<论文翻译>RepVGG: Making VGG-style ConvNets Great Again
RepVGG:让VGG风格的卷积网络再一次伟大
文章目录
- RepVGG:让VGG风格的卷积网络再一次伟大
-
- 摘要
- 1. Introduction
- 2. Related Work
-
- 2.1 从单路径到多分支
- 2.2 有效的单路径模型的训练
- 2.3 模型重新参数化
- 2.4 温诺格勒(Winograd)卷积
- 3. 通过结构性重新参数化构建RepVGG
-
- 3.1 简单就是快,内存经济型,灵活
- 3.2 训练时间多分支架构
- 3.3 普通的推理模型的重新化参数
- 3.4 架构特殊化
- 4. 实验
-
- 4.1 RepVGG用于图像分类网络
- 4.2 结构性的重新化参数是关键
- 4.3 语义分割
- 4.4 局限
- 5. 结论
- References
作者

摘要
我们提出了一个简单但功能强大的卷积神经网络架构,该架构具有类似于VGG的推理时间体(inference-time body),该推理体仅由3×3卷积和ReLU的堆栈组成,而训练时间模型具有一个多分支拓扑。 训练时间和推理时间架构的这种解耦是通过结构的重新参数化技术(structural re-parameterization technique)实现的,因此模型叫做RepVGG。 在ImageNet上,RepVGG达到80%以上top-1精度,据我们所知这是普通模型中的首个。在NVIDIA 1080Ti GPU上,RepVGG模型的运行速度比ResNet-50快83%或101%与诸如EfficientNet和RegNet的最新模型相比,具有比ResNet-101更高的速度和更高的精度,并显示出良好的精度和速度之间的权衡。代码和经过训练的模型可以在这个地址找到:https://github.com/megvii-model/RepVGG.
1. Introduction
卷积神经网络(ConvNets)已经成为许多任务的主流解决方案。 VGG [30]通过由卷积,ReLU和池化组成的组成的简单架构在图像领域实现了巨大的成功。有了Inception [32,33,31,17],ResNet [10]和DenseNet [15],许多研究兴趣转移到精心设计的架构,使模型更多、更复杂。 最近一些强大的架构是通过自动[43、28、22]或手动[27]架构搜索或在基础体系结构上搜索的复合缩放策略获得的[34]。
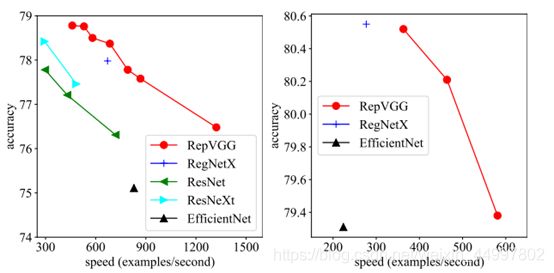
fig.1. ImageNet的Top-1准确性与实际速度之间的关系。左:轻量级和中量级RepVGG和训练了120个epoch的基线(baselines)。 右:训练了200个epoch的重量级模型。速度是在相同的1080Ti测得的,一个batch的大小为128,全精度(fp32),单笔裁剪(single crop),以示例/秒(examples/second)为单位。用于EfficientNet-B3 [34]的输入分辨率为300,其他则为224。

Table.4. RepVGG模型和基线(baselines)在图网络(ImageNet)上进行了简单数据增强,训练了120个epoch。 该速度在1080Ti上测得,批处理量为128,全精度(fp32),以示例/秒(examples/secnd)为单位进行了测量。我们算理论上所述的FLOP和Wino MULs写在了2.4。 基线(baselines)是我们具有相同训练设置的实现。
尽管许多复杂的ConvNet都比简单的ConvNet提供更高的准确性,但缺点也很明显。1)复杂的多分支设计(例如,ResNet中的残差加法(residual-addition)和Inception中的分支级联(branch-concatenation))使模型难以实现和定制(customize),降低了推断速度并降低内存利用率。 2)一些组件(例如,Xception[2]和MobileNets [14,29]中的深度智能卷积(depthwise conv)以及ShuffleNets[23,40]中的频道随机播放(channel ))增加了内存访问成本,并且缺乏各种设备的支持。 有这么多影响推论速度的因素,每秒浮点运算次数(FLOP)不能准确反映实际速度。尽管一些新颖的模型的FLOP低于VGG和ResNet-18/34/50 [10]等老式模型,但它们可能并不运行得更快(Table.4)。 因此,VGG和ResNets的原始版本在学术界和工业界仍被大量用于实际应用。

fig.2. RepVGG体系结构示意图。RepVGG有5个阶段,并在每个阶段开始时通过stride-2卷积进行下采样。 在这里我们只显示一个特定阶段的前4层。受ResNet [10]的启发,我们也使用实体(identity)和1×1分支,但仅用于训练。
在本文中,我们提出了RepVGG,这是一种VGG风格的架构,其性能优于许多复杂的模型(fig.2)。RepVGG具有以下优点。
•模型具有类似VGG(也称为前馈)的朴素拓扑结构,没有任何分支。 也就是说,每一层都只需要前一层的输出作为输入并且只输出到其下一层。
•模型的主体仅使用3×3 conv和ReLU。
•具体架构(包括具体深度和图层宽度)不会被实例化以自动搜索[43],手动优化[27],复合缩放[34]或其他繁琐的设计。
普通模型要达到和多分支架构可比的性能级别是极有挑战性的。 一个解释是多分支的拓扑,例如ResNet,使该模型成为众多更浅的模型的隐式集合[35],因此可以训练多分支模型避免了梯度消失的问题。
由于多分支体系结构的全部好处在于训练,而缺点则不希望用于推理,因此我们建议通过结构重新参数化(structural re-paramaterization)将训练时间的多分支和推理时间的普通架构解耦,这意味着通过转换其参数将架构转换为另一种。具体而言,一个网络结构是与一组参数耦合的,例如,一个conv层可由一个4th-order kernel tensor。 如果某个结构的参数可以转换为与另一种结构耦合的另一组参数,我们可以用后者等效地替换前者,从而改变整个网络体系结构。

