开局一张图教你记住HTTP基本格式
文章目录
-
- 一、HTTP请求(Request)
-
- 1.1 什么是URL
- 1.2 熟悉各种方法(Method)
-
- 1.2.1 关于GET方法
- 1.2.2 关于POST方法
- 1.3 认识“报头”(Header)
-
- 1.3.1 Host
- 1.3.2 Content-Length
- 1.3.3 Content-Type
- 1.3.4 User-Agent
- 1.3.5 Referer
- 1.3.6 Cookie
- 1.4 正文~(Body)
- 二、HTTP响应(Response)
-
- 2.1 状态码和它的描述
- 2.2 响应的“报头”(Header)
- 2.3 响应的正文(Body)
开局一张图,没有狗,细节全靠详情案例,想不记住HTTP基本格式,很难~
HTTP基本格式的总结就近在这一幅图中
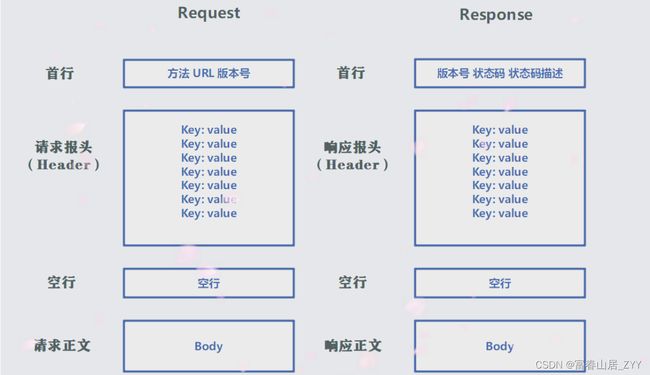
接下来就将围绕着这一张图,通过各种案例来一探HTTP格式的真面目。。。
一、HTTP请求(Request)
1.1 什么是URL
URL英文全称 Uniform Resource Locator ,中文全称统一资源定位符,俗称网址。互联网上每个网页都有独一无二的URL,是用于完整地描述Internet上网页和其他资源的地址的一种标识方法。
URL的基本格式

协议方案名:在很多地方会使用到URL,http和https较为常见。如果省略,默认为http://登录信息:一般会被省略,因为现在的身份的认证一般不会再用URL进行服务器地址:可以是域名也可以是IP地址,上面的URL使用的是域名,和IP地址相比更加的方便记忆,IP地址就是网络上一个比较详细的地址(比如118.24.113.28),可以定位到一个具体的主机,两者之间是可以相互解析转换的端口号:用于区分一个主机上的不同的应用程序,每个程序在访问网络的时候,都会关联上一个或多个端口号,从而区分出需要将当前客户端的请求交给谁。带层次的文件(PATH路径):表示访问服务器某应用程序中的具体资源查询字符串(query string):这是客户端给服务器传递的参数片段标识:用于页面内的跳转,通过该标识可以跳到文档的不同位置
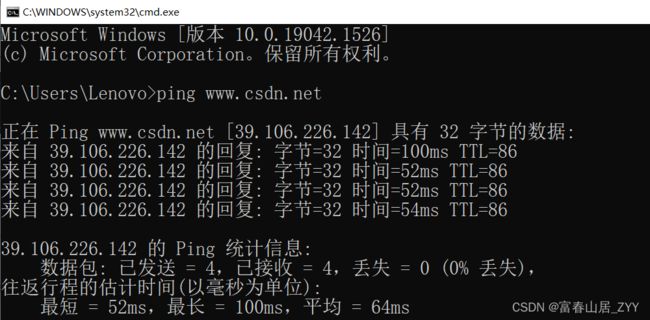
补充1:查看域名对应的IP地址
- win+R
- 输入cmd
- 输入ping 域名,就可以查看域名所对应的解析结果
查看CSDN网址的IP地址
补充2:有关query string
- 键值对结构,键和值之间用
=分割,每个键值对之间用&分割,其中的键和值都是由程序员进行定义的,因此可以有该参数,也可以没有- 在开发 web 程序的过程中扮演着重要角色
补充3:有关URL encode
当我们在百度中搜索协议方案名关键字时,会发现query string 中的第一个键值对wd的值就是此次搜索查询的内容,进行粘贴复制后,发现那五个字变成了一串由字母数字百分号构成的字符串
这是因为URL中有着很多有特殊含义的符号(’:’,’/’,’#’,…),为了避免query string中出现这些特殊符号,导致格式错误,就需要对其中的符号进行转义,这样转义的过程就叫 URL encode
转义的方法就是直接取当前需要被转义的字符串的内存十六进制形式,每个字节前加上%,这里使用的是UTF-8编码,五个汉字需要用3个字节进行表示,一共是15个字节

