pytorch代码实现transformer
参考:https://blog.csdn.net/stupid_3/article/details/83184691
目录
transformer整体结构
Encoder:
Decoder:
Positional Encodings:
Position-wise Feed-Forward network
multi-headed attention(多头注意力机制):
Residuals(残差模块)
Layer normalization的实现
Mask
Padding mask
Sequence mask
encoder代码实现如下:
decoder代码如下:
把encoder和decoder组成Transformer模型!
transformer整体结构
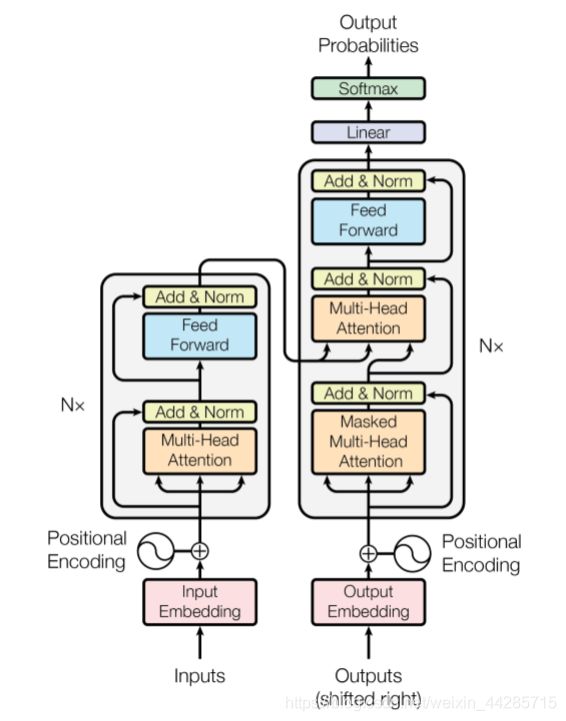 Transformer结构图
Transformer结构图
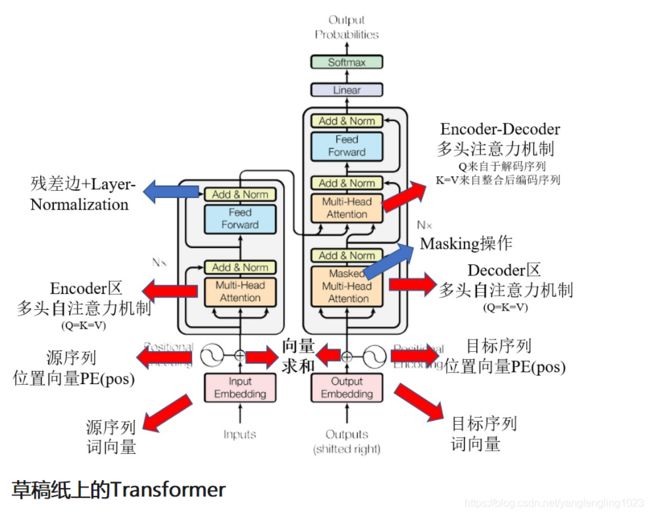
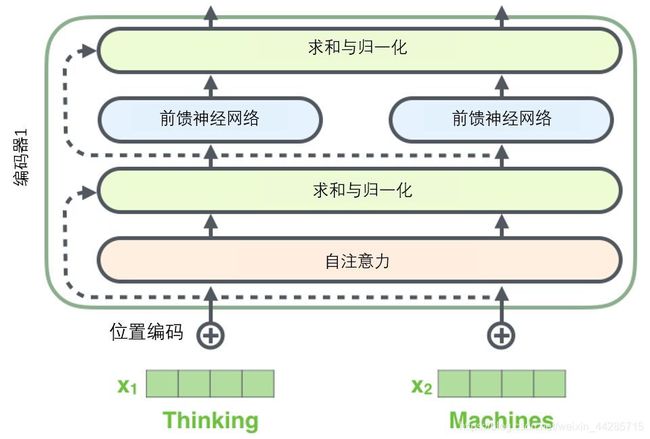
Transformer 的 encoder、decoder 均由 6 个编码器叠加组成,encoder 和decoder在结构上都是相同的,但它们不共享权重。
输入序列经过word embedding和positional encoding相加后,输入到encoder。
输出序列经过word embedding和positional encoding相加后,输入到decoder。
最后,decoder输出的结果,经过一个线性层,然后计算softmax。

Encoder:
首先使用嵌入算法将输入的 word 转换为 vector,encoder 的输入就是 embedding 向量,在每个 encoder 内部,输入向量经过 self-attention,再经过 feed-forward 层,每个 encoder 的输出向量是它正上方 encoder 的输入,即下一个编码器中。向量的大小是一个超参数,通常设置为训练集中最长句子的长度。
每一个 encoder 都分为两个子层:
1、先经multi-head self-attention 层,这一层可以帮助编码器在编码某个特定单词时,也会查看其他单词
2、self-attention 层的输出再传递给一个position-wise feed-forward network(前馈神经网络层,是一个全连接层),在每个位置的前馈网络都是完全相同的
随着模型处理输入序列的每个单词,自注意力会关注整个输入序列的所有单词,帮助模型对本单词更好地进行编码。每个位置的单词在 encoder 中都有自己的路径,self-attention 层中的这些路径之间存在依赖关系,然而在 feed-forward 层不具有那些依赖关系,这样各种路径在流过 feed-forward 层时可以并行执行。


Decoder:
每一个 decoder 也具有上述encoder的两个层,但还有一个编码-解码注意力层,用来帮助解码器关注输入句子的相关部分。
- multi-head self-attention mechanism (对应的 masked multi-head attention). 自注意力层
- multi-head context-attention mechanism (对应的 multi-head attention). 编码-解码注意力层
- position-wise feed-forward network 前馈神经网络层

两个部分,都有一个残差连接(residual connection),然后接着一个Layer Normalization。
Positional Encodings:
序列的顺序是一个很重要的信息,如果缺失了这个信息,可能我们的结果就是:所有词语都对了,但是无法组成有意义的语句!
