pandas进行数据处理
pandas读取多列
选择表格中的’w’、'z’列
data[[‘w’,‘z’]]
这里是双重方括号!
时间问题
需要把中文转为其他click here
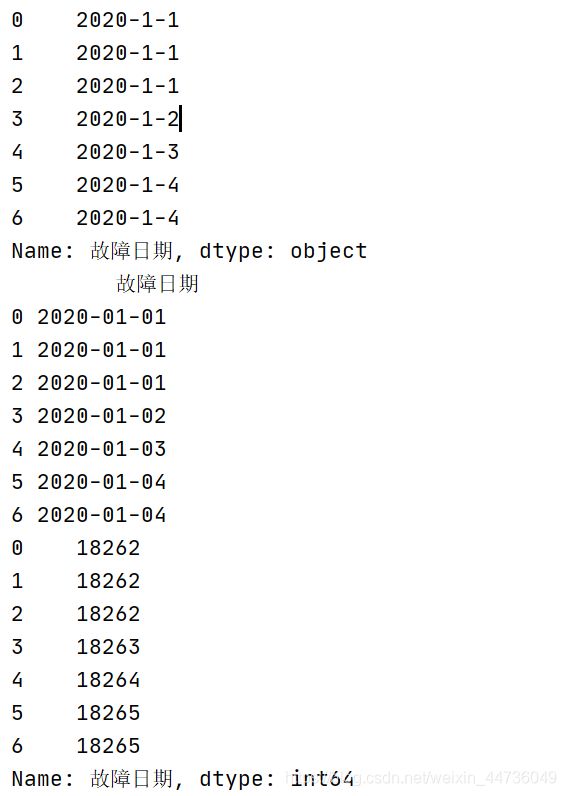
涉及到时间的差值问题的时候,可以首先转化为datatime类型数据支持日期运算
代码中附带正则表达式替换。其中delta.dt.days可以查看差值大小。
import pandas as pd
data = pd.read_csv('./data_trans_Test.csv', encoding='gbk')
data[u'故障日期'].replace((u'年', u'月'), '-', regex=True, inplace=True)
data[u'故障日期'].replace(u'日', '', regex=True, inplace=True)
print(data[u'故障日期'])
data[u'故障日期'] = pd.to_datetime(data[u'故障日期'])
delta = data[u'故障日期'] - pd.to_datetime('1970-01-01')
print(data)
print(delta.dt.days)
DataFrame增加列与删除列操作
DataFrame添加一列的方法非常简单,只需要新建一个列索引。并对该索引下的数据进行赋值操作即可。
import pandas as pd
data = {'Name':['Tom', 'Jack', 'Steve', 'Ricky'],'Age':[28,34,29,42]}
df = pd.DataFrame(data, index=['s1','s2','s3','s4'])
df['score']=pd.Series([90, 80, 70, 60], index=['s1','s2','s3','s4'])
print(df)
Name Age score
s1 Tom 28 90
s2 Jack 34 80
s3 Steve 29 70
s4 Ricky 42 60
删除列
import pandas as pd
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd']),
'three' : pd.Series([10, 20, 30], index=['a', 'b', 'c'])}
df = pd.DataFrame(d)
print("dataframe is:")
print(df)
# 删除一列: one
del(df['one'])
print(df)
#调用pop方法删除一列
df.pop('two')
print(df)
增加行
import pandas as pd
df = pd.DataFrame([['zs', 12], ['ls', 4]], columns = ['Name','Age'])
df2 = pd.DataFrame([['ww', 16], ['zl', 8]], columns = ['Name','Age'])
df = df.append(df2)
print(df)
删除行
import pandas as pd
df = pd.DataFrame([['zs', 12], ['ls', 4]], columns = ['Name','Age'])
df2 = pd.DataFrame([['ww', 16], ['zl', 8]], columns = ['Name','Age'])
df = df.append(df2)
Name Age
0 zs 12
1 ls 4
0 ww 16
1 zl 8
------------------
# 删除index为0的行
df = df.drop(0)
print(df)
Name Age
1 ls 4
1 zl 8
pandas的排序方式
使用
sort_index()
方法,通过传递axis参数和排序顺序,可以对DataFrame进行排序。 默认情况下,按照升序对行标签进行排序。
import pandas as pd
import numpy as np
# 按照行标进行排序(按照列排序则在sort_index传入axis=1)
sorted_df=unsorted_df.sort_index()
print (sorted_df)
col2 col1
0 -0.798315 1.216546
1 0.395530 0.025233
2 -0.880199 -0.936372
3 0.610572 0.118816
4 -0.406779 0.873662
5 -0.343186 -0.822493
6 -0.637138 0.830524
7 -0.241964 0.339942
8 0.775675 2.003242
9 -0.911961 -0.061606
-----------------------
# 控制排序顺序
sorted_df = unsorted_df.sort_index(ascending=False)
print (sorted_df)
col2 col1
9 0.575977 -0.359740
8 -0.253888 -1.466810
7 -1.255561 0.325737
6 0.870994 0.875937
5 -0.809964 -2.042410
4 0.134664 -0.480342
3 -0.978605 0.301837
2 0.879021 -0.154140
1 1.692807 0.502087
0 -1.300620 0.035543
按某列值排序
像索引排序一样,sort_values()是按值排序的方法。它接受一个by参数,它将使用要与其排序值的DataFrame的列名称。
