关于urllib
目录
介绍:
1)打开网址
请求我自己的博客,我的博客为qq_62932195的博客_heart_6662_CSDN博客
查看状态status函数
2)超时设置
异常检测
3)更深请求
请求头添加(UA伪装)
4)链接解析
1.urlparse
2.urlunparse
3.urlsplit
4.urlunsplit()
5.urljoin
6.urlencode
7.parse_qs
9.quote(发言!)
10.unquote
5)Robots 协议(这就是规则)
6)万能视频下载
介绍:
材料来源川川大佬
爬虫之祖urlib
urlib库有几个模块
- request :用于请求网址的模块
- error:异常处理模块
- parse:用于修改拼接等的模块
- robotparser:用来判断哪些网站可以爬,哪些网站不可以爬
1)打开网址
请求我自己的博客,我的博客为qq_62932195的博客_heart_6662_CSDN博客
import urllib.request
resp = urllib.request.urlopen('https://blog.csdn.net/qq_62932195')
print(resp.read().decode('utf-8'))
运行结果: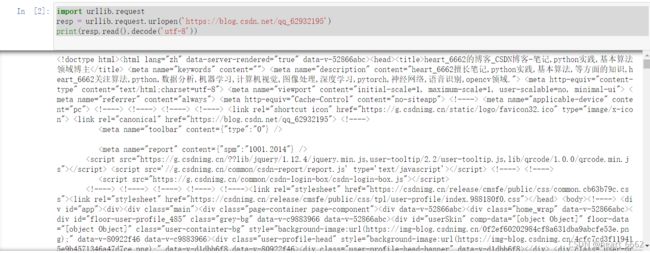
查看状态status函数
import urllib.request
resp = urllib.request.urlopen('https://blog.csdn.net/qq_62932195')
print(resp.status)

查看Facebook
import urllib.request
response = urllib.request.urlopen('https://www.facebook.com/')
print(response.status) 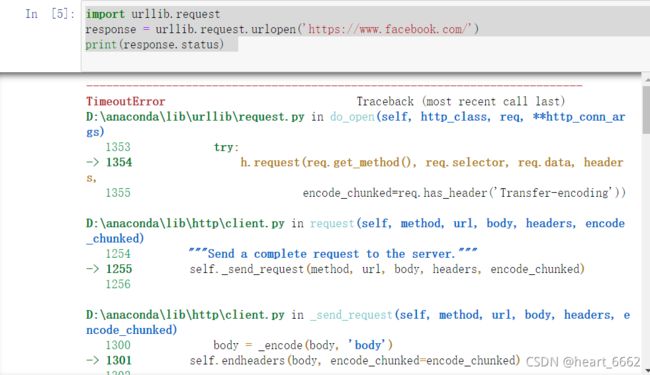
请求超时,非常正常,毕竟有qiang
2)超时设置
比如这个网站超过十秒就不请求
import urllib.request
response = urllib.request.urlopen('https://www.facebook.com/',timeout=10)
print(response.status)
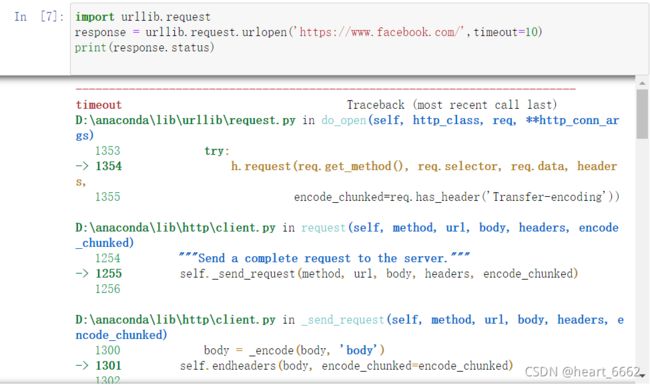
异常检测
try…except语法捕获异常
import socket
import urllib.request
import urllib.error
try:
response = urllib.request.urlopen('https://github.com/', timeout=5)
except urllib.error.URLError as e:
if isinstance(e.reason, socket.timeout):
print('请求超时')

3)更深请求
- 第一行导入模块
- 第二行用Requests请求网址
- 第三行再用urlopen打开网址
- 第四行用read打印内容
import urllib.request
request = urllib.request.Request("https://blog.csdn.net/qq_62932195")
resp = urllib.request.urlopen(request)
print(resp.read().decode("utf-8"))
和之前简单请求的结果一样
请求头添加(UA伪装)
模拟浏览器去爬取内容,主要是为了被反扒
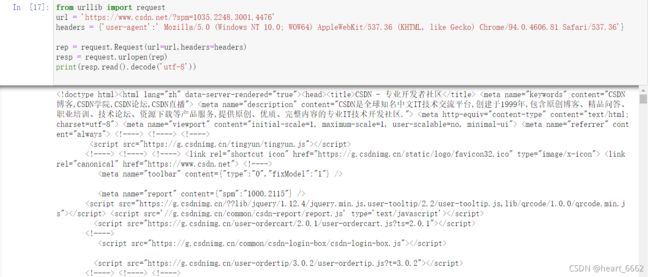
from urllib import request