fig.4. RepVGG块的结构性重新参数化。为了便于可视化,我们假设C2 = C1 = 2,因此3×3层具有四个3×3矩阵,而1×1层的核是2×2矩阵。
具体来说,我们使用实体(identity)和1×1分支构造训练时的RepVGG,这是受了ResNet的启发,但通过结构性重新参数化可以删除分支(fig.2,4)。 训练后,我们用简单的代数进行变换,因为一个实体分支可以看作是退化的1×1 conv,而后者又可以看作是退化的3×3 conv,因此我们可以构造一个具有训练好的原始3×3内核的参数的单一的3×3内核(这句话有点绕),实体和1×1分支以及批归一化层(batch normalization)[17]。因此,转换后的模型具有许多3×3 conv层,将其保存以进行测试和部署。
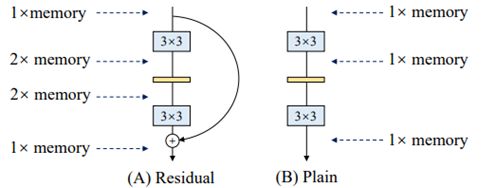
fig.3. 剩余(residual)和普通模型中的峰值内存占用。如果残差块保持特征图(feature map)的大小,则特征图占用的内存峰值将是输入值的2倍。 与因此忽略的特征相比,模型参数占用的内存较小。
值得注意的是,推理时间RepVGG的主体仅涉及一种单一类型的操作:跟随以ReLU的3×3 conv,这使得RepVGG在诸如GPU之类的通用计算设备上快速运行。更好的是,RepVGG允许专用硬件来实现更高的速度,因为给定了芯片尺寸和功耗,我们需要的操作类型越少,我们可以集成到芯片上的计算单元就越多。 即,专用于RepVGG的推理芯片可以具有大量的3×3-ReLU单元和更少的存储单元(因为普通拓扑在存储方面是经济的,如fig.3所示)。我们的贡献总结如下。
•我们提出了RepVGG,这是一种简单的架构,与最新技术相比,具有良好的速度精度折衷。
•我们建议使用结构性重新参数化将训练时的多分支拓扑与推理时的纯体系结构分离。
•我们已经展示了RepVGG在图像分类和语义分割中的有效性,以及实现的效率和简便性。
2. Related Work
2.1 从单路径到多分支
在VGG [30]将ImageNet分类的top-1准确性提高到70%以上之后,在使ConvNets变得复杂以提高性能方面,出现了许多创新,例如,现代的GoogLeNet [32]和后来的采用精心设计的多分支架构的Inception模型[33,31,17],ResNet [10]提出了一种简化的两分支架构,而DenseNet [15]通过连接低层和高层使拓扑更加复杂。神经架构搜索(NAS)[43、28、22、34]和手动设计空间设计[27]可以生成具有更高性能的ConvNet,但要付出大量计算资源或人力的代价。 NAS生成的模型的某些大型版本甚至无法在普通GPU上进行训练,因此限制了应用程序。 除了执行上的不便外,复杂的模型可能会降低并行性[23],因此减慢了推理速度。
2.2 有效的单路径模型的训练
已经进行了一些在没有分支结构的情况下训练ConvNets的尝试。 但是,现有技术主要试图使非常深的模型以合理的精度收敛,而不是使其比复杂的模型获得更好的性能。 因此,方法和结果模型既不简单也不实际。 例如,一种初始化方法[36]被提出以训练非常深的普通的ConvNets。 通过基于均值场理论的方案,训练了10,000层以上的网络,在MNIST上取得了超过99%的精度,在CIFAR-10上取得了82%以上的精度。 尽管这些模型不切实际(即使LeNet-5 [19]在MNIST上可以达到99.3%的准确度,而VGG-16在CIFAR10上也可以达到93%以上的准确度),但是理论上的贡献是有见地的。 最近的一项工作[24]结合了多种技术,包括Leaky ReLU,max-norm和小心的初始化。在ImageNet上,它显示具有147M参数的普通ConvNet可以达到74.6%的top-1精度,比其报告的基线(ResNet-101,76.6%,45M参数)低2%。
值得注意的是,本文不仅说明普通模型可以很好地收敛,而且不打算训练像ResNets这样的非常深的ConvNets,而是旨在构建一个具有合理深度和有利的精度-速度折衷的简单模型, 可以使用最常见的组件(例如常规conv和BN)和简单的代数简单地实现。
2.3 模型重新参数化
DiracNet [38]是与我们相关的重新参数化方法。它通过将conv层的内核编码为W = diag(a)I + diag(b)Wnorm来构建深度普通模型,其中W是用于卷积的最终权重(将四阶张量视为矩阵),a和b是学习的向量,Wnorm是归一化的可学习内核。与具有相当数量参数的ResNet相比,DiracNet的top-1准确性比CIFAR100低2.29%(78.46%对80.75%),比ImageNet低0.62%(DiracNet-34的72.21%对ResNet-34的72.83%)。 DiracNet与我们的方法的不同之处在于:1)我们的结构重新参数化是实际的数据流通过一个具体的结构来实现的,之后可以将其转换成另一个,而DiracNet仅使用conv内核的另一个数学表达式来简化优化。即,结构上重新参数化的纯模型是真实的训练时多分支模型,而DiracNet不是。 2)DiracNet的性能高于一般参数化的普通模型,但低于相当大的ResNet,而RepVGG模型的性能超出ResNets很大的距离。非对称转换块(ACB)[9]采用非对称转换来增强常规conv的“骨架”,从将训练后的块转换为一个conv的意义上来说,这可以看作是结构重新参数化的另一种形式。与我们的方法相比,区别在于ACB是为组件级改进而设计的,并且可以用作任何架构中conv层的直接替代品,而我们的结构重新参数化对于训练普通的ConvNets至关重要,如4.2节所示。

