Spatial-Spectral Transformer for Hyperspectral Image Classification_外文翻译
笔者在毕设期间翻译了此论文。
Spatial-Spectral Transformer for Hyperspectral Image Classification_外文翻译
- 摘要
- 关键字
- 1.前言
- 2.用于高光谱图像分类的空间-光谱变换器
-
- 2.1基于CNN的HSI空间特征提取
- 2.2用于HSI分类的光谱空间转换器
- 2.3动态特征增强
- 3.用于高光谱图像分类的异质传输空间-光谱变换器
-
- 3.1.两个数据集的异质性映射
- 3.2.建议用于HSI分类的T-SST
- 3.3.建议用于HSI分类的T-SST-L
- 4.实验结果
-
- 4.1.高光谱数据集
- 4.2.训练详情
- 4.3.参数分析
- 4.4.SST和SST-FA在HSI分类中的分类结果
- 4.5.拟议的用于HSI分类的T-SST和T-SST-L的分类结果
- 4.6.拟议的T-SST的变压器编码器表示法的分析
- 4.7.分类地图
- 4.8.时间消耗
- 5.结论
摘要
最近,已经提出了许多基于深度卷积神经网络(CNN)的方法用于高光谱图像(HSI)分类。尽管提出的基于CNN的方法具有空间特征提取的优点,但它们难以处理序列数据,并且CNN不擅长对远程依赖关系进行建模。然而,HSI的光谱是一种序列数据,HSI通常包含数百个波段。因此,CNN很难很好地处理HSI处理。另一方面,基于注意力机制的Transformer模型已经证明了其在处理序列数据方面的优势。为了解决远距离捕获HSI序列光谱关系的问题,在本研究中,研究了Transformer用于HSI分类。具体而言,在本研究中,提出了一种新的分类框架,名为空间光谱变换器(SST),用于HSI分类。在提出的SST中,使用设计良好的CNN来提取空间特征,并提出改进的Transformer(具有密集连接的Transformer,即DenseTransformer)来捕获序列谱关系,并使用多层感知器完成最终的分类任务。此外,提出了动态特征增强,旨在缓解过拟合问题,从而很好地泛化模型,并将其添加到SST(SST-FA)中。此外,针对HSI分类中训练样本有限的问题,将迁移学习与SST相结合,提出了另一种分类框架Transfer-SST(T-SST)。最后,为了缓解过拟合问题并提高分类精度,为基于T-SST的分类框架(T-SST-L)引入了标签平滑。建议的SST、SST-FA、TSST和T-SST-L在三个广泛使用的高光谱数据集上进行了测试。获得的结果表明,与最先进的方法相比,所提出的模型提供了具有竞争力的结果,这表明Transformer的概念为HSI分类打开了一个新窗口。
关键字
分类;卷积神经网络(CNN);高光谱图像(HSI);变压器
1.前言
由于成像光谱学的进步,高光谱传感器倾向于以越来越高的空间和光谱分辨率捕获给定场景的反射强度[1]。获得的高光谱图像(HSI)同时包含空间特征和不同物体的连续诊断光谱[2]。因此,获得的丰富信息使HSI在许多领域有用,包括有效测量农业绩效[3]、植物病害检测[4]、矿物鉴定[5]、疾病诊断和图像引导手术[6]、生态系统测量[7],和地球监测[8]。为了充分利用获得的HSI,已经探索了许多数据处理技术,例如解混合、检测和分类[8]。HSI分类旨在对场景中每个像素的内容进行分类[9],这是应用中的基本程序,例如在地球监测中识别土地覆盖类别的类型[10]。
在过去的二十年中,已经提出了许多用于HSI分类的监督方法[11]。在HSI分类的早期阶段,HSI分类方法仅使用光谱信息。[12]中介绍了一个典型的光谱分类器,它基于支持向量机(SVM)。SVM表现出对高维的低敏感性[13];因此,已经提出了许多基于SVM的分类器来处理HSI[14]的光谱分类。随着成像技术的发展,高光谱传感器可以提供丰富的观测场景空间信息。开发光谱空间分类器是合理的。已经开发了许多形态学操作来提取HSI的空间特征以进行空间光谱分类,例如形态剖面(MP)[15]、扩展MP(EMP)[16]、扩展多属性剖面(EMAP)[17]和消光曲线(EP)[18]。然而,上述HSI分类器并不是深度模型[11]。
