PIXOR Real-time 3D Object Detection from Point Clouds 中文译文
中文标题:PIXOR 点云中的实时 3D 检测器
作者:Bin Yang 等
期刊:CVPR
年份:2018
引用数:506
代码地址:https://github.com/philip-huang/PIXOR
摘要
我们解决了在自动驾驶背景下从点云实时检测 3D 对象的问题。 速度至关重要,因为检测是安全的必要组成部分。 然而,由于点云的高维数,现有的方法在计算上很昂贵。 我们通过从鸟瞰图 (BEV) 中表示场景来更有效地利用 3D 数据,并提出 PIXOR,这是一种无提议的单级检测器,可输出从像素级神经网络预测解码的定向 3D 对象估计。 输入表示、网络架构和模型优化是专门为平衡高精度和实时效率而设计的。 我们在两个数据集上验证 PIXOR:KITTI BEV 对象检测基准和大规模 3D 车辆检测基准。 在这两个数据集中,我们表明所提出的检测器在平均精度 (AP) 方面优于其他最先进的方法,同时仍以 10 FPS 运行。
1.介绍
在过去的几年里,我们看到了大量利用卷积神经网络来产生准确的 2D 对象检测的方法,通常来自单个图像 [12,11,28,4,27,23]。 然而,在自动驾驶等机器人应用中,我们对检测 3D 空间中的物体感兴趣。 这是运动规划的基础,以便规划安全路线。
最近的 3D 对象检测方法利用了不同的数据源。 基于相机的方法利用单目 [1] 或立体图像 [2]。 然而,从 2D 图像进行准确的 3D 估计是很困难的,尤其是在长距离内。 随着廉价 RGB-D 传感器(如 Microsoft Kinect、英特尔 realsense 和 Apple PrimeSense)的普及,已经开发了几种利用深度信息并将其与 RGB 图像融合的方法 [32,33]。 与单目方法相比,它们已被证明可以显着提高性能。 在自动驾驶的背景下,像 LIDAR(光检测和测距)这样的高端传感器更常见,因为安全需要更高的精度。 处理 LIDAR 数据的主要困难在于,传感器以点云的形式生成非结构化数据,每 360 度扫描通常包含大约 1053D 点。 这给现代检测器带来了巨大的计算挑战。
在 3D 对象检测的背景下,已经探索了不同形式的点云表示。 主要思想是形成可以应用标准卷积运算的结构化表示。 现有的表示主要分为两种类型:3D 体素网格和 2D 投影。 3D 体素网格将点云转换为规则间隔的 3D 网格,其中每个体素单元格可以包含标量值(例如,占用率)或矢量数据(例如,根据该体素单元格内的点计算的手工统计数据)。 3D 卷积通常用于从体素网格中提取高阶表示 [6]。 然而,由于点云本质上是稀疏的,体素网格非常稀疏,因此很大一部分计算是多余的和不必要的。 因此,典型的系统 [6,37,20] 只能以 1-2 FPS 的速度运行。
另一种方法是将点云投影到平面上,然后将其离散化为基于 2D 图像的表示,其中应用了 2D 卷积。 在离散化过程中,手工制作的特征(或统计数据)被计算为 2D 图像的像素值 [3]。 常用的投影有范围视图(即 360 度全景视图)和鸟瞰视图(即自顶向下视图)。 这些基于 2D 投影的表示更紧凑,但它们在投影和离散化过程中会带来信息丢失。 例如,范围视图投影将具有扭曲的对象大小和形状。 为了减轻信息丢失,MV3D [3] 建议将 2D 投影与相机图像融合以带来附加信息。 然而,融合模型相对于输入模态的数量具有几乎线性的计算成本,使得实时应用不可行。
在本文中,我们提出了一种精确的实时 3D 对象检测器,我们称之为 PIXOR(来自 PIXel-wise 神经网络预测的定向(ORiented) 3D 对象检测),它在 3D 点云上运行。 PIXOR 是一种单级、无提议的密集对象检测器,它以有效的方式利用 2D 鸟瞰图 (BEV) 表示。 我们选择 BEV 表示,因为与 3D 体素网格相比,它在计算上更友好,并且还保留了度量空间,这使我们的模型能够探索关于对象类别大小和形状的先验。 我们的检测器在鸟瞰图的真实世界维度中输出准确的定向边界框。 请注意,这些是 3D 估计值,因为我们假设物体在地面上。 这是在自动驾驶场景中的合理假设,因为车辆不会飞行。
我们在两个数据集,公共 KITTI 基准 [10] 和大规模 3D 车辆检测数据集 (TG4D) 中证明了我们的方法的有效性。 具体来说,PIXOR 在 KITTI 鸟瞰目标检测基准上实现了所有先前发布的方法中最高的平均精度 (AP),同时也是其中运行最快的(超过 10 FPS)。 我们还对 KITTI 进行了深入的消融研究,以调查每个模块对性能提升的贡献,并通过将其应用于大规模 ATG4D 数据集来证明 PIXOR 的可扩展性和泛化能力。
2.相关工作
我们首先回顾了将卷积神经网络应用于目标检测的最新进展,然后回顾了两个相关子领域的工作,单阶段目标检测和 3D 目标检测。
2.1 CNN-based 目标检测
卷积神经网络 (CNN) 在图像分类方面表现出色 [18]。当应用于对象检测时,通过在表示对象候选的裁剪区域上运行推理来利用它们是很自然的。 Overfeat [30] 在不同的位置和尺度上滑动 CNN,并每次预测每个类的边界框。自从引入与类别无关的对象提议 [36,26] 以来,基于提议的方法流行起来,其中 Region-CNN (RCNN) [12] 及其更快的版本 [11,4] 是最具开创性的工作。 RCNN 首先使用 ImageNet [5] 预训练的 CNN 提取整个图像特征图,然后通过对整个图像特征图 [13] 的 RoI 池化操作预测每个提议的置信度分数和框位置。 Faster-RCNN [28] 进一步建议学习使用 CNN 生成区域提议,并与检测共享特征表示,从而进一步提高性能和速度。基于提议的对象检测器在许多公共基准测试中取得了出色的性能 [7,29]。然而,典型的两级流水线使其不适合实时应用。