Table.5. RepVGG模型和baselines在带有自动增强、标签平滑和mixup的情况下训练了200个epochs.
2.4 温诺格勒(Winograd)卷积

Table.1. 在NVIDIA 1080Ti上具有不同内核大小速度测试,批处理大小= 32,输入通道=输出通道= 2048,分辨率=56×56,步幅= 1。 时间的结果是硬件预热后使用10次的结果平均。
RepVGG仅使用3×3 conv,因为它已在GPU和CPU上得到了一些现代计算库(如NVIDIA cuDNN [1]和Intel MKL [16])的高度优化。Table.1显示了在1080Ti GPU上使用cuDNN 7.5.0测试的理论FLOP,实际运行时间和计算密度(以每秒Tera浮点运算为单位,即TFLOPS)2。结果表明,3×3 conv的理论计算密度约为其他的4倍,这表明总的理论FLOP不能替代不同结构中的实际速度。 Winograd算法[18](仅当步幅为1时)是加速3×3 conv的经典算法,该类库已经得到了像cuDNN和MKL这样的类库的很好的支持(默认情况下启用)。例如,使用标准F(2×2、3×3)Winograd,3×3conv的乘积(MUL)减少为原来的4/9。由于乘法比加法耗时得多,因此我们计算MUL来衡量Winograd支持下的计算成本(在Table 4、5中由Wino MUL表示)。请注意,特定的计算库和硬件决定是否对于每个运营商使用Winograd,因为小规模的卷积由于内存开销未必会被加速。
3. 通过结构性重新参数化构建RepVGG
3.1 简单就是快,内存经济型,灵活
至少有三个使用简单ConvNets的理由:快、内存经济以及灵活。
**关于快。**许多最新的多分支架构具有比VGG更低的理论FLOP,但运行速度可能并不更快。例如,VGG-16有着EfficientNet-B3 [34]8.4倍的FLOP,但在1080Ti上的运行速度高出其1.8倍(表4),这意味着前者的计算密度是后者的15倍。除了Winograd conv带来的加速以外,FLOP和速度之间的差异可以归因于两个重要因素,它们对速度有很大影响,但FLOP并未考虑这些因素:内存访问成本(memory access cost,MAC)和并行度[23]。例如,尽管所需的分支加法或级联计算可以忽略不计,但MAC还是很重要的。此外,MAC在成组卷积中占时间使用的很大一部分。另一方面,有着相同数目的FLOP,具有高并行度的模型可能比具有低并行度的模型快得多。由于在Inception和自动生成的架构中广泛采用了多分支拓扑,因此使用了多个小运算符,而不是几个大运算符。先前的一项工作[23]报告说,NASNET-A [42]中的碎片运算符的数量(即,单个构建块中的单个conv或池操作的数量)为13,这对具有强大并行计算能力的设备(如GPU)不友好,引入了额外的开销,例如内核启动和同步。相比之下,这个数字在ResNets中是2或3,我们做到1:一次转换。
**关于内存经济。**多分支拓扑是内存效率低下的,因为每个分支的结果都需要保持到添加或串联为止,从而显着提高了内存占用的峰值。 例如,如fig.3所示,一个剩余块的输入需要保持到它被相加。假设该块保持特征图的大小,则存储器占用的峰值为输入的2倍。 相反,简单的拓扑结构允许在操作完成后立即释放特定层的输入所占用的内存。 在设计专用硬件时,普通的ConvNet可以进行深度内存优化并降低内存单元的成本,因此我们可以将更多计算单元集成到芯片上。
**关于灵活。**多分支拓扑对架构规范施加了约束。 例如,ResNet要求将conv层组织为残差块,这限制了灵活性,因为每个残差块的最后一个conv层必须产生相同形状的张量,否则快捷方式添加将没有意义。 更糟糕的是,多分支拓扑限制了channel pruning的应用[20,12],这是一种实用的技术,可以去除一些不重要的通道,并且某些方法可以通过自动发现每层的适当宽度来优化模型结构[7]。但是,多分支模型使修剪变得棘手,并导致显著的性能下降或低加速率。相比之下,简单的架构使我们可以根据我们的要求自由配置每个conv层,并进行修剪以获得更好的性能与效率间的权衡。
3.2 训练时间多分支架构
普通的ConvNets有很多优点,但有一个致命的缺点:性能不佳。例如,使用BN [17]等现代组件,VGG-16可以在ImageNet上达到72%的top-1精度,似乎已经过时。我们的结构化重新参数化方法受到ResNet的启发,该方法显式构造了一个捷径分支,将信息流建模为y = x + f(x),并使用残差块学习f。当x和f(x)的尺寸不匹配时,它变为y = g(x)+ f(x),其中g(x)是由1×1 conv实现的卷积捷径。 ResNets成功的一个解释是,这种多分支架构使该模型成为许多较浅模型的隐式集成[35]。具体来说,对于n个块,该模型可以解释为2 ^ n个模型的集合,因为每个块将流分支为两条路径。
鉴于多分支拓扑结构有着推理上的缺点但是分支似乎对训练有利,我们使用多个分支来制作众多模型的唯一训练时间集合。为了使大多数成员更浅或更简单,我们使用类似于ResNet的实体(仅在尺寸匹配时)和1×1分支,以便构建块的训练时信息流为y = x + g(x)+ f(x)。我们简单地堆叠几个这样的块来构建训练时间模型。从与[35]相同的角度来看,模型成为具有n个这样的块的3 ^ n个成员的集合。训练后,将其等效转换为y = h(x),其中h由单个conv层实现,并且其参数是通过一系列代数运算从训练后的参数中得出的。
3.3 普通的推理模型的重新化参数
(以下两段鉴于公式原因直接截图了)


上面的变换也适用于实体分支,因为身份映射可以视为以实体矩阵为内核的1×1 conv。经过这样的转换,我们将有一个3×3内核,两个1×1内核和三个偏置向量。然后,我们通过将三个偏差向量相加来获得最终偏差,并通过将1×1内核与3×3内核的中心点相加来获得最终3×3内核,这可以通过首先对两个1×1内核进行零填充转换为3×3内核,然后将三个内核相加轻松,如fig.4所示。请注意,此类转换的等效性要求3×3和1×1层具有相同的步幅,并且填充配置为后者应比前者少一个像素。例如,对于3×3的图层,将输入填充一个像素(这是最常见的情况),则1×1的图层应具有padding = 0。