近年来,深度学习技术,特别是深度卷积神经网络(CNN),彻底改变了遥感数据处理的手段。恒指分类任务也不例外。在[19]中,引入了堆叠自动编码器作为HSI特征提取和分类的深度模型。之后,一些深度学习模型,如深度信念网络[20]、CNN[21,22]、循环神经网络[23,24]、生成对抗网络[25,26]和胶囊网络[27,28]对HSI分类进行了研究,并获得了良好的分类性能。
由于其局部连接和共享权重,这使得它可以有效地捕获局部相关性,CNN对于图像处理非常有用,包括HSI分类。根据模型的输入信息,基于CNN的HSI分类方法可以分为三种类型:光谱CNN、空间CNN和光谱-空间CNN。基于光谱CNN的HSI分类接收像素向量作为输入,并使用CNN仅在光谱域中对HSI进行分类。例如,胡等人。提出了具有五个卷积层的一维CNN来提取HSI[29]的光谱特征。此外,[30]中提出了一项有趣的工作,该工作使用CNN提取像素对特征进行HSI分类,并获得了良好的分类性能。
基于空间CNN的方法是第二种基于CNN的HSI分类方法。得到的HSI除了光谱信息外,还包含丰富的空间信息;因此,使用空间CNN(2-DCNN)来提取HSI的空间特征是合理的。大多数现有的基于空间CNN的HSI分类方法都是在一个或几个主成分上进行的。例如,在[31]中,属于他的第一个主成分的以像素为中心的邻居的裁剪空间补丁被用于训练用于HSI分类的2-DCNN。
基于光谱-空间CNN的方法是第三种基于CNN的HSI分类方法,旨在在统一的框架中联合利用光谱和空间HSI特征。由于HSI的输入是三次张量,因此3-D卷积用于HSI分类[32]。例如,在[33]中,He等人。提出了一种3D深度CNN,通过计算多尺度特征来联合提取空间和光谱特征。在[34]中,3-D卷积层和批归一化层分别用于提取光谱空间信息和正则化模型。由于基于CNN的方法获得了良好的分类性能,近年来CNN已成为HSI分类的事实标准。
现有的用于HSI分类的CNN模型已经达到了最先进的性能;但是,仍然存在一些限制。首先,输入HSI的一些信息被忽略了,并且在基于CNN的方法中没有得到很好的探索。CNN是一种基于向量的方法,它将输入视为像素向量的集合[35]。对于HSI,它本质上在谱域中具有基于序列的数据结构。因此,在处理高光谱像素向量时,使用CNN会导致信息丢失[36]。其次,学习带的远距离位置之间来回的远程顺序依赖是困难的。由于卷积运算处理的是局部邻域,因此CNN的感受野受到其内核大小和层数的严格限制,这使得它在捕获输入数据的远程依赖关系方面不太有利[37]。因此,很难学习HSI的长程依赖性,通常包含数百个光谱带。
最近,已经提出了一种名为Transformer[38]的模型,它基于自注意力机制[39],用于自然语言处理。Transformer使用注意力在输入序列中绘制全局依赖关系。对于包括Transformer在内的深度学习模型,存在梯度消失的常见问题,这阻碍了训练过程中的收敛[40]。为了缓解梯度消失问题,本研究提出了一种新型的Transformer,它使用密集连接来加强特征传播,名为DenseTransformer。
此外,针对HSI分类提出了两个基于DenseTransformer的分类框架。第一个分类框架结合了CNN、DenseTransformer和多层感知器。在第二个分类框架中,迁移学习策略与Transformer相结合,以有限的训练样本提高HSI分类性能。
本研究的主要贡献总结如下:
1)提出了一种名为DenseTransformer的改进型Transformer,它使用密集连接来缓解Transformer中的梯度消失问题。
2)针对HSI分类提出了一种新的分类框架,即空间光谱变换器(SST),它结合了CNN、DenseTransformer和多层感知器(MLP)。在提出的SST中,使用精心设计的CNN提取HSI的空间特征,提出的DenseTransformer用于捕获HSI的序列光谱关系,并使用MLP完成分类任务。
3)此外,提出了旨在缓解过拟合问题并因此很好地泛化模型的动态特征增强,并将其添加到SST中以形成新的HSI分类方法(即SST-FA)。
4)提出了另一种新的分类框架,即转移空间-光谱变换器(T-SST),以进一步提高HSI分类的性能。所提出的T-SST在大型数据集上使用预训练的VGG-like模型作为SST中使用的CNN的初始化;因此,它通过有限的训练样本提高了HSI分类的准确性。