url = 'https://www.csdn.net/?spm=1035.2248.3001.4476'
headers = {'user-agent':' Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'}
rep = request.Request(url=url,headers=headers)
resp = request.urlopen(rep)
print(resp.read().decode('utf-8'))
4)链接解析
1.urlparse
from urllib.parse import urlparse
s=urlparse('https://www.csdn.net/?spm=1011.2124.3001.5359')#解析的网址
print(type(s),s)#打印类型和解析结果
分析下结果:
ParseResult这个类型对象,打印了六个部分结果:
scheme是协议,这里协议就是https
netloc是域名,域名是啥就步说了吧,自己百度
path是访问路径
params就是参数
query就是查询条件,一般用作get类型的url
fragment就是描点,用于定位页面内部下拉位置
2.urlunparse
与第一个对立,他接受的参数是可迭代对象,对象长度必须是6
from urllib.parse import urlunparse
data=['http','www.baidu.com','index.com','user','a=7','comment']
print(urlunparse(data))
构造了一个url

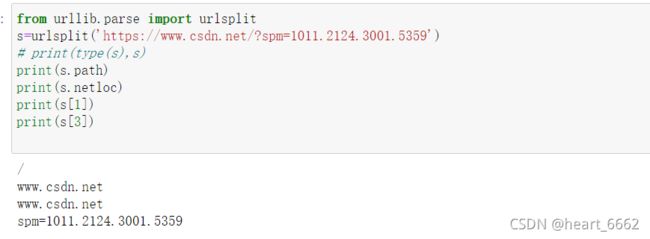
3.urlsplit
跟urlparse类似,知识返回结果只有五个,params合并到了path中
from urllib.parse import urlsplit
s=urlsplit('https://www.csdn.net/?spm=1011.2124.3001.5359')
print(type(s),s)
![]()
但是呢,SplitResult是元组类型,可以通过索取获得想要的,不用都打印出来
from urllib.parse import urlsplit
s=urlsplit('https://www.csdn.net/?spm=1011.2124.3001.5359')
# print(type(s),s)
print(s.path)
print(s.netloc)
print(s[1])
print(s[3])
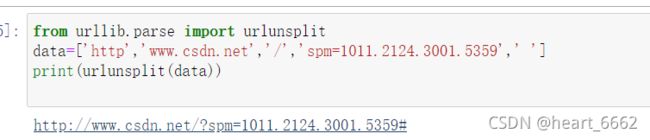
4.urlunsplit()
各个部分组合成完整的链接,长度必须是5
from urllib.parse import urlunsplit
data=['http','www.csdn.net','/','spm=1011.2124.3001.5359',' ']
print(urlunsplit(data))
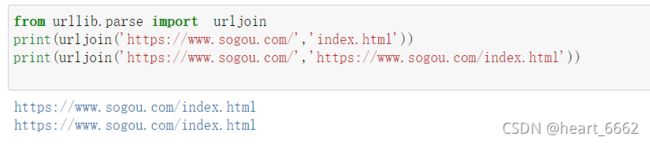
5.urljoin
就是对链接的补充合并
from urllib.parse import urljoin
print(urljoin('https://www.sogou.com/','index.html'))
print(urljoin('https://www.sogou.com/','https://www.sogou.com/index.html'))
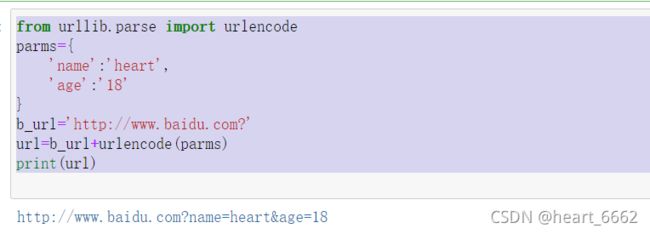
6.urlencode
构造url
from urllib.parse import urlencode
parms={
'name':'heart',
'age':'18'
}
b_url='http://www.baidu.com?'