3.4 架构特殊化

Table.2. RepVGG的架构具体化。例如,2x64a意味着阶段2有两层,每层有64a个channel.
Table.2显示了RepVGG的具体,包括深度和宽度。 RepVGG是VGG风格的,在某种意义上它采用简单的拓扑并大量使用3×3 conv,但是它不像VGG那样使用max pooling,因为我们希望主体仅具有一种类型的操作。我们将3×3层安排进5个阶段,阶段的第一层向下采样,步幅=2。对于图像分类,我们使用全局平均池化,然后使用完全连接的层作为头部。对于其他任务,可以在任何层产生的特征上使用特定于任务的头。
我们遵循三个简单的准则来决定每个阶段的层数。 1)第一阶段以高分辨率运行,这很耗时,因此我们仅使用一层来降低延迟。 2)最后一级应具有更多通道,因此我们仅使用一层来保存参数。 3)我们将最多的图层放到倒数第二个阶段(在ImageNet上具有14×14的输出分辨率),紧随ResNet及其最新版本10、27、37(例如,ResNet-101在其14×14分辨率阶段使用69层)。 我们让这五个阶段分别具有1、2、4、14、1层,构造出一个名为RepVGG-A的实例。 我们还构建了更深的RepVGG-B,在stage2、3和4中各增加了2层。我们使用RepVGG-A与其他轻量级和中等重量的模型(包括ResNet-18 / 34/50和RepVGG-B)比较,使用RepVGG-B与其他高性能的模型比较。
我们通过均匀缩放[64、128、256、512]的经典宽度设置(例如VGG和ResNets)来确定图层宽度。 我们使用乘数a来缩放前四个阶段,使用b来缩放最后一个阶段,通常设置b> a,因为我们希望最后一层对分类或其他下游任务具有更丰富的功能。由于RepVGG在最后阶段只有一层,因此较大的b不会显着增加等待时间或参数数量。 具体而言,stage2、3、4、5的宽度为[64a,128a,256a,512b]。
为了避免在大特征图上进行大卷积,如果a <1,我们将减小stage1的大小,但不对其进行放大,以使stage1的宽度为min(64,64a)。
为了进一步减少参数和计算量,我们可以选择将按行排列的3×3 conv层与密集的层进行交织,以牺牲精度来提高效率。 具体来说,我们为RepVGG-A的第3、5、7,…,21层以及RepVGG-B的第23、25和27层设置组数g。为简单起见,我们将此类层的g全局设置为1、2或4,而无需逐层调整。我们不使用相邻逐层的conv层,因为那样会禁用通道间信息交换并带来副作用[40]:某个通道的输出只能从一小部分输入通道中得出。请注意,1×1分支应具有与3×3 conv相同的g。
4. 实验
在本节中,我们将RepVGG的性能与ImageNet上的基线进行比较,通过一系列消融研究和比较证明结构性重新参数化的重要性,并验证RepVGG在语义分割上的泛化性能[41]。
4.1 RepVGG用于图像分类网络

Table.3. 由乘数a和b定义的RepVGG模型
我们在1k的Inage-Net上将RepVGG与经典和最先进的模型进行比较,其中包括ImageNet1K [5]上的VGG-16 [30],ResNet [10],ResNeXt [37],EfficientNet [34]和RegNet [27],其中包括1.28 用于训练的M张高分辨率图像,1000类别的50K验证图像。我们分别使用EfficientNet-B0 / B3和RegNet-3.2GF / 12GF作为中量级和重量级最新技术模型的代表。我们改变乘数a和b来生成一系列RepVGG模型以与基线进行比较。如Table.3中总结。
我们首先将RepVGG与最常用的基准ResNets [10]进行比较。 为了与ResNet-18进行比较,我们为RepVGG-A0设置a = 0.75,b = 2.5。对于ResNet-34,我们使用更宽的RepVGG-A1。为了使RepVGG的参数比ResNet-50略少,我们构建RepVGG-A2的a = 1.5,b = 2.75。为了与更大的模型进行比较,我们构造了宽度增加的更深的RepVGG B0 / B1 / B2 / B3。 对于那些具有交错的分组层的RepVGG模型,我们将g2 / g4附加到模型名称作为后缀。
为了训练轻量级和中量级模型,我们仅使用简单的数据增强管道,包括随机裁剪(random cropping)和左右翻转(left-right flipping),遵循官方的PyTorch示例26。我们在8个GPU上使用256的全局批处理大小,将学习率初始化为0.1,并进行120个epoch的余弦退火,标准SGD的动量系数为0.9,并且在conv和完全连接层的内核上设置权重衰减为10^-4。对于包括RegNetX-12GF,EfficientNet-B3和RepVGG-B3在内的重量级模型,我们使用5-epoch预热,余弦学习率退火200个epoch,标签平滑33和混合39(以下[11]),以及一个自动增强(Autoaugment) [4],随机裁剪和翻转的数据增强管道。 RepVGG-B2及其g2 / g4变体在这两种设置中都经过训练。我们测试每个模型的速度,批处理大小为128,在1080Ti GPU 上,首先喂入50个batch以预热硬件,然后记录50个batch并记录时间使用情况。为了公平地比较,我们在同一GPU上测试所有模型,并且所有基线的conv-BN序列也都转换为带偏差的conv(等式3)。
