神经网络入门
神经网络入门
文章目录
- 神经网络入门
-
- 1、神经网络剖析
- 2、Keras
- 3、电影评论分类:二分类问题
-
- 总结
- 4、新闻分类:多分类问题
-
- 总结
- 5、预测房价:回归问题
-
- 总结
- 6、总结
神经网络的核心组件,即 层、 网络、 目标函数和 优化器。
1、神经网络剖析
-
训练神经网络主要围绕以下四个方面:
- 层,多个层组合成网络(或模型);
- 输入数据和相应的目标;
- 损失函数,即用于学习的反馈信号;
- 优化器,决定学习过程如何进行。
-
层:深度学习的基础组件
神经网络的基本数据结构是层。层是一个数据处理模块,将一个或多个输入张量转换为一个或多个输出张量。
有些层是无状态的,但大多数的层是有状态的,即层的权重。权重是利用随机梯度下降学到的一个或多个张量,其中包含网络的知识。
不同的张量格式与不同的数据处理类型需要用到不同的层:
- 简单的向量数据保存在形状为 (samples, features) 的 2D 张量中,通常用密集连接层[ densely connected layer,也叫全连接层( fully connected layer)或密集层( dense layer),对应于 Keras 的 Dense 类]来处理;
- 序列数据保存在形状为 (samples, timesteps, features) 的 3D 张量中,通常用循环层( recurrent layer,比如 Keras 的 LSTM 层)来处理;
- 图像数据保存在 4D 张量中,通常用二维卷积层( Keras 的 Conv2D)来处理。
在 Keras 中,构建深度学习模型就是将相互兼容的多个层拼接在一起,以建立有用的数据变换流程。这里层兼容性( layer compatibility)具体指的是每一层只接受特定形状的输入张量,并返回特定形状的输出张量。
from keras import layers layers = layers.Dense(32, input_shape=(784,))我们创建了一个层,只接受第一个维度大小为 784 的 2D 张量(第 0 轴是批量维度,其大小没有指定,因此可以任意取值)作为输入。这个层将返回一个张量,第一个维度的大小变成了 32。
因此,这个层后面只能连接一个接受 32 维向量作为输入的层。使用 Keras 时,你无须担心兼容性,因为向模型中添加的层都会自动匹配输入层的形状:
from keras import models from keras import layers model = models.Sequential() model.add(layers.Dense(32, input_shape=(784,))) model.add(layers.Dense(32))其中第二层没有输入形状( input_shape)的参数,相反,它可以自动推导出输入形状等于上一层的输出形状。
-
模型:层构成的网络
深度学习模型是层构成的有向无环图。
网络的拓扑结构定义了一个假设空间( hypothesis space)。之前机器学习的定义:“在预先定义好的可能性空间中,利用反馈信号的指引来寻找输入数据的有用表示。”选定了网络拓扑结构,意味着将可能性空间(假设空间)限定为一系列特定的张量运算,将输入数据映射为输出数据。然后,你需要为这些张量运算的权重张量找到一组合适的值。
-
损失函数与优化器:配置学习过程的关键
一旦确定了网络架构,你还需要选择以下两个参数:
- 损失函数( 目标函数)——在训练过程中需要将其最小化。它能够衡量当前任务是否已成功完成;
- 优化器——决定如何基于损失函数对网络进行更新。它执行的是随机梯度下降( SGD)的某个变体。
具有多个输出的神经网络可能具有多个损失函数(每个输出对应一个损失函数)。但是,梯度下降过程必须基于单个标量损失值。因此,对于具有多个损失函数的网络,需要将所有损失函数取平均,变为一个标量值。
一定要明智地选择目标函数,否则你将会遇到意想不到的副作用:
- 对于二分类问题,你可以使用二元交叉熵( binary crossentropy)损失函数;
- 对于多分类问题,可以用分类交叉熵( categorical crossentropy)损失函数;
- 对于回归问题,可以用均方误差( mean-squared error)损失函数;
- 对于序列学习问题,可以用联结主义时序分类( CTC, connectionist temporal classification)损失函数。
2、Keras
-
使用 Keras 开发:概述
典型的 Keras 工作流程:
- 定义训练数据:输入张量和目标张量;
- 定义层组成的网络(或模型),将输入映射到目标;
- 配置学习过程:选择损失函数、优化器和需要监控的指标;
- 调用模型的 fit 方法在训练数据上进行迭代。
3、电影评论分类:二分类问题
-
准备数据
