Redis学习笔记--Redis基本类型及其数据结构
什么是Redis?
Redis(全称:Remote Dictionary Server 远程字典服务)是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。它通常被称为数据结构服务器,因为值(value)可以是 字符串(String), 哈希(Hash), 列表(list), 集合(sets) 和 有序集合(sorted sets)等类型。
redisObject
Redis的key是顶层模型,它的value是扁平化的。Redis中,所有的value都是一个object,它的结构如下:
typedef struct redisObject {
unsigned [type] 4;
unsigned [encoding] 4;
unsigned [lru] REDIS_LRU_BITS;
int refcount;
void *ptr;
} robj;简单介绍一下这几个字段:
-
type:数据类型,就是我们熟悉的string、hash、list等。
-
encoding:内部编码,其实就是本文要介绍的数据结构。指的是当前这个value底层是用的什么数据结构。因为同一个数据类型底层也有多种数据结构的实现,所以这里需要指定数据结构。
-
REDIS_LRU_BITS:当前对象可以保留的时长。
-
refcount:对象引用计数,用于GC。
-
ptr:指针,指向以encoding的方式实现这个对象的实际地址。
string
在Redis内部,string类型有两种底层储存结构。Redis会根据存储的数据及用户的操作指令自动选择合适的结构:
-
int:存放整数类型;
-
SDS:存放浮点、字符串、字节类型;SDS: 简单动态字符串 simple dynamic string
SDS
SDS的内部数据结构:
typedef struct sdshdr { // buf中已经占用的字符长度 unsigned int len; // buf中剩余可用的字符长度 unsigned int free; // 数据空间 char buf[]; }可见,其底层是一个char数组。buf最大容量为512M,里面可以放字符串、浮点数和字节。所以你甚至可以放一张序列化后的图片。它为什么没有直接使用数组,而是包装成了这样的数据结构呢?
因为buf会有动态扩容和缩容的需求。如果直接使用数组,那每次对字符串的修改都会导致重新分配内存,效率很低。
buf的扩容过程如下:
-
如果修改后len长度将小于1M,这时分配给free的大小和len一样,例如修改过后为10字节, 那么给free也是10字节,buf实际长度变成了10 + 10 + 1 = 21byte
-
如果修改后len长度将大于等于1M,这时分配给free的长度为1M,例如修改过后为30M,那么给free是1M.buf实际长度变成了30M + 1M + 1byte
