论文阅读笔记《Generalized and Incremental Few-Shot Learning……》
Generalized and Incremental Few-Shot Learning by Explicit Learning and Calibration without Forgetting
0 第一次写CSDN博客,记录一下自己看过的论文
本论文出自ICCV2021
1 对论文的理解
这篇文章主要是解决了一个generalized few-shot learning(GFSL)的一个问题,GFSL是在base class 的基础上增加一个novel class 然后进行fune-tune学习的一个过程,而incremental few-shot learning(IFSL)是在base class的基础上增加n个novel class然后再学习的一个过程。作者在本文中提出了一种三阶段的GFSL的方法,很显然,我们增加novel class的个数,GFSL就变成了IFSL
2 方法
一,提出了Figure 3所示的度量方法

B/B 表示不考虑novel class的影响,只训练base class然后进行测试
N/N 表示不考虑base class的影响,对novel class学习后的测试
B/J 表示考虑novel class的影响,在base class上的测试
N/J 表示考虑base class的影响,在novel class上的测试
二,整体架构
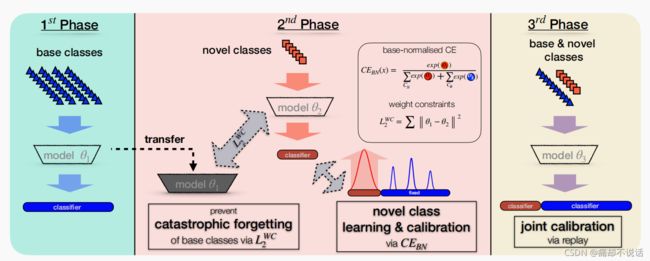
1st phase:
在第一阶段,用大量的数据训练一个分类模型,模型参数![]() 1,这些数据也就是base class,paper用的是ResNet18,这里对应的就是B/B,因为此时还没有novel class,只是对base class进行训练和测试
1,这些数据也就是base class,paper用的是ResNet18,这里对应的就是B/B,因为此时还没有novel class,只是对base class进行训练和测试
2st phase:
在第二阶段,要做两件事,第一件事就是学习novel class,第二件事是防止灾难性遗忘
学习novel class比较简单,通过一个cross entropy实现:

这里CN是novel class的个数,如果x属于第i类则yi=1,否则yi=1,这里需要注意的是oi是logit值
其实我们发现,这个loss其实就是对应N/N的,因为只考虑的novel class,但是我们要解决的是小样本增量学习(IFSL)的问题,显然不能只考虑N/N或者B/B,那么N/J怎么实现呢?看下面的loss:
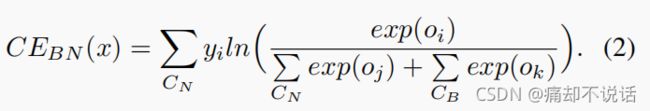
这里相比(1)在分母多了一个CB,顾名思义这就是base class 的数量,也就是说,在对novel class进行测试的时候,把base class 也考虑进去,这样就构建了N/J 。
众所周知,增量学习一个很重要的问题是灾难性遗忘(catastrophic forgetting),很多文章解决这个问题才用只是蒸馏的方法,而本文采用的是L2惩罚项来实现在学习novel class的同时不忘记学习过的base class的知识,公式如下:
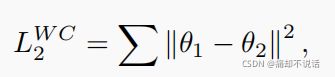
这里![]() 1就是第一阶段的参数,需要注意的是,
1就是第一阶段的参数,需要注意的是,![]() 2是第二阶段的参数,但是只是backbone的参数,并不包括分类器。这里为什么使用L2 normal作为惩罚项,可以看他的blog(https://blog.csdn.net/zouxy09/article/details/24971995https://blog.csdn.net/zouxy09/article/details/24971995
2是第二阶段的参数,但是只是backbone的参数,并不包括分类器。这里为什么使用L2 normal作为惩罚项,可以看他的blog(https://blog.csdn.net/zouxy09/article/details/24971995https://blog.csdn.net/zouxy09/article/details/24971995 https://blog.csdn.net/zouxy09/article/details/24971995),个人觉得写的很不错。
https://blog.csdn.net/zouxy09/article/details/24971995),个人觉得写的很不错。
总loss如下:
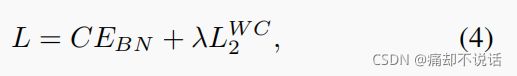
3st phase
这里就比较简单了,在第一、二阶段我们解决了B/B,N/N,N/J的问题,也就是说我们已经能够保证novel class在联合空间(N/J)的一个良好表现,但是base class在联合空间(B/J)的表现我们并没有处理,只是使用L2进行防止学习到的知识丢失,如下图第二阶段蓝色实线,base class在联合空间的表现一直下降
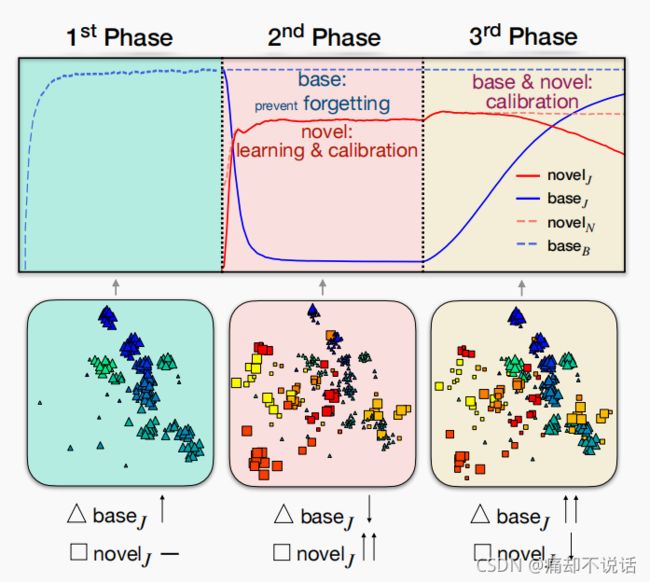
所以在第三阶段,我们把novel class 和base class联合起来训练,当然是基于第二阶段的,不然前面不就白干了!!!文章采用balance replay,具体方法是,用一个增量学习最常用的exemplars存储base class,然后构建一个新的训练集,这个训练集包含所有novel class的samples和从每一个base class随机选取一个samples,用这个新的训练集训练一个分类器,因为之前有L2防止遗忘,所以base class 在联合空间B/J(上图蓝色实线)的表现会迅速提高,虽然会使得N/J有所下降,但是无伤大雅。这样的话所有的表现都不错了。
GFSL TO IFSL
前面说了整体的架构,解决的是GFSL的问题,就是只做一次增量,而IFSL是从数据流中不断地学习,那么怎么把这种方法运用到IFSL上呢?其实很简单,第一阶段不变,作为base class,在第二阶段实现增量学习,比如5个task(5次增量),在5个task完成后,接一个第三阶段来balance replay就好啦!
3 说明
本blog只作为自己的阅读笔记,方便以后复习查阅。