在Table.4和fig.1中,RepVGG显示出良好的精度-速度折衷。例如,就准确性和速度而言,RepVGG-A0比ResNet-18好1.25%和33%,RepVGG-A1比ResNet34好0.29%/ 64%,RepVGG-A2比ResNet-50好0.17%/ 83%。通过逐层交错(g2 / g4),可以通过牺牲精度进一步加速RepVGG模型。例如RepVGG-B1g4比ResNet-101好0.37%/ 101%,而RepVGG-B1g2则以与ResNet-152相同的精度达到其2.66倍的速度。尽管参数数量不是我们主要关注的,以上所有RepVGG模型都比ResNets具有更高的参数效率。与经典的VGG-16相比,RepVGGB2仅具有58%的参数,但运行速度快10%,精度高6.57%。与用RePr [25](一种基于修剪的精心设计的训练方法)训练的VGG模型(据我们所知,它是精度最高(74.5%)的类VGG模型)相比,RepVGG-B2的准确度超出其4.28%。
与最先进的基线相比,RepVGG考虑到其简单性也显示出良好的性能:RepVGG-A2比EfficientNetB0好1.37%/ 59%,RepVGG-B1比RegNetX3.2GF好0.39%,并且运行速度稍快 。
值得注意的是,RepVGG模型经过200个epoch达到了80%以上的精度(表5),这是普通模型首次据我们所知赶上最新技术。与RegNetX-12GF相比,RepVGGB3的运行速度提高了31%,考虑到RepVGG不需要像RegNet [27]那样的大量人力来完善设计空间,并且架构超参数是随便设置的,因此这令人印象深刻。
作为计算复杂性的两个代理,我们计算了2.4部分中介绍的理论FLOP和Wino MULs。例如,我们发现Winograd算法不会加速EfficientNet-B0 / B3中的conv。Table.4显示Wino MUL在GPU上是更好的代理,例如ResNet-152的运行速度比VGG-16慢,理论FLOP较低,但Wino MUL较高。当然,实际速度应始终是黄金标准。
4.2 结构性的重新化参数是关键

Table.6. 在ImageNet上经过120个epoch的消融实验

Table.7. 在训练了120个epoch的RepVGG-B0上与变体和基线进行比较
在本小节中,我们验证了结构性重新参数化技术的重要性(Table. 6)。 使用上述相同的简单训练设置,从头开始训练所有模型120个epoch。 首先,我们通过从RepVGG-B0的每个块中删除实体和/或1×1分支来进行消融研究。删除全部分支后,训练时间模型会降级为简单的普通模型,并且只能达到72.39%的准确性。1x1分支精度提高到73.15%,实体的精度提高到74.79%。全功能RepVGG-B0的精度为75.14%,比一般的普通模型高2.75%。
• Identity w/o BN 删除了实体分支中的BN。
• Post-addition BN 会删除三个分支中的BN层,并在添加后附加一个BN层。即,将BN的位置由前添加更改为后添加。
• +ReLU in branches 将ReLU插入每个分支中(在BN之后,添加之前). 由于无法将这样的块转换为单个conv层,因此没有实际用途,我们仅希望了解更多的非线性是否会带来更高的性能。
• DiracNet [38] 采用了经过精心设计的conv内核重新参数化,如2.2中所述。 2.2。我们使用其官方PyTorch代码构建图层以替换原始的3×3 conv。
• Trivial Re-param 是通过将实体内核直接添加到3×3内核中来对conv内核进行更简单的重新参数化,可以将其视为DiracNet的降级版本(W’ = I + W [38])。
• Asymmetric Conv Block (ACB) [9] 可以看作是结构性重新参数化的另一种形式。我们将其与ACB进行比较,以查看结构性重新参数化的改进是否归因于组件级的超参数化(即额外的参数使每3×3 conv更强)。
• Residual Reorg 通过以类似于ResNet的方式重新组织每个阶段(每个块2层)。具体而言,生成的模型在第一和最后一个阶段具有一个3×3层,在stage2、3、4中具有2、3、8个残差块,并且使用类似于ResNet-18 / 34的快捷方式。
我们认为结构重参数优于DiractNet和琐碎重参数的事实在于,前者依赖于通过具有非线性行为(BN)的具体结构的实际数据流,而后者仅使用了conv核的另一种数学表达式。即,前者“重新参数化”的意思是“使用一个结构的参数来参数化另一个结构”,而后者的意思是“首先使用另一组参数计算参数,然后将其用于其他计算”。 对于训练时间BN等非线性分量,前者无法近似。有证据表明,通过去除BN会降低准确性,而通过添加ReLU会提高准确性。换句话说,尽管可以将RepVGG块等效地转换为单个conv进行推理,但是推理时间等价并不意味着训练时间等价,因为我们无法构造一个conv层使其具有与RepVGG块相同的训练时间行为。
与ACB的比较表明,RepVGG的成功不应仅仅归因于每个组件的过度参数化,因为ACB使用更多的参数,但不能像RepVGG一样提高性能。仔细再检查一下,我们将ResNet-50的每3×3 conv转换用一个RepVGG块替换,并从头开始训练120个epoch。准确性为76.34%,仅比ResNet50基线高0.03%,这表明RepVGG风格的结构性重新参数化不是通用的过度参数化技术,而是对训练功能强大的普通ConvNets至关重要的方法。
与残差重组(residual reorg)相比,一个具有相同数量的3×3 conv和额外的捷径的真实残差网络,在训练和推理方面,RepVGG的表现高出0.58%,这并不奇怪,因为RepVGG的分支结构要多得多。 例如,分支使RepVGG的stage4成为2×3 ^ 15 = 2.8×10 ^ 7个模型的整体[35],而残差重组的数目为2 ^ 8 = 256。
4.3 语义分割

Table.8. 在验证子集上对Cityscapes [3]上的语义分割进行了测试。 在同一1080Ti GPU上以批处理大小16,全精度(fp32)和输入分辨率713×713测试了速度(单位示例/秒)。