Positional Encoding 是一种考虑输入序列中单词顺序的方法。encoder 为每个输入 embedding 添加了一个向量,这些向量符合一种特定模式,可以确定每个单词的位置,或者序列中不同单词之间的距离。一句话概括就是:对序列中的词语出现的位置进行编码!如果对位置进行编码,那么我们的模型就可以捕捉顺序信息!
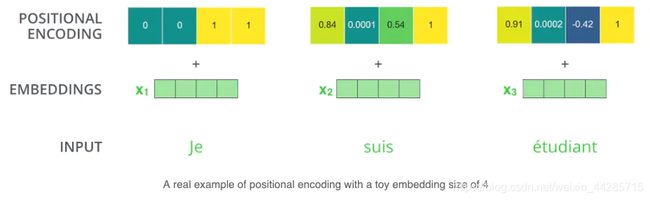

pos是指词语在序列中的位置。可以看出,在偶数位置,使用正弦编码,在奇数位置,使用余弦编码。- dmodel 是模型的维度,论文默认是
512。 - 给定词语的位置pos,我们可以把它编码成dmodel
上面的位置编码是绝对位置编码。但是词语的相对位置也非常重要。
import torch
import torch.nn as nn
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_seq_len):
"""初始化。
Args:
d_model: 一个标量。模型的维度,论文默认是512
max_seq_len: 一个标量。文本序列的最大长度
"""
super(PositionalEncoding, self).__init__()
# 根据论文给的公式,构造出PE矩阵
position_encoding = np.array([
[pos / np.pow(10000, 2.0 * (j // 2) / d_model) for j in range(d_model)]
for pos in range(max_seq_len)])
# 偶数列使用sin,奇数列使用cos
position_encoding[:, 0::2] = np.sin(position_encoding[:, 0::2])
position_encoding[:, 1::2] = np.cos(position_encoding[:, 1::2])
# 在PE矩阵的第一行,加上一行全是0的向量,代表这`PAD`的positional encoding
# 在word embedding中也经常会加上`UNK`,代表位置单词的word embedding,两者十分类似
# 那么为什么需要这个额外的PAD的编码呢?很简单,因为文本序列的长度不一,我们需要对齐,
# 短的序列我们使用0在结尾补全,我们也需要这些补全位置的编码,也就是`PAD`对应的位置编码
pad_row = torch.zeros([1, d_model])
position_encoding = torch.cat((pad_row, position_encoding))
# 嵌入操作,+1是因为增加了`PAD`这个补全位置的编码,
# Word embedding中如果词典增加`UNK`,我们也需要+1。看吧,两者十分相似
self.position_encoding = nn.Embedding(max_seq_len + 1, d_model)
self.position_encoding.weight = nn.Parameter(position_encoding,
requires_grad=False)
def forward(self, input_len):
"""神经网络的前向传播。
Args:
input_len: 一个张量,形状为[BATCH_SIZE, 1]。每一个张量的值代表这一批文本序列中对应的长度。
Returns:
返回这一批序列的位置编码,进行了对齐。
"""
# 找出这一批序列的最大长度
max_len = torch.max(input_len)
tensor = torch.cuda.LongTensor if input_len.is_cuda else torch.LongTensor
# 对每一个序列的位置进行对齐,在原序列位置的后面补上0
# 这里range从1开始也是因为要避开PAD(0)的位置
input_pos = tensor(
