Java集合深入剖析【韩顺平老师版】
Java集合知识体系【思维导图】
1、集合体系
1.1、为什么使用集合?
1、数组的不足
- 长度固定,不能更改
- 存储的必须是同一类型的元素(基本类型或引用类型)
- 增加、删除元素比较麻烦
2、集合的优势
- 长度可变,可以动态保存任意多个对象
- 可以存不同类型的元素(必须是引用类型,不能是基本类型:int、long…(基本类型数据会自动装箱成对象))
- 操作对象方便:add、remove、set、get等
3、区别
| 比较 | 数组 | 集合 |
|---|---|---|
| 长度 | 长度固定,不能更改 | 长度可变,可以动态保存任意多个对象 |
| 存储元素 | 同一类型(基本类型或引用类型) | 可以存不同类型(引用类型),但一般为相同类型 |
| 操作方法 | 增加、删除比较麻烦 | 增删查改比较方便 |
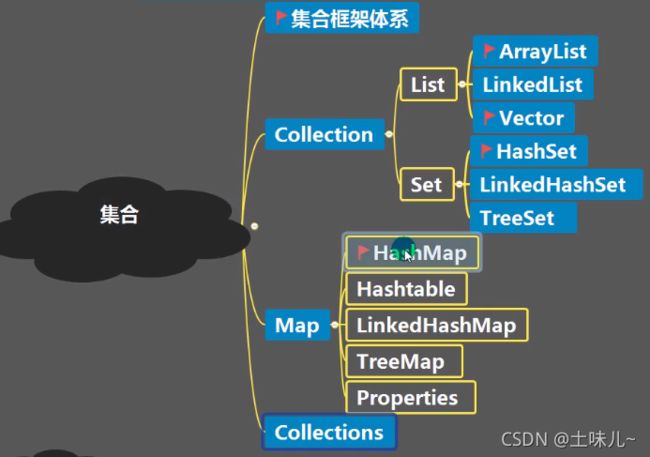
1.2、集合的框架体系
- 集合框架体系(Collection、Map等)位于java.util包下


1.3、hashCode() 与 equals() 基本原则



2、Collection
2.1、介绍
public interface Collection<E> extends Iterable<E> {}
- Collection实现子类可以存放多个元素,每个元素可以是Object
- Collection有些实现子类可以存放重复元素(List),有些不可以(Set)
- Collection接口没有直接的实现子类,是通过它的子接口List和Set来实现的

2.2、Collection方法
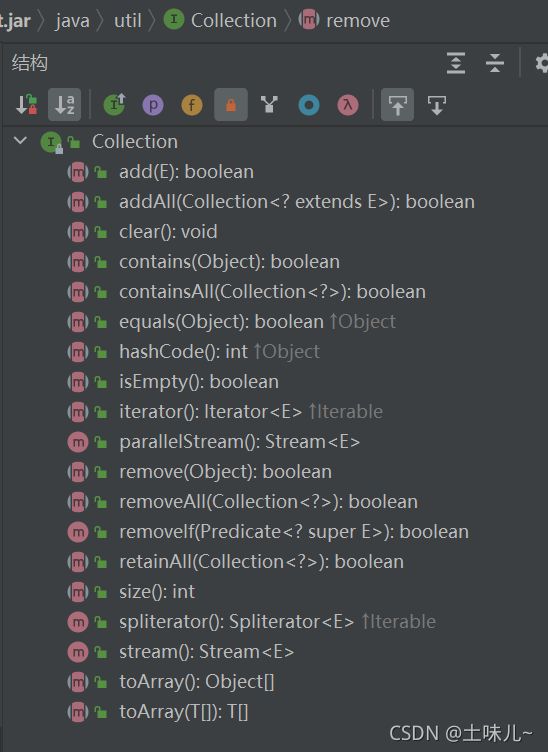
-
add(Object obj)添加一个元素。参数Object,所以可以是不同类型。如:String、int、boolean(基本类型时会自动装箱)
-
add(Collection coll)添加多个元素。参数Collection
-
int size()获取有效元素的个数
-
void clear()清空集合
-
boolean isEmpty()判断是否为空
-
boolean contains(Object obj)是否包含某个元素。通过元素的equals()方法比较
-
boolean containsAll(Collection c)是否包含多个元素。通过元素的equals()方法比较。两个集合逐个比较
-
boolean remove(Object obj)删除某个元素。通过元素的equals()方法比较。只删除找到的第一个元素。
-
boolean removeAll(Collection c)删除多个元素。从当前集合中删除c集合,留下的是差集。
-
boolean retainAll(Collection c)retain:保持; 持有; 保留; 继续拥有
交集。把当前集合与c集合的交集存在当前集合中。不影响c
-
boolean equals(Object obj)集合是否相等
-
Object[] toArray()转成对象数组
-
int hashCode()获取集合对象的哈希值
-
Iterator[E] iterator()遍历。返回迭代器对象。
2.3、Iterator迭代器接口
1、介绍
-
Java Iterator(迭代器)不是一个集合,它是一种用于访问集合的方法,可用于迭代Collection集合。
-
GOF给迭代器模式的定义为:提供一种方法访问一个容器(Container)对象中各个元素,而又不需暴露该对象的内部细节。迭代器模式,就是为容器而生。类似于“公交车上的售票员”。
GOF:《Design Patterns: Elements of Reusable Object-Oriented Software》(即后述《设计模式》一书),由 Erich Gamma、Richard Helm、Ralph Johnson 和 John Vlissides 合著(Addison-Wesley,1995)。这几位作者常被称为"四人组(Gang of Four)"。
-
Collection接口继承了java.lang.Iterable接口,该接口有一个iterator()方法,那么所有实现了Collection接口的集合类都有一个iterator()方法,用以返回一个实现了Iterator接口的对象。
-
Iterator仅用于遍历集合,Iterator本身并不承装(存储)对象。如果要创建Iterator对象,则必须有一个被迭代的集合。
-
集合对象每次调用iterator()方法都得到一个全新的迭代器对象,默认游标都在集合的第一个元素之前。
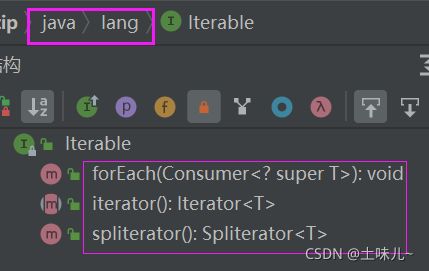
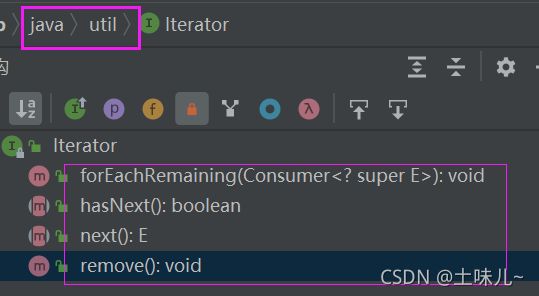
2、Iterable 与 Iterator
| 区别 | Iterable | Iterator |
|---|---|---|
| 类型 | 接口 | 接口 |
| 包 | java.lang | java.util |
| 方法 | iterator() forEach() spliterator() |
forEachRemaining() hasNext() next() remove() |
| 与Collection关系 | Collection实现Iterable接口 | Collection的iterator()方法返回Iterator对象 |
为什么Collection一定要去实现Iterable这个接口呢?为什么不直接实现Iterator接口呢?
因为Iterator接口的核心方法next()或者hasNext() 是依赖于迭代器的当前迭代位置的,是有状态的。 当集合在不同方法间被传递时,由于当前迭代位置不可预知,那么next()方法的结果会变成不可预知。 而Iterable则不然,每次调用都会返回一个从头开始计数的迭代器。 多个迭代器是互不干扰的。
3、Iterator方法
-
E next()返回下一个元素。作用:
1、游标下移
2、返回下一个元素
-
boolean hasNext()判断是否还有下一个元素
调用next()之前,必须先调用hasNext()进行检测,否则有可能抛出NoSuchElementException异常
-
void remove()删除当前游标位置的元素。返回void
不同于集合本身的remove()删除方法 (返回boolean)
4、迭代器的执行原理