2.2 单级目标检测
与首先预测提议然后细化它们的两阶段检测管道不同,单阶段检测器直接预测最终检测。 YOLO [27] 和 SSD [23] 是实时速度方面最具代表性的作品。 YOLO [27] 将图像划分为稀疏网格,并对每个网格单元进行多类和多尺度预测。 SSD [23] 还使用预定义的对象模板(或锚点)来处理对象大小和形状的巨大差异。对于单类目标检测,DenseBox [17] 和 EAST [38] 表明单级检测器在不使用手动设计的锚点的情况下也能很好地工作。它们都采用全卷积网络架构 [24] 进行密集预测,其中每个像素位置对应一个候选对象。最近 RetinaNet [22] 表明,如果正确解决训练期间的类别不平衡问题,单级检测器可以胜过两级检测器。我们提出的检测器遵循单级密集物体检测器的思想,同时通过重新设计输入表示、网络架构和输出参数化将这些思想进一步扩展到实时 3D 物体检测。我们还通过重新定义目标定位的目标函数来去除预定义目标锚的超参数,从而导致更简单的检测框架。
2.3 点云中的 3D 目标检测
Vote3D [37] 在 3D 体素网格中的稀疏体积上使用滑动窗口来检测对象。在每个体积上提取手工制作的几何特征并将其输入到 SVM 分类器 [34]。 Vote3Deep [6] 也使用点云的体素表示,但使用 3D 卷积神经网络 [35] 提取每个体积的特征。体素表示的主要问题是效率,因为 3D 体素网格通常具有高维数。相比之下,VeloFCN [20] 将 3D 点云投影到前视图并获得 2D 深度图。然后通过在深度图上应用 2D CNN 来检测车辆。最近 MV3D [3] 也使用了投影表示。它结合了从多个视图(前视图、鸟瞰图以及相机视图)中提取的 CNN 特征来进行 3D 对象检测。然而,手工制作的特征被计算为光栅化图像的编码。然而,我们提出的检测器在自动驾驶的背景下单独使用鸟瞰图表示进行实时 3D 物体检测,我们假设所有物体都位于同一地面上。
3. PIXOR
在本文中,我们提出了一种高效的 3D 对象检测器,它能够在给定 LIDAR 点云的情况下生成非常准确的边界框。 我们的边界框估计不仅包含 3D 空间中的位置,还包含航向角,因为准确预测这对于自动驾驶非常重要。 我们利用 LIDAR 点云的 2D 表示,因为与 3D 体素网格表示相比,它更紧凑,因此更适合实时推理。 所提出的 3D 物体检测器的概述如图 1 所示。 在下文中,我们将介绍我们的输入表示、网络架构并讨论我们如何对定向边界框进行编码。 我们还介绍了有关检测器学习和推理的详细信息。

3.1 输入表示
标准卷积神经网络执行离散卷积,因此假设输入位于网格上。 然而,3D 点云是非结构化的,因此不能直接应用标准卷积。 一种选择是使用体素化来形成 3D 体素网格,其中每个体素单元包含位于该体素内的点的某些统计信息。 为了从这个 3D 体素网格中提取特征表示,经常使用 3D 卷积。 然而,这在计算上可能非常昂贵,因为我们必须沿三个维度滑动 3D 卷积核。 这也是不必要的,因为 LIDAR 点云非常稀疏,以至于大多数体素单元都是空的。
相反,我们可以仅从鸟瞰图 (BEV) 来表示场景。 (暂不理解)通过将自由度从 3 减少到 2,我们不会丢失点云中的信息,因为我们仍然可以将高度信息保留为沿第 3 维的通道(如 2D 图像的 RGB 通道)。 然而,实际上我们得到了更紧凑的表示,因为我们可以将 2D 卷积应用于 BEV 表示。 在自动驾驶的背景下,这种降维是合理的,因为感兴趣的对象在同一地面上。 除了计算效率,BEV 表示还有其他优势。 它减轻了对象检测的问题,因为对象彼此不重叠(与前视图表示相比)。 它还保留了度量空间,因此网络可以利用关于对象物理尺寸的先验。
在这里,我们详细说明了 BEV 表示的投影和离散化过程。 我们首先定义我们有兴趣检测对象的场景的 3D 物理尺寸 L × W × H L×W×H L×W×H。 该 3D 矩形空间内的 3D 点随后以每个单元 d L × d W × d H d_L×d_W×d_H dL×dW×dH 的分辨率进行离散化。 每个单元格的值被编码为占用率(即,如果该单元格中存在点,则为 1,否则为 0)。 离散化后,我们得到形状为 L d L × W d W × H d H \frac{L}{dL} × \frac{W}{dW} × \frac{H}{dH} dLL×dWW×dHH 的 3D 占用张量。 我们还以类似的方式对 LIDAR 点的反射率(归一化为 [ 0 , 1 ] [0,1] [0,1] 内的真实值)进行编码。 唯一的区别是对于反射率,我们设置 d H = H d_H=H dH=H。 我们的最终表示是 3D 占用张量和 2D 反射率图像的组合,其形状为 L d L × W d W × ( H d H + 1 ) \frac{L}{dL} × \frac{W}{dW} ×(\frac{H}{dH}+1) dLL×dWW×(dHH+1)。
3.2 网络架构
PIXOR 使用专为密集定向 3D 对象检测而设计的全卷积神经网络。 我们不采用常用的提案生成分支 [11,28,4,3]。 相反,网络在单个阶段输出像素级预测,每个预测对应于 3D 对象估计。 因此,PIXOR 的召回率定义为 100%。 由于全卷积架构,可以非常有效地计算这种密集预测。 在网络预测中对 3D 对象的编码方面,我们使用直接编码而不使用预定义的对象锚点 [11,28,4],这在实践中效果很好。 由于网络架构中的超参数为零,所有这些设计都使 PIXOR 变得非常简单并且可以很好地泛化。 具体来说,不需要设计对象锚点,也不需要调整从第一阶段传递到第二阶段的提议数量以及相应的非最大抑制阈值。
我们在图 2 中展示了 PIXOR 的架构。 整个架构可以分为两个子网:骨干网(backbone)和头网 (header)。 骨干网络用于以卷积特征图的形式提取输入的一般表示。 它具有学习鲁棒特征表示的高表示能力。 头 (header)网络用于进行特定于任务的预测,在我们的例子中,它具有带有多任务输出的单分支结构:表示对象类别概率的分数图,以及编码定向 3D 对象大小和形状的几何图。