import pandas as pd
import numpy as np
d = {'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Minsu','Jack',
'Lee','David','Gasper','Betina','Andres']),
'Age':pd.Series([25,26,25,23,30,29,23,34,40,30,51,46]),
'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8,3.78,2.98,4.80,4.10,3.65])}
unsorted_df = pd.DataFrame(d)
# 按照年龄进行排序
sorted_df = unsorted_df.sort_values(by='Age')
print (sorted_df)
# 先按Age进行升序排序,然后按Rating降序排序
sorted_df = unsorted_df.sort_values(by=['Age', 'Rating'], ascending=[True, False])
print (sorted_df)
pandas分组
import pandas as pd
ipl_data = {'Team': ['Riders', 'Riders', 'Devils', 'Devils', 'Kings',
'kings', 'Kings', 'Kings', 'Riders', 'Royals', 'Royals', 'Riders'],
'Rank': [1, 2, 2, 3, 3,4 ,1 ,1,2 , 4,1,2],
'Year': [2014,2015,2014,2015,2014,2015,2016,2017,2016,2014,2015,2017],
'Points':[876,789,863,673,741,812,756,788,694,701,804,690]}
df = pd.DataFrame(ipl_data)
print(df)
# 按照年份Year字段分组
print (df.groupby('Year'))
# 查看分组结果
print (df.groupby('Year').groups)
groupby返回可迭代对象,可以使用for循环遍历
grouped = df.groupby('Year')
# 遍历每个分组
for year,group in grouped:
print (year)
2014
2015
2016
2017
print (group)
Team Rank Year Points
0 Riders 1 2014 876
2 Devils 2 2014 863
4 Kings 3 2014 741
9 Royals 4 2014 701
Team Rank Year Points
1 Riders 2 2015 789
3 Devils 3 2015 673
5 kings 4 2015 812
10 Royals 1 2015 804
Team Rank Year Points
6 Kings 1 2016 756
8 Riders 2 2016 694
Team Rank Year Points
7 Kings 1 2017 788
11 Riders 2 2017 690
获得一个分组细节
grouped = df.groupby('Year')
print (grouped.get_group(2014))
pandas连表操作,类似于数据库
Pandas提供了一个单独的merge()函数,作为DataFrame对象之间所有标准数据库连接操作的入口。
合并两个DataFrame
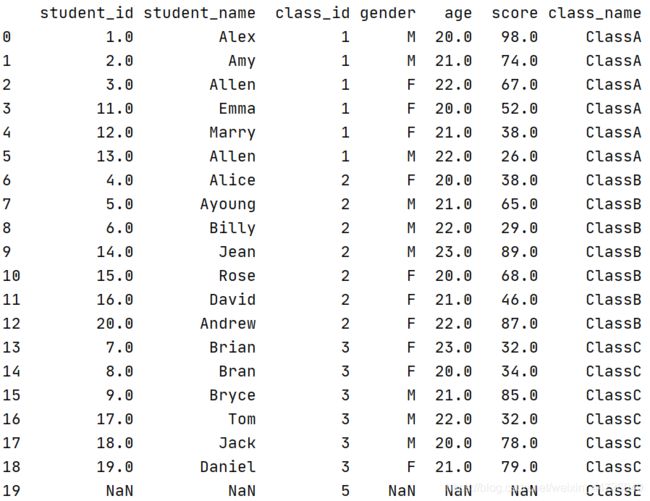
import pandas as pd
left = pd.DataFrame({
'student_id':[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20],
'student_name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung', 'Billy', 'Brian', 'Bran', 'Bryce', 'Betty', 'Emma', 'Marry', 'Allen', 'Jean', 'Rose', 'David', 'Tom', 'Jack', 'Daniel', 'Andrew'],
'class_id':[1,1,1,2,2,2,3,3,3,4,1,1,1,2,2,2,3,3,3,2],
'gender':['M', 'M', 'F', 'F', 'M', 'M', 'F', 'F', 'M', 'M', 'F', 'F', 'M', 'M', 'F', 'F', 'M', 'M', 'F', 'F'],
'age':[20,21,22,20,21,22,23,20,21,22,20,21,22,23,20,21,22,20,21,22],
'score':[98,74,67,38,65,29,32,34,85,64,52,38,26,89,68,46,32,78,79,87]})
right = pd.DataFrame(
{'class_id':[1,2,3,5],
'class_name': ['ClassA', 'ClassB', 'ClassC', 'ClassE']})
# 合并两个DataFrame
data = pd.merge(left,right) #左连接
#data = pd.merge(left,right,how='right')##右连接
print(data)
左连接(根据左表的id来进行连接)