与 MNIST 数据集一样, IMDB 数据集也内置于 Keras 库。它已经过预处理:评论(单词序列)已经被转换为整数序列,其中每个整数代表字典中的某个单词。
from keras.datasets import imdb (train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)参数 num_words=10000 的意思是仅保留训练数据中前 10 000 个最常出现的单词。
train_data 和 test_data 这两个变量都是评论组成的列表,每条评论又是单词索引组成的列表(表示一系列单词)。train_labels 和 test_labels 都是 0 和 1 组成的列表,其中 0代表负面( negative), 1 代表正面( positive)。
你不能将整数序列直接输入神经网络。你需要将列表转换为张量。转换方法有以下两种:
- 填充列表,使其具有相同的长度,再将列表转换成形状为 (samples, word_indices) 的整数张量,然后网络第一层使用能处理这种整数张量的层;
- 对列表进行 one-hot 编码,将其转换为 0 和 1 组成的向量。举个例子,序列 [3, 5] 将会被转换为 10 000 维向量,只有索引为 3 和 5 的元素是 1,其余元素都是 0。然后网络第一层可以用 Dense 层,它能够处理浮点数向量数据。
import numpy as np def vectorize_sequences(sequences, dimension=10000): results = np.zeros((len(sequences), dimension)) for i, sequence in enumerate(sequences): results[i, sequence] = 1. return results x_train = vectorize_sequences(train_data) x_test = vectorize_sequences(test_data)你还应该将标签向量化:
y_train = np.asarray(train_labels).astype('float32') y_test = np.asarray(test_labels).astype('float32') -
构建网络
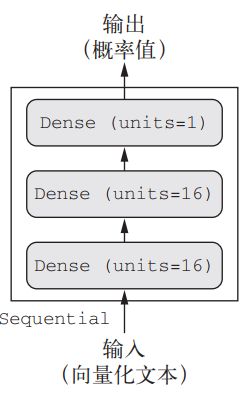
输入数据是向量,而标签是标量(1 和 0),这是你会遇到的最简单的情况。有一类网络在这种问题上表现很好,就是带有 relu 激活的全连接层(Dense)的简单堆叠,比如 Dense(16, activation=‘relu’)。
传入 Dense 层的参数(16)是该层隐藏单元的个数。一个隐藏单元(hidden unit)是该层表示空间的一个维度。每个带有 relu 激活的 Dense 层都实现了下列张量运算:
o u t p u t = r e l u ( d o t ( W , i n p u t ) + b ) output = relu(dot(W, input) + b) output=relu(dot(W,input)+b)
16 个隐藏单元对应的权重矩阵 W 的形状为 (input_dimension, 16),与 W 做点积相当于将输入数据投影到 16 维表示空间中(然后再加上偏置向量 b 并应用 relu 运算)。你可以将表示空间的维度直观地理解为 “网络学习内部表示时所拥有的自由度”。隐藏单元越多(即更高维的表示空间),网络越能够学到更加复杂的表示,但网络的计算代价也变得更大,而且可能会导致学到不好的模式(这种模式会提高训练数据上的性能,但不会提高测试数据上的性能)。
对于这种 Dense 层的堆叠,你需要确定以下两个关键架构:
- 网络有多少层?
- 每层有多少个隐藏单元?
选择的架构:
- 两个中间层,每层都有 16 个隐藏单元;
- 第三层输出一个标量,预测当前评论的情感。
from keras import models from keras import layers model = models.Sequential() model.add(layers.Dense(16, activation='relu', input_shape=(10000,))) model.add(layers.Dense(16, activation='relu')) model.add(layers.Dense(1, activation='sigmoid'))中间层使用 relu 作为激活函数,最后一层使用 sigmoid 激活以输出一个 0~1 范围内的概率值(表示样本的目标值等于 1 的可能性,即评论为正面的可能性)。
- relu( rectified linear unit,整流线性单元)函数将所有负值归零;
- 而 sigmoid 函数则将任意值 “压缩” 到 [0,1] 区间内,其输出值可以看作概率值。
什么是激活函数?为什么要使用激活函数?