5)最后,将标签平滑引入到基于Transformer的分类中。标签平滑与T-SST相结合,形成了一种名为TSST-L的新HSI分类方法。
本文的其余部分安排如下。为HSI分类提出的SST和转移SST分别在第II节和第III节中介绍。第四节报告了实验结果和讨论。第五节介绍了本研究的结论。
2.用于高光谱图像分类的空间-光谱变换器
Spatial-SpectralTransformerforHyperspectralImageClassification提出的用于HSI分类的SST框架如图1所示。总的来说,分类方法分为三个部分:基于CNN的空间特征提取、基于改进的Transformer的空间-光谱特征提取和基于MLP的分类。
首先,对于HSI的每个波段,选择包含待分类像素的相邻像素的2D补丁作为输入。训练样本有(即HSI的波段数)补丁。之后,使用精心设计的CNN来提取每个2D补丁的特征,然后将提取的特征发送到Transformer。然后,使用修改后的Transformer获得序列空间特征的关系。最后,利用得到的空间光谱特征得到分类结果。
2.1基于CNN的HSI空间特征提取
CNN具有强大的图像空间特征提取能力,广泛用于图像分类、检测、分割等图像处理。对于HSI,它包含丰富的空间信息。本研究使用CNN来有效提取HSI的空间特征。
CNN包含各种不同的架构。如何选择合适的架构很重要。虽然HSI是一个3-D立方体,但本研究中没有使用3-DCNN。相反,在这个分类框架中使用了2-DCNN。此外,我们分别使用2-DCNN来提取his中每个波段的特征,并将提取的特征输入到Transformer中。VGGNet是一个简单但有效的模型,它考虑了适当层的深度,并且与之前的AlexNet[41]相比不会增加参数的总数。因此,我们使用了类似VGG的架构。原始VGG包含16层,其中包括13个卷积层和3个全连接层。每个卷积层后面是BN层和ReLU操作,在第2、4、7、10、13个卷积层之后增加了maxpooling层。可能,整个16层的使用并不是HSI空间特征提取的好选择。如何设计合适的CNN架构是成功HSI分类器的关键。在实验部分,我们设计了一个类似VGG的深度CNN,用于HSI的空间特征提取。
2.2用于HSI分类的光谱空间转换器
CNN使用本地连接来提取输入的相邻特征。恒指通常包含数百个波段;因此,CNN很难获得远距离的光谱关系。自注意力机制可以获得每两个波段的关系。例如,机载可见光/红外成像光谱仪(AVIRIS)包含224个波段。使用self-attention,通过学习过程可以得到一个形状为224×224的矩阵。矩阵中的每个元素代表两个波段之间的关系。如图1所示,上一部分CNN提取的特征然后被送Transformer学习长程依赖,主要包含三个元素。
第一个元素称为位置嵌入,旨在捕获不同波段的位置信息。这个元素修改了最后一部分的输出特征,这取决于它的位置而不改变这些完整的特征。在本文中,利用一维位置嵌入,将输入特征视为不同波段的序列。这些生成的位置嵌入被添加到特征中,然后一起发送到下一个元素。此外,还准备了一个可学习的位置嵌入(即数字零),其状态用作波段的整个表示。这种可学习的位置嵌入与第三部分相结合来完成分类任务。
第二个元素是Transformer编码器,它是我们模型的核心部分。
Transformer编码器总共包含个编码器块,每个编码器块由一个多头注意力和一个MLP层组成,再加上层归一化和残差连接。在每个编码器块中,在每个多头注意力和一个MLP层之前添加一个归一化层,并在每个多头注意力和MLP层之后设计残差连接。让我们用B∈R^(n×d"model" ) “来表示恒生指数” (b_1,b_2,⋯b_n )的n带的数量,其中的编码来捕捉HSI所有n频段之间的互动。具体来说,我们定义丁三个可学习的权重矩阵包括查询(即Q)、键(即K)和值(即V),维度为d_k。应用点积来计算所有键的查询然后用softmax函数来计算值的权重。注意力的输出被定义如下。

其中d_k是K的尺寸。用不同的和学习过的投影对查询、键和值进行多次投影(即h次)是有益的,然后将这些结果串联起来。这个过程被称为多头关注。这些平行计算的每个结果都被称为头。
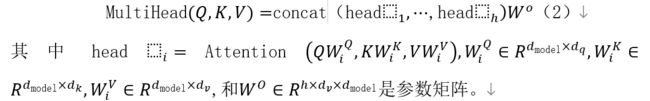