右连接(根据右表的id来进行连接)

透视表
透视表(pivot table)是各种电子表格程序和其他数据分析软件中一种常见的数据汇总工具。它根据一个或多个键对数据进行分组聚合,并根据每个分组进行数据汇总
# 以class_id与gender做分组汇总数据,默认聚合统计所有列,但是只是聚合数字的列,字母的列并不会聚合
print(data.pivot_table(index=['class_id', 'gender']))
age score student_id
class_id gender
1 F 21.000000 52.333333 8.666667
M 21.000000 66.000000 5.333333
2 F 20.750000 59.750000 13.750000
M 22.000000 61.000000 8.333333
3 F 21.333333 48.333333 11.333333
M 21.000000 65.000000 14.666667
# 以class_id与gender做分组汇总数据,聚合统计score列
print(data.pivot_table(index=['class_id', 'gender'], values=['score']))
score
class_id gender
1 F 52.333333
M 66.000000
2 F 59.750000
M 61.000000
3 F 48.333333
M 65.000000
# 以class_id与gender做分组汇总数据,聚合统计score列,针对age的每个值列级分组统计
print(data.pivot_table(index=['class_id', 'gender'], values=['score'], columns=['age']))
score
age 20 21 22 23
class_id gender
1 F 52.0 38.0 67.0 NaN
M 98.0 74.0 26.0 NaN
2 F 53.0 46.0 87.0 NaN
M NaN 65.0 29.0 89.0
3 F 34.0 79.0 NaN 32.0
M 78.0 85.0 32.0 NaN
# 以class_id与gender做分组汇总数据,聚合统计score列,针对age的每个值列级分组统计,添加行、列小计
print(data.pivot_table(index=['class_id', 'gender'], values=['score'],
columns=['age'], margins=True))
score
age 20 21 22 23 All
class_id gender
1 F 52.000000 38.0 67.0 NaN 52.333333
M 98.000000 74.0 26.0 NaN 66.000000
2 F 53.000000 46.0 87.0 NaN 59.750000
M NaN 65.0 29.0 89.0 61.000000
3 F 34.000000 79.0 NaN 32.0 48.333333
M 78.000000 85.0 32.0 NaN 65.000000
All 61.333333 64.5 48.2 60.5 58.789474
# 以class_id与gender做分组汇总数据,聚合统计score列,针对age的每个值列级分组统计,添加行、列小计
print(data.pivot_table(index=['class_id', 'gender'], values=['score'], columns=['age'], margins=True, aggfunc='max'))
score
age 20 21 22 23 All
class_id gender
1 F 52.0 38.0 67.0 NaN 67
M 98.0 74.0 26.0 NaN 98
2 F 68.0 46.0 87.0 NaN 87
M NaN 65.0 29.0 89.0 89
3 F 34.0 79.0 NaN 32.0 79
M 78.0 85.0 32.0 NaN 85
All 98.0 85.0 87.0 89.0 98
交叉表
是一种用于计算分组频率的特殊透视表:
# 按照class_id分组,针对不同的gender,统计数量
print(pd.crosstab(data.class_id, data.gender, margins=True))
gender F M All
class_id
1 3 3 6
2 4 3 7
3 3 3 6
All 10 9 19
pandas可视化
plot方法允许除默认线图之外的少数绘图样式。 这些方法可以作为plot()的kind关键字参数。这些包括 :
bar或barh为条形
hist为直方图
scatter为散点图
pandas数据读取
# filepath 文件路径。该字符串可以是一个URL。有效的URL方案包括http,ftp和file
# sep 分隔符。read_csv默认为“,”,read_table默认为制表符“[Tab]”。
# header 接收int或sequence。表示将某行数据作为列名。默认为infer,表示自动识别。
# names 接收array。表示列名。
# index_col 表示索引列的位置,取值为sequence则代表多重索引。
# dtype 代表写入的数据类型(列名为key,数据格式为values)。
# engine 接收c或者python。代表数据解析引擎。默认为c。
# nrows 接收int。表示读取前n行。
pd.read_table(
filepath_or_buffer, sep='\t', header='infer', names=None,
