基于Python的政府新闻人物网络挖掘(网络、群体与市场)
用户手册
概述
程序支持使用结巴分词获取人物、地点、机构三类实体名,以 network x \text{network}x networkx 和 Neo4j \text{Neo4j} Neo4j 两种方法构建人物关系网络,在此基础上计算网络属性、 PageRank \text{PageRank} PageRank 、聚集系数、中介中心度、 Louvain \text{Louvain} Louvain 社区发现以及 k \text{k} k 短路径。
项目文件夹下包括源代码目录 src,已计算好的各类分值及预处理后的 Json \text{Json} Json 文件目录 data_Json,以及从 gov.cn \text{gov.cn} gov.cn 上获取的新闻数据 KaTeX parse error: Expected '}', got '_' at position 10: \text{gov_̲news.txt} 。用户可调用函数复现项目内容,也可以根据计算好的 Json \text{Json} Json 文件直接获取结果。
本项目的实现使用 python3.7 和 Neo4j-3.5.11。
**注:**不同版本的 Neo4j \text{Neo4j} Neo4j 数据库支持的函数 API \text{API} API 不全然相同,可根据 Neo4j \text{Neo4j} Neo4j 官网说明修改 src/Gov_neo4y.py 和 src/utils.py 中的部分 Neo4j \text{Neo4j} Neo4j 命令行语句,可达到同样的效果。
文件及参数说明
-
utils.py
参数 功能 − d -d −d 需附加参数,参数为预处理结果保存目录,默认为KaTeX parse error: Expected '}', got '_' at position 19: …xt{'../data/new_̲data_Json'} -
Gov_networkx.py
参数 功能 − d -d −d 需附加参数,参数为网络关系文件路径,由数据预处理过程得到,默认为KaTeX parse error: Expected '}', got '_' at position 20: …t{'../data/data_̲Json/relation_f… − n -n −n 需附加参数,参数为结果文件保存目录,默认为 KaTeX parse error: Expected '}', got '_' at position 20: …t{'../data/data_̲Json'} − v -v −v 图的验证,输入一个人名,查询与其关系最强的 10 个邻居 − s -s −s 图的统计,获取图的结点个数、边数、连通分量个数、最大连通分量大小 − c p -cp −cp 计算并返回 PageRank \text{PageRank} PageRank影响力 Top 10 \text{Top 10} Top 10 人物及分数,将所有人物的分值保存在结果目录下的 KaTeX parse error: Expected '}', got '_' at position 15: \text{pagerank_̲networkx.json} − c c -cc −cc 使用 Louvain \text{Louvain} Louvain 算法社区挖掘,并将各人所属社区编号保存至结果目录下的 KaTeX parse error: Expected '}', got '_' at position 16: \text{community_̲networkx.json} − c f -cf −cf 计算并返回聚集系数 Top 10 \text{Top 10} Top 10 人物及分值,将所有人物的聚集系数保存至结果目录下的 KaTeX parse error: Expected '}', got '_' at position 17: …text{clustering_̲coef_networkx.j… − p -p −p 读取结果目录下的 KaTeX parse error: Expected '}', got '_' at position 15: \text{pagerank_̲networkx.json} 文件,获取 Top 10 \text{Top 10} Top 10 − f -f −f 读取结果目录下的 KaTeX parse error: Expected '}', got '_' at position 17: …text{clustering_̲coef_networkx.j… ,获取 Top 10 \text{Top 10} Top 10 − w -w −w 获取两节点间的 前 10 10 10 条最短路径 -
Gov_neo4j.py
参数 功能 − d -d −d 需附加参数,参数为网络关系文件路径,由数据预处理过程得到,默认为KaTeX parse error: Expected '}', got '_' at position 20: …t{'../data/data_̲Json/relation_f… − n -n −n 需附加参数,参数为结果文件保存目录,默认为 KaTeX parse error: Expected '}', got '_' at position 20: …t{'../data/data_̲Json'} − c -c −c 创建 N e o 4 j Neo4j Neo4j 数据库 − c p r -cpr −cpr 计算 PageRank \text{PageRank} PageRank 分值,并保存至 N e o 4 j Neo4j Neo4j 数据库,作为节点属性 − p r -pr −pr 获取 N e o 4 j Neo4j Neo4j 中保存的 PageRank \text{PageRank} PageRank 分值,并保存至结果文件夹下 KaTeX parse error: Expected '}', got '_' at position 15: \text{pagerank_̲neo4j.json} − c b c -cbc −cbc 计算中介中心性,并保存至 N e o 4 j Neo4j Neo4j 数据库,作为节点属性 − b c -bc −bc 获取 N e o 4 j Neo4j Neo4j 中保存的 Betweenness centrality \text{Betweenness centrality} Betweenness centrality 分值,并保存至结果文件夹下 KaTeX parse error: Expected '}', got '_' at position 18: …ext{betweenness_̲centrality.json… − c l -cl −cl 使用 Louvain \text{Louvain} Louvain 算法划分社区,并将各节点所属社区编号保存至 N e o 4 j Neo4j Neo4j 数据库,作为节点属性 − l -l −l 获取各社区包含的所有节点,并保存至结果文件夹下 KaTeX parse error: Expected '}', got '_' at position 16: \text{community_̲neo4j.json}
数据预处理
数据预处理部分代码在 src/utils.py 中,如下运行即可对新闻数据进行预处理:
cd src #进入代码目录文件www.biyezuopin.vip
python utils.py # 使用默认存储目录../data/new_data_Json
python utils.py -d ../data/new_data_Json # 自定义存储目录
预处理结果已存放在目录 src/data_Json 中,用户可直接利用该目录中的数据文件。
**注:**推荐使用 src/data_Json 中的 KaTeX parse error: Expected '}', got '_' at position 12: \text{human_̲filtered2.json} 和 KaTeX parse error: Expected '}', got '_' at position 15: \text{relation_̲filtered.json} 文件,其为作者人工删除掉部分结巴分词得到的“垃圾”数据的结果,例如成语、四字词语、地名、机构名后的人名集合和关系集合,相对原始数据更准确。用户也可自行从头运行数据预处理部分,比对结果。
该文件主要包括以下两部分功能:
-
结巴分词及频度统计:
使用结巴分词对人名、地名、机构名进行抽取和词频统计,并根据新闻共现关系建立联系。存储在指定目录下的 human.json,places.json,organs.json \text{human.json,places.json,organs.json} human.json,places.json,organs.json 和 relation.json \text{relation.json} relation.json 中。
-
实体名排序及过滤
对三类实体按频度排序,并存储在 KaTeX parse error: Expected '}', got '_' at position 12: \text{human_̲sorted1.json, p… 文件中。进一步对人名处理,过滤掉其中单字人名,并相应删除对应的关系。保存在 KaTeX parse error: Expected '}', got '_' at position 12: \text{human_̲sorted2.json} 和 KaTeX parse error: Expected '}', got '_' at position 15: \text{relation_̲filtered.json} 中。
N e t w o r k x Networkx Networkx 网络分析
使用 Networkx \text{Networkx} Networkx 构建和分析网络,实现了网络构建、图的验证、图的统计、 PageRank \text{PageRank} PageRank影响力计算、聚集系数计算、 Louvain \text{Louvain} Louvain社区挖掘。代码在 src/Gov_networkx.py 中。
-
图的验证
如下运行 KaTeX parse error: Expected '}', got '_' at position 10: \text{Gov_̲networkx.py},获取目标人物的 Top 10 \text{Top 10} Top 10 强关系节点。
cd src python Gov_networkx.py -v # 使用默认关系数据路径 python Gov_networkx.py -d ../data/data_Json/relation_filtered.json -v #使用自定义关系数据路径根据提示输入人名,输入 quit \text{quit} quit即可退出。若输入的人名不存在,则程序给出提示,可重新输入人名。

-
图的统计
如下运行 KaTeX parse error: Expected '}', got '_' at position 10: \text{Gov_̲networkx.py},获取图的统计信息:
cd src python Gov_networkx.py -s # 使用默认关系数据路径 python Gov_networkx.py -d ../data/data_Json/relation_filtered.json -s #使用自定义关系数据路径输出结点数、边数、连通分支数、极大连通分支节点数:

-