之后,由多头关注机制提取的权重被送到MLP层,其输出特征为512维。这里,MLP由两个全连接层构成,其间有一个名为高斯误差线性单元(GELU)的非线性激活。这里,GELU是ReLU的变体,可以定义如下[42]。

在MLP层之前,总是有一个归一化层[43],它不仅通过归一化神经元减少了训练时间,而且还缓解了梯度消失或爆炸的问题。对于第层的第a_i^l求和输入,归一化层表示如下:

别表示学习的尺度参数和移位参数。其中是归一化求和输入,和分别表示第层的期望和方差。和分别表示学习的比例参数和移位参数。对于深度学习模型,存在用来形成一个DenseTransformer。特别地,DenseTransformer中的每一层都与DenseTransformer中的前几层相连接。对于一个传统的TransformerH_L (.)在第层的连接,而DenseTransformer有(L(L+1))/2连接。这个DenseTransformer鼓励特征重用,因此减轻了消失梯度问题。图2显示了当=3时建议的DenseTransformer。提出的DenseTransformer由层组成,考虑到单个e_L表示传统TransformerH_L (.),在第层的输出。因此,所提出的DenseTransformer的第层接收之前的层产生的权重e_0,e_1,⋯,e_(L-1),可以定义如下:

SST的第三部分是MLP。MLP的体系结构包括具有GELU操作的两个完全连接层,其中最后一个完全连接层(即Softmax层)旨在生成用于HSI分类的最终结果。在SoftMAX中,对于输入向量R,可以如下估计输入属于类别i的概率:

其中W和b分别是SoftMAX层的权重和偏差。在MLP中,输入层的大小被设置为与变压器的输出层的大小相同,并且输出层的大小被设置为与类的总数相同。Softmax确保每个输出单元的激活和为1。因此,可以将输出视为一组条件概率。
2.3动态特征增强
由于所提出的,SST往往容易被过度拟合,因此需要适当的正则化来实现良好的泛化。在本小节中,我们提出了一种简单的正则化技术,即动态特征增强技术,它是通过在训练过程中快速掩盖特征而实现的。然后,SST与特征增强相结合,形成一个新的HSI分类器(即SST-FA),它提高了SST的鲁棒性和总体分类性能。特别是,由VGG提取的空间特征的维度很高(即512-维),这对于Transformer模型来说很容易过度拟合。这里,首先在特征中随机选择一个坐标,然后,在坐标周围放置一个掩码,决定有多少特征被设置为零。请注意,这个坐标是动态变化的,在训练过程中,通过对历时性的分析,可以确保Transformer模型得到不同的图像。所提出的SST-FA不仅易于实现,而且能够进一步提高变形器模型的性能。
3.用于高光谱图像分类的异质传输空间-光谱变换器
训练样本的收集不仅是昂贵的,而且是耗时的。因此,有限的训练样本是HSI分类中的一个普遍问题。为了解决这个问题,本研究将转移学习与SST相结合。转移学习是一种从源域提取知识并将其转移到目标域的技术[44]。例如,在基于CNN的迁移学习中,源域的学习权重可以用来初始化目标域的网络。因此,如果使用得当,在训练样本数量有限的情况下,转移学习可以提高目标任务的分类性能。为了进一步提高拟议的SST的分类性能,本节提出了转移SST(T-SST)。图3显示了拟议的用于HSI分类的T-SST框架。一般来说,分类方法有三个部分:基于CNN的空间特征提取,基于Transformer的空间光谱特征提取,以及基于MLP的分类。
3.1.两个数据集的异质性映射
由于大规模数据集(即源数据集)有三个通道,但HSI(即目标数据集)包含数百个通道,因此简单地使用转移学习进行HSI分类存在一个问题。为了解决异质转移学习引起的问题,使用了一个映射层来处理两个数据集的不同通道数(即波段数)的问题。在大规模ImageNet数据集上的预训练模型有三个输入通道(即RGB),但T-SST中的CNN接收一个波段的输入。

在异质映射中,有三个可学习的参数。映射操作与后续的CNN相结合,形成一个端到端的学习系统。
3.2.建议用于HSI分类的T-SST