我们验证了ImageNet预训练的RepVGG在Cityscapes [3]上的语义分割的泛化性能,其中包含5K精细注释的图像和19个类别。 我们使用PSPNet [41]框架,一个以0.01为底,功效为0.9,重量衰减为10 ^ −4且全局批次大小为16的多学习率策略。在8个GPU上训练了40个epoch。为了公平起见,我们仅将ResNet-50 / 101主干更改为RepVGG-B1g2 / B2,保持其他设置相同。
继正式实现PSPNet-50 / 101 [41],即在ResNet-50 / 101的后两个阶段中使用膨胀的conv,我们还将RepVGG-B1g2 /的后两个阶段中的所有3×3 conv层B2扩张了。由于目前效率不高的3 x 3扩张conv(尽管FLOP与3 x 3常规conv相同),这样的修改会减慢推理速度。为了便于比较,我们构建了另外两个(Table.8中用fast表示)仅在最后5层(即stage4的最后4层和stage5的唯一层)上进行扩张的PSPNet,以便于PSPNet比相当的ResNet-50 / 101骨干网快一点。结果表明,RepVGG主干网的性能比ResNet-50和ResNet-101分别高出1.71%和1.01%,在平均IoU情况下有着更高的速度。令人印象深刻的是,RepVGG-B1g2-fast在mIoU中比ResNet101主干网高0.37,运行速度快62%。有趣的是,对于较大的模型,扩张似乎更有效,因为与RepVGG-B1g2-fast相比,使用更多扩张的conv层不会提高性能,但会因合理地慢下来将RepVGG-B2的mIoU提高1.05%。
4.4 局限
RepVGG模型是快速,简单和实用的ConvNet,旨在在GPU和专用硬件上以最快的速度运行,而无需考虑参数或理论FLOP的数量。 尽管RepVGG模型比ResNets更具参数效率,但对于低功耗设备,它们可能不如MobileNets [14、29、13]和ShuffleNets [40、23]这样的移动方式模型受青睐。
5. 结论
我们提出了RepVGG,这是一个由3×3 conv和ReLU构成的简单架构,这使其特别适合于GPU和专用推理芯片。通过我们的结构性重新参数化方法,如此简单的ConvNet在ImageNet上达到了80%的精确度第一,和与最先进的复杂模型相比,它显示出优良的速度精度折衷。
References
[1] Sharan Chetlur, Cliff Woolley, Philippe Vandermersch,Jonathan Cohen, John Tran, Bryan Catanzaro, and Evan Shelhamer. cudnn: Efficient primitives for deep learning.
arXiv preprint arXiv:1410.0759, 2014. 3
[2] Franc¸ois Chollet. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1251–1258, 2017. 1
[3] Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The cityscapes dataset for semantic urban scene understanding. In 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, June 27-30, 2016,pages 3213–3223. IEEE Computer Society, 2016. 8
[4] Ekin D Cubuk, Barret Zoph, Dandelion Mane, Vijay Vasudevan, and Quoc V Le. Autoaugment: Learning augmentation strategies from data. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 113–123,2019. 6, 7
[5] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li,and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In Computer Vision and Pattern Recognition,2009. CVPR 2009. IEEE Conference on, pages 248–255. IEEE, 2009. 6
[6] Xiaohan Ding, Guiguang Ding, Yuchen Guo, and Jungong Han. Centripetal sgd for pruning very deep convolutional networks with complicated structure. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4943–4953, 2019. 4
[7] Xiaohan Ding, Guiguang Ding, Yuchen Guo, Jungong Han,and Chenggang Yan. Approximated oracle filter pruning for destructive cnn width optimization. In International Conference on Machine Learning, pages 1607–1616, 2019. 4
[8] Xiaohan Ding, Guiguang Ding, Jungong Han, and Sheng Tang. Auto-balanced filter pruning for efficient convolutional neural networks. In Thirty-Second AAAI Conference on Artificial Intelligence, 2018. 4