如果没有 relu 等激活函数(也叫非线性), Dense 层将只包含两个线性运算——点积和加法:
o u t p u t = d o t ( W , i n p u t ) + b output = dot(W, input) + b output=dot(W,input)+b
这样 Dense 层就只能学习输入数据的线性变换(仿射变换):该层的假设空间是从输入数据到 16 位空间所有可能的线性变换集合。这种假设空间非常有限,无法利用多个表示层的优势,因为多个线性层堆叠实现的仍是线性运算,添加层数并不会扩展假设空间。为了得到更丰富的假设空间,从而充分利用多层表示的优势,你需要添加非线性或激活函数。
最后,你需要选择损失函数和优化器:
- 由于你面对的是一个二分类问题,网络输出是一个概率值(网络最后一层使用 sigmoid 激活函数,仅包含一个单元),那么最好使用 binary_crossentropy(二元交叉熵)损失;
- 优化器选择 rmsprop 优化器。
下面的步骤是用 rmsprop 优化器和 binary_crossentropy 损失函数来配置模型。注意,我们还在训练过程中监控精度:
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy'])上述代码将优化器、损失函数和指标作为字符串传入,这是因为 rmsprop、 binary_crossentropy 和 accuracy 都是 Keras 内置的一部分。有时你可能希望配置自定义优化器的参数,或者传入自定义的损失函数或指标函数。前者可通过向 optimizer 参数传入一个优化器类实例来实现。后者可通过向 loss 和 metrics 参数传入函数对象来实现。
-
验证你的方法
为了在训练过程中监控模型在前所未见的数据上的精度,你需要将原始训练数据留出 10 000个样本作为验证集:
现在使用 512 个样本组成的小批量,将模型训练 20 个轮次(即对 x_train 和 y_train 两个张量中的所有样本进行 20 次迭代)。
与此同时,你还要监控在留出的 10 000 个样本上的损失和精度。你可以通过将验证数据传入 validation_data 参数来完成:
history = model.fit(partial_x_train, partial_y_train, epochs=20, batch_size=512, validation_data=(x_val, y_val))注意,调用 model.fit() 返回了一个 History 对象。这个对象有一个成员 history,它是一个字典,包含训练过程中的所有数据:
history_dict = history.history history_dict.keys() #dict_keys(['loss', 'accuracy', 'val_loss', 'val_accuracy'])字典中包含 4 个条目,对应训练过程和验证过程中监控的指标。
使用 Matplotlib 在同一张图上绘制训练损失和验证损失,以及训练精度和验证精度:
import matplotlib.pyplot as plt history_dict = history.history loss_values = history_dict['loss'] val_loss_values = history_dict['val_loss'] epochs = range(1, len(loss_values) + 1) plt.plot(epochs, loss_values, 'bo', label='Training loss') plt.plot(epochs, val_loss_values, 'b', label='Validation loss') plt.title('Training and validation loss') plt.xlabel('Epochs') plt.ylabel('Loss') plt.legend() plt.show()plt.clf() acc = history_dict['accuracy'] val_acc = history_dict['val_accuracy'] plt.plot(epochs, acc, 'bo', label='Training accuracy') plt.plot(epochs, val_acc, 'b', label='Validation accuracy') plt.title('Training and validation accuracy') plt.xlabel('Epochs') plt.ylabel('Accuracy') plt.legend() plt.show()这里产生了过拟合(overfit)。
-
使用训练好的网络在新数据上生成预测结果
训练好网络之后,你希望将其用于实践。你可以用 predict 方法来得到评论为正面的可能性大小:
model.predict(x_test)
总结
- 通常需要对原始数据进行大量预处理,以便将其转换为张量输入到神经网络中。单词序列可以编码为二进制向量,但也有其他编码方式;
- 带有 relu 激活的 Dense 层堆叠,可以解决很多种问题(包括情感分类);
- 对于二分类问题(两个输出类别),网络的最后一层应该是只有一个单元并使用 sigmoid 激活的 Dense 层,网络输出应该是 0~1 范围内的标量,表示概率值;
- 对于二分类问题的 sigmoid 标量输出,你应该使用 binary_crossentropy 损失函数;
- 无论你的问题是什么, rmsprop 优化器通常都是足够好的选择;
- 随着神经网络在训练数据上的表现越来越好,模型最终会过拟合,并在前所未见的数据上得到越来越差的结果。一定要一直监控模型在训练集之外的数据上的性能。
4、新闻分类:多分类问题
因为每个数据点只能划分到一个类别,所以更具体地说,这是单标签、多分类( single-label, multiclass classification)问题的一个例子。
如果每个数据点可以划分到多个类别(主题),那它就是一个多标签、多分类( multilabel, multiclass classification)问题。
-
准备数据