index_col=None, dtype=None, engine=None, nrows=None)
pd.read_csv(
filepath_or_buffer, sep=',', header='infer', names=None,
index_col=None, dtype=None, engine=None, nrows=None
pd.cut() 和 pd.qcut()
#qcut是根据这些值的频率来选择箱子的均匀间隔每个箱子中含有的数的数量是相同的
#cut将根据值本身来选择箱子均匀间隔,即每个箱子的间距都是相同的,但是数量是不一定相同的
pd.cut()
import numpy as np
import pandas as pd
# 我们先给 scores传入30个从0到100随机的数
scores = np.random.uniform(0,100,size=30)
# 然后使用 np.round()函数控制数据精度
scores = np.round(scores,1) #一位小数
# 指定分箱的区间
grades = [0,59,70,85,100]
cuts = pd.cut(scores,grades)
print(cuts)
print(pd.value_counts(cuts))
group_names = ['不及格','及格','良','优秀']
cuts1 = pd.cut(scores,grades,labels=group_names)
#这个只是把范围改成标签
print(cuts1)
print(pd.value_counts(cuts1))
scores1 = np.random.uniform(0,100,size=30)
cuts2 = pd.cut(scores1,4,precision=2)
# 将成绩的值均匀的分在四个箱子中,
#选项将精度控制在两位。所以不会出现个数相等。
precision=2
print(cuts2)
print(pd.value_counts(cuts2))

pd.qcut()
scores_qcut = np.random.uniform(0,100,size=30)
cut_qcut = pd.qcut(scores_qcut, 5)
print(cut_qcut)
print(pd.value_counts(cut_qcut))

map函数(Series)
注意 map()中不能使用sum之类的函数,for循环
map是Series的一个函数,所以只能是某一列数据
map()可以映射新一列数据
map()中可以使用lambd表达式
map()中可以使用方法,可以是自定义的方法
df = pd.DataFrame(data[['zhangsan',1000,'sale'],
['lisi',2000,'dev'], ['wangwu',3333,'dev']],
columns= ['name','salary','dep'])
df['e_name']=df['name'].map({'lisi':'Tony','zhangsan':'Tom','wangwu':'Jerry'})
print(df)
name salary dep e_name
0 zhangsan 1000 sale Tom
1 lisi 2000 dev Tony
2 wangwu 3333 dev Jerry
map() applymap() apply()
Series的map方法可以接受一个函数或含有映射关系的字典型对象。使用map是一种实现元素级转换以及其他数据清理工作的便捷方式。(DataFrame中对应的是applymap()函数,当然DataFrame还有apply()函数)
toward_dict = {1: '东', 2: '南', 3: '西', 4: '北'}
df = pd.DataFrame({'house' : list('AABCEFG'),
'price' : [100, 90, '', 50, 120, 150, 200],
'toward' : ['1','1','2','3','','3','2']})
house price toward
0 A 100 1
1 A 90 1
2 B 2
3 C 50 3
4 E 120
5 F 150 3
6 G 200 2
map()
df['朝向'] = df.toward.map(toward_dict)
匹配不出来,因为df.toward这列数字是str型的, toward_dict中的key是int型,下面修正操作下:两个思路:
house price toward 朝向
0 A 100 1 NaN
1 A 90 1 NaN
2 B 2 NaN
3 C 50 3 NaN
4 E 120 NaN
5 F 150 3 NaN
6 G 200 2 NaN
#第一种思路:toward_dict的key转换为str型
toward_dict2 = dict((str(key), val) for key, val in toward_dict.items())
# 第二种思路, 将df.toward转为int型
df.toward = df.toward.map(lambda x: np.nan if x == '' else x).map(int,na_action='ignore')
df['朝向2'] = df.toward.map(toward_dict);df
apply()
apply()将一个函数作用于DataFrame中的每个行或者列
df = pd.DataFrame({'key1' : ['a', 'a', 'b', 'b', 'a'],
'key2' : ['one', 'two', 'one', 'two', 'one'],
'data1' : np.arange(5),
'data2' : np.arange(5,10)})