5、三种遍历方式
Collection coll = new ArrayList();
coll.add(123);
coll.add(456);
coll.add(new Person("Jerry", 20));
coll.add(new String("Tom"));
coll.add(false);
-
方式一:普通for循环(不推荐)
方式一不适用于Set集合
因为Set集合有些是无序的,没有索引index
Set集合的实现类也有一些是有序的,如LinkedHashSet、TreeSet
for (int i =0;i< coll.size;i++){
System.out.println(coll[i]);
}
-
方式二:增强for循环(推荐)
增强for循环底层实现也是迭代器,就是简化版本的迭代器
Debug测试时,用 步入(F7) 或 强制步入(Alt + Shift + F7) 可以查看
for (String c : coll){
System.out.println(c);
}
-
方式三:迭代器(推荐)
IDEA快捷键:Ctrl + J,显示提示窗口,里面为快速输出提示
输入 itit :可以显示
while (iterator.hasNext()) {
Object next = iterator.next();
}
Iterator iterator = coll.iterator();
while (iterator.hasNext()){
System.out.println(iterator.next());
}
//退出while后,迭代器的游标指向最后一个元素
2.4、子接口
2.4.1、List
1、介绍
- List集合中元素有序、且可重复,集合中的每个元素都有其对应的顺序。存取顺序一致。
- List容器中的元素都对应一个整数型的序号(索引index)记录位置。从0开始。
- 常用的实现类有:ArrayList、LinkedList 和 Vector

2、List新增方法
List除了从Collection集合继承的方法外,List集合里添加了一些根据索引来操作元素的方法。如果操作的索引index不存在,将抛出异常。
-
void add(int index,Object)在index位置插入ele元素。index后面的元素后移。
-
boolean addAll(int index,Collection eles)从index位置把eles中的所有元素添加进来。返回boolean
-
Object get(int index)获取index位置的元素
-
int indexOf(Object obj)返回obj在集合中首次出现的位置
-
int lastIndexOf(Object obj)返回obj在集合中末次出现的位置
-
Object remove(int index)删除index位置的元素,并返回该元素
-
Object set(int index,Object ele)把index位置的元素设为ele
-
List subList(int fromIndex, int toIndex)返回从fromIndex 到 toIndex位置的子集合,不包括toIndex
3、子类
a、ArrayList
1、特性
-
ArrayList是List接口的典型实现类,也是主要实现类
-
线程不安全,效率高
-
可以存null值,并且可以存多个
-
ArrayList本质上是一个可变长数组,数组元素为Object。
-
transient Object[] elementData
transient:表示瞬间的、短暂的。该属性不会被序列化。
-
-
ArrayList在JDK1.8前后是有区别的
- JDK1.7:像饿汉式,直接创建一个初始容量为10的数组
- JDK1.8:像懒汉式,一开始创建一个长度为0的数组;当添加第一个元素时再创建一个初始容量为10的数组。运行效率更高。
-
Arrays.asList(…)方法返回的是List集合,既不是ArrayList实例,也不是Vector实例。是一个固定长度的List集合。
2、扩容机制
-
初始值:
-
用无参构造方法 ArrayList()
JDK1.7初始值为:10
JDK1.8初始值为:0。当添加第一个元素时再创建一个容量为10的数组
-
用有参构造方法 ArrayList(int)
初始值就是 int
-
-
扩容
-
每次都扩大至现有容量的==1.5==倍
容量全部用完后才开始扩容
如:初始为10,扩容后为15;15再扩容为15+15/2=22…
底层用Arrays.copyOf()
-
韩顺平老师扩容机制源码分析
b、Vector
1、特性
- Vector是一个古老集合,JDK1.0就有了。
- 与ArrayList基本相同,区别是Vector是线程安全的,但效率比较低。
- Vector扩容机制:
-
默认构造方法,长度为10,默认扩容至现有容量的2倍
饿汉式:只要声明了vector,就马上创建容量为10的数组
-
指定大小时,每次扩容至现有容量的2倍
-
全部用完后才扩容
-
2、新增方法
-
void addElement(Object obj)添加元素
-
void insertElementAt(Object obj,int index)在index位置插入元素
-
void setElementAt(Object obj,int index)设置index位置的元素
-
void removeElementAt(Object obj)删除某个元素
-
void removeAllElementAts()删除所有元素
c、LinkedList
1、特性
- 当插 入、删除频繁时选择LinkedList。添加、删除效率高。
- 线程不安全,效率较高
- 双向链表。内部没有声明数组,而是定义了Node类型的first和last,用于记录首末元素。同时,定义内部类Node,作为LinkedList中保存数据的基本结构,其中还定义了两个变量:
- prev:记录前一个元素的位置
- next:记录后一个元素的位置