url encode 转义工具
补充4:端口号
Fiddler 抓取的一个具体URL案例:
GET https://www.360kan.com/dianshi/index.html?from=dongdong HTTP/1.1
在此处会发现没有端口号,这是因为端口号不是特殊的情况下,端口号通常会被省略,浏览器会加上默认的端口号。
对于HTTP的请求,浏览器会自动加上80端口号
对于HTTPS的请求,浏览器会自动加上443端口号
1.2 熟悉各种方法(Method)
当下最主流的HTTP协议版本是1.1,HTTP/1.1规定了8种方法
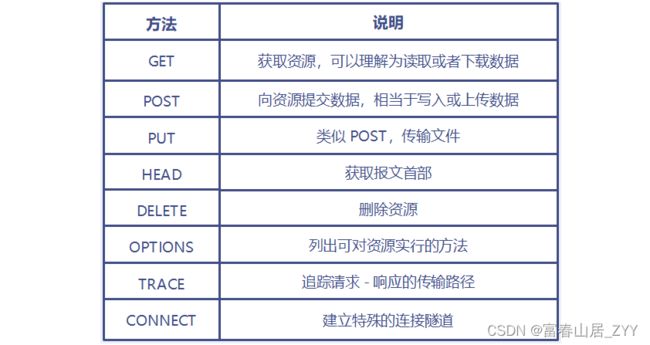
方法虽多,但是使用的最多的还是GET和POST,因此这里笔者只来介绍这两种。
1.2.1 关于GET方法
GET方法是HTTP方法中最最常用的方法,从用于获取服务器上的某个资源
触发方法:
- 浏览器的地址栏中直接输入一个URL,回车
- 点击浏览器中收藏夹中的链接,含义同上,只不过是将输入URL改成了点击鼠标,本质并无差别
- HTML中的一些标签中有需要填写URL的地方,比如link,img,script,a等标签,浏览器会自动的构造出对应的GET请求
- 使用JS直接在浏览器的前端构造出HTTP GET请求
- …
案例:

从这个GET方法的请求中,可以看出
- GET 被写在了首行的第一部分
- URL中的 query string 可以为空,但也可以不为空
- body 部分一般为空
- header部分有很多键值对,用一个冒号和一个空格进行分割键和值,键值对之间通过空行进行分割
1.2.2 关于POST方法
POST方法时HTTP中比较常见的方法,大多用于登录页面。
当登录Gitee时,通过 Fiddler 抓包,在左侧可以看见登录的请求

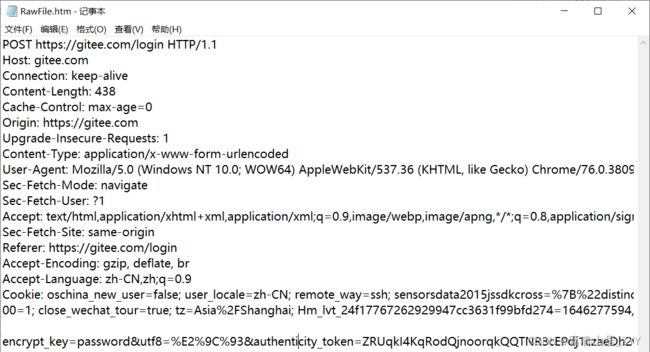
通过查看具体的POST方法的请求,能够发现:
- POST 被写在了首行的第一部分
- URL中的 query string 一般为空
- body 部分一般不为空,此处的具体格式由Header中的Content-Type来描述,具体长度由Header中的Content-Length 来描述
- Header部分有很多键值对,用一个冒号和一个空格进行分割键和值,键值对之间通过空行进行分割
面试题:关于GET 和 POST的区别
GET和POST本质上是没有区别的。
使用GET的场景完全可以使用POST进行替代,使用POST的场景同样也可以使用GET替代。
具体使用上的细节区别有:
- 一般来说,GET的body部分是空着的,习惯上将客户端的数据通过 query string 来传输;POST的 query string 的部分是空着的,习惯上把客户端的数据通过 body 来传输
- 语义上的区别,GET习惯上从服务器获取数据,POST习惯上是客户端给服务器提交数据
- 一般情况下,程序员会将GET的请求的处理实现成“幂等”,POST的请求的处理,不要求实现成“幂等”(如果多次请求得到的结果相同,不会产生负面效果就被认为请求是幂等的)
- GET请求可以被缓存,POST不可以
1.3 认识“报头”(Header)
像在前面介绍的那样,报头中的格式是键值对的结构,每个键值对占一行,键和值之间用冒号和空格开分割。
1.3.1 Host