迁移学习是一种旨在从源领域提取知识并将其应用于目标领域的技术[44]。从源任务中学习的知识被用来提高目标任务的性能。在基于深度学习的迁移学习中,深度模型可以从ImageNet这样的大型数据集中学习大量的知识,而学到的知识可以转移到新的任务中,如HSI分类。因此,适当使用迁移学习可以减少必要的训练样本数量。许多先前的研究证明,在原始领域的CNN中学习到的权重可以在新的任务中重新使用[45]。对于一个图像分类任务来说,前几层通常会提取低层次的特征(即斑点、角落和边缘),而低层次的特征通常在图像分类任务中很常见。由于ImageNet和HSI分类之间的任务相似,转移学习步骤可以通过对HSI分类任务进行微调来促进。具体来说,在ImageNet数据集上学习的VGGNet的权重可以用来初始化HSI分类的网络,然后在HSI分类任务中微调权重。这里,我们提出了一个新的分类框架,名为T-SST,用于HSI分类,它是由转移的VGGNet、修改的Transformer(即DenseTrans-former)和MLP组合而成。在T-SST中,使用了16层的VGGNet,它是在ImageNet数据集上训练的,源任务中所有卷积层的训练好的权重被转移到我们的目标任务。然后,这些初始化的权重在HSI数据集上进行微调。与原始的VGGNet相比,使用转移的VGGNet可以提取更多的鲁棒性和判别性特征,这对下面的处理很有用。使用转移的VGGNet获得的特征被用作转化器的输入。特别是,一个二维斑块,它包含了HSI波段中的相邻像素,是转换的VGGNet的输入。VGGNet使用所有的卷积层来提取输入的特征,然后将获得的特征送入DenseTransformer。下面的MLP被用来获得最终的分类结果。
3.3.建议用于HSI分类的T-SST-L
如果没有足够的训练样本,模型就会面临"过拟合"的问题,这意味着测试数据的分类精度会很低。当T-SST应用于HSI分类时,这个问题就暴露出来了,因为在实际应用中,训练样本有限是一个常见的问题。为了解决T-SST中的过拟合问题,我们引入了标签平滑法。在分类中,每个训练样本x都有相应的标签y∈{1,2,…,C}。是类的数量。这里,我们用一个维的单热向量y来表示训练样本的标签。其中,y_k=δ_(k,y) r,k=1,2,…,C,δ_(k,y)代表离散狄拉克三角函数,在下列k=y情况下等于1=,否则0。
然而,[46]中的工作表明,如果我们把所有的地面真实标签都分配为"硬标签"(即theδ_(k,y)),那么模型将在许多努力中挣扎,把标签的预测分布推向硬标签。此外,如果对标签进行适当的平滑处理,即在δ_(k,y)中的零点上分配微小的概率质量,就可以有效地缓解这种情况。直观地说,发生这种情况是因为模型对其预测变得过于自信。因此,在本文中,本文引入了一种称为标签平滑的机制,用于鼓励模型不那么自信,以实现更好的性能。标签平滑将原始标签y_k改变为y_k^’,可以定义如下:

通过减少模型学习每个训练样本的全部概率标签,标签平滑机制可以缓解过拟合问题,并以简单的形式提高模型的生成能力。
4.实验结果
4.1.高光谱数据集
在这项研究中,所提出的方法的性能在三个公共数据集上进行了评估,包括Salinas、Pavia大学(Pavia)和IndianPines数据集。表1报告了所有数据集的信息,包括传感器、波段数、空间分辨率、像素大小尺寸、等级数和数据采集年份。所有数据集的描述总结如下。 对于萨利纳斯数据集,它是由AVIRIS于1998年在美国加利福尼亚州萨利纳斯谷上空收集的。在去除20个低信噪比(SNR)的频段后,204个频段被用于实验。
这个超规格图像包括512×217像素,空间分辨率为3.7米。常见的16个类别被标注在地面实况中。图4中显示了假色对比图像、可用的地面实况图和标度条。
就帕维亚数据集而言,它是由意大利帕维亚大学的反射光学光谱成像系统(ROSIS)传感器在2001年在一个城市场景中获得。该数据集的大小为×610像素340,空间分辨率为m1.3,光谱范围为μ0.430.86m。由于信噪比和水的吸收,一些波段12被去除,剩下的波段103被用于实验。有9个城市区分等级。图5显示了假彩色合成图像、可用的地面实况图和比例尺。
对于印度松树数据集,它是由AVIRIS传感器在1992年印第安纳州西北部的印度松树地区捕获的。它的空间大小为145×145,空间分辨率为m20。0.4到μ2.5m,在舍弃水20吸收带后。在可用的地面实况中标注了16个地面实况等级。图中6显示了假彩色合成图像、可用的地面实况图和比例尺。