2、新增方法
-
void addFirst(Object obj)向链表开头添加一个元素
-
void addLast(Object obj)向链表结尾添加一个元素
-
Object getFirst()获取链表开头的元素
-
Object getLast()获取链表结尾的元素
-
Object removeFirst()删除链表开头的元素
-
Object removeLast()删除链表结尾的元素
d、区别
-
如何选择?
把ArrayList作为默认选择
当插 入、删除频繁时选择LinkedList
当多个线程需要同时操作某个集合时,选择Vector,线程安全
由于Vector是线程安全的,很多方法有synchronized限制,效率低,尽量避免使用
-
相同点
| 比较 | ArrayList、Vector、LinkedList相同点 |
|---|---|
| 包 | java.util |
| 实现接口 | list |
| 元素是否有序 | 有序,存取一致 |
| 元素是否可以重复 | 可以重复,可以存多个null |
- 不同点
| 比较 | ArrayList | Vector | LinkedList |
|---|---|---|---|
| 底层实现 | 可变数组 | 可变数组 | 双向链表 |
| 版本 | JDK1.2 | JDK1.0 | - |
| 初始容量 | 0,第一次添加时创建10个 | 10 | - |
| 加载因子 | 1 (用完才扩容) | 1 (用完才扩容) | - |
| 长度 | 可变长,1.5倍扩容 | 可变长,2倍扩容 | - |
| 线程安全 | 线程不安全 | 线程安全 | 线程不安全 |
| 执行效率 | 高 (查询快) | 低 | 中(添加、删除快) |
| 适用场景 | 查询 (单线程操作) | 多线程操作 | 添加、删除频繁时 (单线程操作) |
2.4.2、Set
1、介绍
-
Set接口是Collection接口的子接口
-
Set有些是无序的,有些是有序的(存取顺序一致,内部数组中仍是散列分布,无序的)
-
HashSet
是无序的,存入和取出的顺序不保证一致,不能通过索引index来获取元素;但内部也是有计算逻辑的,所以取出顺序是固定的,多次取出顺序一致
-
LinkedHashSet 有双向链表,存取顺序一致,内部数组中仍是散列分布,无序的
-
TreeSet 也是有序的
-
-
Set集合不允许包含相同的元素,可以存null,但只能有一个。存入相同元素会失败,不报错。
-
Set集合判断两个对象是否相同,用==equals()方法,不用运算符
-
Set接口的主要实现类有:TreeSet、HashSet

-
Set集合遍历
具体实现见迭代器小节
普通for循环不适用。因为Set是无序的,没有索引index
- 增强for循环
- 迭代器
2、子类
1、HashSet
a、介绍
-
HashSet底层是HashMap
public HashSet() { map = new HashMap<>(); } -
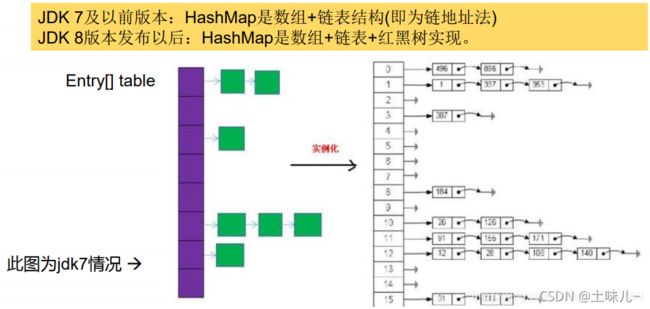
HashMap底层是:数组 + 链表 + 红黑树 (JDK1.8);
JDK1.7及之前:数组 + 链表
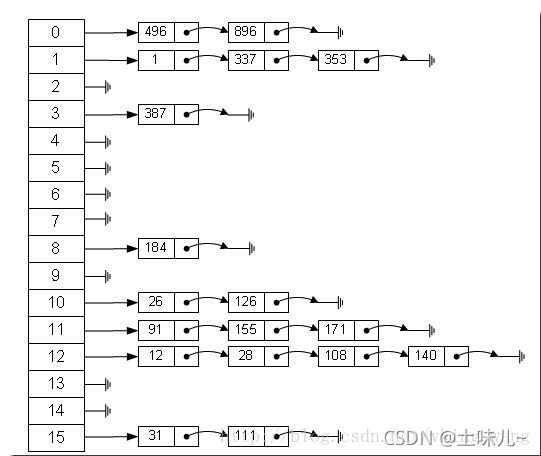
由于HashSet底层是HashMap,HashMap底层有数组,所以HashSet也是有索引的,但外部不能通过索引来获取元素,这个索引值是由元素的haspCode值计算来的,是散列分布在数组中的,无序的
b、扩容机制
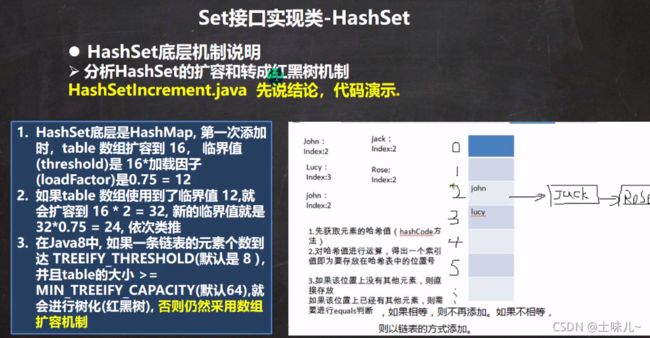
只要size达到临界值就扩容
size是数组、链表、红黑树中元素的总和。即便数组中的元素数量没有达到临界值,也一样扩容。
如:数组为16,临界值为12,size为13,但13个元素全部在一个链表中,只占用一个数组位,数组中还有15个空位,此时仍然扩容
c、添加不同类型元素
boolean add(Object obj)
不能添加相同的元素
new出来的类对象是不同的 (hashCode值不同),既便表面上名字相同
其它类型(基本类型、null、String),只要值相同 ,就可以作为相同对象,就不能重复添加
HashSet hashSet = new HashSet();
-
基本数据类型
如:int、long等
先对类型进行装箱,值相等时添加失败
hashSet.add(200);//true hashSet.add(200);//false -
null类型
hashSet.add(null);//true hashSet.add(null);//false -
字符串
不管是引用字符串,还是直接new的字符串,只要字符串内容相同,后面的就会添加失败
String对象是通过 equals() 来比较的
String对象的 hashCode() 也是通过字符串值计算出来的
hashSet.add("abc");//true hashSet.add("abc");//false hashSet.add(new String("xyz"));//true hashSet.add(new String("xyz"));//false
-
类对象
自定义类,可以重写 hashCode() 和 equals(),即使某些参数相等,hashCode() 和 equals() 也可能不同
如:Dog类的 hashCode() 和 equals()不是仅靠name计算的,name相同,hashCode() 和 equals()值也不同,所以可以添加
引用的类对象是相同的
//new:不同的,可以添加 hashSet.add(new Dog("小黄"));//true hashSet.add(new Dog("小黄"));//true //引用:相同的,添加失败 Dog dog = new Dog("小黑"); hashSet.add(dog);//true hashSet.add(dog);//false
d、添加原理剖析