#我们现在用apply来对列data1,data2进行相加
df['total'] = df[['data1','data2']].apply(lambda x : x.sum(),axis=1 )
key1 key2 data1 data2 total
0 a one 0 5 5
1 a two 1 6 7
2 b one 2 7 9
3 b two 3 8 11
4 a one 4 9 13
df.loc['total']=df[['data1','data2']].apply(lambda x : x.sum(),axis=0 )
key1 key2 data1 data2 total
0 a one 0.0 5.0 5.0
1 a two 1.0 6.0 7.0
2 b one 2.0 7.0 9.0
3 b two 3.0 8.0 11.0
4 a one 4.0 9.0 13.0
total NaN NaN 10.0 35.0 NaN
applymap()
将函数做用于DataFrame中的所有元素(elements)
例如,在所有元素前面加个字符A
def addA(x):
return "A" + str(x)
df.applymap(addA)
key1 key2 data1 data2 total
0 Aa Aone A0.0 A5.0 A5.0
1 Aa Atwo A1.0 A6.0 A7.0
2 Ab Aone A2.0 A7.0 A9.0
3 Ab Atwo A3.0 A8.0 A11.0
4 Aa Aone A4.0 A9.0 A13.0
total Anan Anan A10.0 A35.0 Anan
split()函数
import pandas as pd
df=pd.DataFrame({"A":["ad-s","df-w","er-3w","23-wd"],"B":[1,2,3,4]})
df
A B
0 ad-s 1
1 df-w 2
2 er-3w 3
3 23-wd 4
df["A"].str.split("-")
0 [ad, s]
1 [df, w]
2 [er, 3w]
3 [23, wd]
.str提供了一个访问series每一行的接口
df["A"].str.split("-")[0]
['ad', 's']
str只是给访问dataframe的列中的内容提供了接口
这里不是访问列,而是访问某列中的每行。访问行可以这样。
df["A"].str.split("-").str[0]
0 ad
1 df
2 er
3 23
# Input
df = pd.DataFrame(["STD, City State",
"33, Kolkata West Bengal",
"44, Chennai Tamil Nadu",
"40, Hyderabad Telengana",
"80, Bangalore Karnataka"], columns=['row'])
print(df)
# Solution
df_out = df.row.str.split(',|\t', expand=True)
# Make first row as header
new_header = df_out.iloc[0]
df_out = df_out[1:]
df_out.columns = new_header
print(df_out)
row
0 STD, City State
1 33, Kolkata West Bengal
2 44, Chennai Tamil Nadu
3 40, Hyderabad Telengana
4 80, Bangalore Karnataka
================================================
0 STD City State
1 33 Kolkata West Bengal
2 44 Chennai Tamil Nadu
3 40 Hyderabad Telengana
4 80 Bangalore Karnataka
count()和size()
size跟count的区别: size计数时包含NaN值,而count不包含NaN值
df = pd.DataFrame({"Name":["Alice", "Bob", "Mallory", "Mallory", "Bob" , "Mallory"],
...: "City":["Seattle", "Seattle", "Portland", "Seattle", "Seattle", "Portland"],
...: "Val":[4,3,3,np.nan,np.nan,4]})
...:
...: df
...:
Out[10]:
City Name Val
0 Seattle Alice 4.0
1 Seattle Bob 3.0
2 Portland Mallory 3.0
3 Seattle Mallory NaN
4 Seattle Bob NaN
5 Portland Mallory 4.0
count()
df.groupby(["Name", "City"], as_index=False)['Val'].count()
Out[11]:
Name City Val
0 Alice Seattle 1
1 Bob Seattle 1
2 Mallory Portland 2
3 Mallory Seattle 0
size()
df.groupby(["Name", "City"])['Val'].size().reset_index(name='Size')
Name City Size
0 Alice Seattle 1
1 Bob Seattle 2
2 Mallory Portland 2
3 Mallory Seattle 1
更多请参考