R3Det: Refined Single-Stage Detector with Feature Refinement for Rotating Object
本文针对旋转目标的检测提出了R3det。论文地址:https://arxiv.org/abs/1908.05612
1.Introduciton
目前,旋转目标检测面临三个主要挑战:
- 待检测目标纵横比较大
- 待检测目标的排列较为密集
- 类别不平衡
本文讨论了如何设计一个准确和快速的旋转目标检测器。文章提出了一个refined one-stage 旋转检测器,其设计策略结合了水平anchor的高召回率和旋转anchor对密集场景的适应性两方面的优点,在第一个阶段使用水平anchor,从而获得更快的速度和更多的proposals,在refinement stage使用了refined 旋转anchors以适应密集场景; 此外,设计了特征精细化模块(FRM),利用特征插值获得refined anchor的位置信息,然后对特征图进行重建以实现特征对齐。
2. Proposed Method
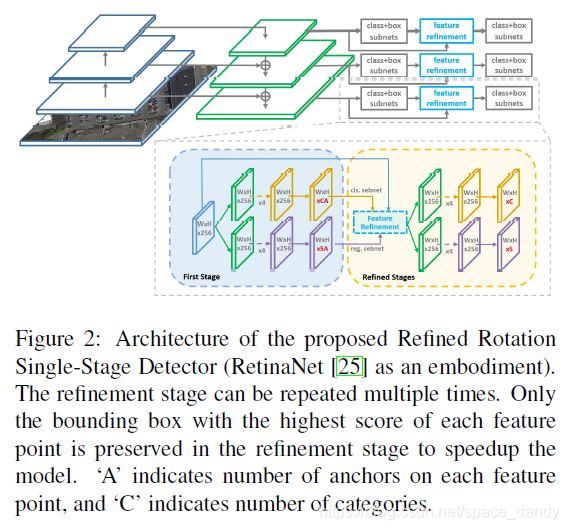
该实例基于RetinaNet,网络后增加了refinement stage来对bounding box进行refine,FRM用于重建特征图。
2.1 Rotation RetinaNet
该网络为一个先进的one-stage检测器,包括两个部分:backbone网络和分类回归子网络。Backbone网络为FPN,FPN通过自上而下的路径和横向连接来增强了卷积网络,从而有效地从单个分辨率的输入图像构建丰富的多尺度特征金字塔,每层金字塔均可以用于不同尺度的目标检测;FPN的每一层均与一个分类回归子网络相连。RetinaNet设计了focal loss来解决类别不平衡问题。
本文使用(x,y,w,h,theta)五个参数表述旋转矩形,theta表示与x轴的锐角,变化范围为[-90,0),另一侧为w。因此,需要预测子网络中的附加角度偏移:

上式中,x,y,w,h,theta表示box的重心坐标,宽、高和角度;x.x_a.x'分别为ground-truth,anchor box和预测box。多类别的损失函数定义如下:

上式中,N表示anchor的个数,t'_n取值为0或1(foreground为1,background为0,background无回归);v'_*j表示预测的偏移矢量,v_*j表示ground-tryth的目标向量。tn为目标类别,pn为sigmoid计算的各类别概率分布。L_cls为focal loss和L_reg为smooth L1 loss。
2.2 Refined Rotation RetinaNet
在不同的refinement stage中使用了不同的IoU阈值;在first stage前景(foreground)和背景(background)的阈值分别为0.5和0.4,first refinement stage二者分别使用了0.5和0.4,如果refinement stage重复了多次,剩余的分别为0.7和0.6。Refine detector的总体损失为:

Li为第i个refinement阶段的损失,ai为权衡系数,默认为1.
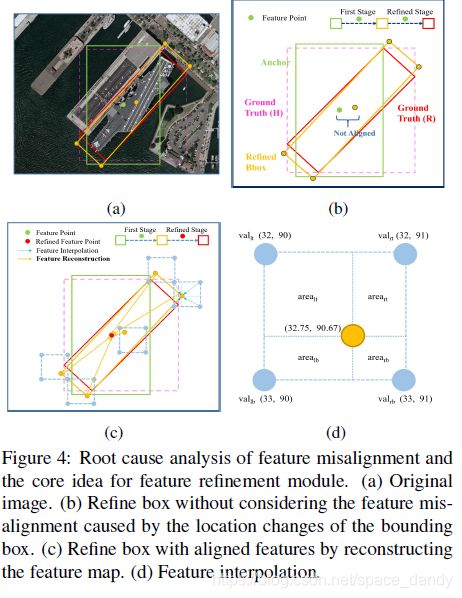
2.3 Feature Refinment Module
许多refined 检测器使用相同的特征映射进行多个分类和回归,没有考虑边界框位置变化引起的特征偏移,对长宽比较大或者样本量小的类别不利。本文提出将refined边界框的位置信息重新编码到响应的特征点,从而重建整个特征映射,实现特征对齐。
特征插值公式为:
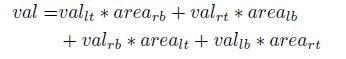
FRM的结构和伪代码如下:


具体操作位:利用双向卷积将特征映射相加来得到新的特征,细化阶段只保留每个特征点得分最高的bounding box,以提高速度,并同时保证一个特征点只对应一个细化的边界框。对于特征映射的每个特征点,根据refined bbox的五个坐标在特征图上获得对应的特征向量,通过双线性插值得到更精确地特征向量,然后添加五个特征向量并替换当前的特征向量,遍历特征点之后,重建了整个特征地图,最后将重构后的特征图加入原始特征图完成整个过程。
FRM可以保存完整的卷积结构,具有更高的效率和更少的参数。
3.在DOTA数据集上的测试
DOTA数据集包含15个类别。本文作者在实验过程中将图像分为600x600的子图并将其缩放至800*800。训练时,backbones选择了Resnet-FPN和MobileNetv2-FPN,所有的backbones在ImageNet上训练,anchor在金字塔P3-P7等级上的面积为32x32-512x512,每个金字塔层次使用了7个纵横比(1,1/2,2,1/3,3,5,1/5)和3个尺度(2^0,2^(1/3),2^(2/3)),对旋转anhor添加了6个角度(-90,-75,-60,-45,-30,-15)