3.2.1 Backbone 网络
卷积神经网络通常由卷积层和池化层组成。 卷积层用于提取输入特征的过完备表示,而池化层用于对特征图大小进行下采样以节省计算并帮助创建更稳健的表示。 许多基于图像的目标检测器中的主干网络通常具有 16[28,11,4] 的下采样因子,并且通常被设计为在高分辨率中具有较少的层而在低分辨率中具有更多层。 它适用于图像,因为对象的像素大小通常很大。 但是,在我们的情况下,这会导致问题,因为对象可能非常小。 当使用 0.1m 的离散化分辨率时,典型车辆的尺寸为 18×40 像素。 经过 16 倍下采样后,它只覆盖了大约 3 个像素。
一种直接的解决方案是使用更少的池化层。 但是,这会减小最终特征图中每个像素的感受野大小,从而限制了表示能力。 另一种解决方案是使用扩张卷积。 然而,这会导致高级特征图中的棋盘伪影 [25]。 我们的解决方案很简单,我们使用 16x 下采样因子,但做了两个修改。 首先,我们在较低级别添加更多具有小通道数的层以提取更多细节信息。 其次,我们采用类似于 FPN [21] 的自顶向下分支,将高分辨率特征图与低分辨率特征图结合起来,以便对最终特征表示进行上采样。
我们在图 2 中展示了骨干网络架构。具体来说,我们在骨干网络中总共有五个层块。 第一个块由两个卷积层组成,通道数为 32,步长为 1。第二到第五个块由残差层组成 [15](层数分别等于 3、6、6、4)。 每个残差块的第一个卷积的步长为 2,以便对特征图进行下采样。 总的来说,我们有一个 16 的下采样因子。 为了对特征图进行上采样,我们添加了一个自上而下的路径,每次对特征图进行 2 上采样。 然后通过逐像素求和将其与相应分辨率的自下而上的特征图相结合。 使用了两个上采样层,这导致最终的特征图具有相对于输入的 4 倍下采样因子。
3.2.2 Header 网络
Header 网络是一个处理对象识别和定位的多任务网络。 它被设计成小而高效。 分类分支输出 1 个通道特征图,后跟 sigmoid 激活函数。 回归分支输出没有非线性的 6 通道特征图。 在两个分支之间共享权重的层数方面存在权衡。 一方面,我们希望更有效地利用权重。 另一方面,由于它们是不同的子任务,我们希望它们更加独立和更加专业化。 我们在下一章中对这种权衡进行了调查实验,发现共享两个任务的权重会导致性能稍好一些。
我们将每个对象作为一个定向边界框 b b b 参数化为 { θ , x c , y c , w , l } \{θ, xc, yc, w, l\} {θ,xc,yc,w,l},每个元素对应的航向角(在 [ − π , π ] [−π, π] [−π,π] 范围内)、对象的中心位置和对象的尺寸。 与基于长方体的 3D 对象检测相比,我们省略了沿 Z 轴的位置和大小,因为在自动驾驶等应用中,感兴趣的对象被限制在同一地平面上,因此我们只关心如何将其定位在该平面上(此设置 在一些文献中也称为 3D 定位 [3])。 给定这样的参数化,对于位置 ( p x , p y ) (px, py) (px,py) 处的每个像素,回归分支的表示为 { c o s ( θ ) , s i n ( θ ) , d x , d y , w , l } \{cos(θ), sin(θ), dx, dy, w, l\} {cos(θ),sin(θ),dx,dy,w,l}(如图 3 中的红点所示)。
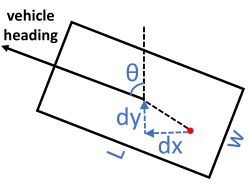
图3。一个正样本(红色像素)的几何输出参量化。学习目标是 { c o s ( θ ) , s i n ( θ ) , l o g ( d x ) , l o g ( d y ) , l o g ( w ) , l o g ( l ) } \{cos(θ),sin(θ),log(dx),log(dy),log(w),log(l)\} {cos(θ),sin(θ),log(dx),log(dy),log(w),log(l)},在移交训练集之前对其进行规范化,使其具有零均值和单位方差。
请注意,航向角被分解为两个相关值以强制执行角度范围约束。 我们在推理过程中将 θ θ θ 解码为 a t a n 2 ( s i n ( θ ) , c o s ( θ ) ) atan2(sin(θ), cos(θ)) atan2(sin(θ),cos(θ))。 ( d x , d y ) (dx, dy) (dx,dy) 对应于从像素位置到对象中心的位置偏移。 ( w , l ) (w, l) (w,l) 对应于对象大小 . 值得注意的是,对象位置和大小的值在现实世界的度量空间中。 学习目标是
{ c o s ( θ ) , s i n ( θ ) , l o g ( d x ) , l o g ( d y ) , l o g ( w ) , l o g ( l ) } \{cos(θ),sin(θ),log(dx),log(dy),log(w),log(l)\} {cos(θ),sin(θ),log(dx),log(dy),log(w),log(l)},预先在训练集上归一化,使其均值和单位方差为零。 在下一章中,我们进一步发现在训练时解码定向框并直接在四个框角的坐标上计算回归损失可以带来额外的性能增益。
3.3 学习和推理
我们采用常用的多任务损失[11]来训练整个网络。 具体来说,我们在分类输出 p p p 上使用交叉熵损失,在回归输出 q q q 上使用 Smooth ℓ1 损失。 我们对输出地图上所有位置的分类损失求和,而回归损失仅在正位置上计算。
