自动化测试实战——Selenium+Python3+unittest
源码:gitbub地址
做之前学习了:
- 慕课网自动化测试之selenium工具使用
这个是免费课程。最好的是它讲清楚了Selenium IDE和Selenium Webdriver的关系。刚开始学的时候非常容易搞混。

- 慕课网Selenium3 与 Python3 实战 Web自动化测试框架
这个教程主要以登录、注册功能为例讲解了PO模型、Unittest的使用、日志、数据驱动、关键字驱动等。整体很全面,内容也比较深入。我的代码主要参考了这个工程。
- Selenium详细文字教程
这个教程非常好,适合整理自己的思路。还有配套的b站视频。
- selenium ide+导出脚本版本2.9.1.1回退教程(firefox)
如果想使用selenium ide导出脚本,需要进行环境配置。
为什么要进行自动化测试
- 如果项目周期比较长,需求变更不频繁,项目比较大,可以用自动化测试减轻工作量。
- 反正现在作业要做,就要做了。
功能说明
要先明确测试什么功能,写出具体的说明。因为Selenium只可以测试网页,所以选择了一个电商网站 折800。我负责测试品牌团这个网页。分析过后,我决定测试一些简单的功能作为入门:查看品牌专场、商品。其实此外还有很多选择,比如“把商品加入购物车”、“搜索商品”等。“登录、注册”由于涉及到手机扫码(要和手机交互)、滑块验证(想象一下用代码控制滑块滑动)就会比较复杂。

测试用例
了解了功能之后,就要对具体的功能设计出测试用例。

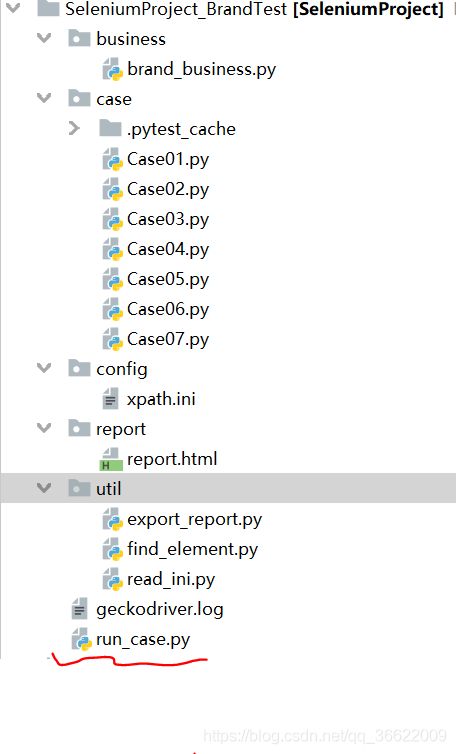
项目代码目录
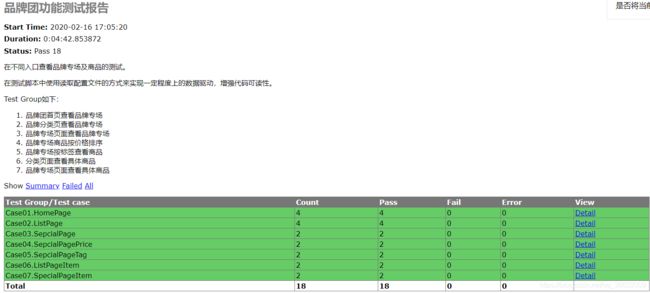
1.run_case.py是整个项目的入口脚本。负责读取case文件夹中的脚本顺序执行,及生成测试报告。
import unittest
import os
from util.export_report import export_report
class RunCase(unittest.TestCase):
def test_case(self):
case_path = os.path.join(os.getcwd(), 'case')
suite = unittest.defaultTestLoader.discover(case_path, 'Case*.py')
# 生成报告
export_report(suite)
if __name__ == '__main__':
unittest.main()(2)生成测试报告借助了python库HTMLTestRunner,主要使用方法看这个博客
from HTMLTestRunner import HTMLTestRunner # 导入生成HTML报告的包
def export_report(suite):
"""生成测试报告"""
file_path = "E:\\Python3.7\\PythonStudy\\SeleniumProject\\report\\report.html"
f = open(file_path, 'wb')
runner = HTMLTestRunner(stream=f, title="品牌专场功能测试报告",
description=u"在不同入口查看品牌专场及商品的测试",
verbosity=2)
runner.run(suite)
f.close()(3)具体的一个测试用例如下(代码可以由Selenium IDE录制生成):
# coding=utf-8
from selenium import webdriver
import unittest
from business.brand_business import BrandBusiness
class HomePage(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrome(r'e:\webdrivers\chromedriver.exe')
self.driver.implicitly_wait(30)
self.driver.get('https://www.zhe800.com')
self.driver.maximize_window()
self.brand=BrandBusiness(self.driver)
def tearDown(self):
# time.sleep(2)
self.driver.quit()
# 品牌专场入口测试
def test01_brand_pop(self):
self.brand.click_one('brand_btn')# 点击品牌团
self.brand.click_one('pop_brand_a')# 点击热卖品牌第一个品牌图标
target_name = self.brand.get_text_from_img('pop_brand_img')#获取品牌专场的名字
expect_name = self.brand.get_brand_expect_name('pop_brand_a')#获取点开链接后的专场名字
return self.assertTrue(expect_name == target_name, "测试失败")#判断两个名字是否相同
def test02_brand_card(self):
self.brand.click_one('brand_btn')# 点击品牌团
self.brand.click_one('brand_card_a') # 点击第一个品牌卡片
target_name = self.brand.get_text_from_content('brand_card_text_a')# 获取品牌专场的名字
expect_name = self.brand.get_brand_expect_name('brand_card_a')#获取点开链接后的专场名字
return self.assertTrue(expect_name == target_name, "测试失败")#判断两个名字是否相同
# if __name__ == '__main__':
# suite = unittest.TestSuite()
# suite.addTest(HomePage('test01_brand_pop'))
# suite.addTest(HomePage('test02_brand_card'))
# unittest.TextTestRunner().run(suite)
注释掉的main函数可以用来测试单独的testcase。需要注意的几个点是:
- test case函数必须以“test”开头命名。
- 在每个test case执行前都会执行setUp函数,在执行后都会执行tearDown函数。
(4)brand_business.py主要是封装了一些测试用例中的重复代码。
(5)为了增加可读性和方便后续修改,采用读配置文件的办法来获取xpath,然后再进行web元素的获取。
xpath.ini内容如下:
[BrandElement]
brand_btn=//*[@id="head_nav"]/div/div[1]/div/a[5]
pop_brand_img=/html/body/div[7]/ul/li[1]/a[1]/img
pop_brand_a=/html/body/div[7]/ul/li[1]/a[1]
brand_h1=/html/body/div[5]/div[1]/div/h1读配置文件的方法封装在read_ini.py中:
# coding=utf-8
import configparser
class ReadIni(object):
def __init__(self, file_name=None, node=None):
if file_name == None:
file_name = r"E:\Python3.7\PythonStudy\SeleniumProject\config\xpath.ini"
if node == None:
self.node = "BrandElement"
else:
self.node = node
self.cf = self.load_ini(file_name)
# 加载文件
def load_ini(self, file_name):
cf = configparser.ConfigParser()
cf.read(file_name)
return cf
# 获取value的值
def get_value(self, key):
data = self.cf.get(self.node, key)
return data
# if __name__ == '__main__':
# read_init = ReadIni()
# print(read_init.get_value('brand_btn'))(6)最后生成的测试报告是这样的: