Windows下PyCharm远程连接Spark
我这里的spark部署在虚拟机内,使用的版本为:
python3.8
hadoop3.3
spark3.2
java8
为了防止报错,在windows环境我也安装了python3.8和虚拟机同步
此时linux集群已经部署好了spark环境
1、配置Hadoop DLL
在编写spark时可能会用到hadoop的一些功能,所以需要配置hadoop的运行环境
文件可以在github上下载,https://github.com/cdarlint/winutils
因为没有对应的hadoop版本,我用的是对应hadoop3.1的文件,目前没有发现问题
![]()
下载完成后将bin目录的hadoop.dll文件复制进C盘的System32下
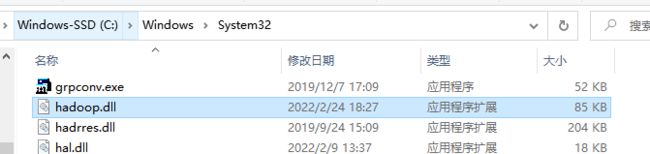
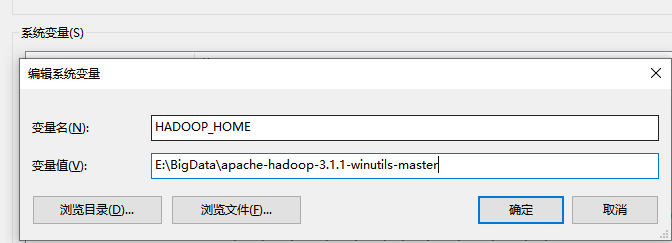
配置完成后,需要加上环境变量
变量名为HADOOP_HOME
变量值为 apache-hadoop-3.1.1-winutils-master文件的位置
2、下载pyspark库
本机的python版本最好和虚拟机保持一致,以免出现问题
可以使用anaconda创建虚拟环境
pip install pyspark
3、配置pycharm
3.1新建python工程,配置解释器
