人工智能大体浏览(机器学习,回归分类算法,神经网络等)
文章目录
- 人工智能
-
- 1、人工智能是什么,如何学习人工智能
- 2、三个学派概括
-
-
- ==连接主义==
-
- 3、范围
- 3、GAN(生成对抗网络)
- 4、深度学习软件
- 5、人工智能的三个流派
- 机器学习
-
- 1、机器学习是什么
- 2、机器学习的缺点
- 3、机器学习的模型
- 4、机器学习的术语
- 5、监督学习【有监督学习】
- 6、无监督学习
- 7、半监督学习
- 8、强化学习
- 8.5、回归与分类的概念
-
- 1、性能度量
- 2、回归基线方法
- 3、分类基线方法
- 4、防止过拟合的方法
- 9、线性回归——回归 方法
-
- 1、基本介绍
- 2、数据的概念
- 3、模型的定义
- 4、线性回归算法讲解
- 10、logistics回归(逻辑回归)——分类方法
-
- 逻辑回归分类器
- 11、决策树——分类与回归算法
-
- 1、决策树常用算法
- 2、计算信息增益
- 11、聚类分析
-
- 1、聚类分析是什么
- 2、聚类算法
-
- K-Means(K均值)聚类法
- 12、神经网络
- 13、各种算法的优缺点
- 14、题型解释
人工智能
1、人工智能是什么,如何学习人工智能
是什么:让机器人具备人的思维和意识
**如何学习:**首先你需要良好的高数知识和线性代数知识,逻辑思维能力要很强的同时也要有很强的抽象能力,不然进度会非常缓慢,学习前建议先把高数和线代的知识补补
2、三个学派概括
-
行为主义
- 是基于控制论的,是在构建感知、动作的控制系统。单脚站立是 行为主义一个典型例子,通过感知要摔倒的方向,控制两只手的动作,保持身体 的平衡。这就构建了一个感知、动作的控制系统,是典型的行为主义。
-
符号主义
- 基于算数逻辑表达式。即在求解问题时,先把问题描述为表达式, 再求解表达式。例如在求解某个问题时,利用 if case 等条件语句和若干计算公式 描述出来,即使用了符号主义的方法,如专家系统。符号主义是能用公式描述的 人工智能,它让计算机具备了理性思维。
-
连接主义
- **人工神经网络,**仿造人脑内的神经元连接关系,使人类不仅具备理性思维,还具备无法用公式描述的感性思维,如对某些知识产生记忆。
3、范围
人工智能>机器学习>深度学习
深度学习是人工智能时代的操作系统
3、GAN(生成对抗网络)
原理: 一个神经网络负责生成虚拟图像,另一个神经网络负责鉴定假图像。 两者相互对抗,直到生成最优结果
4、深度学习软件
sklearn(机器学习,第三方Python机器学习编程库)
paddlepaddele(百度推出)免费的资源(Gpu)
Tensorflow(谷歌推出深度学习平台)、colab是谷歌实验室
pytorch(facebook脸书推出)
5、人工智能的三个流派
编写相应程序实现相应的功能,实现相应的人工智能系统。 适合不太复杂,人类认识的很清楚的系统 —— 可以理解为对应行为主义。
专家通过分析给出决策规则,如 if then 当然,还有搜索算法。搜索算法中有两种情况,一是数据中包含答案,在数据中搜索答案,主要是设计搜索算法;二是没有答案,搜索一个距离目标最近的答案。 专家系统(符号主义)需要专家参与。
机器学习——连接主义: 建立模型,对数据进行学习,实现对未来的预测。不需要像行为主义需要了解机制、不需要像符号主义的专家系统需要专家参与。
机器学习
1、机器学习是什么
- 建立==模型==,对数据进行学习,实现对未来的预测。
- 机器学习是一个从训练集中学习出算法的研究领域。
- 属于人工智能的第三个流派——连接主义
- 深度学习是机器学习中的一个分支,是目前最流行的建模方法
- 机器学习可以看做是基于数据的方法,和大数据分析有交叉。
2、机器学习的缺点
- 模型的精度与数据量有关,需要大量的数据才能获得较好的模型;
- 能耗很大; 消耗的算力很大
- 模型的可解释性差
3、机器学习的模型
- Linear Regression(线性回归)最常用
- Logistics Regression(逻辑回归)现在很流行
- Decision Tree(决策树)
- Neural Network(神经网络)现在很流行
- K-Nearest Neighbors(K近邻)
- K-Means(K-平均)
4、机器学习的术语
-
标签 label 标记
即所要预测的结果是什么,如回归结果的y,分类问题中的分类结果,每一个类。
-
特征feature
事物的固有属性,做出判断的依据。如鸢尾花分类问题中,花瓣、花蕊等。一个事物具有N个特征,这些组成了事物的特性,作为机器学习中识别、学习的基本依据。
特征是机器学习的输入变量,如线性回归中的x。 -
样本example
分为有标签样本和无标签样本
有标签样本
同时包含特征和标签
如房价预测问题,房屋年龄、房屋大小、房屋价格这三个组成的样本为有标签样本。无标签样本
只含有特征,不含有标签
房价预测问题,房屋年龄,房屋大小这两个组成的样本为无标签样本。(此类样本可以用于测试训练后的模型,将样本输入后得到预测值,与原标签相比较,衡量模型的预测效果) -
分类(classification):预测是离散值,比如把人分为好人和坏人之类的学习任务
-
回归(regression):预测值是连续值,比如你的好人程度达到了0.9,0.6之类的
-
二分类(binary classification):只涉及两个类别的分类任务
-
正类(positive class):二分类里的一个
-
反类(negative class):二分类里的另外一个
-
多分类(multi-class classification):涉及多个类别的分类
-
测试(testing):学习到模型之后对样本进行预测的过程
-
测试样本(testing sample):被预测的样本
-
聚类(clustering):把训练集中的对象分为若干组
-
簇(cluster):每一个组叫簇
-
监督学习(supervised learning):典范–分类和回归
-
无监督学习(unsupervised learning):典范–聚类
https://zhuanlan.zhihu.com/p/152408012
更多术语请点击链接查看
5、监督学习【有监督学习】
通过已有的训练样本去训练得到一个最优模型,再利用这个模型将所有的输入映射为相应的输出,对输出进行简单的判断从而实现预测和分类的目的,也就具有了对未知数据进行预测和分类的能力。简单来说,就像有标准答案的练习题,然后再去考试,相比没有答案的练习题然后去考试准确率更高。监督学习中的数据中是提前做好了分类信息的, 它的训练样本中是同时包含有特征和标签信息的,因此根据这些来得到相应的输出。
有监督算法常见的有:线性回归算法、BP神经网络算法、决策树、支持向量机、KNN等。
特征:X 标签 Y
有监督学习中,比较典型的问题可以分为:输入变量与输出变量均为连续的变量的预测问题称为回归问题(Regression),输出变量为有限个离散变量的预测问题称为分类问题(Classfication),输入变量与输出变量均为变量序列的预测问题称为标注问题。
6、无监督学习
概念:
训练样本的标签信息未知, 目标是通过对无标记训练样本的学习来揭示数据的内在性质及规律,为进一步的数据分析提供基础,此类学习任务中研究最多、应用最广的是"聚类" (clustering),聚类目的在于把相似的东西聚在一起,主要通过计算样本间和群体间距离得到。深度学习和PCA都属于无监督学习的范畴。
无监督算法常见的有:密度估计(densityestimation)、异常检测(anomaly detection)、层次聚类、EM算法、K-Means算法(K均值算法)、DBSCAN算法 等。
应用:
比较典型的是一些聚合新闻网站(比如说百度新闻、新浪新闻等),利用爬虫爬取新闻后对新闻进行分类的问题,将同样内容或者关键字的新闻聚集在一起。所有有关这个关键字的新闻都会出现,它们被作为一个集合,在这里我们称它为聚合(Clustering)问题。
7、半监督学习
是监督学习与无监督学习相结合的一种学习方法。半监督学习使用大量的未标记数据,以及同时使用标记数据,来进行模式识别工作。
8、强化学习
强化学习(Reinforcement Learning, RL),又称再励学习、评价学习或增强学习,是机器学习的范式和方法论之一,用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题 。
强化学习把学习看作试探评价过程,Agent选择一个动作用于环境,环境接受该动作后状态发生变化,同时产生一个强化信号(奖或惩)反馈给Agent,Agent根据强化信号和环境当前状态再选择下一个动作,选择的原则是使受到正强化(奖)的概率增大。选择的动作不仅影响立即强化值,而且影响环境下一时刻的状态及最终的强化值。
8.5、回归与分类的概念
预测问题根据预测输出的类型是连续的数值,还是离散的标签,区分为回归任务和分类任务。
y=f(x,w) y的值有无穷多个 这就是一个简单的回归模型;
y=f(x,w) y的值有有限多个,最常见是两个(0,1) 这就是一个简单的分类模型
1、性能度量
对学习器的泛化性能进行评估,不仅仅需要有效可行的实验估计方法,还需要有衡量模型泛华能力的评价标准,这就是性能度量。我们通常会根据不同的业务选出适合的业务指标。
评价指标大概有
1、回归的有:RMSE(平方根误差)、MAE(平均绝对误差)、MSE(平均平方误差)、Coefficient of determination (决定系数)。
2、分类的有:精度 (Accuracy) 、召回率、精确率 (Precision) 、F值、ROC-AUC 、混淆矩阵(Confusion Matrix)、PRC。
3、聚类的有:兰德指数、互信息、轮廓系数。
2、回归基线方法
- 线性回归
3、分类基线方法
- SVM 支持向量机(Support Vector Machine, SVM) 二元分类
- K-Means算法最最基础的分类基线方法(无监督学习,聚类算法)
- KNN 邻近算法,或者说K最邻近(KNN,K-NearestNeighbor) ,最最基础的分类基线方法(监督学习技术)
- Logistic回归
- logistic回归的因变量可以是二分类的,也可以是多分类的,但是二分类的更为常用,也更加容易解释,多类可以使用softmax方法进行处理。实际中最为常用的就是二分类的logistic回归。
- 决策树 ANN算法 的方法分为三大类:基于树的方法、哈希方法、矢量量化方法。
4、防止过拟合的方法
- 给更多的数据,让模型看见更多的例外情况,不断修正自己的模型
- 限制权值,正则化方式
- 增加噪声和数据增强
- 简化模型
9、线性回归——回归 方法
1、基本介绍
- 线性:两个变量之间的关系是一次函数关系的——图象是直线,叫做线性。
- 非线性:两个变量之间的关系不是一次函数关系的——图象不是直线,叫做非线性。
- 回归:人们在测量事物的时候因为客观条件所限,求得的都是测量值,而不是事物真实的值,为了能够得到真实值,无限次的进行测量,最后通过这些测量数据计算回归到真实值,这就是回归的由来。
- 线性回归模型主要用来预测一些存在着线性关系的数据集
- 存在一个点集,用一条曲线去拟合它分布的过程。如果拟合曲线是一条直线,则称为线性回归。如果是一条二次曲线,则被称为二次回归
- 假设函数: 用数学的方法描述 自变量和因变量 之间的关系,它们之间可以是一个线性函数或非线性函数。 在本次线性回顾模型中,我们的假设函数为 Y’= wX+b ,其中,Y’表示模型的预测结果(预测房价),用来和真实的Y区分。模型要学习的参数即:w,b。
- 损失函数 : 用数学的方法衡量假设函数预测结果与真实值之间的误差。这个差距越小预测越准确,而算法的任务就是使这个差距越来越小。 建立模型后,我们需要给模型一个优化目标,使得学到的参数能够让预测值Y’尽可能地接近真实值Y。
- 优化算法:神经网络的训练就是调整权重(参数)使得损失函数值尽可能得小 所以,优化算法的最终目标是找到损失函数的最小值。 **常见的优化算法有随机梯度下降法(SGD)、Adam算法等等 **
2、数据的概念
机器学习是通过数据学习
数据集划分为训练集(确定模型的参数 约占80%) 和测试集(评价模型的效果 约占20%);
中间可以加上验证集
机器学习在训练集上学习,在测试集上测试效果。
X:数据 y:预测项(标记label)
3、模型的定义
模型就是个函数 y=f(x,w)。 其中 模型的输入为 x, 模型的输出 y, w 是模型的参数。
以前在学校的时候总是不理解数学建模比赛到底在做些什么,现在理解了,是从题目给的数据中找到数据与数据之间的关系,建立数学方程模型,得到结果解决现实问题。其实是和机器学习中的模型是一样的意思。
4、线性回归算法讲解
注意:线性回归最重要的是梯度下降算法,而梯度下降算法最重要的是偏导数的概念,具体可以查看高数偏导数那节
下面点击连接具体查看
https://www.cnblogs.com/mantch/p/10135708.html
复制链接查看
10、logistics回归(逻辑回归)——分类方法
逻辑回归(Logistic Regression)是机器学习中的一种二分类模型(主要为二分类应用,Softmax 回归是直接对逻辑回归在多分类的推广,即多元逻辑回归),由于算法的简单和高效,在实际中应用非常广泛。
Logistics算法其实本质上还是线性回归算法,但是多了一个S型函数,S型函数具体实现是f(x) = 1/(1+e^-x),S函数在神经网络中也有利用,用作设置每个节点的门限值。具体的内容可以浏览神经网络
https://baike.baidu.com/item/logistic%E5%9B%9E%E5%BD%92/2981575?fr=aladdin
点击链接查看百度百科的解释
逻辑回归分类器
https://blog.csdn.net/qustqustjay/article/details/46874527
11、决策树——分类与回归算法
决策树(decision tree)是一种基本的分类与回归方法。决策树模型呈树形结构,在分类问题中,表示基于特征对实例进行分类的过程。它可以认为是if-then规则的集合,也可以认为是定义在特征空间与类空间上的条件概率分布。
其主要优点是模型具有可读性,分类速度快。学习时,利用训练数据,根据损失函数最小化的原则建立决策树模型。预测时,对新的数据,利用决策树模型进行分类。
决策树学习通常包括3个步骤:特征选择、决策树的生成和决策树的修剪
1、决策树常用算法
- ID3 (信息增益作为节点分割的依据)
- C4.5(排名第一,其核心算法还是ID3 信息增益率作为节点分割的依据)
- CART
2、计算信息增益