实现步骤:
- 先计算元素的哈希值,进而得到索引
- 通过索引,找到数组中的位置 (即数据表table的位置)
- 索引位置没有元素时,直接加入
- 索引位置有元素,调用equals()比较。如果相同,放弃添加;如果不同,以链表的形式添加到后面。
韩顺平老师视频讲解
e、size()
HashSet的size()值为数组、链表以及红黑树中所有元素的总和。
只要向HashSet里面加一个元素,size就增加1。不管这个元素最后落在哪里(数组、链表 或者 红黑树)
f、练习(仔细体会)
import org.junit.Test;
import java.util.HashSet;
import java.util.Objects;
public class HomeWork4Test {
@Test
public void test1(){
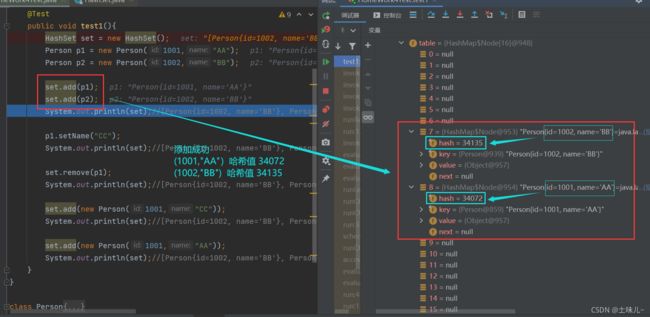
HashSet set = new HashSet();
Person p1 = new Person(1001,"AA");
Person p2 = new Person(1002,"BB");
set.add(p1);
set.add(p2);
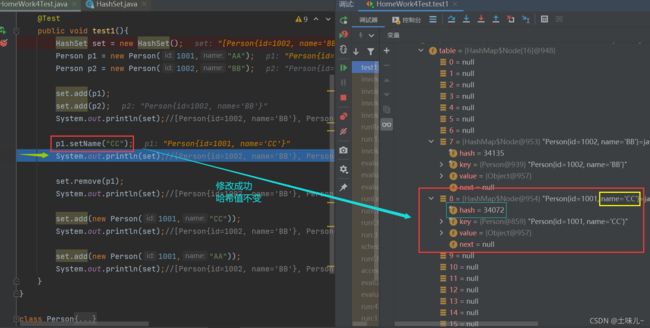
System.out.println(set);//[Person{id=1002, name='BB'}, Person{id=1001, name='AA'}]
p1.setName("CC");//修改后在哈希表中的位置没有变,还是以(1001,"AA")计算得到的哈希值
System.out.println(set);//[Person{id=1002, name='BB'}, Person{id=1001, name='CC'}]
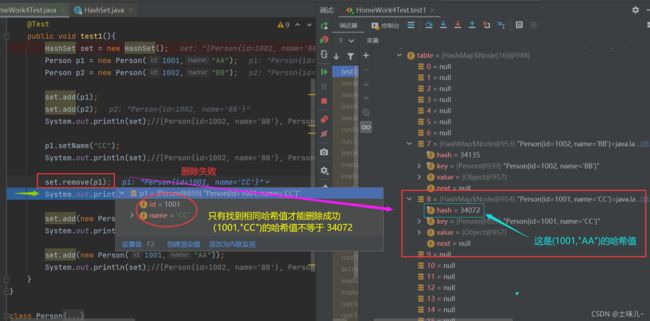
set.remove(p1);//此时删除失败。因为此时p1为(1001,"CC"),删除时会计算(1001,"CC")哈希值,此时哈希表中这个位置没有值,所以删除失败。
System.out.println(set);//[Person{id=1002, name='BB'}, Person{id=1001, name='CC'}]
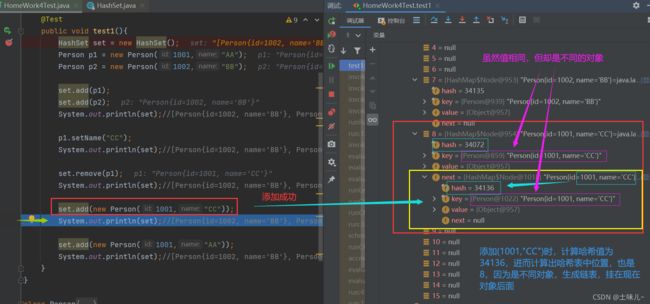
set.add(new Person(1001,"CC"));//添加成功。因为(1001,"CC")的哈希值对应位置为空。虽然集合中已有(1001,"CC"),但集合中的(1001,"CC")哈希值对应位置还是(1001,"AA")计算得来的,"CC"只是由"AA"修改得来的
System.out.println(set);//[Person{id=1002, name='BB'}, Person{id=1001, name='CC'}, Person{id=1001, name='CC'}]
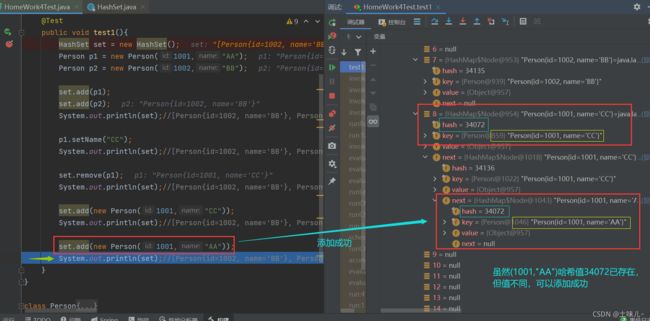
set.add(new Person(1001,"AA"));//添加成功。因为此时集合中没有(1001,"AA"),虽然集合中第一个(1001,"CC")的哈希值对应位置和(1001,"AA")一致,但equals()不同。(1001,"AA")会挂在(1001,"CC")链表的的后面
System.out.println(set);//[Person{id=1002, name='BB'}, Person{id=1001, name='CC'}, Person{id=1001, name='CC'}, Person{id=1001, name='AA'}]
}
}
class Person{
private int id;
private String name;
public Person(int id, String name) {
this.id = id;
this.name = name;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return id == person.id && Objects.equals(name, person.name);
}
@Override
public int hashCode() {
return Objects.hash(id, name);
}
@Override
public String toString() {
return "Person{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
}
2、LinkedHashSet
- LinkedHashSet 是 HashSet的子类
- LinkedHashSet 底层是 LinkedHashMap (HashMap的子类)
- LinkedHashSet 有双向链表,存入和取出顺序是一致的,所以表面上看是有序的,但在内部数组中仍然是散列分布,无序的
- LinkedHashSet 插入性能略低于 HashSet,但有很好的查询性能
- LinkedHashSet 不能插入重复元素(Set接口的特性)