解释器选择之前创建的虚拟环境下的python.exe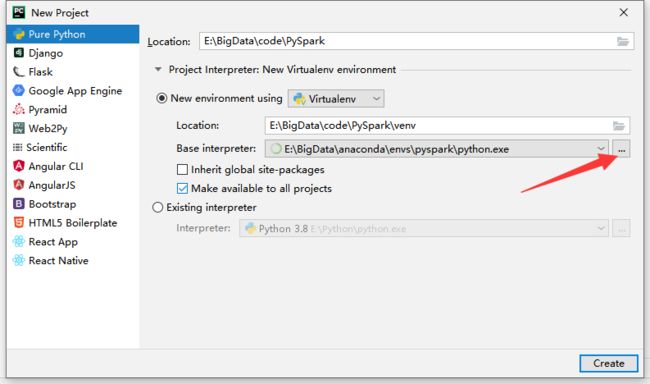
3.2远程连接linux的python解释器
点击pycharm左上角的File -> Settings,找到Python Interpreter
点击右上角的齿轮,选择add增加解释器
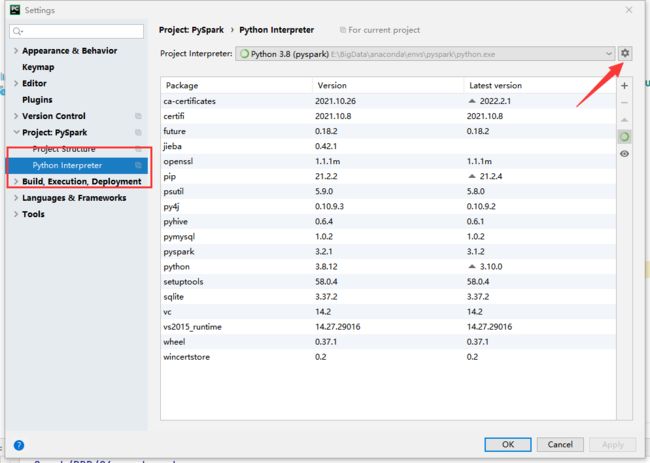
进入后选择SSH,填入主机名和用户名,点击next
因为linux我使用的也是anaconda安装python,且anaconda的所有者是用户user,所以我这里填的是user
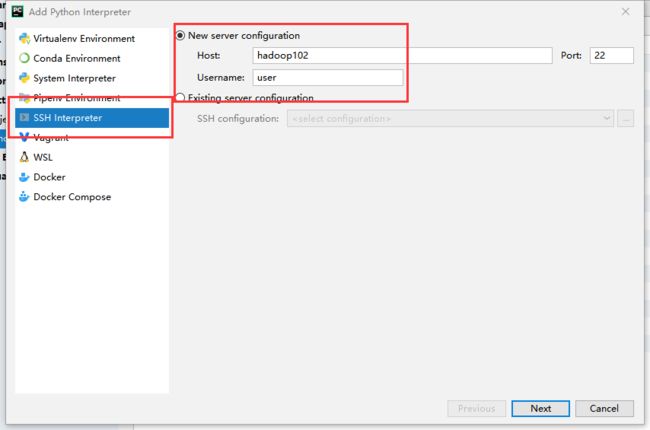
然后填入登录密码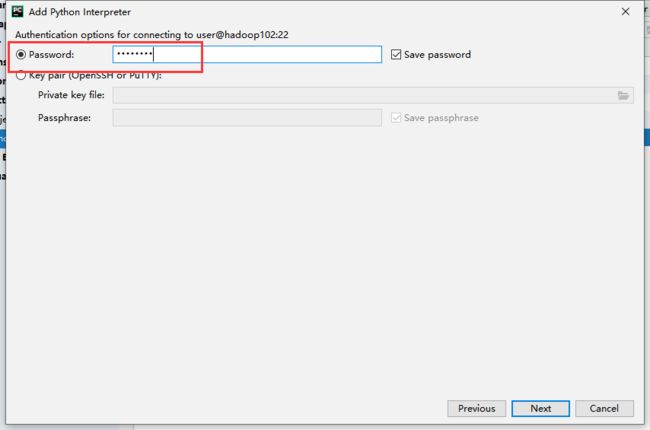
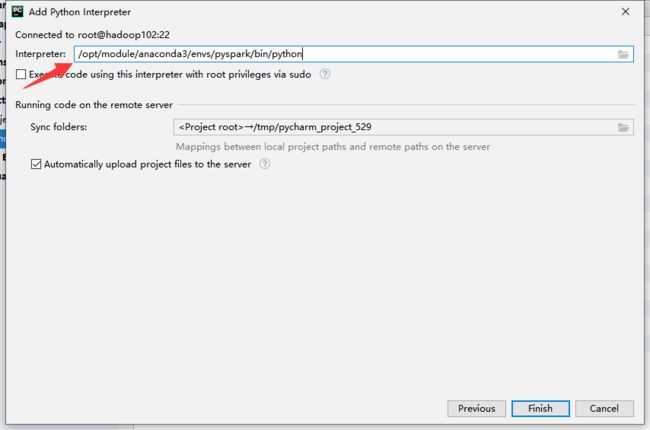
然后填入linux下的python的位置,点击finish
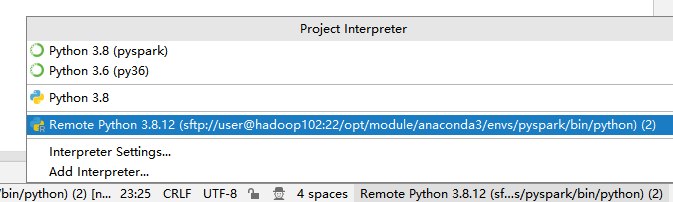
完成后可以在pycharm的右下角选择解释器
4、一些环境变量
为了确保spark在运行时少出现问题,需要在windows配置一些环境变量
因为Spark程序是运行在JVM基础之上的,所以需要配置JAVA_HOME

PYSPARK_PYTHON指向python的解释器,这是为了本地模式能运行spark程序