每个数据集被分为三个子集:训练集、验证集和测试集。训练集包括200个用于模型训练的标记样本,这些样本是从所有的标记样本中随机抽取的,验证集包括50个用于指导模型的标记样本,剩下的样本被用作测试集。输入的HSI数据集被归一化为[-0.50.5]。根据图1,为了捕捉光谱领域的长距离关系,HSI数据立方体由个波段组成,其中波段的顺序与光谱顺序一致。每个样本的邻域像素被设置为33×33,然后这些样本被送入VGGNet。
4.2.训练详情
实验中采用了16层的VGGNet,其中包含13个卷积层和3个全连接层。VGGNet的特点是主要采用小型卷积滤波器,大小为3×3。此外,卷积13层可以分为五组,每组包含两到三个卷积层,后面还有一个最大池层。SST中的VGGNet的结构与VGGNet相似;为了减少HSI分类的过拟合,几个卷积层被忽略,前三个卷积层组减少一个卷积层,第四个卷积层减少前两个卷积层。此外,对于T-SST,VGGNet的架构采用了所有的卷积层,将其作为初始化权重。对于Pavia和印度松树数据集,加入了dropout。然后,利用HSI训练样本,通过反向传播算法对VGGNet进行微调。由于VGGNet在每个波段的输入,设计了一个映射层,其输入是每个波段,输出是三个特征。然后,这些特征被送到VGGNet中,以提取鉴别性特征。
在训练过程中,采用了小批量算法,对所有数据集都设置为128[48]。对于SST,萨利纳斯数据集的初始学习率被设置为8×10(-5),帕维亚和印第安松数据集的初始学习率被设置为9×10(-5),并且每0.9一个历时的学习率都会降低。在实验中,小的学习率被认为适合于SST的HSI分类。此外,对于T-SST,萨利纳斯、帕维亚和印第安松树数据集的学习率分别被设置为3×10(-4),9×10(-5)和1×10^(-4)。对于Salinas、Pavia和IndianPines数据集,学习率在0.9每个历时中分别减少和0.7,0.9,。此外,Salinas数据集的训练历时设置为150,Pavia和IndianPines数据集的训练历时设置为80此外,还考虑了总体准确率(OA)、平均准确率(AA)和卡帕系数(K),以评估不同方法的性能。
4.3.参数分析
为了全面研究空间-光谱变换器,本节将分析变换器中涉及的一些关键参数,包括注意力头的数量、变换器编码器的深度以及所提出的T-SST-L的平滑系数。对于注意头的数量和变换器编码器的深度,它们不仅影响模型的鲁棒性,而且还影响模型的复杂性。随着模型深度的增加,模型很容易出现过拟合问题。对于平滑因子,的值可能会影响到模型的性能。因此,需要研究这些参数的最佳参数设置。
为了分析这些参数对模型的影响,其他参数是固定的;训练样本200被用来寻找最佳参数。图中显示7了在Salinas、Pavia和IndianPines数据集上由OA(%)评估的分析结果。为了寻找最佳的注意力头数,我们选择了1、2、4、8和16个注意力头。这一结果显示在图7a中:可以看出,所有数据集的最佳注意力头数是2个。对于跨前编码器的深度,搜索了从1到5的深度。图7b显示,所有数据集的最佳深度为2:可以得出结论,深度不足可能会导致信息不完整,而对于太深的模型,由于需要大量的参数来训练,准确率会下降。在实验中,根据这些结果,所有数据集的注意力头数和Transformer编码器的深度都设置为2,以获得更好的分类结果。
是T-SST-L的平滑因子;为了验证T-SST-L在不同的值下的影响,利用网格搜索法搜索的最佳值,从0.2到0.9变化。图8显示了不同的值的OA。可以看出,不同的值的OA是波动的,但是当值被设定为0.9时,所提出的T-SST-L在三个数据集上获得了最好的结果。因此,在所有的实验中,0.9所有数据集的值都设置为0.9,以获得HSI分类的最佳性能。
4.4.SST和SST-FA在HSI分类中的分类结果
在本节中,通过几个对比实验验证了所提出的SST和SST-FA,包括传统方法(即RBFSVM和EMP-SVM)和经典的CNN相关方法(即CNN,SSRN和VGG)。对于RBF-SVM,采用径向基函数作为核,并使用网格搜索方法来寻找最佳的和值,它们处于指数增长序列{10(-3),10(-2),…,┤,├ 10^3 }。最佳参数和是通过五次交叉验证得到的。EMP-SVM结合了EMP和SVM;对于EMP,在EMP中设计了一个大小从2到8递增的盘状结构元素,用于提取特征的开合操作。CNN和SSRN的结构分别按照[49]和[34]中描述的设置实现。