- 扩容机制和 HashSet 一样
3、TreeSet
-
TreeSet 实现了 SortedSet 接口,SortedSet 是 Set 的子接口。TreeSet 可以确保集合元素处于排序状态
-
TreeSet 底层是 TreeMap。使用红黑树结构存储数据。
-
有两种排序方法:
-
自然排序 (默认)
-
TreeMap 的所有 key 必须实现 Comparator 接口,而且所有的 key 应该是同一个类的对象,否则将会抛出 ClassCastException
TreeSet set = new TreeSet();//未传入Comparator对象,按默认自然排序 set.add(new Person("absent",12));//Person 需实现 Comparator 接口,否则抛异常 set.add("hello");//String 对象实现了 Comparator 接口 class Person implements Comparator{// key类需要实现 Comparator 接口 private String name; private int age; }
-
-
定制排序
-
创建 TreeSet 时,传入一个 Comparator 对象,该对象实现了 compare() 方法,用该方法对 key 进行排序。此时不需要 key 对象实现 Comparator 接口
Comparator comparator = new Comparator() { @Override public int compare(Object o1, Object o2) { if (o1 instanceof Person && o2 instanceof Person){ Person p1 = (Person)o1 ; Person p2 = (Person)o2 ; return Integer.compare(p1.getAge(),p2.getAge()); }else { throw new RuntimeException("输入的数据类型不匹配"); } } }; TreeSet set = new TreeSet(comparator);//传入一个 Comparator 对象 set.add(new Person("absent",12)); class Person{// 有 Comparator 对象时,key类不需要实现 Comparator 接口 private String name; private int age; }
-
-
-
有序,查询速度比 List 快

红黑树讲解

会抛出ClassCastException
TreeSet 在创建时未传入 Comparator 对象,默认自然排序。此时 key 对象类需实现 Comparator 接口
4、区别
| 比较 | HashSet | LinkedHashSet | TreeSet |
|---|---|---|---|
| 包 | java.util | java.util | java.util |
| 父接口/父类 | Set | Set / 父类HashSet | Set |
| 底层实现 | HashMap | LinkedHashMap (双向链接) | TreeMap |
| 元素惟一性 | 不可重复 | 不可重复 | 不可重复 |
| 元素顺序 | 存取不一致 | 存取一致 | 可排序 |
| 效率 | 增删快、查询慢 | 增删稍慢、查询快 | 增删慢、查询快 |
-
HashSet 和 TreeSet 的去重机制
适用于 HashMap 和 TreeMap
HashSet 底层为 HashMap
TreeSet 底层为 TreeMap
- HashSet去重机制
- hashCode() + equals() 。底层先通过存入对象,进行运算得到一个hash值,通过hash值得到对应的索引,如果发现哈希表table索引所在的位置没有数据,就直接存放;如果有数据,就进行equals()比较(遍历);比较后,不相同,就加入(挂在链表后面或红黑树上),相同就不加入。
- TreeSet去重机制
- 如果传入了一个Comparator匿名对象,就使用实现的==compare()去重,方法返回0,就认为是相同的元素(或对象),就不添加;如是没有传入一个Comparator匿名对象,那么添加的对象必须实现Comparator接口,该接口有compareTo()==方法,就利用该方法去重。
- HashSet去重机制
3、Map
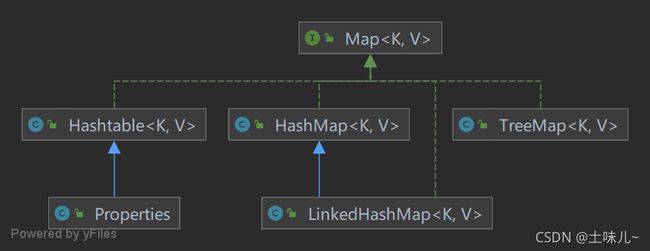
3.1、介绍
| 接口/类 | 主要特点 |
|---|---|
| Map(接口) | 双列数据,key-value键值对 |
| HaspMap | Map主要实现类,线程不安全,效率高 |
| LinkedHashMap | 继承自HashMap。有双向链表,存取顺序一致。遍历效率比HashMap高 |
| TreeMap | 保证按照添加的key-value对进行排序,实现排序遍历。底层使用红黑树 |
| HashtabLe | 古老的Map实现类;线程安全的,效率低;不能存储null的key和value |
| properties | 常用来处理配置文件。keyFialue都是String类型 |

