDB 的特性之上,UbiSQL 在稳定性、安全性和应用性上面都做了提升,打造出一个金融级且内核源码自主可控的分布式数据库,提供一栈式 HTAP 解决方案。
UbiSQL 的规划是提供金融级别的安全能力,比如加密算法、给 TDE 的透明算法做增强,以及集群内部管理的加强。因为后续会增加到上千套集群,我们对于集群的管理做了加强,监控都做了合并。此外,UbiSQL 提供冷热数据的分离,支持把集群的冷数据都分离到 SATA 盘上,从而降低存储成本。
从 Oracle 迁移到 UbiSQL 的过程
接下来分享一个比较详细的 Oracle 迁移实践,这是我们在平安集团里面做了多年去 O 工作的总结,希望给到大家借鉴。集团的核心支付系统迁移的数据量大概在 8 T 左右,因为都是 rac 节点,为了避免节点之间的相互影响,就把它迁移到两个 UbiSQL 的实例上面。
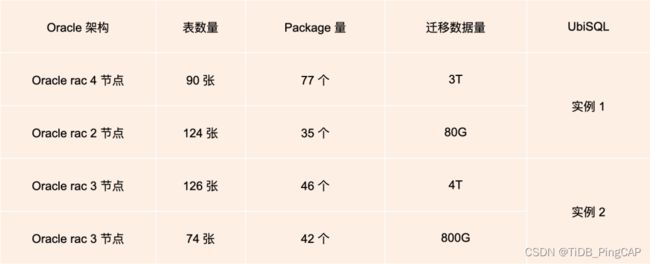
图:迁移前后集群的对比
UbiSQL 的架构是通过 F5 负载均衡,打到三个数据中心的 TiDB 集群上面,F5 在三地机房都有部署,通过 DNS 方式访问相应 UbiSQL 的实例,在机房 IDC1、IDC2、IDC3 的集群之间通过 UbiSQL 自身的 Raft 协议实现强一致的数据同步,再通过 Drainer 工具进行异步复制,复制到远程的灾备集群。

图:迁移后的 UbiSQL 架构
首先是迁移前对于现状的分析,主要包括三个方面:
数据库的负载以及迁移 SQL 的金融性、对象,存储过程的分析,确定是不是都可以迁移,这部分分析是 DBA 通过代码的扫描、报告得出的。
应用方面的分析,应用层需要看新的数据库是不是能适配,能不能兼容应用,了解应用层的结构还有相应的 JDBC 的版本。
关联系统的分析,Oracle 数据库有很多通过 OGG 或者 ETL、Kettle 或者调用第三方进行同步,接口调用情况也需要做相应的梳理。
接下来基于分析的结果,做数据库的选型:
选择 RDBMS 还是选其他的开源数据库或是分布式数据库,我们需要根据应用层的要求来看,是做到双活,还是做到快速的扩容,亦或是分布式,然后根据要求来做相应数据库的选型。数据库的架构设计方案,是不是需要做多活,还是 NG 就足够了,也需要根据相应的业务需求做设计。
应用系统的拆分与解耦方案,确定应用是整个迁移,还是只迁移一部分,然后再启动应用的前期改造。
关联数据的同步方案设计,这部分就是 OGG 或者其他 ETL 数据的同步,分布式数据库以及开源的 PG,目前不支持 OGG 为源的,所以需要借助于第三方,比如 Kafka 之类的工具做相应的数据同步。
然后是相应的迁移方案和回退方案设计,需要做相应的人力规划,还要看一下投入多少人力和成本。
在这些准备都做完后,我们就开始搭建数据库、开发环境、测试环境、生产环境。准备好以后我们开始做数据的迁移,将前面梳理出来的一些表结构、对象之类的迁移到新的 UbiSQL 上,需要涉及到表结构的比对和数据的比对,这部分后面会详细介绍。