L t o t a l = c r o s s − e n t r o p y ( p , y c l s ) + s m o o t h L 1 ( q − y r e g ) (1) L_{total} = cross-entropy(p,y_{cls})+smooth_{L_1}(q-y_{reg}) \tag{1} Ltotal=cross−entropy(p,ycls)+smoothL1(q−yreg)(1)
c r o s s − e n t r o p y ( p , y ) = { − log ( p ) if y = 1 − log ( 1 − p ) otherwise , (2) cross-entropy(p,y) = \begin{cases} -\log(p) & \text{if } y=1 \\ -\log(1-p) & \text{otherwise}, \end{cases} \tag{2} cross−entropy(p,y)={−log(p)−log(1−p)if y=1otherwise,(2)
s m o o t h L 1 ( x ) = { 0.5 x 2 if ∣ x ∣ < 1 ∣ x ∣ − 0.5 otherwise , (3) smooth_{L_1}(x)=\begin{cases} 0.5x^2 & \text{if } |x|<1 \\ |x|-0.5 & \text{otherwise}, \end{cases} \tag{3} smoothL1(x)={0.5x2∣x∣−0.5if ∣x∣<1otherwise,(3)
请注意,我们有严重的类不平衡,因为场景的很大一部分属于背景。 为了稳定训练过程,我们采用与 [22] 具有相同超参数的焦点损失来重新加权所有样本。 在下一章中,我们还为正样本提出了一种有偏采样策略,可以更好地收敛。 在推理过程中,我们将计算的 BEV 表示从 LIDAR 点云提供给网络,并获得一个置信度分数通道和六个几何信息通道。 然后,我们仅在置信度分数高于特定阈值的位置上将几何信息解码为定向边界框。NMS 用于获得最终检测,其中重叠计算为两个定向框的 Intersection-Over-Union。
[22] T.-Y . Lin, P . Goyal, R. Girshick, K. He, and P. Dollár. Focal loss for dense object detection. InProceedings of the IEEE International Conference on Computer Vision, 2017.2,5,7
4. 实验
我们在这里进行了三种类型的实验。 首先,我们在公共 KITTI 鸟瞰对象检测基准上将 PIXOR 与其他最先进的 3D 对象检测器进行比较 [10]。 我们表明,与之前发布的所有方法相比,PIXOR 在准确性和速度方面都实现了最佳性能。 其次,我们从三个方面对 PIXOR 进行了消融研究:优化、网络架构和速度。 第三,我们通过将 PIXOR 应用于自动驾驶的新大规模车辆检测数据集来验证 PIXOR 的泛化能力。
4.1.基于KITTI的BEV目标检测
4.1.1 实现细节
我们将点云的感兴趣区域设置为 [0,70] × [−40,40] 米,并以 0.1 米的离散化分辨率进行鸟瞰图投影。 我们在 LIDAR 坐标中将高度范围设置为 [−2.5,1] 米,并将所有点分成 35 个切片,bin 大小为 0.1 米。 还计算了一个反射通道。 因此,我们的输入表示的维度为 800×700×36。 我们在训练期间使用沿 Z 轴 [−5,5] 度之间旋转的数据增强和沿 X 轴随机翻转。 与从预训练模型初始化网络权重的其他检测器 MV3D[3] 不同,我们从头开始训练我们的网络,而无需求助于任何预训练模型。
4.1.2 评价指标
除非另有说明,否则我们在所有实验中都使用以 0.7 IoU 计算的平均精度 (AP) 作为我们的评估指标。我们将 AP 计算为精确召回曲线下的面积 (AUC) [8]。我们评估“汽车”类别并在评估期间忽略 KITTI 中的“Van”、“Truck”、“Tram”和“DontCare”类别,这意味着我们不计算真阳性 (TP) 或假阴性 (FN)。请注意,我们使用的度量标准在以下两个方面与 KITTI 报告的不同:(1)KITTI 通过以 11 个线性采样召回率(从 0% 到 100%)进行采样来计算 AP,这是对实际 AUC 的粗略近似。 (2) KITTI 将标签划分为基于图像定义的三个子集(例如,以像素为单位的对象高度,以图像为单位的可见性),并在每个子集上报告 AP,这不适合纯基于 LIDAR 的对象检测。相比之下,我们对感兴趣区域内的所有标签进行评估,并对范围(到自驾车的物体距离)进行细粒度评估。
4.1.3评价结果
我们在 KITTI 基准测试中与使用激光雷达的 3D 物体检测器进行了比较:VeloFCN [20]、3D FCN [19] 和 MV3D [3]。 我们在表 1 中显示了评估结果。 从表中我们看到,PIXOR 在 70 米范围内以 0.7 IoU 在 AP 中的表现大大优于其他方法,领先第二好 9% 以上。 我们还展示了关于范围的评估结果,并表明 PIXOR 在长期范围内表现更好。 在 KITTI 的测试集上,PIXOR 在中等和困难设置中优于 MV3D。 注意PIXOR在简单设置测试集上的AP较低,这是11点AP指标不稳定造成的。

表 1.在 KITTI 鸟瞰基准测试中使用 LIDAR 作为输入的 3D 物体检测器的评估。MV3D+im[3] 使用图像作为附加输入。 我们使用 A P 0.7 AP_{0.7} AP0.7(所有汽车上具有 0.7 IoU 阈值的 PR 曲线的 AUC)和 A P K I T T I AP_{KITTI} APKITTI(官方 KITTI 指标,仅计算具有 11 个采样点的 AUC,在三个子集上进行评估)作为验证集[3]和测试集的评估指标。 我们还展示了关于不同范围(到自驾车的距离以米为单位)的细粒度评估,这在 3D 检测中更有意义。