- Map 与 Collection 并列存在,用于保存具有映射关系的数据:key - value (键值对,双列数据)
- key 和 value 可以是任何引用类型的数据,会封装到 HashMap$Node 对象中
- key 不能重复;如果添加相同的key,后面的value会替换前面的value(key不会替换)
- key 值常用 String 类型
- key 和 value 之间存在单向一对一关系,通过 key 总能找到对应的 value

3.2、方法

- 添加、删除、修改
| 方法 | 返回类型 | 说明 |
|---|---|---|
| put(Object key , Object value) | Object | 添加(或替换,key相同时)指定的key-value |
| putAll(Map m) | void | 把m中的所有key-value添加到当前map中 |
| remove(Object key) | Object | 移除指定key的key-value |
| clear() | void | 清空所有 |
- 元素查询
| 方法 | 返回类型 | 说明 |
|---|---|---|
| get(Object key) | Object | 获取指定key对应的value |
| containsKey(Object key) | boolean | 是否包含指定的key |
| containsValue(Object value) | boolean | 是否包含指定的value |
| size() | int | key-value对的个数 |
| isEmpty() | boolean | 是否为空 |
| equals(Object obj) | boolean | 判断当前map和参数ojb是否相等 |
- 元视图操作
| 方法 | 返回类型 | 说明 |
|---|---|---|
| keySet() | Set | 返回所有key构成的Set集合 |
| values() | Collection | 返回所有value构成的Collection集合 |
| entrySet() | Set | 返回所有key-value对构成的Set集合 集合中的元素(Map.Entry)可以调用:getKey()、getValue() |
3.3、三组(六种)遍历方式
Map map = new HashMap();
map.put("1","a1");
map.put("2","a2");
map.put("3","a3");
map.put("4","a4");
map.put("5","a5");
-
1、keySet()
-
增强for循环
Set set = map.keySet(); for (Object key : set) { System.out.println(key+" - "+map.get(key)); } -
迭代器
Iterator iterator = set.iterator(); while (iterator.hasNext()) { Object key = iterator.next(); System.out.println(key +" - "+map.get(key)); }
-
-
2、values()
只能取得value,不能取得key
-
增强for循环
Collection values = map.values(); for (Object value : values) { System.out.println(value); } -
迭代器
Iterator iterator1 = values.iterator(); while (iterator1.hasNext()) { Object value = iterator1.next(); System.out.println(value); }
-
-
3、entrySet()
entrySet集合中是key-value键值对(HashMap$Node)
HashMap$Node 实现了 Map.Entry 接口
Map.Entry 接口中有 getKey() 和 getValue()
遍历时需要进行类型强制转换为 Map.Entry
-
增强for循环
Set entrySet = map.entrySet(); for (Object entry : entrySet) { Map.Entry e = (Map.Entry) entry; System.out.println(e.getKey()+" - "+e.getValue()); } -
迭代器
Iterator iterator2 = entrySet.iterator(); while (iterator2.hasNext()) { Object entry = iterator2.next(); Map.Entry e = (Map.Entry)entry; System.out.println(e.getKey()+ " - "+e.getValue()); }
-
3.4、子类
1、HashMap
HaspMap知识点可以参考HashSet、Map介绍和方法
HashSet底层也是HashMap
1.1、介绍
-
HaspMap是Map接口使用频率最高的实现类
-
以key-value键值对存放数据;key 和 value 可以是任何引用类型的数据,会封装到 HashMap$Node 对象中(Map接口的特性)
//HashMap$Node 实现了 Map.Entry 接口 static class Node<K,V> implements Map.Entry<K,V> {} -
key 可以是为null,但只能有一个(不能重复);value可以为null,可以有多个
-
如果添加相同的key,后面的会替换前面的key-value(key不会替换,value会替换)
-
存取顺序不一致。底部有哈希表,会以散列的形式分布于哈希表中。
- keySet:所有key构成的集合 (Set)
- 无序的,不可重复。key所在的类要重写:equals() 和 hashCode()
- values:所有value构成的集合 (Collection)
- 无序的,可以重复。value所在的类要重写:equals()
- entrySet:所有entry构成的集合
- 无序的,不可重复
- keySet:所有key构成的集合 (Set)
-
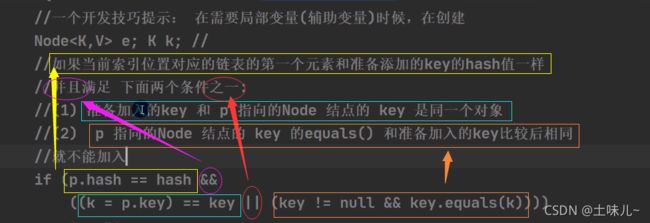
HashMap 判断两个 key 相等的标准:
- key 的hashCode值相等 (必须满足)
- key 值相等 或者 key的equals()为true (必须满足其一)
p.hash == hash //key 的hashCode值相等 && //前后同时满足 ( (k = p.key) == key //key 值相等 || //子条件满足其一 (key != null && key.equals(k))//equals()为true )所以 key 所在的类要重写:equals() 和 hashCode()
-
HashMap 判断两个 value 相等的标准:两个 value 的 equals() 比较结果为 true
所以 value 所在的类要重写:equals()
-
线程不安全。没有实现同步,没有synchronized
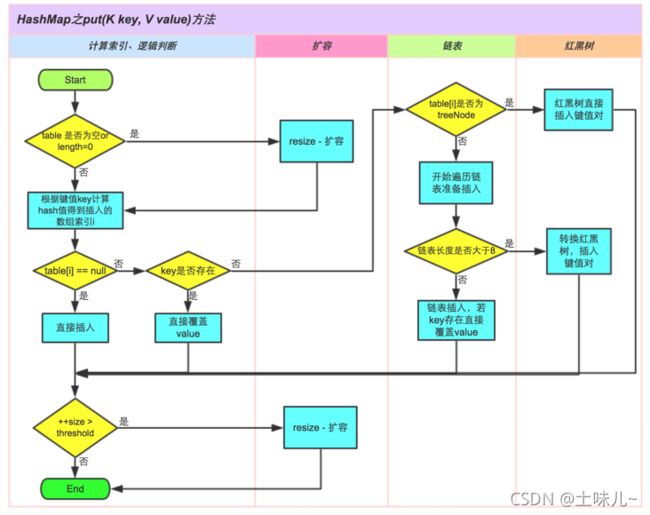
1.2、扩容机制
和HashSet一样
HashSet 底部也是 HashMap
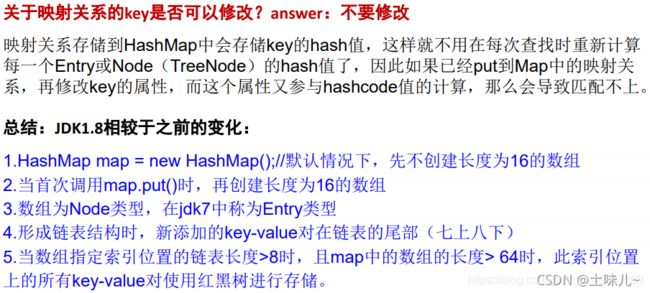
- new HashMap():底层创建数组,但为 null
- 首次调用 put() 方法时,数组扩容为 16
- 负载因子为:0.75,每次按2倍扩容。即32 – 64
- (jdk8中底层结构:数组+链表+红黑树)当数组的某一个索引位置上的元素以链表形式存在的数据个数 > 8 且当前数组的长度 >64 时,此时此索引位置上的所有数据改为使用红黑树存储