表示服务器主机的地址和端口。
其中的值可以是IP地址,同样也可以是域名,也可以是指定的端口号,host可以和URL一样,也可以有所差异,如果直接访问网站,两者就会是一样的,如果是通过"代理"来访问网站,两者就会不同,加上 Host 实际上是为同一服务器提供两个以上的站点服务。
1.3.2 Content-Length
用来表述body中的数据的长度,单位是字节
1.3.3 Content-Type
用来表示body中的数据的格式
样式一:
application/x-www-form-urlencoded
此时body的数据样式类似于 query string ,键值对的形式,键值对之间用&来分割,键和值之间用=来分割,HTML中可以用form标签来构造这样的格式
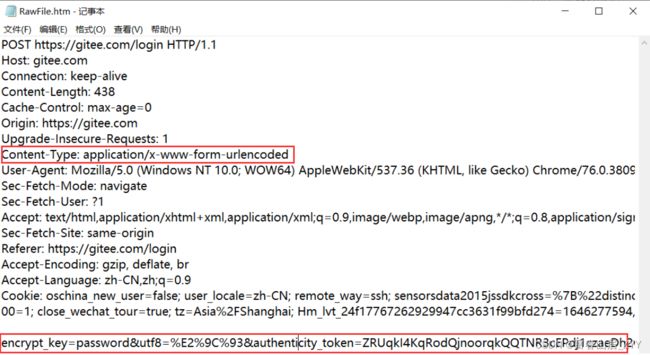
样式二:
multipart/form-data
通常用于提交文件或者图片,用的相对比较少
样式三:
application/json
这是用的比较多的一种样式,也是键值对的结构,用{ } 将所有的键值对包裹起来,里面的键值对用逗号分割,键和值之间用冒号进行分割,键、值字符串会被双引号引起来
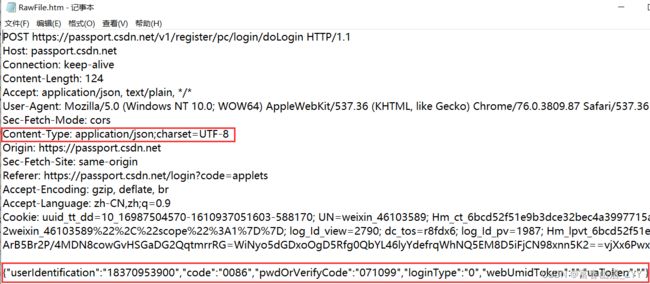
1.3.4 User-Agent
用来表示操作系统以及浏览器的属性

该字段提高了浏览器的兼容性,在浏览器的功能层次不齐的过去,网站的开发者需要通过该字段来判断用户浏览器/操作系统的各种属性,根据版本的信息来做相关的兼容性设计(比如浏览器有播放能力的就返回带视频的网页,没有视频播放能力的就只返回文本的页面)。现如今,可以用该字段来判断PC端和移动端。
1.3.5 Referer
用于表示该页面是从那个页面跳转过来的
如下案例,该网页是从CSDN的主网站跳转过来的
因此,如果是直接在浏览器中输入URL或者点击收藏夹访问某网站时是没有该字段的
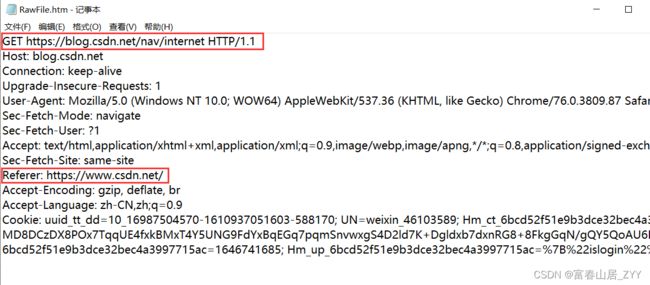
1.3.6 Cookie
Cookie是浏览器提供的方便程序员在客户端持久化存储数据的一种机制。
比如当我们在电脑上填写用户信息来登录 CSDN 网站时,登录上以后,即使之后将该网页关闭,再次登录时就会发现直接就是登录状态,不用再填写用户信息,这实际上就是 Cookie 在发挥作用产生的影响。
为了更加直观的了解Cookie 的运行机制,就拿搜狗网站为例
- 通过如图的步骤清除搜狗之前已经保存的Cookie数据
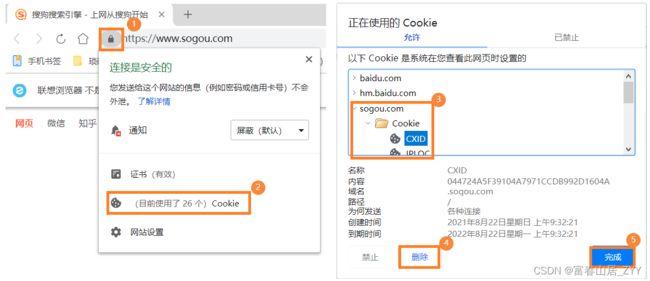
- 刷新搜狗网站,Fiddler 抓包
请求(此时的请求是没有Cookie的):

