基于autoEncoder神经网络计算图片相似度
- autoEncoder网络简介
- 图片相似度算法
- 代码部分
- 相似度计算结果验证
- 应用和扩展
- autoEncoder网络简介:
- 什么是autoEncoder?
autoEncoder——自编码网络,无监督神经网络的一种。
- autoEncoder的网络组成部分:
autoEncoder网络主要是两部分组成,分别是压缩和解码
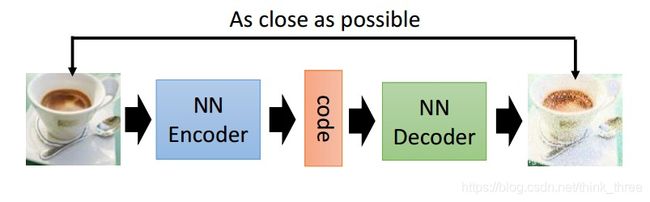
其中压缩部分称之为Encoder,解码部分称之为Decoder
中间的code称之为特征码
- 为什么使用autoEncoder网络计算图片相似度
其实autoEncoder网络并不能直接计算出不同图片的相似度,但是可以获取图片的特征码code,将源图片输入到autoEncoder网络中,input-->Encoder-->code-->Decoder-->output,当输入和输出一样(达不到完全一样)时,我们可以认为code可以在某种维度表示源图片的特征值,那么通过计算不同code之间的相似度即可以判断图片的相似程度
- 图片相似度算法:
通过autoEncoder网络提取到了图片的特征码,可以视作源图片在更高维度的特征值,可以通过计算多维向量夹角的方式计算图片相似度,算法原理如下:
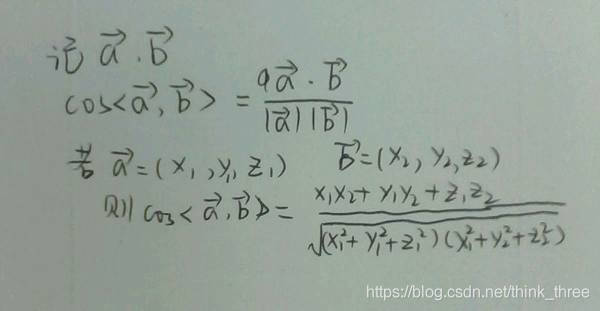
Cos的值越大,则图片越相似
- 代码部分:
关于autoEncoder网络,我目前是借鉴了BEGAN的思路去实现的,BEGAN的核心是由一个autoEncoder作为鉴别器的生成对抗神经网络,关于BEGAN的有疑惑请自行百度或者谷歌(BEGAN解读)。当计算图片相似度的时候,我们只需要关注这个部分即可,下面附上网络部分和训练部分代码:
网络部分:
# -*- conding:utf-8 -*-
import torch.nn as nn
def conv_layer(in_dim,out_dim): #img_size --> img_size/2
return nn.Sequential(
nn.Conv2d(in_dim,in_dim,3,1,1),
nn.ReLU(True),
nn.Conv2d(in_dim,in_dim,3,1,1),
nn.ReLU(True),
nn.Conv2d(in_dim,out_dim,3,1,1),
nn.MaxPool2d(2)
)
def deconv_layer(in_dim,out_dim): #img_size --> img_size*2
return nn.Sequential(
nn.ConvTranspose2d(in_dim,out_dim,3,1,1),
nn.LeakyReLU(0.1,True),
nn.ConvTranspose2d(out_dim,out_dim,3,1,1),
nn.LeakyReLU(0.1,True),
#nn.ConvTranspose2d(out_dim,out_dim,2,2,0),
nn.UpsamplingNearest2d(scale_factor=2)
#nn.LeakyReLU(0.1,True)
)
class net_D(nn.Module):
def __init__(self,in_dim,out_dim,img_size,Linear_size):
super(net_D,self).__init__()
self.in_dim = in_dim
self.out_dim = out_dim
self.img_size = img_size
self.Linear_size = Linear_size
self.layer1 = conv_layer(in_dim,out_dim)
self.layer2 = conv_layer(out_dim,2*out_dim)
self.layer3 = conv_layer(2*out_dim,3*out_dim)
#self.layer9 = conv_layer(3*out_dim,4*out_dim)
self.layer4 = nn.Sequential(
nn.Conv2d(3*out_dim,3*out_dim,3,1,1),
nn.LeakyReLU(0.1,True),
nn.Conv2d(3*out_dim,3*out_dim,3,1,1),
nn.LeakyReLU(0.1,True)
)
self.encode = nn.Linear(3*out_dim *8*8,Linear_size)
self.decode = nn.Linear(Linear_size,out_dim*8*8)
self.layer5 = deconv_layer(out_dim,out_dim)
self.layer6 = deconv_layer(out_dim,out_dim)
self.layer7 = deconv_layer(out_dim,out_dim)
#self.layer10 = deconv_layer(out_dim,out_dim)
self.layer8 = nn.Sequential(
nn.ConvTranspose2d(out_dim,out_dim,3,1,1),
nn.LeakyReLU(0.1,True),
nn.ConvTranspose2d(out_dim,in_dim,3,1,1),