1.3、底层原理 JDK1.8

1.4、JDK1.8新特性
1.5、重要属性
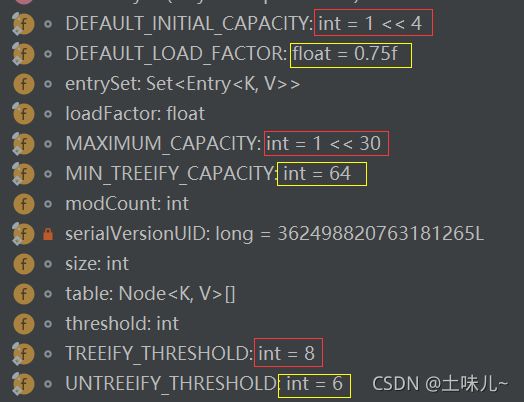
| 名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| DEFAULT_INITIAL_CAPACITY | int | 16 (1 << 4) | HashMap默认容量 |
| MAXIMUM_CAPACITY | int | 2^30 (1 << 30) | HashMap最大支持容量 |
| DEFAULT_LOAD_FACTOR | float | 0.75f | 默认加载因子(填充因子) |
| TREEIFY_THRESHOLD | int | 8 | 链表长度大于该默认值时转红黑树 只是转红黑树的两个条件之一 |
| UNTREEIFY_THRESHOLD | int | 6 | 红黑树中数量小于该默认值时转链表 |
| MIN_TREEIFY_CAPACITY | int | 64 | 被树化时的哈希表最小容量 只是转红黑树的两个条件之一 |
| table | Node |
- | 存储元素的数组,2的n次幂 |
| entrySet | Set |
- | 存储元素的集合 存储的只是引用地址,为了方便遍历 |
| size | int | - | HaspMap中key-value的数量 |
| modCount | int | - | HaspMap扩容和结构改变的次数 |
| threshold | int | - | 扩容的临界值 (=容量X填充因子) |
| loadFactor | float | - | 自定义加载因子(填充因子) |
1.6、面试常见问题
谈谈你对HashMap中put/get方法的认识?如果了解再谈谈HashMap的扩容机制?默认大小是多少?什么是负载因子(或填充比)?什么是吞吐临界值(或阈值、threshold)?

2、TreeMap
参考TreeSet,有详细介绍
TreeSet 底层是 TreeMap
- TreeMap 存储 key-value 对时,需要根据 key-value 对进行排序,使 key-value 处于有序状态
- TreeMap 底层使用红黑树结构存储数据
- 有两种排序方法:
- 自然排序 (默认)
- 定制排序
- TreeMap 判断key相等的标准:两个 key 通过 compareTo() 方法或者 compare() 方法返回0
TreeMap map = new TreeMap(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
if (o1 instanceof Person && o2 instanceof Person){
Person p1 =(Person) o1;
Person p2 =(Person) o2;
return Integer.compare(p1.getAge(),p2.getAge());
}
throw new RuntimeException("输入的类型不匹配");
}
});
Person p1 = new Person("jack",22);
Person p2 = new Person("Tom",21);
Person p3 = new Person("DYQ",20);
map.put(p1,90);
map.put(p2,87);
map.put(p3,88);
-
HashMap 和 TreeMap 的去重机制
和HashSet 、reeSet 的去重机制一样
3、Hashtable
| 比较 | Hashtable | HashMap |
|---|---|---|
| 版本 | JDK1.0开始 | JDK1.2开始 |
| key、value 是否可以为null |
不可以 key、value都不能为null |
可以 key最多有一个null value可以有多个null |
| key-value 是否可以重复 |
不可以 | 不可以 |
| key、value 判断相等标准 |
一样 key (hashCode()、equals()) value (equals()) |
一样 key (hashCode()、equals()) value (equals()) |
| 存取顺序 | 不一致 | 不一致 |
| 加载因子 | 0.75 | 0.75 |
| 默认初始大小 | 11 | 初始为null,首次put为16 |
| 扩容机制 | 2倍加1 (* 2 + 1) 即 11 * 2 + 1 = 23 |
2倍 (* 2) 即16 - 32 - 64 |
| 线程安全性 | 安全 | 不安全 |
| 效率 | 较低 | 高 |

