Spark Streaming(一)简介与架构
现在工作中正在使用flink,避免对Spark流式处理的遗忘,在此进行总结。主要分为以下几个方面,均附有实际代码:
- Spark Streaming简介
- Spark Streaming架构
- 基础概念
- 作业提交
- Spark Streaming窗口操作
- Spark Streaming容错性分析
- WAL工作原理
- Spark Streaming整合Kafka
- createStream与createDirectStream的区别
- 整合kafka0.8与Kafka0.10的案例
- Spark Streaming应⽤用程序如何保证Exactly-Once?
1. Spark Streaming简介
spark家族的强大主要是可以针对不同的场景可以使用不同的依赖包。比方说基于spark SQL实现数据的业务逻辑处理,使用Spark Streaming进行数据的流式处理,使用Spark MLib实现算法。使用Spark GraphX进行图计算。这里主要讲解其中的流式处理功能。
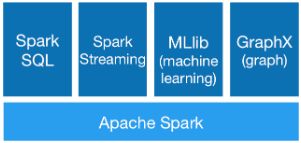
Spark流是对于Spark核心API的拓展,从而支持对于实时数据流的可拓展,高吞吐量和容错性流处理。数据可以由多个源取得,例如:Kafka,Flume,Twitter,ZeroMQ,Kinesis或者TCP接口,同时可以使用由如map,reduce,join和window这样的高层接口描述的复杂算法进行处理。最终,处理过的数据可以被推送到文件系统,数据库和HDFS。

1.Spark Streaming简介
1.1Spark Streaming 将接收到的实时流数据,按照一定时间间隔,对数据进行拆分,交给Spark Engine引擎处理,最终得到一批批的结果。
1.2每一批数据,在Spark内对应一个RDD实例。
1.3Dstream可以看做一组RDDs,即RDD的一个序列。


2.DStream:Spark Streaming提供了表示连续数据流的、高度抽象的被称为离散流的DStream
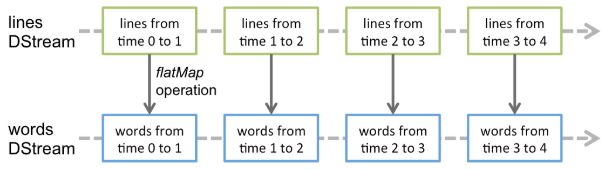
2.1任何对DStream的操作都会转变为对底层RDD的操作。
2.2Spark Streaming程序中一般会有若干个对DStream的操作。DStreamGraph就是由这些操作的依赖关系构成。
将连续的数据持久化、离散化,然后进行批量处理。
2.Spark Streaming架构
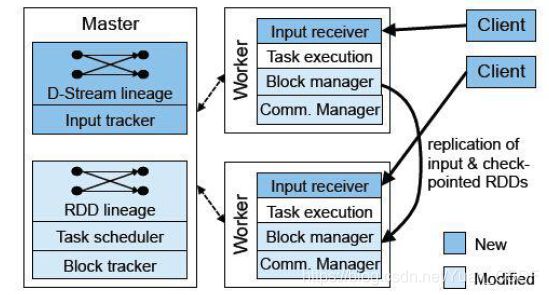
1.基础概念
Master:记录Dstream之间的依赖关系或者血缘关系,并负责任务调度以生成新的RDD
Worker:1.从网络接受数据并存储到内存,2.执行RDD计算
Client:负责向Spark Streaming中灌入数据(flume kafka)
2.作业提交
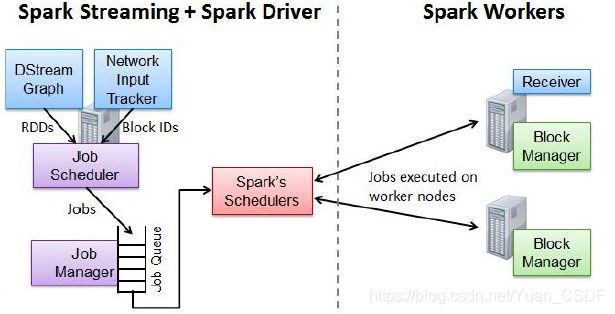
Network Input Tracker:跟踪每一个网络received数据,并将其映射到相应的input Dstream上。
Job Scheduler:周期性的访问DStream Graph并生成Spark Job,并将其交给Job Manager执行
Job Manager:获取任务队列,并执行Spark任务。
3.Streaming窗口操作
Spark提供了一组窗口操作,通过滑动窗口技术对大规模数据的增量进行统计分析。
Window Operation:定时进行一定时间段内的数据处理。