由于 MV3D 是所有最先进方法中的最佳方法,我们想使用基于 AUC 的 AP 指标进行更详细的比较。我们在图 4 中展示了 PIXOR 和 MV3D 的细粒度 Precision-Recall (PR) 曲线。从图中,我们得到以下观察结果: (1) PIXOR 在所有 IoU 阈值上都优于 MV3D,尤其是在像 0.8 和 0.9 这样非常高的 IoU 时,表明即使不使用建议,PIXOR 仍然可以获得超精确的对象定位,与两者相比基于阶段提议的检测器 MV3D。 (2) PIXOR 在低召回率下具有与 MV3D 相似的精度。然而,当涉及到更高的召回率时,PIXOR 显示出巨大的优势。在MV3D曲线终点的相同准确率下,PIXOR在所有范围内的召回率一般都高出5%以上。这表明,与两阶段检测器相比,像 PIXOR 这样的密集检测器确实具有召回率更高的优势。 (3) 在难度更大的远距离部分,PIXOR 仍然表现出优于 MV3D 的优势,这证明了我们的输入表示设计很好地保留了 3D 信息以及我们的网络架构设计同时捕获了细节和区域上下文。

图 4. PIXOR 和 MV3D [3] 在 KITTI 验证集上的评估。对于每种方法,我们绘制了 5 条 Precision-Recall 曲线,对应于 0.5 和 0.9 之间的 5 个不同 IoU 阈值,并报告平均 AP (%)。 我们在三个不同的范围内进行比较。
4.2消融研究
我们展示了对该探测器在优化、网络结构、速度和故障模式方面的广泛烧蚀研究。
4.2.1实验设置
由于我们还在验证集上与其他最先进的方法进行了比较,因此在同一集上进行消融研究是不合适的。 因此,我们求助于 KITTI 原始数据集 [9],并在 KITTI 对象检测数据集中随机选取 3000 帧与训练集和验证集不重叠的帧,我们称之为 val-dev 集。 我们报告了该组的消融研究结果。 我们使用 0.7 IoU 的 AP 以及平均从 0.5 到 0.95 IoU(步幅为 0.05)的 AP 作为评估指标。
4.2.2优化
我们在这里研究了四个主题:分类损失、回归损失、采样策略和数据增强。
分类损失:RetinaNet [22] 提出了焦点损失来重新加权样本以进行密集检测器训练。 为简单起见,我们使用他们的超参数设置。 我们在表 2 中显示了结果,发现焦点损失将 A P 0.7 AP_{0.7} AP0.7 提高了 1% 以上。
回归损失:对于框回归部分,我们的默认选择是回归目标的每个维度上的平滑 L1 损失 [11]。 我们还提出了解码损失(decoding loss),其中输出目标首先被解码为定向框,然后在四个框角的 ( x , y ) (x, y) (x,y) 坐标上直接针对 ground truth 计算平滑 L1 损失。 由于从回归目标解码定向框只是一些正常数学运算的组合,所以这个解码过程是可微的,梯度可以通过这个解码过程反向传播。 我们认为这种解码损失(decoding loss)更加端到端,并且隐含地平衡了回归目标的不同维度。 在表 2 所示的结果中,我们表明直接使用解码损失(decoding loss)进行训练效果不佳。 然而,首先使用传统损失训练,然后使用建议的解码损失(decoding loss)进行微调有助于大大提高性能。

表 2. 不同损失函数的消融研究。smoothL1 + decode (f.t.) 意味着网络首先使用平滑 L1 损失进行训练,然后通过用解码损失(decoding loss)替换平滑 L1 损失进行微调。
数据采样和增强:在训练密集检测器时,一个问题是如何定义正负样本。在基于提案(proposal)的方法中,这是由提案和 ground truth 之间的 IoU 定义的。由于 PIXOR 是一种无提议方法,我们采用更直接的采样策略:ground-truth 内的所有像素都是正样本,而外部像素是负样本。这个简单的定义已经提供了不错的性能。然而,这个定义的一个问题是回归目标的方差对于对象边界附近的像素可能很大。因此,我们建议对像素进行子采样,即在训练期间忽略对象边界附近的像素。具体来说,我们分别使用 0.3 和 1.2 的缩放因子将真实对象框缩放两次,并忽略位于这两个缩放框之间的所有像素。从表 3 所示的结果中,我们发现这种子采样策略有利于稳定训练。我们还发现我们对 KITTI 的数据增强有一点帮助,因为 PIXOR 是从头开始训练的,而不是从预训练的模型中训练的。

4.2.3网络架构
骨干网络:我们首先比较不同的骨干网络:vgg16 半通道数 [31]、pvanet [16]、resnet-50 [14] 和 resnet-lidar,如图 2 所示。所有这些骨干网络的运行速度都低于 100 毫秒。 除了 vgg16-half 之外的所有骨干网络都使用残差单元作为构建块。 我们发现 vgg16-half 在训练集内收敛速度更快,训练损失比所有其他残差变体都要低,但是在评估集时性能下降了很多。 这不会发生在其他三个基于残差的网络上。 我们推测这是因为 vgg16-half 更容易过拟合,而没有由残差连接强加的隐式正则化。
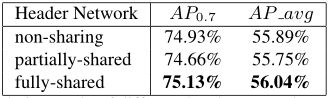
头部网络:我们还比较了头部网络的不同结构。 我们调查了我们应该为多任务输出共享多少参数。 在图5中提出了三种版本的头网络,具有不同程度的权重共享,并在表5中进行了比较。 所有这三个版本的参数数量都非常接近。 我们发现完全共享的结构效果最好,因为它最有效地利用了参数。

4.2.4 Speed
我们在表 6 中展示了单个帧的 PIXOR 的详细时序分析。 输入表示的计算和最终的 NMS 都在 Python 中在 CPU 上处理。 网络时间是在 NVIDIA Titan Xp GPU 上测量的,并在 KITTI 中平均超过 100 个非序列帧。

4.2.5 故障模式