响应(可以清楚地看见,响应中有很多的Set-Cookie):
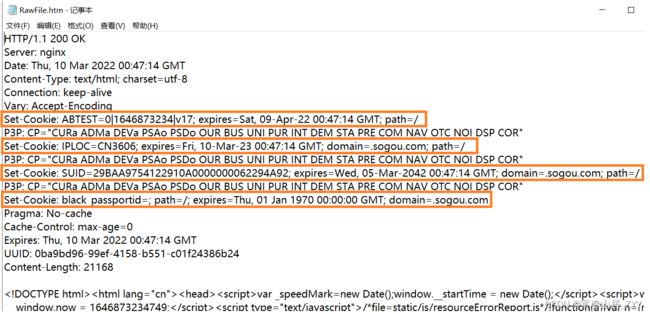
- 再次刷新搜狗网站
请求(可以看见此时的请求中带上了Cookie,键值对结构物,键值对之间用分号进行分割,键和值之间用=分割,并且可以发现其中的值不就是上一次的响应中Set-Cookie中的值):

响应(可以看见此时已将没有那么多的 Set-Cookie):

由此,大致便可以知道Cookie在这个过程中的用法
- Cookie 存在的意义是让程序员在客户端持久化的存储一些程序员自定义的数据
- Cookie里面存储的是一些键值对,键值对之间用分号分割,键和值之间用等号分割
- 浏览器中的Cookie都是从服务器的响应报头中(Set-Cookie)中获取到的,每一个Set-Cookie中都有着一个Cookie的键值对,浏览器获取到这些Cookie的内容后,就会将其保存至本地
- 等下一次的请求,浏览器再把存储的这些Cookie在发给服务器
1.4 正文~(Body)
空行后面的内容都是body,可以是空字符串,如果存在的话,其长度用Content-Length来标识,其类型用Content-Type来标识。如果服务器返回一个HTML页面,那么body中就有HTML页面的内容
二、HTTP响应(Response)
2.1 状态码和它的描述
状态码表示着访问一个页面的结果,或许是成功,或许是失败,如果是失败的话,也会分成很多种情况…
- 200 OK
这是最为常见的状态码,用Fiddler进行抓包,绝大多数都是200 OK,表示访问成功

- 404 Not Found
该状态码表示没有找到资源,B站上面并没有什么123.html 因此就会提示错误,产生404响应


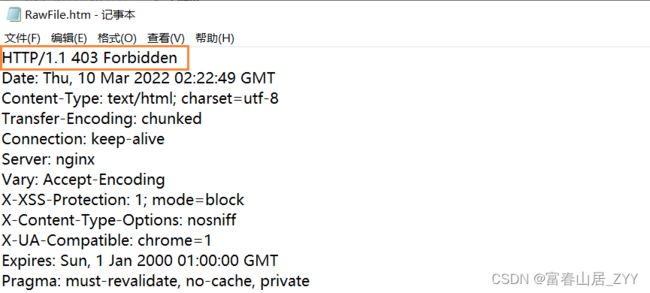
- 403 Forbidden
访问被拒绝了,没有权限的表现
在没有登录的情况下,尝试访问一个Gitee中私有的仓库,就会别拒接,原因是没有权限

- 405 Method Not Allowed
有些服务器不一定支持所有的HTTP方法,当出现无法使用的方法时,就会报405错误
- 500 Internal Server Error
代表着服务器内部的代码出现了错误,崩溃了
- 504 Gateway Timeout
服务器负载太高,等待的时间太长,出现超时的现象
- 302 Move temporarily
临时重定向,表示该资源原本确实存在,但已经被临时改变了位置,在登录页面时会比较常见,当登录成功后就会自动跳转到主页。
响应报头中会包含 Location 字段,表示跳转到的页面
较好比呼叫转移业务,手机号换了,办理该业务,那么别人拨打以前的号码,也会直接直接转移到新号码上。
- 301 Moved Permanently
永久定向,同样通过 Location 字段来表示跳转的新的地址,和临时重定向不同的是后续的请求都会被改成新的地址
状态码总结:
- 1XX:接收的请求正在处理(等会儿继续)
- 2XX:请求正常处理完毕(成功啦)
- 3XX:需要进行附加操作以完成请求(重定向)
- 4XX:服务器无法处理请求(客户端请求有问题)
- 5XX:服务器处理请求出错(服务器出问题了)
2.2 响应的“报头”(Header)
基本格式与请求的报头差不多
响应中的 Content-Type 类型:
- text/html(body中数据是HTML格式)
- text/css(body中的数据是CSS)
- application/javascript(body中的数据是JS格式)
- application/json(body中的数据是JSON格式)
2.3 响应的正文(Body)
空行后面的内容都是body,可以是空字符串,如果存在的话,其长度用Content-Length来标识,其类型用Content-Type来标识。
完!