【模型训练】目标检测实现分享三:详解 YOLOv3 算法实现
欢迎关注我的公众号 [极智视界],回复001获取Google编程规范
O_o >_< o_O O_o ~_~ o_O
大家好,我是极智视界,本文详细介绍一下 YOLOv3 算法的设计与实践。
本文是目标检测类算法实现分享的第三篇,前面已经写过两篇,感兴趣的同学可以查阅:
(1) 《【模型训练】目标检测实现分享一:详解 YOLOv1 算法实现》;
(2) 《【模型训练】目标检测实现分享二:听说克莱今天复出了?详解 YOLOv2 算法与克莱检测》;
YOLOv3 是 YOLO 系列的第三个版本,在论文 《YOLOv3:An Incremental Improvement》中提出,性能进一步提升。基于 YOLOv3 的目标检测模型结构在工程应用中可以说非常常见了,下面我们一起来看 YOLOv3 相对于之前的 YOLO 版本主要做了哪些方面的优化。
同样这里不止会讲原理也会讲实践。
文章目录
-
- 1、YOLOv3 原理
-
- 1.1 Backbone:Darknet-53
- 1.2 Predictions Across Scales
- 1.3 Bounding Box Prediction
- 1.4 Loss Fuction
- 2、YOLOv3 实践
-
- 2.1 COCO 数据集配置
- 2.2 训练
- 2.3 验证
1、YOLOv3 原理
老规矩,先来看实验数据:

上图纵轴精度数据是 COCO AP,横轴效率数据在 Nvidia Titan X 上测得,可以看到 YOLOv3 相比 SSD、FRCN、RetinaNet 等检测网络,能更加好的兼顾效率和精度。
再来看一组更细一些的精度数据:

这里的数据比对将检测算法分为 Two-stage 和 One-stage,其中 Two-stage 检测算法以 Faster R-CNN 为代表,一般 Two-stage 的检测算法以精度著称,但由于检测过程 (两阶段:筛选候选区域 + 分类) 较为繁琐,所以前向效率不高,工程应用上比较少见。One-stage 检测算法这里罗列的比较多一些:YOLOv2、SSD、RetinaNet 还有 YOLOv3,One-stage 的算法以效率著称,并随着发展能逐步兼顾精度。纵观整个精度数据比对,可以看到在 COCO 数据集上, backbone 为 ResNeXt-101-FPN 的 RetinaNet 的 AP、AP50、AP75、APs、APm 均为最高,Faster R-CNN w TDM 的 APl 为最高。解释一下这些指标,在 COCO 数据集评价指标中,所有的 AP 默认均为 mAP,即 AP=mAP、AP50=mAP50 … 递推。其中 AP 表示 IOU 阈值为 .05~0.95 的精度,AP50 表示 IOU 阈值为 .50 的精度,AP75 表示 IOU 阈值为 .75 的精度,APs 表示对于小目标 (area < 32^2) 的检测精度,APm 表示对于中目标 (32^2 < area < 96^2) 的检测精度,APl 表示对于大目标 (area > 96^2) 的检测精度。可以看出 RetinaNet 的 ResNeXt-101-FPN 的特征提取能力十分强悍,YOLOv3 比不过它,且 YOLOv3 也比不过 Faster R-CNN w TDM 在大目标上的检测能力。YOLOv3 的整体检测精度处于中上上水准,且改进了 YOLOv1&YOLOv2 中一直被诟病的小目标检测能力弱的问题,再结合它强大的推理效率,配得上文章中说的YOLOv3 is pretty good!
下面讲 YOLOv3 做了哪些改进。
1.1 Backbone:Darknet-53
YOLOv2 中提出了 Darknet-19 作为 backbone,YOLOv3 在 Darknet-19 的基础上,借鉴 Resnet 的残差结构进一步加深网络深度,能够极大提高 backbone 的特征提取能力,Darknet-53 的结构如下:

不吹不擂,来看一下 Darknet-53 与其他一些主流 backbone 的性能对比数据:
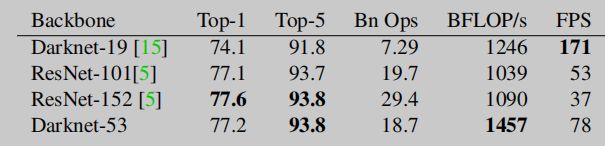
可以看到相比 YOLOv2 的 Darknet-19,Darknet-53 在精度上大幅提升,由于 Darknet-53 的网络更深,前向效率没有 Darknet-19 快。再对比 ResNet 如此深的网络,Darknet-53 在精度上也能与之匹敌,另外前向效率比 ResNet-152 快 2 倍,比 ResNet-101 快 1.5 倍。从这些数据可以看出,Darknet-53 具有十分强的特征提取能力,且能兼顾前向效率。
1.2 Predictions Across Scales
最开始的实验数据说到,YOLOv3 改善了一直被人诟病的小目标检测能力弱的问题,这正是由于它采用了多尺度预测的方式。截了一部分 YOLOv3 的网络结构 (可能太小看不太清),如下:

YOLOv3 网络中有两处 route + upsample 的结构,分别引出了两个 yolo 分支,再加上主分支的 yolo,一共形成了 1个 backbone + 3 个 yolo 检测分支的结构。三个 yolo 分支的 shape 分别为 13 x 13、26 x 26、52 x 52,其中最小的 13 x 13 的 yolo 具有最大的感受野,适合检测大目标;26 x 26 的 yolo 适合检测中等大小的目标;最大的 52 x 52 的 yolo 适合检测小目标。这样就形成了 大、中、小目标检测的全场景覆盖,模型鲁棒性更好。
1.3 Bounding Box Prediction
YOLOv3 中延用了 YOLOv2 提出的 Anchor Boxes k-means 聚类选择及 Bounding Boxes 约束策略。可能有部分人不太理解 Anchor Boxes 和 Bounding Boxes 的区别,这里解释一下:Anchor Boxes 没有位置信息,只有宽高尺度信息,所以在 k-means 聚类的时候只针对宽、高;而 Bounding Boxes 的信息要多一些,包括框的中心点位置信息、宽高、置信度、类别得分。
然后说一下 YOLOv3 中的 Anchor 和 YOLOv2 的区别,我们知道 YOLOv2 中通过 k-means 聚类分析得出 Anchor 数 k = 5 时效果较好,所以选择了 5 个 Anchor 嵌入网络设计;而 YOLOv3 结合前面提到的多尺度预测结构,每个尺度的 yolo 都给它配了 3 个 Anchor,最后一共有 9 个 Anchor,这 9 个 Anchor 在 COCO 中使用聚类选择为:(10 × 13)、(16 × 30)、(33 × 23)、(30 × 61)、(62 × 45)、(59 × 119)、(116 × 90)、(156 × 198)、(373 × 326)。且怎么样分配也有讲究,对于适合检测大目标的 13 x 13 的 yolo feature map 上使用 (116 x 90)、(156 x 198)、(373 x 326) 的 Anchor,对于适合检测小目标的 52 x 52 的 yolo feature map 上使用 (10 x 13)、(16 x 30)、(33 x 23) 的 Anchor,其余 Anchors 用于检测中等大小的目标。
1.4 Loss Fuction
为了更好的收敛和提升精度,YOLOv3 对损失函数也进行了一些改动,其中 x、y、w、h 损失采用 MSE 均方误差,置信度损失采用二分类交叉熵,分类损失采用多类别交叉熵进行计算,整体的损失函数如下:

以上介绍了 YOLOv3 的技术改进,下面进行实践。
2、YOLOv3 实践
这里同样采用 darknet 来训练 YOLOv3,数据集选择 COCO,下面开始。
2.1 COCO 数据集配置
git clone https://github.com/pdollar/coco
cd coco
mkdir images
# download train valdatasets
wget http://images.cocodataset.org/zips/train2014.zip
wget http://images.cocodataset.org/zips/val2014.zip
# unzip .zip
unzip train2014.zip
unzip val2014.zip
cd ..
# download coco metadata
wget https://pjreddie.com/media/files/instances_train-val2014.zip
unzip instances_train-val2014.zip
wget https://pjreddie.com/media/files/coco/labels.tgz
tar zxvf labels.tgz
wget https://pjreddie.com/media/files/coco/5k.part
wget https://pjreddie.com/media/files/coco/trainvalno5k.part
paste <(awk "{print \"$PWD\"}" <5k.part) 5k.part | tr -d '\t' > 5k.txt
paste <(awk "{print \"$PWD\"}" <trainvalno5k.part) trainvalno5k.part | tr -d '\t' > trainvalno5k.txt
数据集搞定。
2.2 训练
在 cfg 目录下创建 yolov3 文件夹,加入 coco.data、coco.names、yolov3.cfg、darknet53.conv.74,并创建 backup 文件夹,形成如下的目录 tree:

其中 backup 为训练中间权重保存目录,coco.names 为类别名称,coco.data 为训练配置文件,差不多长这样:

执行训练指令:
./darknet detector train cfg/yolov3/coco.data cfg/yolov3/yolov3.cfg cfg/yolov3/darknet53.conv.74
其中 darknet53.conv.74 为预训练权重,不要也行,只是一切将从头开始。
附上 darknet53.conv.74 下载传送:https://pjreddie.com/media/files/darknet53.conv.74
训练的时间总是很漫长,但是开心的是看到 loss 在慢慢收敛:
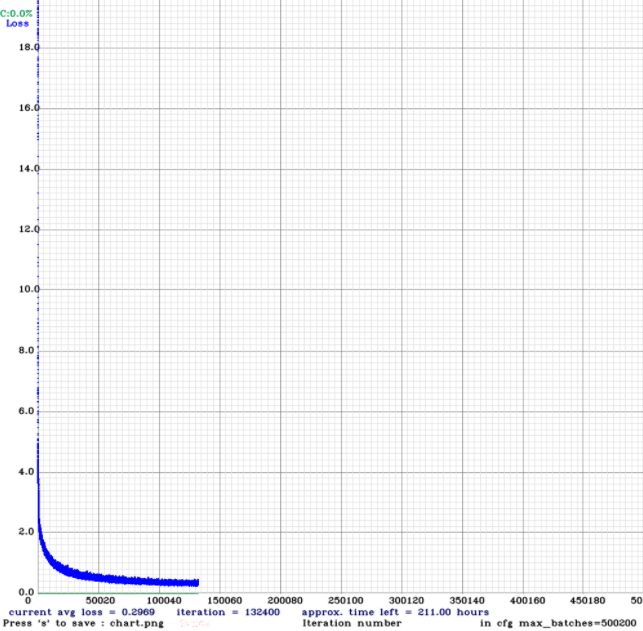
2.3 验证
等把模型训练好了,可以拿来验证一下。
这里拿街景视频进行一下 YOLOv3 的目标检测验证,执行验证指令:
./darknet detector demo cfg/yolov3/coco.data cfg/yolov3/yolov3.cfg cfg/yolov3/backup/yolov3.weights data/street.mp4
检测效果如下:
可以看到检测效果还是不错的。
好了,以上详细分享了 YOLOv3 算法原理和实践,希望我的分享能对你的学习有一点帮助。
【公众号传送】
《【模型训练】目标检测实现分享三:详解 YOLOv3 算法实现》
扫描下方二维码即可关注我的微信公众号【极智视界】,获取更多AI经验分享,让我们用极致+极客的心态来迎接AI !