我们在图 6 中展示了 PIXOR 的一些检测结果,并发现了一些故障模式。 一般来说,当没有观察到 LIDAR 点时,PIXOR 会失败。 在更长的范围内,我们几乎没有对象的证据,因此对象定位变得不准确,导致在更高的 IoU 阈值下出现误报。

图 6. PIXOR 在 KITTI Object 验证集上的示例检测结果。检测为红色,而 ground truth 为蓝色。 灰色区域不在摄像机视野范围内,因此没有标签。
4.3.大规模数据集上的BEV目标检测
4.3.1 ATG4D 数据集
我们还收集了一个名为 ATG4D 的大规模 3D 车辆检测数据集,该数据集具有与 KITTI 不同的传感器配置,并在北美城市收集。 总共收集了 6500 个序列,分为 5000/500/1000 作为训练/验证/测试分割。 训练序列以 10 Hz 的频率采样为帧,而验证和测试序列以 0.5Hz 的频率采样。 结果,训练集中有超过 120 万帧,验证集和测试集中有 5969 和 11969 帧。 所有车辆都用鸟瞰图边界框标签进行了注释。
4.3.2评价结果
我们将 PIXOR 应用于具有“vgg-half”骨干网络的 ATG4D,因为 ATG4D 的训练数据比 KITTI 多得多,因此防止过度拟合不是我们主要关注的问题。 我们在高达 100 米的范围内训练和测试检测器,并将输入离散化分辨率提高到 0.2 米。 结果,检测器仍以>10Hz 运行。 相比之下,我们在 ATG4D 上构建了一个带有定制骨干网络的类似 YOLO [27] 的基线检测器,并添加了对象锚点和多尺度特征融合以进一步提高性能。 评估结果列于表 7 中,其中我们表明 PIXOR 在 A P 0 . 7 AP_0.7 AP0.7 中的性能优于基线 3.9%,证明 PIXOR 简单且易于泛化,无需调整超参数。

5. 结论
在本文中,我们提出了一种名为 PIXOR 的实时 3D 对象检测器,它在 LIDAR 点云上运行。 PIXOR 是一种单级、无提议、密集的对象检测器,在自动驾驶的 3D 对象定位环境中实现了极其简单的目的。 PIXOR 将鸟瞰图表示作为计算效率的输入。 提出了一种更适合 3D 对象定位任务的新型解码损失。 我们在具有挑战性的 KITTI 基准测试以及大规模车辆检测数据集 ATG4D 上评估 PIXOR,并表明它在平均精度 (AP) 方面大大优于其他方法,同时仍以 10 FPS 运行。
参考文献
[1] X. Chen, K. Kundu, Z. Zhang, H. Ma, S. Fidler, and R. Urtasun. Monocular 3d object detection for autonomous driving. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2147–2156, 2016.1
[2] X. Chen, K. Kundu, Y . Zhu, H. Ma, S. Fidler, and R. Urtasun. 3d object proposals using stereo imagery for accurate object class detection.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017.1
[3] X. Chen, H. Ma, J. Wan, B. Li, and T. Xia. Multi-view 3d object detection network for autonomous driving. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017.1, 3,4,5,6
[4] J. Dai, Y . Li, K. He, and J. Sun. R-fcn: Object detection via regionbased fully convolutional networks. InAdvances in Neural Information Processing Systems, pages 379–387, 2016.1,2,3,4
[5] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. Imagenet: A large-scale hierarchical image database. InComputer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conference on, pages 248–255. IEEE, 2009.2
[6] M. Engelcke, D. Rao, D. Z. Wang, C. H. Tong, and I. Posner. V ote3deep: Fast object detection in 3d point clouds using efficient convolutional neural networks. InRobotics and Automation (ICRA), 2017 IEEE International Conference on, pages 1355–1361. IEEE, 2017.1,3
[7] M. Everingham, L. V an Gool, C. K. Williams, J. Winn, and A. Zisserman. The pascal visual object classes (voc) challenge.International journal of computer vision, 88(2):303–338, 2010.2