表2-4中报告了SST和SST-FA的实验结果。可以看出,所提出的SST-FA实现的OA、AA和kappa值是最好的,在Salinas、Pavia、IndianPines上分别达到94.94%、93.37%和88.98%。
所有的实验结果表明,SST-FA在所有的HSI数据集上都达到了最好的性能,它在缓解过拟合方面具有优势。以Salinas数据集为例,与传统方法相比,SST的OA比RBF-SVM和EMP-SVM分别提高了11.33%和6.83%;AA分别提高了7.65%和4.46%;Kappa提高了12.66%和7.58%。此外,与CNN相比,SST的OA在Salinas、Pavia和IndianPines数据集上分别提高了6.02%、1.33%和1.96%。此外,与基于CNN的方法(包括SSRN和VGG)相比,对于IndianPines数据集,SST的准确率达到了88.77%,分别提高了5.56%和1.97%。SST在Salinas和Pavia数据集上也有改进。图中显示了SST的9学习曲线,包括三个数据集的损失、训练精度和验证样本。实验结果表明,所提出的SST在提取HSI的顺序信息方面具有优势。
4.5.拟议的用于HSI分类的T-SST和T-SST-L的分类结果
在这一节中,预先发送了所提出的T-SST和T-SST-L的实验结果,以测试HSI分类的性能,它们使用预先在大型数据集上训练的VGGNet作为VGGNet的初始化权值。为了进一步验证所提出的T-SST和T-SST-L在HSI分类中优于其他方法,EMP-randomfor纪元损失遥感.2021,13,49816的22我们选择了EMP-RF、EMP-CNN、VGG和T-CNN进行比较。对于EMP-RF,关于EMP的去尾信息与之前的设置相同。然后,由EMP导出的特征被送入具有200棵决策树的RF分类器[50]。此外,EMP-CNN将EMP与CNN结合起来,用于光谱-空间分类。具体来说,EMP-CNN的架构设计类似于CNN[49]。此外,我们采用了一种名为VGG的比较方法,其结构遵循VGGNet中所有的卷积层;之后,为HSI分类增加了一个全连接层。此外,为了证明所提出的带有转移学习的Transformer方法是有效的,我们还利用了带有转移学习的CNN(T-CNN)。从所有波段中随机选择三个波段,然后用前七个卷积层的所有VGGNet权重来初始化T-CNN,完成HSI分类任务。表5-7中报告了拟议的T-SST和T-SST-L的结果。与最先进的精心设计的网络相比,建议的T-SST-L取得了有竞争力的结果。在Salinas、Pavia和IndianPines数据集上,建议的TSST-L的OA分别达到96.83%、93.73%和91.20%。此外,可以看出,在所有的数据集上,所提出的T-SST都优于其他现有方法。具体来说,在Salinas、Pavia和IndianPines数据集上,TSST分别比EMP-RF高出4.16%、5.08%和4.96%的OA。此外,T-SST在萨利纳斯数据集上获得的准确率比EMP-CNN高3.09%,而在印度松树数据集上,则为2.84%。此外,与T-CNN相比,提议的T-SST在Salinas数据集上的OA和方面取得了约2%的改进。此外,与提议的T-SST相比,提议的T-SST-L在Salinas和IndianPines数据集上的精确度分别提高了1.03%和1.14%。这表明,标签平滑是防止过拟合问题的有效方法。
4.6.拟议的T-SST的变压器编码器表示法的分析
在本小节中,为了了解所提出的T-SST是如何捕获长距离的依赖关系的,我们通过可视化的正常化注意力权重来分析Transformer编码器的表示。图10-12显示了三个高光谱数据集上各波段之间的归一化注意力权重。由于HSI中有数百个波段,很难对每一个波段进行完整的可视化处理。因此,我们选择了第一个波段、中间波段和最后一个波段来说明所选波段与另一个波段之间的长距离依赖关系。特别是,在Salinas数据集上204选择了波段1,和100,波段;在Pavia数据集上选择了波段1,50和波段103;在IndianPines数据集上200选择了波段1、波段100和波段。