[list(range(1, len + 1)) + [0] * (max_len - len) for len in input_len])
return self.position_encoding(input_pos)
Position-wise Feed-Forward network
这是一个全连接网络,包含两个线性变换和一个非线性函数(实际上就是ReLU)。公式如下:
![]()
这个线性变换在不同的位置都表现地一样,并且在不同的层之间使用不同的参数。
import torch
import torch.nn as nn
class PositionalWiseFeedForward(nn.Module):
def __init__(self, model_dim=512, ffn_dim=2048, dropout=0.0):
super(PositionalWiseFeedForward, self).__init__()
self.w1 = nn.Conv1d(model_dim, ffn_dim, 1)
self.w2 = nn.Conv1d(model_dim, ffn_dim, 1)
self.dropout = nn.Dropout(dropout)
self.layer_norm = nn.LayerNorm(model_dim)
def forward(self, x):
output = x.transpose(1, 2)
output = self.w2(F.relu(self.w1(output)))
output = self.dropout(output.transpose(1, 2))
# add residual and norm layer
output = self.layer_norm(x + output)
return output
multi-headed attention(多头注意力机制):
增加multi-headed attention的目的:提高了注意力层的性能。论文默认heads数量是8。
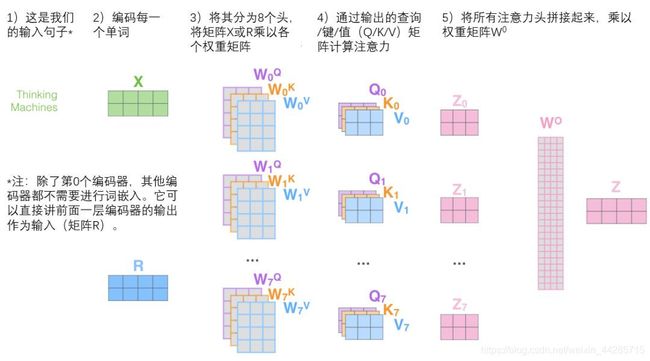
1、multi-headed attention扩展了模型专注于不同位置的能力。在上面的例子中,虽然每个编码都在z1中有或多或少的体现,但是它可能被实际的单词本身所支配。如果我们翻译一个句子,比如“The animal didn’t cross the street because it was too tired”,我们会想知道“it”指的是哪个词,这时模型的“多头”注意机制会起到作用。
2、对于“多头”注意机制,我们有多个查询/键/值权重矩阵集(Transformer使用八个注意力头,因此我们对于每个编码器/解码器有八个矩阵集合)。这些集合中的每一个都是随机初始化的,在训练之后,每个集合都被用来将输入词嵌入(或来自较低编码器/解码器的向量)投影到不同的表示子空间(representation subspaces)中。
具体流程:
multi-headed attention中,每个头保持独立的查询/键/值权重矩阵,从而产生不同的查询/键/值矩阵。


前馈层不需要8个矩阵(Z1…Z7),它只需要一个矩阵(由每一个单词的表示向量组成)。所以我们把这八个矩阵压缩成一个矩阵Z。

import torch
import torch.nn as nn
class MultiHeadAttention(nn.Module):
def __init__(self, model_dim=512, num_heads=8, dropout=0.0):
super(MultiHeadAttention, self).__init__()
self.dim_per_head = model_dim // num_heads
self.num_heads = num_heads
self.linear_k = nn.Linear(model_dim, self.dim_per_head * num_heads)