4.Streaming容错性分析
实时的流式处理系统必须是7*24运行的,同时可以从各种各样的系统错误中恢复,在设计之初,Spark Streaming就支持driver和worker节点的错误恢复。
Worker容错:spark和rdd的保证worker节点的容错性。spark streaming构建在spark之上,所以它的worker节点也是同样的容错机制。
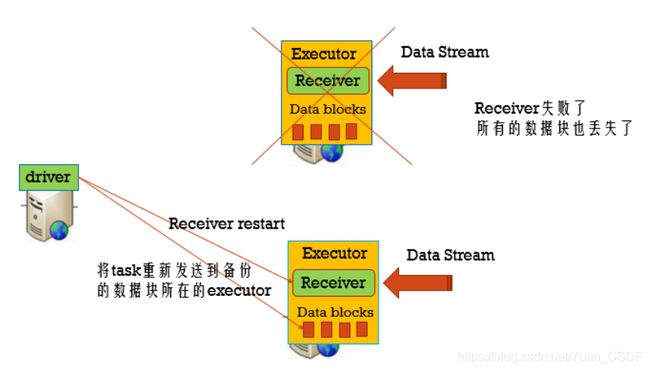
Tasks和Receiver自动的重启,不需要做任何的配置
Driver容错:依赖WAL持久化日志
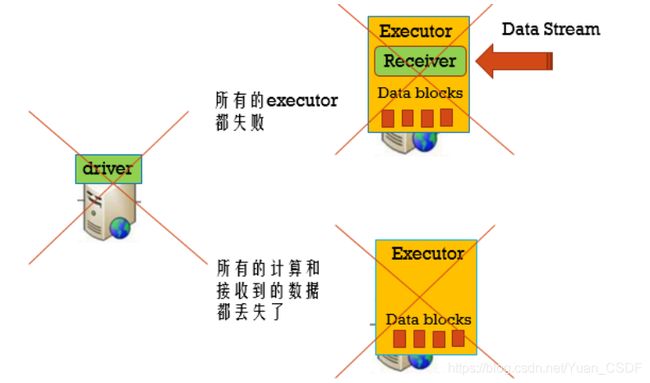
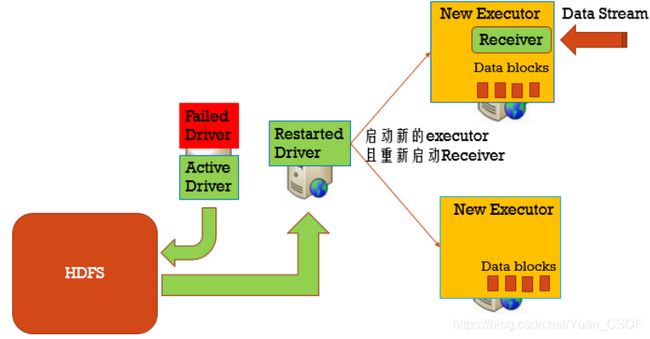
用checkpoint机制恢复失败的Driver,定期的将Driver信息写⼊入到HDFS中。
1. checkpoint(Driver的元数据信息存储起来)
2. 自动重启
1.Standalone任务:spark-submit中增加以下参数: --supervise
2.yarn模式:在yarn配置中设置yarn.resourcemanager.am.max-attemps 重试几次?3
3.开启checkpoint机制:streamingContext.setCheckpoint(hdfsDirectory)
注意:1.给streamingContext设置checkpoint的目录,该目录必须是HADOOP支持的文件系统hdfs,用来保存WAL和做Streaming的checkpoint。
2.spark.streaming.receiver.writeAheadLog.enable设置为true,receiver才会有WAL。
总结:这种方案如果我们升级程序,会丢数据
5.Streaming中WAL工作原理
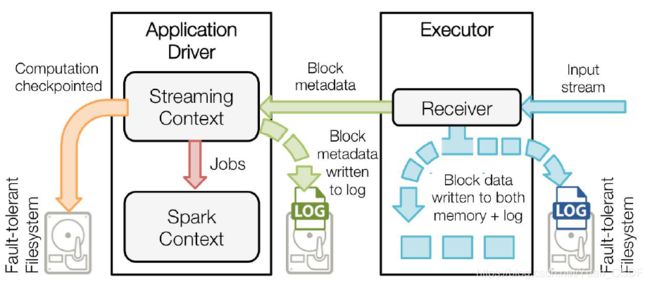
1.接收器把数据流打包成块,存储在executor的内存中,如果开启了WAL,将会把数据写入到存在容错文件系统的日志文件中。
2.接收到的数据块的元信息发送给driver中的StreamingContext,这些元数据包括:executor内存中数据块的引用ID和日志文件中数据块的偏移信息。
3.每一个批处理间隔,StreamingContext使用块信息用来生成RDD和jobs,SparkContext执行这些job用于处理executor内存中的数据块。
4.以便于恢复,流式处理会周期的被checkpoint到文件中。
Driver失败重启后的恢复流程:
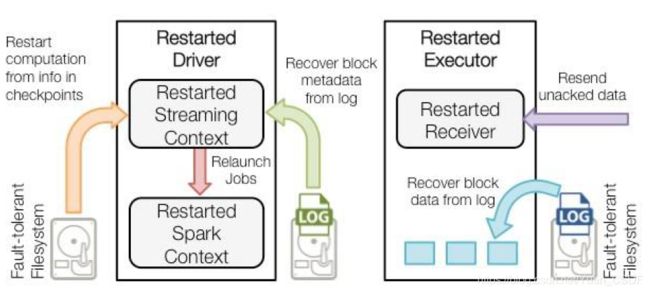
1.checkpiointed的信息是用于启动driver,重新构建上下文和重启所有的receiver。
2.所有的块信息对已恢复计算很重要。
3.重新生成未完成的job。
4.当job重新执行的时候,块数据将会直接从日志中读取。
5.缓冲的数据没有写到WAL中去将会被重新发送。