[8] M. Everingham, L. V an Gool, C. K. Williams, J. Winn, and A. Zisserman. The pascal visual object classes (voc) challenge.International Journal of Computer Vision, 88(2):303–338, 2010.5
[9] A. Geiger, P . Lenz, C. Stiller, and R. Urtasun. Vision meets robotics: The kitti dataset.The International Journal of Robotics Research, 32(11):1231–1237, 2013.6
[10] A. Geiger, P . Lenz, and R. Urtasun. Are we ready for autonomous driving? the kitti vision benchmark suite. InComputer Vision and Pattern Recognition (CVPR), 2012 IEEE Conference on, pages 3354–3361. IEEE, 2012.2,5
[11] R. Girshick. Fast r-cnn. InProceedings of the IEEE International Conference on Computer Vision, pages 1440–1448, 2015.1,2,3,4, 5,7
[12] R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 580–587, 2014.1,2
[13] K. He, X. Zhang, S. Ren, and J. Sun. Spatial pyramid pooling in deep convolutional networks for visual recognition.IEEE transactions on pattern analysis and machine intelligence, 37(9):1904–1916, 2015. 2
[14] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 770–778, 2016.7
[15] K. He, X. Zhang, S. Ren, and J. Sun. Identity mappings in deep residual networks. InEuropean Conference on Computer Vision, pages 630–645. Springer, 2016.4
[16] S. Hong, B. Roh, K.-H. Kim, Y . Cheon, and M. Park. PV ANet: Lightweight deep neural networks for real-time object detection. arXiv preprint arXiv:1611.08588, 2016.7
[17] L. Huang, Y . Yang, Y . Deng, and Y . Y u. Densebox: Unifying landmark localization with end to end object detection.arXiv preprint arXiv:1509.04874, 2015.2
[18] A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. InAdvances in neural information processing systems, pages 1097–1105, 2012.2
[19] B. Li. 3d fully convolutional network for vehicle detection in point cloud. InIntelligent Robots and Systems (IROS), 2017 IEEE/RSJ International Conference on, pages 1513–1518. IEEE, 2017.5,6
[20] B. Li, T. Zhang, and T. Xia. V ehicle detection from 3d lidar using fully convolutional network. InRobotics: Science and Systems, 2016.1,3,5,6
[21] T.-Y . Lin, P . Dollár, R. Girshick, K. He, B. Hariharan, and S. Belongie. Feature pyramid networks for object detection. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017.4
[22] T.-Y . Lin, P . Goyal, R. Girshick, K. He, and P . Dollár. Focal loss for dense object detection. InProceedings of the IEEE International Conference on Computer Vision, 2017.2,5,7
[23] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y . Fu, and A. C. Berg. Ssd: Single shot multibox detector. InEuropean Conference on Computer Vision, pages 21–37. Springer, 2016.1,2