应用功能的改造和测试是最重要、最核心的部分,开发人员需要对相应的功能、SQL 以及存储过程这方面进行改造,这是整个脱 O 的核心部分,如果存储过程较大,有几十万行之类的,需要评估人力的投入。我们今年脱 O 的项目存储过程大概有 2 万行左右,投入的人力约 10 个人,做了两个月左右,把整体约 100个 package,全部转换为 java 代码,这块的人力投入是挺大的。这部分做完之后就是应用层功能的全回归测试,校验开发转化的功能是否完全一致,和原来 Oracle 的逻辑是否完全一致。 接下来依次是做应用的性能压测、数据库的压测,然后是相应的迁移手册。
接下来进入生产实施的阶段,按照实际的情况和方案步骤进行迁移,可能是“一次迁移,一次切换”,也可能是“多批次迁移、逐步切换”,因为有一些核心系统的迁移需要做保障措施,比如切过去不能有任何问题,可能切一些灰度数据过去。后续进入到生产数据库的并行运行阶段,我们对迁移后的数据库做相应监控和报告,紧接着下线老的 Oracle 数据库和回滚链路,进行项目的总结。
流量复制与回放方案
重点剖析一下流量复制和流量回放方面我们的实现方案。首先,为什么有流量复制和流量回放?流量回放是因为 Oracle 转化为 java 代码后,不知道这个逻辑对不对,完全通过测试人员做回归测试,可能测试不全,也有可能遗漏掉很重要的部分,我们想通过流量回放的方案保证生产业务流量完全在测试环境做相应的应用。
流量复制是因为可以做压测,把生产的流量直接引入到迁移之后的环境,然后把流量做到翻倍,翻到两三倍做压测,做完之后还可以在后续核心系统去 O 上面做重复利用,从而节约了相应的成本和人力。
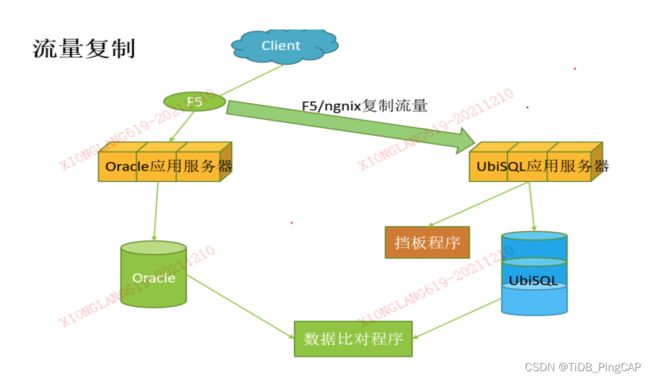
图:流量复制
流量复制借助的是 F5,或者 Ngnix 的流量,将所有客户端的流量通过 F5 访问到 Oracle 的环境,也可以在 F5 这一层将流量做镜像,将实时到 F5 的流量转发到应用层,应用层通过访问 UbiSQL,再通过挡板程序做到相应业务的访问。整个环节的核心在 F5,所有的流量都要经过 F5,如果没有走 F5 的流量则没有办法抓取到相应 SQL 的调用或者执行。挡板程序则是将所有环境按照生产环境进行调用,如果访问其他数据库的话,不需要做相应的访问,在这个地方会有一个挡板程序。这个挡板程序就是直接访问其他数据库,直接获取结果,不在其他数据库执行,不然会出现数据混乱。
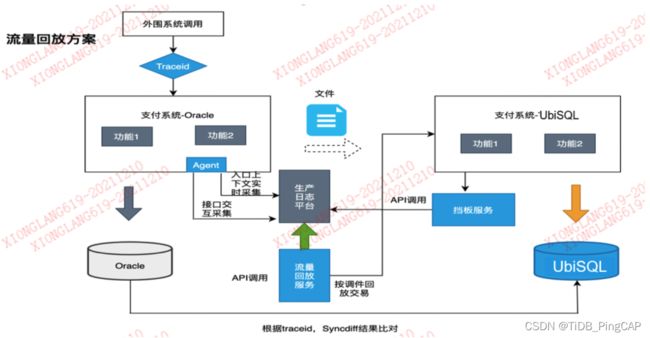
图:流量回放方案
流量回放相对比较复杂,主要是开发同学实现的。主要的实现逻辑,就是通过外围系统的调用,通过 Traceid 访问相应的功能点,功能点上面会有一个 Agent,会去把相应调用的情况和参数,调用到哪个接口记录下来,存储到日志平台上。再通过日志平台里面的存储,将这部分存储下来,存储后调用后续支付系统的 UbiSQL,就可以做到数据的回放。
因为是存储下来,想什么时候调用就可以什么时候去调,这个地方也有相应的挡板程序。做完之后我们可以做到 Oracle 和 UbiSQL 数据库的对比,因为之前的 SQL 都是一样的,而且是全量的,那么就可以把 Oracle 的数据通过恢复的方式恢复到某一个时间点,然后再把 UbiSQL 的数据通过流量回放的方式把那天的数据进行回放,这两边的数据基本就是一致的,再通过数据比对工具比对两边数据是否一致,这样来验证功能是不是完全一致。