self.linear_v = nn.Linear(model_dim, self.dim_per_head * num_heads)
self.linear_q = nn.Linear(model_dim, self.dim_per_head * num_heads)
self.dot_product_attention = ScaledDotProductAttention(dropout)
self.linear_final = nn.Linear(model_dim, model_dim)
self.dropout = nn.Dropout(dropout)
# multi-head attention之后需要做layer norm
self.layer_norm = nn.LayerNorm(model_dim)
def forward(self, key, value, query, attn_mask=None):
# 残差连接
residual = query
dim_per_head = self.dim_per_head
num_heads = self.num_heads
batch_size = key.size(0)
# linear projection
key = self.linear_k(key)
value = self.linear_v(value)
query = self.linear_q(query)
# split by heads
key = key.view(batch_size * num_heads, -1, dim_per_head)
value = value.view(batch_size * num_heads, -1, dim_per_head)
query = query.view(batch_size * num_heads, -1, dim_per_head)
if attn_mask:
attn_mask = attn_mask.repeat(num_heads, 1, 1)
# scaled dot product attention
scale = (key.size(-1) // num_heads) ** -0.5
context, attention = self.dot_product_attention(
query, key, value, scale, attn_mask)
# concat heads
context = context.view(batch_size, -1, dim_per_head * num_heads)
# final linear projection
output = self.linear_final(context)
# dropout
output = self.dropout(output)
# add residual and norm layer
output = self.layer_norm(residual + output)
return output, attention
Residuals(残差模块)
residual connection(残差连接)和layer-normalization(层-归一化)。
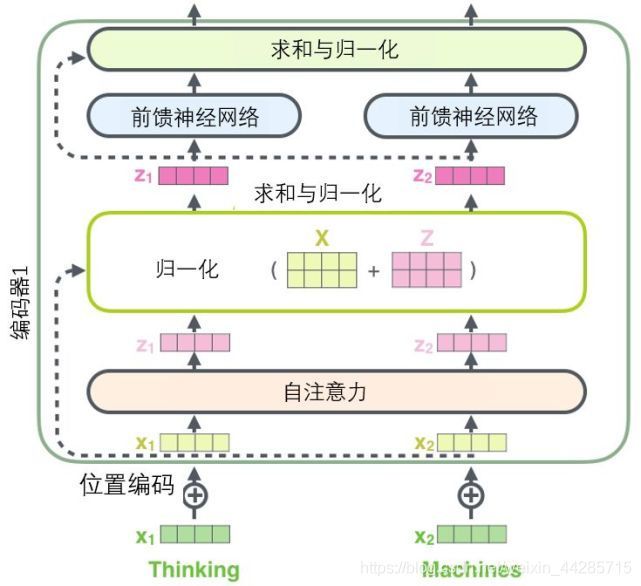
def residual(sublayer_fn,x):
return sublayer_fn(x)+x
Layer normalization的实现
import torch
import torch.nn as nn
class LayerNorm(nn.Module):
"""实现LayerNorm。其实PyTorch已经实现啦,见nn.LayerNorm。"""
def __init__(self, features, epsilon=1e-6):
"""Init.