[9] Xiaohan Ding, Yuchen Guo, Guiguang Ding, and Jungong Han. Acnet: Strengthening the kernel skeletons for powerful cnn via asymmetric convolution blocks. In Proceedings of the IEEE International Conference on Computer Vision,pages 1911–1920, 2019. 3, 7, 8
[10] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun.Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 1, 2, 5, 6
[11] Tong He, Zhi Zhang, Hang Zhang, Zhongyue Zhang, Junyuan Xie, and Mu Li. Bag of tricks for image classification with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 558–567, 2019. 6
[12] Yihui He, Xiangyu Zhang, and Jian Sun. Channel pruning for accelerating very deep neural networks. In International Conference on Computer Vision (ICCV), volume 2, page 6,2017. 4
[13] Andrew Howard, Ruoming Pang, Hartwig Adam, Quoc V.Le, Mark Sandler, Bo Chen, Weijun Wang, Liang-Chieh Chen, Mingxing Tan, Grace Chu, Vijay Vasudevan, and Yukun Zhu. Searching for mobilenetv3. In 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019,Seoul, Korea (South), October 27 - November 2, 2019, pages 1314–1324. IEEE, 2019. 9
[14] Andrew G Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, and Hartwig Adam. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861, 2017. 1, 9
[15] Gao Huang, Zhuang Liu, Laurens van der Maaten, and Kilian Q. Weinberger. Densely connected convolutional networks. In 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017, pages 2261–2269. IEEE Computer Society, 2017. 1, 2
[16] Intel. Intel mkl. https://software.intel.com/content / www / us / en / develop / tools / math -kernel-library.html, 2020. 3
[17] Sergey Ioffe and Christian Szegedy. Batch normalization:Accelerating deep network training by reducing internal covariate shift. In International Conference on Machine Learning, pages 448–456, 2015. 1, 2, 4
[18] Andrew Lavin and Scott Gray. Fast algorithms for convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4013–4021, 2016. 3 [19] Yann LeCun, Leon Bottou, Yoshua Bengio, and Patrick ´Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, 1998.3
[20] Hao Li, Asim Kadav, Igor Durdanovic, Hanan Samet, and Hans Peter Graf. Pruning filters for efficient convnets. arXiv preprint arXiv:1608.08710, 2016. 4
[21] Tsung-Yi Lin, Priya Goyal, Ross B. Girshick, Kaiming He, and Piotr Dollar. Focal loss for dense object detection. In ´IEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, October 22-29, 2017, pages 2999–3007.IEEE Computer Society, 2017.