nn.Tanh()
)
def forward(self,x):
out = self.layer1(x)
out = self.layer2(out)
out = self.layer3(out)
#out = self.layer9(out)
out = self.layer4(out)
out = out.view(out.size(0),-1)
out = self.encode(out)
coding = out.clone()
out = self.decode(out)
out = out.view(out.size(0),self.out_dim,8,8)
out = self.layer5(out)
out = self.layer6(out)
out = self.layer7(out)
#out = self.layer10(out)
out = self.layer8(out)
return out,coding
class net_G(nn.Module):
def __init__(self,nz_dim,in_dim,out_dim,img_size,Linear_size):
super(net_G,self).__init__()
self.nz_dim = nz_dim
self.in_dim = in_dim
self.out_dim = out_dim
self.img_size = img_size
self.Linear_size = Linear_size
self.embed = nn.Linear(nz_dim,out_dim*8*8)
self.layer1 = deconv_layer(out_dim,out_dim)
self.layer2 = deconv_layer(out_dim,out_dim)
self.layer3 = deconv_layer(out_dim,out_dim)
#self.layer5 = deconv_layer(out_dim,out_dim)
self.layer4 = nn.Sequential(
nn.ConvTranspose2d(out_dim,out_dim,3,1,1),
nn.LeakyReLU(0.1,True),
nn.ConvTranspose2d(out_dim,in_dim,3,1,1),
nn.Tanh()
)
def forward(self,x):
out = self.embed(x)
out = out.view(out.size(0),self.out_dim,8,8)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
#out = self.layer5(out)
out = self.layer4(out)
return out训练部分代码:
# -*- coding: utf-8 -*-
import torch
from torch.autograd import Variable
import torch.optim as optim
import torchvision.transforms as transforms
import torch.utils.data as Data
import torchvision.utils as vutils
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
from mydataset import myDataset
import config as cfg
import module
import random
def noize(dim):
return Variable(torch.FloatTensor(cfg.batch_size,dim))
def adjust_learning_rate(optimizer, niter):
#"""Sets the learning rate to the initial LR decayed by 10 every 30 epochs"""
lr = cfg.learning_rate * (0.95 ** (niter // cfg.lr_decay_every))
for param_group in optimizer.param_groups:
param_group['lr'] = lr
return optimizer
transform = transforms.Compose([
transforms.Resize((80,80)),
transforms.RandomCrop((64,64)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5],
std = [0.5])
])
train_dataset = myDataset(
img_dir = cfg.img_train,
img_txt = cfg.train_txt,
transform = transform,
)
train_dataloader = Data.DataLoader(train_dataset,batch_size = 10,shuffle = True)
if cfg.CUDA:
net_G = module.net_G(nz_dim=cfg.nz_dim,in_dim=cfg.in_dim,out_dim=cfg.out_dim,img_size=cfg.img_size,Linear_size=cfg.Linear_size).cuda()
net_D = module.net_D(in_dim=cfg.in_dim,out_dim=cfg.out_dim,img_size=cfg.img_size,Linear_size=cfg.Linear_size).cuda()
else :
net_G = module.net_G(nz_dim=cfg.nz_dim,in_dim=cfg.in_dim,out_dim=cfg.out_dim,img_size=cfg.img_size,Linear_size=cfg.Linear_size)
net_D = module.net_D(in_dim=cfg.in_dim,out_dim=cfg.out_dim,img_size=cfg.img_size,Linear_size=cfg.Linear_size)
optim_G = optim.Adam(net_G.parameters(),lr = cfg.learning_rate)
optim_D = optim.Adam(net_D.parameters(),lr = cfg.learning_rate)
k=0
for i in range(cfg.epoch):
for ii ,(img,label) in enumerate(train_dataloader):
if cfg.CUDA :
img = Variable(img).cuda()
label = Variable(label).cuda()
else:
img = Variable(img)
label = Variable(label)
random.seed(0)
torch.manual_seed(0)
nz = Variable(torch.FloatTensor(cfg.batch_size,cfg.nz_dim))
nz.data.uniform_(-1,1)
optim_D.zero_grad()
real_D,coding = net_D(img)
nz_G = net_G(nz)
fake_G,fake_coding = net_D(nz_G)
L_D = torch.mean(torch.abs(img-real_D))
L_Gz_D = torch.mean(torch.abs(nz_G-fake_G))
lossD = L_D - k*L_Gz_D
lossD.backward()
optim_D.step()
optim_G.zero_grad()
nz_G = net_G(nz)
fake_G,fake_coding = net_D(nz_G)
L_Gz_D = torch.mean(torch.abs(nz_G-fake_G))
lossG = L_Gz_D
lossG.backward()
optim_G.step()
balance = (cfg.gamma*L_D - L_Gz_D).item()
k = min(max(k+cfg.lambda_k*balance,0),1)
measure = L_D.item() + abs(balance)
optim_D = adjust_learning_rate(optim_D,ii)
optim_G = adjust_learning_rate(optim_G,ii)
print('ii ={0},lossD = {1},lossG = {2},measure= {3} ,k = {4},epoch={5}'.format(ii,lossD,lossG,measure,k,i))
torch.save(net_D,'./net/net_D.pth')
torch.save(net_G,'./net/net_G.pth')4.相似度结果验证:
因为没有GPU,所以我只采用了少量的图片来验证上述方法是否可行,图片集只有20个样本,10张猫和10张狗的图片,计算和最后一张狗的图片最相似的图片

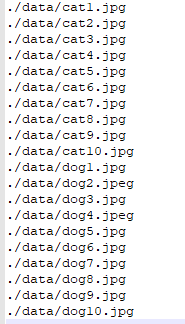
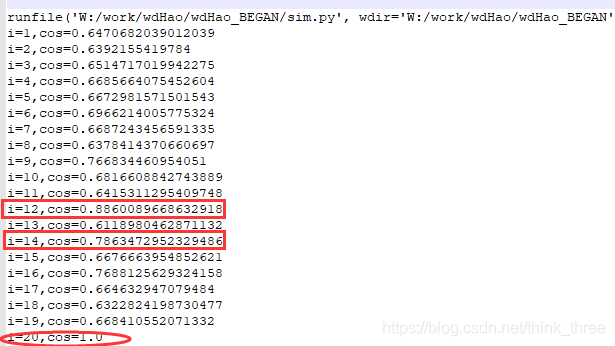
通过相似度计算可以得出和最后一张图片最相似的是第12和14张图片,通过观察发现和计算结果一致,说明使用autoEncoder网络毕竟图片相似度方案可行
5.应用和扩展:
1)autoEncoder网络不仅在图像中应用广泛,在数据、文字等方向也有很多的应用场景,所以同样的也可以用来计算数据等方向的相似度,因为本人的主要工作方向是图像方面,所以关于数据、文字、音频等方向需要感兴趣的小伙伴去尝试验证
2)通过上述相似度比较,可以设置一个适当的置信度,当大于这个置信度的时候将图片划分到一类,这样就实现了一个聚类的操作
3)相比较传统的哈希等算法提取图片的特征值,autoEncoder网络可以更高的维度去提取特征,而且抗干扰的能力更强,例如对图片旋转颠倒等操作几乎没有影响特征码的值
4)关于BEGAN的代码部分,我是使用Pytorch实现的,因为是综合借鉴了许多大神的代码,所以暂时不会将代码上传到github上了,如果有小伙伴需要我提供代码,请留下邮箱(如果后续有比较多的小伙伴需要,我再考虑上传代码到github)
欢迎分享和留言。
分享请注明出处。