如图10-12所示,在三个高光谱数据集上,注意力权重的值有强烈的波动,即使两个波段有很长的距离,注意力权重的值也会很高。以Salinas数据集为例:在图10a中,尽管两个波段的距离很远,但50波段和203波段之间的归一化注意力权重值非常高。这些结果表明,T-SST倾向于捕捉长距离的依赖关系。
4.7.分类地图
为了全面评估分类结果,图13-15显示了不同方法在所有数据集上的分类图;这些方法包括EMP-SVM、CNN、SSRN、VGG,以及我们提出的方法(即SST-FA和T-SST-L)。通过比较可以看出,EMP-SVM的分类图在所有的数据集上都产生了更多的错误,而对于提议的SST和T-SST,存在较少的噪声点。此外,在图中15,与其他基于CNN的方法相比,例如,在CNN、SSRN和VGG的比较中(见图15b-d),许多像素在印度松树数据集的不同类别的边界上被错误地分类,而所提出的方法能够正确地分类出更多的类别(即大豆清洁),并且有更清晰的区分度。显然,与其他方法相比,SST-FA和T-SST-L产生的分类图质量最高,这表明所提出的SST-FA和T-SST-L分别能有效提高模型的性能。
4.8.时间消耗
表8中报告了三种具有200个训练样本的HSI数据集的不同方法的执行时间。所有的实验都是在配备英特尔酷睿i7-10700F处理器(2.9GHz)、64GBDDR4内存、NVIDIAGeForceRTX3070图形处理单元(GPU)的计算机上进行。对于包括RBF-SVM、EMPSVM和EMP-RF在内的传统方法,处理时间很短,但这些方法取得的性能很差。此外,对于CNN和T-CNN来说,由于CNN比其他有竞争力的基于深度学习的方法包含更少的参数,而T-CNN只包含三个用于转移学习的波段,所以运行时间很短。此外,与CNN相比,SSRN和VGG需要更长的时间,因为SSRN需要更多的epochs来训练网络,VGG包含许多3×3卷积核。对于提议的方法(即SST、T-SST和T-SST-L),由于提议的方法考虑了Trans前者的模型,所以处理时间较长。
5.结论
在这项研究中,研究了用于HSI分类的变换器。具体来说,提出了DenseTransformer,它使用密集连接来缓解Transformer训练中的梯度消失问题。此外,还提出了两个分类框架(即SST和T-SST)来处理HSI分类的任务。所提出的方法在三个流行的HSI数据集上获得了卓越的分类精度。对于所提出的基于SST的HSI分类方法,它充分利用了CNN来捕捉二维斑块的空间特征,并充分利用了DenseTransformer来捕捉光谱域中的长距离关系。所使用的自我注意机制考虑了他的像素向量的内在顺序数据结构,CNN和DenseTransformer的组合获得了光谱-空间判别特征,这对接下来的HSI分类很有用。此外,DenseTransformer结合动态特征增强(即SST-FA)被提出来用于缓解过拟合问题,因此它以简单的形式增强了模型的ac-curacy。此外,T-SST的有效性也得到了检验。提出的T-SST将转移学习和SST结合起来,进一步提高了分类性能。为了在ImageNet数据集上使用预训练的模型,我们去掉了一个异质映射层,用来映射源域(即ImageNet数据集)中的模型到目标领域(即HSI)。获得的实验结果显示了T-SST在HSI分类中的作用。最后,标签平滑被证明是基于变换器的HSI分类中一个有用的正则化技术。与SST、SST-FA、T-SST和其他方法相比,所提出的T-SST-L导致了较高的性能。所提出的SST和T-SST已经显示了所提出的DenseTrans-former在HSI分类方面的潜力。然而,这还处于基于Transformer的HSI分类的早期阶段。在我们未来的工作中,可以利用Transformer的各种改进,为HSI的精确分类开辟新的道路。
图表、致谢及参考文献已略去
原文出处:He X , Chen Y , Lin Z . Spatial-Spectral Transformer for Hyperspectral Image Classification[J]. Remote Sensing, 2021, 13(498).
原文链接:https://www.researchgate.net/publication/348804892_Spatial-Spectral_Transformer_for_Hyperspectral_Image_Classification