Args:
features: 就是模型的维度。论文默认512
epsilon: 一个很小的数,防止数值计算的除0错误
"""
super(LayerNorm, self).__init__()
# alpha
self.gamma = nn.Parameter(torch.ones(features))
# beta
self.beta = nn.Parameter(torch.zeros(features))
self.epsilon = epsilon
def forward(self, x):
"""前向传播.
Args:
x: 输入序列张量,形状为[B, L, D]
"""
# 根据公式进行归一化
# 在X的最后一个维度求均值,最后一个维度就是模型的维度
mean = x.mean(-1, keepdim=True)
# 在X的最后一个维度求方差,最后一个维度就是模型的维度
std = x.std(-1, keepdim=True)
return self.gamma * (x - mean) / (std + self.epsilon) + self.beta
Mask
padding mask在所有的scaled dot-product attention里面都需要用到,sequence mask只有在decoder的self-attention里面用到。
Padding mask
什么是padding mask呢?回想一下,我们的每个批次输入序列长度是不一样的!也就是说,我们要对输入序列进行对齐!具体来说,就是给在较短的序列后面填充0。因为这些填充的位置,其实是没什么意义的,所以我们的attention机制不应该把注意力放在这些位置上,所以我们需要进行一些处理。
具体的做法是,把这些位置的值加上一个非常大的负数(可以是负无穷),这样的话,经过softmax,这些位置的概率就会接近0!
而我们的padding mask实际上是一个张量,每个值都是一个Boolen,值为False的地方就是我们要进行处理的地方。
def padding_mask(seq_k, seq_q):
# seq_k和seq_q的形状都是[B,L]
len_q = seq_q.size(1)
# `PAD` is 0
pad_mask = seq_k.eq(0)
pad_mask = pad_mask.unsqueeze(1).expand(-1, len_q, -1) # shape [B, L_q, L_k]
return pad_mask
Sequence mask
是对于一个序列,在time_step为t的时刻,我们的解码输出应该只能依赖于t时刻之前的输出,而不能依赖t之后的输出。因此我们需要想一个办法,把t之后的信息给隐藏起来。
那么具体怎么做呢?也很简单:产生一个上三角矩阵,上三角的值全为1,下三角的值权威0,对角线也是0。把这个矩阵作用在每一个序列上,就可以达到我们的目的啦。
def sequence_mask(seq):
batch_size, seq_len = seq.size()
mask = torch.triu(torch.ones((seq_len, seq_len), dtype=torch.uint8),
diagonal=1)
mask = mask.unsqueeze(0).expand(batch_size, -1, -1) # [B, L, L]
return mask
attn_mask参数有几种情况?分别是什么意思?
- 对于decoder的self-attention,里面使用到的scaled dot-product attention,同时需要
padding mask和sequence mask作为attn_mask,具体实现就是两个mask相加作为attn_mask。 - 其他情况,
attn_mask一律等于padding mask。
encoder代码实现如下:
import torch
import torch.nn as nn
class EncoderLayer(nn.Module):
"""Encoder的一层。"""
def __init__(self, model_dim=512, num_heads=8, ffn_dim=2018, dropout=0.0):
super(EncoderLayer, self).__init__()
self.attention = MultiHeadAttention(model_dim, num_heads, dropout)
self.feed_forward = PositionalWiseFeedForward(model_dim, ffn_dim, dropout)
def forward(self, inputs, attn_mask=None):
# self attention
context, attention = self.attention(inputs, inputs, inputs, padding_mask)
# feed forward network
output = self.feed_forward(context)
return output, attention
class Encoder(nn.Module):
"""多层EncoderLayer组成Encoder。"""
def __init__(self,
vocab_size,
max_seq_len,
num_layers=6,
model_dim=512,
num_heads=8,
ffn_dim=2048,
dropout=0.0):
super(Encoder, self).__init__()
self.encoder_layers = nn.ModuleList(
[EncoderLayer(model_dim, num_heads, ffn_dim, dropout) for _ in
range(num_layers)])
self.seq_embedding = nn.Embedding(vocab_size + 1, model_dim, padding_idx=0)
self.pos_embedding = PositionalEncoding(model_dim, max_seq_len)
def forward(self, inputs, inputs_len):
output = self.seq_embedding(inputs)
output += self.pos_embedding(inputs_len)
self_attention_mask = padding_mask(inputs, inputs)
attentions = []
for encoder in self.encoder_layers:
output, attention = encoder(output, self_attention_mask)