from keras.datasets import reuters (train_data, train_labels), (test_data, test_labels) = reuters.load_data(num_words=10000)与 IMDB 评论一样,每个样本都是一个整数列表(表示单词索引)。
import numpy as np def vectorize_sequences(sequences, dimension=10000): results = np.zeros((len(sequences), dimension)) for i, sequence in enumerate(sequences): results[i, sequence] = 1. return results x_train = vectorize_sequences(train_data) x_test = vectorize_sequences(test_data)将标签向量化有两种方法:你可以将标签列表转换为整数张量,或者使用 one-hot 编码。one-hot 编码是分类数据广泛使用的一种格式,也叫分类编码( categorical encoding)。
from keras.utils.np_utils import to_categorical one_hot_train_labels = to_categorical(train_labels) one_hot_test_labels = to_categorical(test_labels) -
构建网络
这个主题分类问题与前面的电影评论分类问题类似,两个例子都是试图对简短的文本片段进行分类。但这个问题有一个新的约束条件:输出类别的数量从 2 个变为 46 个。输出空间的维度要大得多。
对于前面用过的 Dense 层的堆叠,每层只能访问上一层输出的信息。每一层都可能成为信息瓶颈。上一个例子使用了 16 维的中间层,但对这个例子来说 16 维空间可能太小了,无法学会区分 46 个不同的类别。下面将使用维度更大的层,包含 64 个单元。
from keras import models from keras import layers model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(10000,))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(46, activation='softmax'))关于这个架构还应该注意另外两点:
- 网络的最后一层是大小为 46 的 Dense 层。这意味着,对于每个输入样本,网络都会输出一个 46 维向量。这个向量的每个元素(即每个维度)代表不同的输出类别;
- 最后一层使用了 softmax 激活。你在 MNIST 例子中见过这种用法。网络将输出在 46 个不同输出类别上的概率分布——对于每一个输入样本,网络都会输出一个 46 维向量,其中 output[i] 是样本属于第 i 个类别的概率。 46 个概率的总和为 1。
对于这个例子,最好的损失函数是 categorical_crossentropy(分类交叉熵)。它用于衡量两个概率分布之间的距离,这里两个概率分布分别是网络输出的概率分布和标签的真实分布。通过将这两个分布的距离最小化,训练网络可使输出结果尽可能接近真实标签。
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy']) -
验证你的方法
我们在训练数据中留出 1000 个样本作为验证集。
x_val = x_train[:1000] partial_x_train = x_train[1000:] y_val = one_hot_train_labels[:1000] partial_y_train = one_hot_train_labels[1000:]开始训练网络,共 20 个轮次。
history = model.fit(partial_x_train, partial_y_train, epochs=20, batch_size=512, validation_data=(x_val, y_val))最后,我们来绘制损失曲线和精度曲线:
import matplotlib.pyplot as plt loss = history.history['loss'] val_loss = history.history['val_loss'] epochs = range(1, len(loss) + 1) plt.plot(epochs, loss, 'bo', label='Training loss') plt.plot(epochs, val_loss, 'b', label='Validation loss') plt.title('Training and validation loss') plt.xlabel('Epochs') plt.ylabel('Loss') plt.legend() plt.show()plt.clf() acc = history.history['accuracy'] val_acc = history.history['val_accuracy'] plt.plot(epochs, acc, 'bo', label='Training accuracy') plt.plot(epochs, val_acc, 'b', label='Validation accuracy') plt.title('Training and validation accuracy') plt.xlabel('Epochs') plt.ylabel('Accuracy') plt.legend() plt.show() -
在新数据上生成预测结果
你可以验证,模型实例的 predict 方法返回了在 46 个主题上的概率分布。我们对所有测试数据生成主题预测。
predictions = model.predict(x_test)predictions 中的每个元素都是长度为 46 的向量:
predictions[0].shape #(46,)这个向量的所有元素总和为 1。
np.sum(predictions[0]) #1最大的元素就是预测类别,即概率最大的类别。