PageRank \text{PageRank} PageRank影响力
用户可直接使用计算好的文件输出 PageRank Top 10 \text{PageRank Top 10} PageRank Top 10 ,也可以选择重新计算 PageRank \text{PageRank} PageRank 并保存。
a. 计算 PageRank \text{PageRank} PageRank 并保存结果
如下运行 KaTeX parse error: Expected '}', got '_' at position 10: \text{Gov_̲networkx.py},在输出 Top 10 \text{Top 10} Top 10 人物的同时,将所有节点的分值保存至指定目录下的 KaTeX parse error: Expected '}', got '_' at position 15: \text{pagerank_̲networkx.json} :
cd src python Gov_networkx.py -cp # 使用默认关系数据路径 python Gov_networkx.py -d ../data/data_Json/relation_filtered.json -n ../data/data_Json -cp #使用自定义关系数据路径,自定义输出结果目录b. 直接获取 PageRank \text{PageRank} PageRank
如下运行 KaTeX parse error: Expected '}', got '_' at position 10: \text{Gov_̲networkx.py},在输出 Top 10 \text{Top 10} Top 10 人物的同时,将所有节点的分值保存至指定目录下的 KaTeX parse error: Expected '}', got '_' at position 15: \text{pagerank_̲networkx.json} :
cd src python Gov_networkx.py -p # 使用默认关系数据路径www.biyezuopin.cc python Gov_networkx.py -d ../data/data_Json/relation_filtered.json -n ../data/data_Json -p #使用自定义关系数据路径,自定义结果目录(pagerank_networkx.json所在目录)
-
聚集系数计算
用户可直接使用计算好的文件输出聚集系数 Top 10 \text{Top 10} Top 10 ,也可以选择重新计算聚集系数并保存。
a. 计算聚集系数并保存结果
如下运行 KaTeX parse error: Expected '}', got '_' at position 10: \text{Gov_̲networkx.py},在输出 Top 10 \text{Top 10} Top 10 人物的同时,将所有节点的分值保存至指定目录下的 KaTeX parse error: Expected '}', got '_' at position 17: …text{clustering_̲coef_networkx.j… :
cd src python Gov_networkx.py -cf # 使用默认关系数据路径 python Gov_networkx.py -d ../data/data_Json/relation_filtered.json -n ../data/data_Json -cf #使用自定义关系数据路径,自定义输出结果目录b. 直接获取聚集系数
如下运行 KaTeX parse error: Expected '}', got '_' at position 10: \text{Gov_̲networkx.py},在输出 Top 10 \text{Top 10} Top 10 人物的同时,将所有节点的分值保存至指定目录下的 KaTeX parse error: Expected '}', got '_' at position 17: …text{clustering_̲coef_networkx.j… :
cd src python Gov_networkx.py -p # 使用默认关系数据路径 python Gov_networkx.py -d ../data/data_Json/relation_filtered.json -n ../data/data_Json -p #使用自定义关系数据路径,自定义结果目录(clustering_coef_networkx.json所在目录)
-
Louvain \text{Louvain} Louvain社区挖掘
如下运行 KaTeX parse error: Expected '}', got '_' at position 10: \text{Gov_̲networkx.py},将所有节点所属社区保存至指定目录下的 KaTeX parse error: Expected '}', got '_' at position 16: \text{community_̲networkx.json} :
cd src python Gov_networkx.py -cc # 使用默认关系数据路径 python Gov_networkx.py -d ../data/data_Json/relation_filtered.json -n ../data/data_Json -cc #使用自定义关系数据路径,自定义结果目录正确运行输出如下:

-
小世界现象: K \text{K} K 短路径
如下运行 KaTeX parse error: Expected '}', got '_' at position 10: \text{Gov_̲networkx.py},使用 Yen’s \text{Yen's} Yen’s 算法获取节点间最短路径:
cd src python Gov_networkx.py -w # 使用默认关系数据路径 python Gov_networkx.py -d ../data/data_Json/relation_filtered.json -w #使用自定义关系数据路径根据提示输入源节点和目标节点人名,输入 $\text{quit} $即可退出。

N e o 4 j Neo4j Neo4j 网络分析
使用图数据库 N e o 4 j Neo4j Neo4j 进行网络的构建和指标计算,实现了 PageRank \text{PageRank} PageRank 计算、中介中心性计算和 Louvain \text{Louvain} Louvain 社区挖掘。代码在 src/Gov_neo4j.py 中。
**注:**使用该部分代码需要用户安装或在线使用 N e o 4 j Neo4j Neo4j 数据库。
-
向 N e o 4 j Neo4j Neo4j 数据库导入数据,构建网络
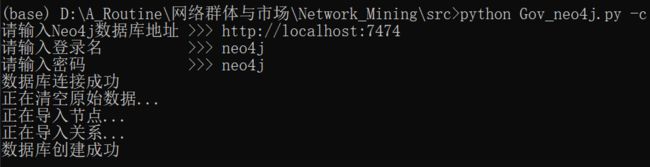
如下运行 KaTeX parse error: Expected '}', got '_' at position 10: \text{Gov_̲neo4j.py},构建图数据库:
cd src python Gov_neo4j.py -c # 使用默认关系数据路径 python Gov_networkx.py -d ../data/data_Json/relation_filtered.json -w #使用自定义关系数据路径代码正确运行输出如下,首先连接 N e o 4 j Neo4j Neo4j 数据库,然后清空当前数据库,将网路节点及关系插入数据库。
-
PageRank \text{PageRank} PageRank 影响力
首次运行时,用户需先调用 − c p r -cpr −cpr 计算 PageRank \text{PageRank} PageRank 分值并保存至数据库,再调用 − p r -pr −pr 获取分值。此后可直接调用 − p r -pr −pr 获取分值。调用 − p r -pr −pr 在输出 Top 10 \text{Top 10} Top 10 的同时,也将结果保存至结果目录下的 KaTeX parse error: Expected '}', got '_' at position 15: \text{pagerank_̲neo4j.json} 文件中。
cd src # 首次运行示例 python Gov_neo4j.py -cpr -pr # 使用默认关系数据路径 python Gov_networkx.py -d ../data/data_Json/relation_filtered.json -n ../data/data_Json -cpr -pr #使用自定义关系数据路径,自定义结果保存目录 # 非首次运行示例 python Gov_neo4j.py -pr python Gov_networkx.py -d ../data/data_Json/relation_filtered.json -n ../data/data_Json -pr #使用自定义关系数据路径,自定义结果保存目录 -
中介中心性 Betweenness centrality \text{Betweenness centrality} Betweenness centrality
首次运行时,用户需先调用 − c b c -cbc −cbc 计算 Betweenness centrality \text{Betweenness centrality} Betweenness centrality 分值并保存至数据库,再调用 − b c -bc −bc 获取分值。此后可直接调用 − b c -bc −bc 获取分值。调用 − b c -bc −bc 在输出 Top 10 \text{Top 10} Top 10 的同时,也将结果保存至结果目录下的 KaTeX parse error: Expected '}', got '_' at position 17: …text{beteenness_̲centrality_neo4… 文件中。
cd src # 首次运行示例 python Gov_neo4j.py -cbc -bc # 使用默认关系数据路径 python Gov_networkx.py -d ../data/data_Json/relation_filtered.json -n ../data/data_Json -cbc -bc #使用自定义关系数据路径,自定义结果保存目录 # 非首次运行示例 python Gov_neo4j.py -bc python Gov_networkx.py -d ../data/data_Json/relation_filtered.json -n ../data/data_Json -bc #使用自定义关系数据路径,自定义结果保存目录 -
Louvain \text{Louvain} Louvain 社区挖掘
首次运行时,用户需先调用 − c l -cl −cl 划分社区并保存至数据库,再调用 − l -l −l 将结果保存至结果目录下的 KaTeX parse error: Expected '}', got '_' at position 14: \text{Louvain_̲neo4j.json} 文件中,且文件形式为社区及其内部成员名单。
cd src python Gov_neo4j.py -cl -l # 使用默认关系数据路径 python Gov_networkx.py -d ../data/data_Json/relation_filtered.json -n ../data/data_Json -cl -l #使用自定义关系数据路径,自定义结果保存目录