attentions.append(attention)
return output, attentions
decoder代码如下:
import torch
import torch.nn as nn
class DecoderLayer(nn.Module):
def __init__(self, model_dim, num_heads=8, ffn_dim=2048, dropout=0.0):
super(DecoderLayer, self).__init__()
self.attention = MultiHeadAttention(model_dim, num_heads, dropout)
self.feed_forward = PositionalWiseFeedForward(model_dim, ffn_dim, dropout)
def forward(self,
dec_inputs,
enc_outputs,
self_attn_mask=None,
context_attn_mask=None):
# self attention, all inputs are decoder inputs
dec_output, self_attention = self.attention(
dec_inputs, dec_inputs, dec_inputs, self_attn_mask)
# context attention
# query is decoder's outputs, key and value are encoder's inputs
dec_output, context_attention = self.attention(
enc_outputs, enc_outputs, dec_output, context_attn_mask)
# decoder's output, or context
dec_output = self.feed_forward(dec_output)
return dec_output, self_attention, context_attention
class Decoder(nn.Module):
def __init__(self,
vocab_size,
max_seq_len,
num_layers=6,
model_dim=512,
num_heads=8,
ffn_dim=2048,
dropout=0.0):
super(Decoder, self).__init__()
self.num_layers = num_layers
self.decoder_layers = nn.ModuleList(
[DecoderLayer(model_dim, num_heads, ffn_dim, dropout) for _ in
range(num_layers)])
self.seq_embedding = nn.Embedding(vocab_size + 1, model_dim, padding_idx=0)
self.pos_embedding = PositionalEncoding(model_dim, max_seq_len)
def forward(self, inputs, inputs_len, enc_output, context_attn_mask=None):
output = self.seq_embedding(inputs)
output += self.pos_embedding(inputs_len)
self_attention_padding_mask = padding_mask(inputs, inputs)
seq_mask = sequence_mask(inputs)
self_attn_mask = torch.gt((self_attention_padding_mask + seq_mask), 0)
self_attentions = []
context_attentions = []
for decoder in self.decoder_layers:
output, self_attn, context_attn = decoder(
output, enc_output, self_attn_mask, context_attn_mask)
self_attentions.append(self_attn)
context_attentions.append(context_attn)
return output, self_attentions, context_attentions
把encoder和decoder组成Transformer模型!
代码如下:
import torch
import torch.nn as nn
class Transformer(nn.Module):
def __init__(self,
src_vocab_size,
src_max_len,
tgt_vocab_size,
tgt_max_len,
num_layers=6,
model_dim=512,
num_heads=8,
ffn_dim=2048,
dropout=0.2):
super(Transformer, self).__init__()
self.encoder = Encoder(src_vocab_size, src_max_len, num_layers, model_dim,
num_heads, ffn_dim, dropout)
self.decoder = Decoder(tgt_vocab_size, tgt_max_len, num_layers, model_dim,
num_heads, ffn_dim, dropout)
self.linear = nn.Linear(model_dim, tgt_vocab_size, bias=False)
self.softmax = nn.Softmax(dim=2)
def forward(self, src_seq, src_len, tgt_seq, tgt_len):
context_attn_mask = padding_mask(tgt_seq, src_seq)
output, enc_self_attn = self.encoder(src_seq, src_len)
output, dec_self_attn, ctx_attn = self.decoder(
tgt_seq, tgt_len, output, context_attn_mask)
output = self.linear(output)
output = self.softmax(output)
return output, enc_self_attn, dec_self_attn, ctx_attn