流量复制或回放方案通过搭建生产旁路验证环境,在旁路环境进行回退链路的生产级别验证。相比传统数据库回放,这个方案进行应用 + 数据库整体架构层面的验证,降低重大核心业务系统新技术上线投产风险。并行验证通过后,完成数据迁移比对后,可直接切换上线,减少了投产时间。
数据对比与切换方案
数据切换和数据比对的方案,先看数据比对的部分。迁移 Oracle 会有一个数据比对的过程,平安集团内部的有一个 Ludbgate 工具可以实现表结构的转化、全量数据的同步、增量数据的同步,还有全量数据的比对,增量数据的比对,它是整个迁移过程中数据对比的全链路工具。
数据比对大致的逻辑是,当开始做数据同步的时候,会在日志里面记录相应的日志点,开始全量同步,全量同步完成之后就可以启动增量同步,因为记录了相应的启动时间点,后续就可以通过这个时间点做增量同步,在做增量的同时,会在中间的 MySQL 里面创建一个影子表,这个影子表的作用主要是记录进程启动后同步表的所有 dml 操作的主键值。
数据同步完成之后就可以做相应的全量同步,这时所有增量及全量数据一直在不断变化,需要进行全量的比较,可以基于这个时间点比对两边的数据,不管是否静态都可以进行比较。全量比较主要通过把数据做一定的分区,首先对表记录做分区划分,用于多进程处理,每个进程根据对应分区的 rowid 去 Oracle 获取对应的记录并算出 md5 值,同时在 UbiSQL 这端获取到这个主键值,并通过查询整个行的数据,计算出 md5 值进行比对,如果比对结果不一致就会存到影子表里面。
全量比对完成之后会启动增量对比,增量对比是每个小时启动一次,会将影子表里面的主键值拿到 Oracle 里面读取相应的记录,计算出 md5 值,再在 UbiSQL 里获取相应记录并计算出 md5 值,然后进行对比,如果一致,将此主键值从影子表中删除,如果不一致,下次在启动的时候会再次做相应对比,这样减少了比对的时间,做到最短的停机时间。

图:数据对比和切换方案
数据的切换方案通过 Oracle Ludbgate 访问到 UbiSQL 这一端,Oracle 这边有到其他 Oracle OGG 的链路,迁移是通过部分流量的切换,因为是资费系统,它需要保证迁移是完全的,没有任何问题,涉及到钱的问题,大家都觉得比较麻烦,所以我们按照切部分用户的方式去做。
我们按照切少量流量,在应用端做相应的功能开关,去做到少量数据切到 UbiSQL 这边,然后做应用的验证,如果没有问题,流量会一点一点地切到 UbiSQL 这一端。另外它有相应到第三方的同步,会启用到 kafka,同步到其他的 Oracle 数据库。这个方案有一个短板,即不能保证回退的机制,因为写到 UbiSQL之后,UbiSQL 的新增数据没有办法写回到 Oracle。也就是说回退的时候这部分数据不再被需要。我们给 TiDB 社区提了相应的需求,是不是可以做到在 TiDB 里面进行用户写入的区分,这样我们就可以做到 Oracle 到 TiDB 双向的同步,就不会存在无法回退的问题。

图:迁移后性能对比
最后看下迁移后的性能对比,可以看到,因为都是资费系统,平均响应时间特别短,迁移到 UbiSQL 后进行了大致的统计,在执行 Count 语句的时候性能有提升,在其他的查询或插入性能方面有损耗,但是损耗不大,基本在 10% 以内,应用端是可以接受的。用这套方法我们迁移了统一支付、CF2 客户关系系统以及工作流系统,这些都是属于平安集团内部比较核心的业务系统。