url=b_url+urlencode(parms)
print(url)
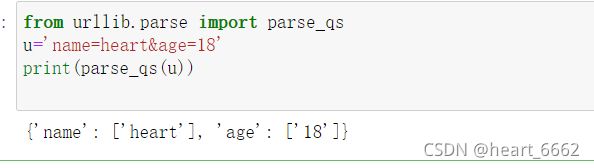
7.parse_qs
from urllib.parse import parse_qs
u='name=heart&age=18'
print(parse_qs(u))
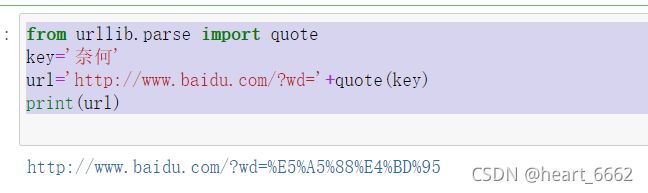
9.quote(发言!)
中文转换为url格式。对中文进行编码
from urllib.parse import quote
key='奈何'
url='http://www.baidu.com/?wd='+quote(key)
print(url)
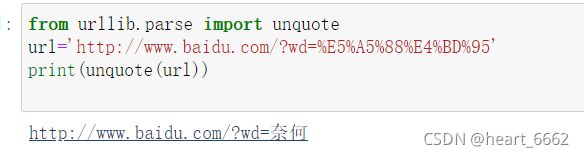
10.unquote
把被编码后的中文还原
from urllib.parse import unquote
url='http://www.baidu.com/?wd=%E5%A5%88%E4%BD%95'
print(unquote(url))
5)Robots 协议(这就是规则)
它告诉我们不要什么都去爬,所以我们来看下哪些可以爬,哪些不可以爬,这就要根据robots协议了
https://www.csdn.net/robots.txt
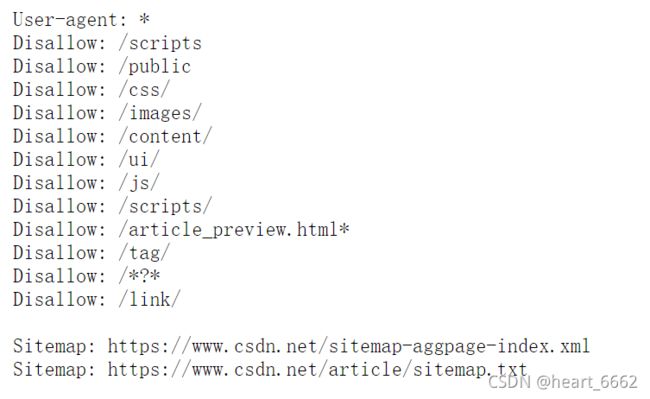
user-agent:后面是蜘蛛的名称,表示一种代理的意思;
disallowed: 表示禁止,后面的内容蜘蛛禁止抓取;
allowed :表示允许蜘蛛抓取后面文件的内容;
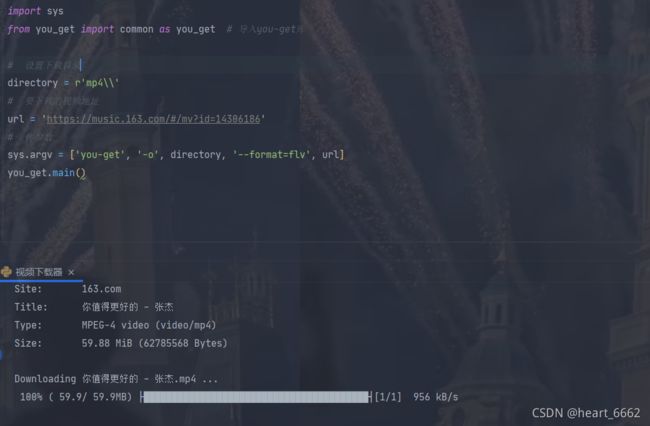
6)万能视频下载
win+r 输入cmd 复制下面代码后回车
下载库
pip install you_get
import sys
from you_get import common as you_get# 导入you-get库
# 设置下载目录
directory=r'mp4\\'
# 要下载的视频地址
url='https://music.163.com/#/mv?id=14306186'
# 传参数
sys.argv=['you-get','-o',directory,'--format=flv',url]
you_get.main()
材料来源川川大佬