[22] Chenxi Liu, Barret Zoph, Maxim Neumann, Jonathon Shlens, Wei Hua, Li-Jia Li, Li Fei-Fei, Alan Yuille, Jonathan Huang, and Kevin Murphy. Progressive neural architecture search. In Proceedings of the European Conference on Computer Vision (ECCV), pages 19–34, 2018. 1, 2
[23] Ningning Ma, Xiangyu Zhang, Hai-Tao Zheng, and Jian Sun.Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European conference on computer vision (ECCV), pages 116–131, 2018. 1, 3, 4, 9
[24] Oyebade K Oyedotun, Djamila Aouada, Bjorn Ottersten, ¨et al. Going deeper with neural networks without skip connections. In 2020 IEEE International Conference on Image Processing (ICIP), pages 1756–1760. IEEE, 2020. 3
[25] Aaditya Prakash, James A. Storer, Dinei A. F. Florencio, and ˆCha Zhang. Repr: Improved training of convolutional filters. In IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019, pages 10666–10675. Computer Vision Foundation/ IEEE, 2019. 7
[26] PyTorch. Pytorch example. https://github.com/pytorch / examples / blob / master / imagenet /main.py, 2019. 6
[27] Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick,Kaiming He, and Piotr Dollar. Designing network design ´spaces. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10428–10436, 2020. 1, 2, 5, 6, 7
[28] Esteban Real, Alok Aggarwal, Yanping Huang, and Quoc V Le. Regularized evolution for image classifier architecture search. In Proceedings of the aaai conference on artificial intelligence, volume 33, pages 4780–4789, 2019. 1, 2
[29] Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4510–4520, 2018. 1, 9
[30] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014. 1, 2, 6
[31] Christian Szegedy, Sergey Ioffe, Vincent Vanhoucke, and Alexander A Alemi. Inception-v4, inception-resnet and the impact of residual connections on learning. In Thirty-first AAAI conference on artificial intelligence, 2017. 1, 2
[32] Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet,Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1–9, 2015.1, 2
[33] Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages2818–2826, 2016. 1, 2, 6
[34] Mingxing Tan and Quoc V Le. Efficientnet: Rethinking model scaling for convolutional neural networks. arXiv preprint arXiv:1905.11946, 2019. 1, 2, 3, 6
[35] Andreas Veit, Michael J Wilber, and Serge Belongie. Residual networks behave like ensembles of relatively shallow networks. In Advances in neural information processing systems, pages 550–558, 2016. 2, 4, 8
[36] Lechao Xiao, Yasaman Bahri, Jascha Sohl-Dickstein,Samuel Schoenholz, and Jeffrey Pennington. Dynamical isometry and a mean field theory of cnns: How to train
10,000-layer vanilla convolutional neural networks. In International Conference on Machine Learning, pages 5393–5402, 2018. 3
[37] Saining Xie, Ross Girshick, Piotr Dollar, Zhuowen Tu, and ´Kaiming He. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1492–1500,2017. 5, 6
[38] Sergey Zagoruyko and Nikos Komodakis. Diracnets: Training very deep neural networks without skip-connections.arXiv preprint arXiv:1706.00388, 2017. 3, 7, 8
[39] Hongyi Zhang, Moustapha Cisse, Yann N Dauphin, and David Lopez-Paz. mixup: Beyond empirical risk minimization. arXiv preprint arXiv:1710.09412, 2017. 6
[40] Xiangyu Zhang, Xinyu Zhou, Mengxiao Lin, and Jian Sun.Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 6848–6856, 2018. 1, 6, 9
[41] Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, Xiaogang Wang, and Jiaya Jia. Pyramid scene parsing network. In 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017,pages 6230–6239. IEEE Computer Society, 2017. 6, 8
[42] Barret Zoph and Quoc V Le. Neural architecture search with reinforcement learning. arXiv preprint arXiv:1611.01578,2016. 4
[43] Barret Zoph, Vijay Vasudevan, Jonathon Shlens, and Quoc V Le. Learning transferable architectures for scalable image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 8697–8710, 2018. 1, 2