https://blog.csdn.net/qq_29663489/article/details/89860279
11、聚类分析
1、聚类分析是什么
用最通俗的话可以解释为:物以类聚
聚类原本是统计学上的概念,现在属于机器学习中非监督学习的范畴,大多都被应用在数据挖掘、数据分析的领域,简单说可以用一个词概括——物以类聚。
如果把人和其他动物放在一起比较,你可以很轻松地找到一些判断特征,比如肢体、嘴巴、耳朵、皮毛等等,根据判断指标之间的差距大小划分出某一类为人,某一类为狗,某一类为鱼等等,这就是聚类。
从定义上讲,聚类就是针对大量数据或者样品,根据数据本身的特性研究分类方法,并遵循这个分类方法对数据进行合理的分类,最终将相似数据分为一组,也就是“同类相同、异类相异”。
2、聚类算法
K-Means(K均值)聚类法
1、决定要分组的数目
K-Means中的K就是要分组的数目,K均值第一步就是确定K的数目
2、随机选择K个值作为数据中心
这个数据中心的选择是完全随机的,也就是说怎么选择都无所谓 ,可以首先选用任意的K个坐标来作为数据中心
3、计算其他数值与数据中心的“距离”
这里我们要引入欧氏距离的概念,通俗点说欧氏距离就是多维空间中各个点之间的绝对距离,表明两点之间的距离远近,其公式为:
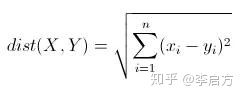
如果是普通的二维数据,这个公式就直接变成了勾股定理,因此我们算出其他6个点距离A和B的距离,谁离得更近,谁与数据中心就是同一类。
4、重新选择新的数据中心
得到了第一次分组的结果,我们再重复前两个步骤,重新选择每一组数据的数据中心。
为每一组的结果分别求出新的数据中心,可以用平均值的方法,然后再次计算每一个坐标到数据中心的距离,再次分组
5、观察最终结果
直到算出任何一次的分组情况与前一次没有发生变化, 这就说明我们的计算收敛已经结束了,不需要继续进行分组了,最终数据成功按照相似性分成了两组。
6、方法总结
简单来说,我们一次次重复这样的选择数据中心-计算距离-分组-再次选择数据中心的流程,直到我们分组之后所有的数据都不会再变化了,也就得到了最终的聚合结果。
7、优缺点
优点:
1)原理比较简单,实现也是很容易,收敛速度快。
2)聚类效果较优。
3)算法的可解释度比较强。
4)主要需要调参的参数仅仅是簇数k。
缺点:
1)K值的选取不好把握
2)对于不是凸的数据集比较难收敛(改进:基于密度的聚类算法更加适合,比如DESCAN算法)
3)如果各隐含类别的数据不平衡,比如各隐含类别的数据量严重失衡,或者各隐含类别的方差不同,则聚类效果不佳。
4) 采用迭代方法,得到的结果只是局部最优。
5) 对噪音和异常点比较的敏感
12、神经网络
只需记住神经网络中存在S型函数,而S型函数是为了限定门限值,将输入值映射成(0,1)范围内的小数即可,其训练方式是有监督训练,可以完成分类任何与回归任务。
具体查看应用
https://blog.csdn.net/as091313/article/details/79080583
13、各种算法的优缺点
https://blog.csdn.net/weixin_29563497/article/details/112075834
14、题型解释
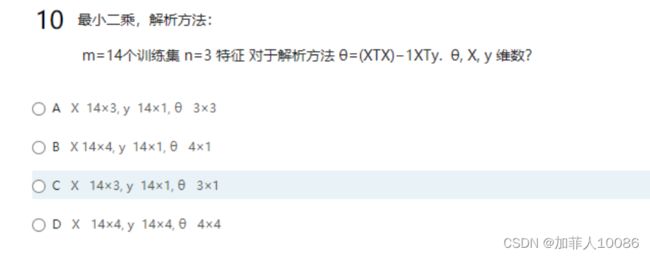
可以画出一张图
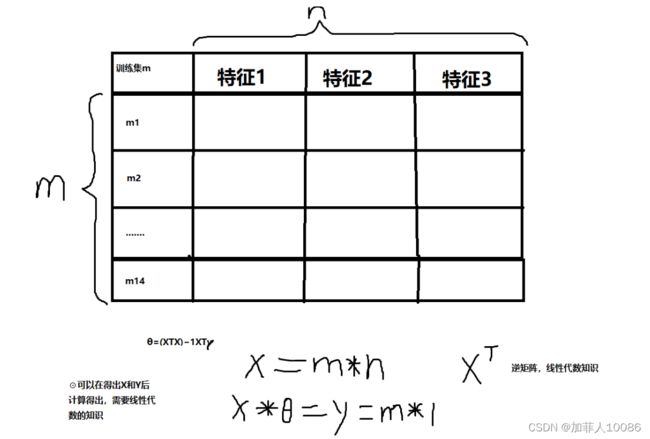
我画的图,有点抽象……不过大概是这个意思,具体的可以去下面这个链接查看
https://blog.csdn.net/artprog/article/details/51172025

卷积神经网络CNN
要想学透卷积神经网络,需要对卷积公式有了解,还是高数问题