[24] J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3431– 3440, 2015.2
[25] A. Odena, V . Dumoulin, and C. Olah. Deconvolution and checkerboard artifacts.Distill, 1(10):e3, 2016.4
[26] J. Pont-Tuset, P . Arbelaez, J. T. Barron, F. Marques, and J. Malik. Multiscale combinatorial grouping for image segmentation and object proposal generation.IEEE transactions on Pattern Analysis and Machine Intelligence, 39(1):128–140, 2017.2
[27] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi. Y ou only look once: Unified, real-time object detection. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 779–788, 2016.1,2,8
[28] S. Ren, K. He, R. Girshick, and J. Sun. Faster r-cnn: Towards realtime object detection with region proposal networks. InAdvances in Neural Information Processing Systems, pages 91–99, 2015.1,2,3, 4
[29] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, et al. Imagenet large scale visual recognition challenge.International Journal of Computer Vision, 115(3):211–252, 2015.2
[30] P . Sermanet, D. Eigen, X. Zhang, M. Mathieu, R. Fergus, and Y . LeCun. Overfeat: Integrated recognition, localization and detection using convolutional networks.International Conference on Learning Representations (ICLR 2014), 2014.2
[31] K. Simonyan and A. Zisserman. V ery deep convolutional networks for large-scale image recognition.CoRR, abs/1409.1556, 2014.7
[32] S. Song and J. Xiao. Sliding shapes for 3d object detection in depth images. InEuropean conference on computer vision, pages 634–651. Springer, 2014.1
[33] S. Song and J. Xiao. Deep sliding shapes for amodal 3d object detection in rgb-d images. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 808–816, 2016.1
[34] J. A. Suykens and J. V andewalle. Least squares support vector machine classifiers.Neural processing letters, 9(3):293–300, 1999.3
[35] D. Tran, L. Bourdev, R. Fergus, L. Torresani, and M. Paluri. Learning spatiotemporal features with 3d convolutional networks. InProceedings of the IEEE international conference on computer vision, pages 4489–4497, 2015.3
[36] J. R. Uijlings, K. E. V an De Sande, T. Gevers, and A. W. Smeulders. Selective search for object recognition.International Journal of Computer Vision, 104(2):154–171, 2013.2
[37] D. Z. Wang and I. Posner. V oting for voting in online point cloud object detection. InRobotics: Science and Systems, 2015.1,3
[38] X. Zhou, C. Yao, H. Wen, Y . Wang, S. Zhou, W. He, and J. Liang. East: An efficient and accurate scene text detector. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017.2