np.argmax(predictions[0]) #3
总结
- 如果要对 N 个类别的数据点进行分类,网络的最后一层应该是大小为 N 的 Dense 层;
- 对于单标签、多分类问题,网络的最后一层应该使用 softmax 激活,这样可以输出在 N个输出类别上的概率分布;
- 这种问题的损失函数几乎总是应该使用分类交叉熵。它将网络输出的概率分布与目标的真实分布之间的距离最小化;
- 处理多分类问题的标签有两种方法:
- 通过分类编码(也叫 one-hot 编码)对标签进行编码,然后使用 categorical_crossentropy 作为损失函数;
- 将标签编码为整数,然后使用 sparse_categorical_crossentropy 损失函数。
- 如果你需要将数据划分到许多类别中,应该避免使用太小的中间层,以免在网络中造成信息瓶颈。
5、预测房价:回归问题
分类问题
其目标是预测输入数据点所对应的单一离散的标签;
回归问题
它预测一个连续值而不是离散的标签。
-
准备数据
它包含的数据点相对较少,只有 506 个,分为 404 个训练样本和 102 个测试样本。输入数据的每个特征(比如犯罪率)都有不同的取值范围。
from keras.datasets import boston_housing (train_data, train_targets), (test_data, test_targets) = boston_housing.load_data()我们有 404 个训练样本和 102 个测试样本,每个样本都有 13 个数值特征,比如人均犯罪率、每个住宅的平均房间数、高速公路可达性等。
将取值范围差异很大的数据输入到神经网络中,这是有问题的。网络可能会自动适应这种取值范围不同的数据,但学习肯定变得更加困难。对于这种数据,普遍采用的最佳实践是对每个特征做标准化,即对于输入数据的每个特征(输入数据矩阵中的列),减去特征平均值,再除以标准差,这样得到的特征平均值为 0,标准差为 1。
mean = train_data.mean(axis=0) train_data -= mean std = train_data.std(axis=0) train_data /= std test_data -= mean test_data /= std注意,用于测试数据标准化的均值和标准差都是在训练数据上计算得到的。在工作流程中,你不能使用在测试数据上计算得到的任何结果,即使是像数据标准化这么简单的事情也不行。
-
构建网络
使用一个非常小的网络,其中包含两个隐藏层,每层有 64 个单元。一般来说,训练数据越少,过拟合会越严重,而较小的网络可以降低过拟合。
from keras import models from keras import layers def build_model(): model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(train_data.shape[1],))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(1)) model.compile(optimizer='rmsprop', loss='mse', metrics=['mae']) return model网络的最后一层只有一个单元,没有激活,是一个线性层。这是标量回归(标量回归是预测单一连续值的回归)的典型设置。添加激活函数将会限制输出范围。例如,如果向最后一层添加 sigmoid 激活函数,网络只能学会预测 0~1 范围内的值。这里最后一层是纯线性的,所以网络可以学会预测任意范围内的值。
编译网络用的是 mse 损失函数,即均方误差( MSE, mean squared error),预测值与目标值之差的平方。这是回归问题常用的损失函数。
在训练过程中还监控一个新指标: 平均绝对误差( MAE, mean absolute error)。它是预测值与目标值之差的绝对值。
-
利用 K 折验证来验证你的方法
为了在调节网络参数(比如训练的轮数)的同时对网络进行评估,你可以将数据划分为训练集和验证集,正如前面例子中所做的那样。但由于数据点很少,验证集会非常小(比如大约 100 个样本)。因此,验证分数可能会有很大波动,这取决于你所选择的验证集和训练集。也就是说,验证集的划分方式可能会造成验证分数上有很大的方差,这样就无法对模型进行可靠的评估。
在这种情况下,最佳做法是使用 K 折交叉验证。这种方法将可用数据划分为 K 个分区( K 通常取 4 或 5),实例化 K 个相同的模型,将每个模型在 K-1 个分区上训练,并在剩下的一个分区上进行评估。模型的验证分数等于 K 个验证分数的平均值。

import numpy as np k = 4 num_val_samples = len(train_data) // k num_epochs = 100 all_scores = [] for i in range(k): print('processing fold #', i) val_data = train_data[i * num_val_samples: (i + 1) * num_val_samples] #准备验证数据:第k个分区的数据 val_targets = train_targets[i * num_val_samples: (i + 1) * num_val_samples] partial_train_data = np.concatenate( #准备训练数据,其他分区的数据 [train_data[:i * num_val_samples], train_data[(i + 1) * num_val_samples:]], axis=0) partial_train_targets = np.concatenate( [train_targets[:i * num_val_samples], train_targets[(i + 1) * num_val_samples:]], axis=0) model = build_model() #构建Keras模型,已编译 model.fit(partial_train_data, partial_train_targets, #训练模型,静默模型:verbose=0 epochs=num_epochs, batch_size=1, verbose=0) val_mse, val_mae = model.evaluate(val_data, val_targets, verbose=0) #在验证数据上评估模型 all_scores.append(val_mae)我们让训练时间更长一点,达到 500 个轮次。为了记录模型在每轮的表现,我们需要修改训练循环,以保存每轮的验证分数记录。