-
惰性空间释放指的是当字符串缩短时,并没有真正的缩容,而是移动free的指针。这样将来字符串长度增加时,就不用重新分配内存了。但这样会造成内存浪费,Redis提供了API来真正释放内存。

list
list底层有两种数据结构:链表linkedlist和压缩列表ziplist。当list元素个数少且元素内容长度不大时,使用ziplist实现,否则使用linkedlist。
链表
Redis使用的链表是双向链表。为了方便操作,使用了一个list结构来持有这个链表。如图所示:
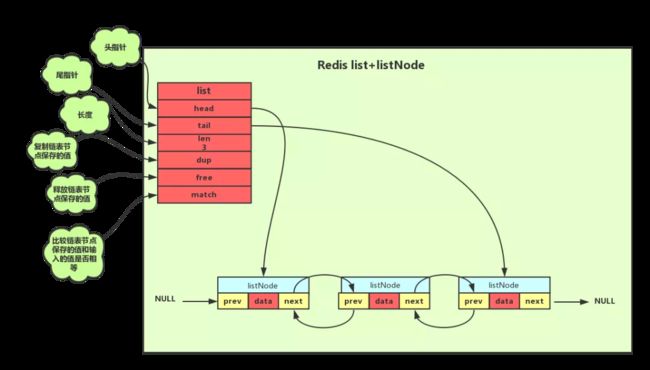
typedef struct list{
//表头节点
listNode *head;
//表尾节点
listNode *tail;
//链表所包含的节点数量
unsigned long len;
//节点值复制函数
void *(*dup)(void *ptr);
//节点值释放函数
void *(*free)(void *ptr);
//节点值对比函数
int (*match)(void *ptr,void *key);
}list;
data存的其实也是一个指针。链表里面的元素是上面介绍的string。因为是双向链表,所以可以很方便地把它当成一个栈或者队列来使用。
压缩列表
与上面的链表相对应,压缩列表有点儿类似数组,通过一片连续的内存空间,来存储数据。不过,它跟数组不同的一点是,它允许存储的数据大小不同。每个节点上增加一个length属性来记录这个节点的长度,这样比较方便地得到下一个节点的位置。
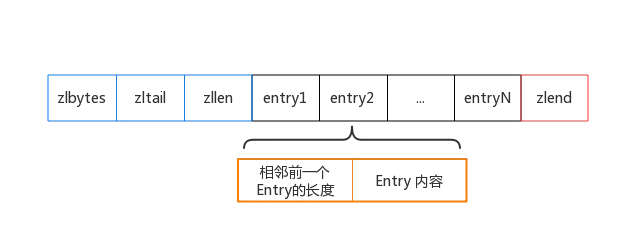
上图的各字段含义为:
-
zlbytes:列表的总长度
-
zltail:指向最末元素
-
zllen:元素的个数
-
entry:元素的内容,里面记录了前一个Entry的长度,用于方便双向遍历
-
zlend:恒为0xFF,作为ziplist的定界符
压缩列表不只是list的底层实现,也是hash的底层实现之一。当hash的元素个数少且内容长度不大时,使用压缩列表来实现。
hash
hash底层有两种实现:压缩列表和字典(dict)。压缩列表刚刚上面已经介绍过了,下面主要介绍一下字典的数据结构。
字典
字典其实就类似于Java语言中的Map,Python语言中的dict。与Java中的HashMap类似,Redis底层也是使用的散列表作为字典的实现,解决hash冲突使用的是链表法。Redis同样使用了一个数据结构来持有这个散列表: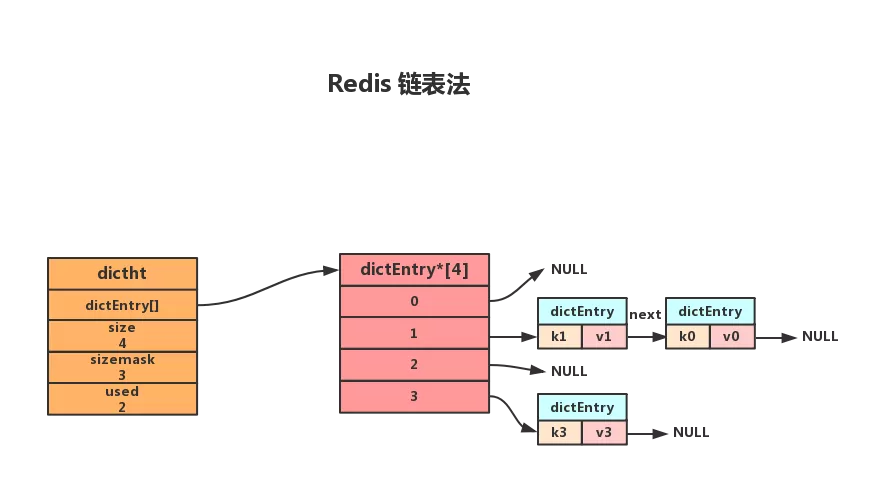
在键增加或减少时,会扩容或缩容,并且进行rehash,根据hash值重新计算索引值。那如果这个字典太大了怎么办呢?