4、Properties
- Properties 类是 Hashtable 的子类,用于处理配置文件
- key、value 都是字符串类型
- 存取数据时,建议用 setProperty(String key,String value) 方法和 getProperty(String key) 方法
读取资源配置文件
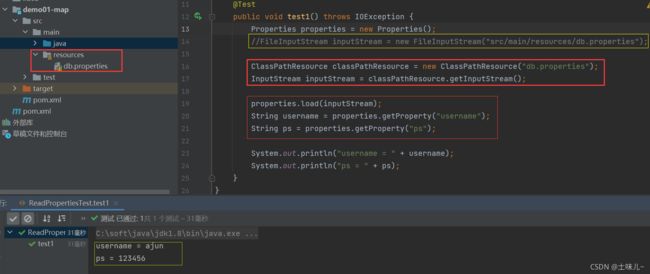
- db.properties
username = ajun
ps = 123456
@Test
public void test1() throws IOException {
Properties properties = new Properties();
//方式一
//FileInputStream inputStream = new FileInputStream("src/main/resources/db.properties");
//方式二
ClassPathResource classPathResource = new ClassPathResource("db.properties");
InputStream inputStream = classPathResource.getInputStream();
properties.load(inputStream);
String username = properties.getProperty("username");
String ps = properties.getProperty("ps");
System.out.println("username = " + username);
System.out.println("ps = " + ps);
}
5、LinkedHashMap
参考LinkedHashSet
LinkedHashSet 底层为 LinkedHashMap
- LinkedHashMap 是 HashMap 的子类
- 有双向链表,存入和取出顺序是一致的,表面上看是有序的,但在内部哈希数组中仍然是散列分布,无序的
6、IdentifyHashMap
-
IdentityhashMap 中key是对象的引用
-
通过判断引用是否相同,来判断key是否相同,放入的对象值可以相同,只要两个对象的引用不相同就行了, 如果作为key的引用相同,新放入的值会覆盖原有的值 ,并把旧的值(value),返回
-
比如对于要保存的key,k1和k2,当且仅当 k1== k2 的时候,IdentityHashMap才会相等,而对于HashMap来说,相等的条件则是:对比两个key的hashCode相等,并且key值相等或equals()相等
-
IdentityHashMap不是Map的通用实现,它有意违反了Map的常规协定。并且IdentityHashMap允许key和value都为null。
-
同HashMap,IdentityHashMap也是无序的,并且该类不是线程安全的,如果要使之线程安全,可以调用Collections.synchronizedMap(new IdentityHashMap(…))方法来实现。
-
IdentityHashMap重写了equals和hashcode方法,不过需要注意的是hashCode方法并不是借助Object的hashCode来实现的,而是通过System.identityHashCode方法来实现的。hashCode的生成是与key和value都有关系的,这就间接保证了key和value这对数据具备了唯一的hash值。同时通过重写equals方法,判定只有key值全等情况下才会判断key值相等。这就是IdentityHashMap与普通HashMap不同的关键所在。
4、集合的比较

| 比较 | 初始容量 | 扩容机制 | 加载因子 | 说明 |
|---|---|---|---|---|
| ArrayList | 0 (添加第一个时 10) | 1.5 倍 | 1 (全部用完才扩容) | |
| LinkedList | - | - | - | 底层双向链表,无需扩容 |
| Vector | 10 | 2 倍 | 1 (全部用完才扩容) | |
| HashSet | 0 (添加第一个时 16) | 2 倍 | 0.75 | 底层为 HashMap |
| LinkedHashSet | 0 (添加第一个时 16) | 2 倍 | 0.75 | 继承自 HashSet |
| TreeSet | - | - | - | 底层 TreeMap |
| HashMap | 0 (添加第一个时 16) | 2 倍 | 0.75 | 树化(链表>8、数组>64) |
| LinkedHashMap | 0 (添加第一个时 16) | 2 倍 | 0.75 | 继承自 HashMap |
| TreeMap | - | - | - | 底层红黑树,无需扩容 |
| Hashtable | 11 | 2 倍 + 1 | 0.75 | 11 - 23 - 47 |
5、集合的选择

6、工具类
1)Arrays
(1)概述

(2)常用方法(静态)
-
void Arrays.sort(Object[] array)
对数组按照升序排序
-
List Arrays.asList(数组)
返回由指定数组支持的一个固定大小的列表
2) Collections
- Collections 是一个操作 Set、List、Map 等集合的工具类
- Collections 中提供了一系列静态的方法对集合元素进行排序、查询、修改等操作
(1)排序
操作对象为List集合,是有序的
静态方法,返回void
| 方法 | 返回 | 属性 | 说明 |
|---|---|---|---|
| reverse(List list) | void | static | 反转List集合中元素的顺序 |
| shuffle(List list) | void | static | 随机排序(可用于抽奖) |
| sort(List list) | void | static | 升序排序(自然顺序) |
| sort(List list, Comparator c) | void | static | 按比较器c的规则排序 |
| swap(List list, int i, int j) | void | static | 把List中i、j位置的元素交换顺序 |
(2)查找、替换
| 方法 | 返回 | 属性 | 说明 |
|---|---|---|---|
| max(Collection coll) | Object | static | 最大元素(按自然顺序) |
| max(Collection coll, Comparator comp) | Object | static | 最大元素(按比较器comp指定规则的顺序) |
| min(Collection coll) | Object | static | 最小元素(按自然顺序) |
| min(Collection coll, Comparator comp) | Object | static | 最小元素(按比较器comp指定规则的顺序) |
| frequency(Collection c, Object o) | int | static | 元素o在集合c中出现的次数 |
| copy(List dest, List src) | void | static | 将List集合src中的内容复制到dest |
| replaceAll(List list, T oldVal, T newVal) | boolean | static | 用新值newVal替换list中的所有旧值 oldVal |
(3)同步控制
- Collections 类中提供了多个 synchronizedXxx() 方法,可把指定的集合包装成线程同步的集合,从而可以解决多线程并发访问集合时的线程安全
- 都是 static 方法