import numpy as np k = 4 num_val_samples = len(train_data) // k num_epochs = 500 all_mae_histories = [] all_scores = [] for i in range(k): print('processing fold #', i) val_data = train_data[i * num_val_samples: (i + 1) * num_val_samples] #准备验证数据:第k个分区的数据 val_targets = train_targets[i * num_val_samples: (i + 1) * num_val_samples] partial_train_data = np.concatenate( #准备训练数据,其他分区的数据 [train_data[:i * num_val_samples], train_data[(i + 1) * num_val_samples:]], axis=0) partial_train_targets = np.concatenate( [train_targets[:i * num_val_samples], train_targets[(i + 1) * num_val_samples:]], axis=0) model = build_model() #构建Keras模型,已编译 history = model.fit(partial_train_data, partial_train_targets, #训练模型,静默模型:verbose=0 validation_data = (val_data, val_targets), epochs=num_epochs, batch_size=1, verbose=0) # print(history.history.keys()) mae_history = history.history['val_mae'] all_mae_histories.append(mae_history)然后你可以计算每个轮次中所有折 MAE 的平均值:
average_mae_history = [np.mean([x[i] for x in all_mae_histories]) for i in range(num_epochs)]import matplotlib.pyplot as plt plt.plot(range(1, len(average_mae_history) + 1), average_mae_history) plt.xlabel('Epochs') plt.ylabel('Validation MAE') plt.show()因为纵轴的范围较大,且数据方差相对较大,所以难以看清这张图的规律。我们来重新绘制一张图:
- 删除前 10 个数据点,因为它们的取值范围与曲线上的其他点不同;
- 将每个数据点替换为前面数据点的指数移动平均值,以得到光滑的曲线。
def smooth_curve(points, factor=0.9): smoothed_points = [] for point in points: if smoothed_points: previous = smoothed_points[-1] smoothed_points.append(previous * factor + point * (1 - factor)) else: smoothed_points.append(point) return smoothed_points smooth_mae_history = smooth_curve(average_mae_history[10:]) plt.plot(range(1, len(smooth_mae_history) + 1), smooth_mae_history) plt.xlabel('Epochs') plt.ylabel('Validation MAE') plt.show()完成模型调参之后(除了轮数,还可以调节隐藏层大小),你可以使用最佳参数在所有训练数据上训练最终的生产模型,然后观察模型在测试集上的性能:
model = build_model() model.fit(train_data, train_targets, epochs=80, batch_size=16, verbose=0) test_mse_score, test_mae_score = model.evaluate(test_data, test_targets)
总结
- 回归问题使用的损失函数与分类问题不同。回归常用的损失函数是均方误差(MSE);
- 同样,回归问题使用的评估指标也与分类问题不同。显而易见,精度的概念不适用于回归问题。常见的回归指标是平均绝对误差( MAE)。
- 如果输入数据的特征具有不同的取值范围,应该先进行预处理,对每个特征单独进行缩放;
- 如果可用的数据很少,使用 K 折验证可以可靠地评估模型;
- 如果可用的训练数据很少,最好使用隐藏层较少(通常只有一到两个)的小型网络,以避免严重的过拟合。
6、总结
- 在将原始数据输入神经网络之前,通常需要对其进行预处理;
- 如果数据特征具有不同的取值范围,那么需要进行预处理,将每个特征单独缩放;
- 随着训练的进行,神经网络最终会过拟合,并在前所未见的数据上得到更差的结果;
- 如果训练数据不是很多,应该使用只有一两个隐藏层的小型网络,以避免严重的过拟合;
- 如果数据被分为多个类别,那么中间层过小可能会导致信息瓶颈;
- 回归问题使用的损失函数和评估指标都与分类问题不同;
- 如果要处理的数据很少, K 折验证有助于可靠地评估模型。