为了解决一次性扩容耗时过多的情况,可以将扩容操作穿插在插入操作的过程中,分批完成。当负载因子触达阈值之后,只申请新空间,但并不将老的数据搬移到新散列表中。当有新数据要插入时,将新数据插入新散列表中,并且从老的散列表中拿出一个数据放入到新散列表。每次插入一个数据到散列表,都重复上面的过程。经过多次插入操作之后,老的散列表中的数据就一点一点全部搬移到新散列表中了。这样没有了集中的一次一次性数据搬移,插入操作就都变得很快了。这个过程也被称为渐进式rehash。
set
set里面没有重复的集合。set的实现比较简单。如果是整数类型,就直接使用整数集合intset。使用二分查找来辅助,速度还是挺快的。不过在插入的时候,由于要移动元素,时间复杂度是O(N)。
如果不是整数类型,就使用上面在hash那一节介绍的字典。key为set的值,value为空。
zset
zset是可排序的set。与hash的实现方式类似,如果元素个数不多且不大,就使用压缩列表ziplist来存储。不过由于zset包含了score的排序信息,所以在ziplist内部,是按照score排序递增来存储的。意味着每次插入数据都要移动之后的数据。
跳表
跳表(skiplist)是另一种实现dict的数据结构。跳表是对链表的一个增强。我们在使用链表的时候,即使元素的有序排列的,但如果要查找一个元素,也需要从头一个个查找下去,时间复杂度是O(N)。而跳表顾名思义,就是跳跃了一些元素,可以抽象多层。
如下图所示,比如我们要查找8,先在最上层L2查找,发现在1和9之间;然后去L1层查找,发现在5和9之间;然后去L0查找,发现在7和9之间,然后找到8。
当元素比较多时,使用跳表可以显著减少查找的次数。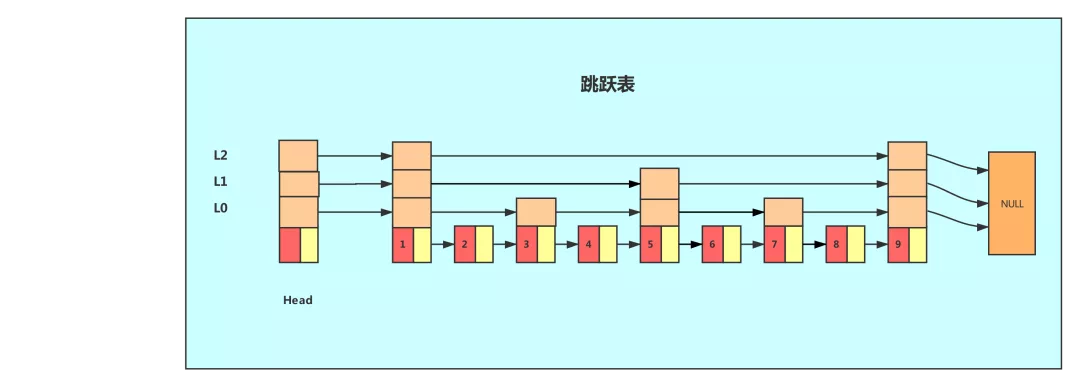
同list类似,Redis内部也不是直接使用的跳表,而是使用了一个自定义的数据结构来持有跳表。下图左边蓝色部分是skiplist,右边是4个zskiplistNode。zskiplistNode内部有很多层L1、L2等,指针指向这一层的下一个结点。BW是回退指针(backward),用于查找的时候回退。然后下面是score和对象本身object。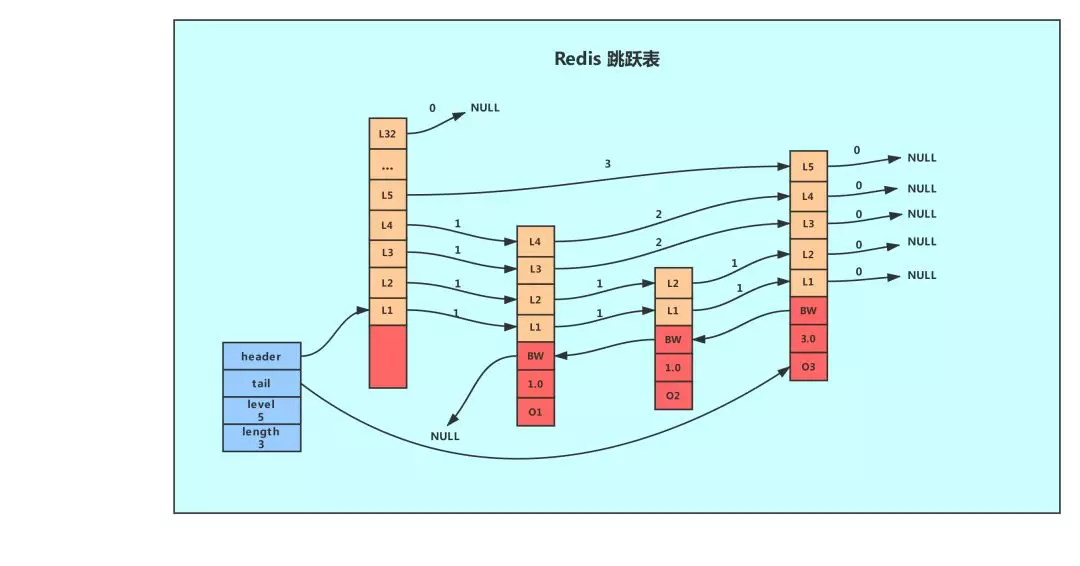
总结
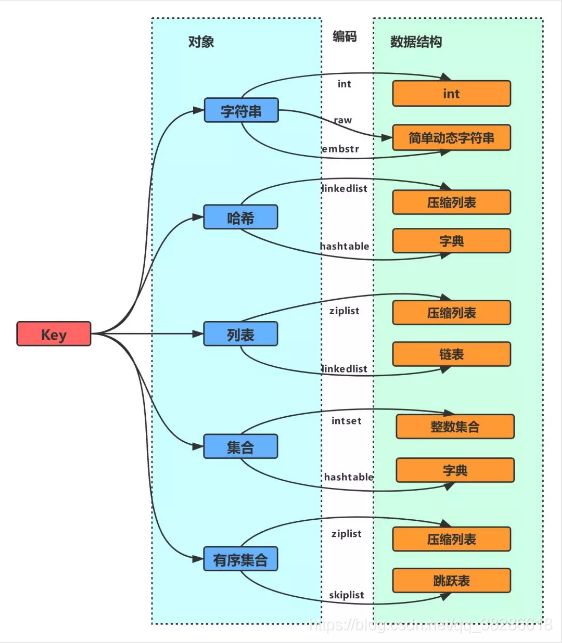
Redis一共分为5中基本数据类型:String,Hash,List,Set,ZSet.Redis对外暴露的是对象(数据类型),而每个对象都是用一个redisObject持有,通过不同的编码,映射到不同的数据结构。从最开始的那个图可以知道,有时候不同对象可能会底层使用同一种数据结构,比如压缩列表和字典等。
在了解数据结构后,我们就能够更清楚应该选用什么样的对象,出现问题时应该如何优化了。
参考文章
本文主要参考了博客主“崖边小生”的Redis系列文章。博客链接:https://www.cnblogs.com/hunternet/tag/Redis/