【3D目标检测】PointPillars: Fast Encoders for Object Detection from Point Clouds论文解读(2019)
1、 为什么要做这个研究(理论走向和目前缺陷) ?
VoxelNet只有4.4fps,SECOND虽然能达到20fps,但还有提升空间。
2、 他们怎么做这个研究 (方法,尤其是与之前不同之处) ?
算是对SECOND的加速版,将原来3D 体素网格的编码方式改为2D立柱方式,且改用2D 卷积而非3D 卷积处理。还有一些其他的加速操作,比如特征降维,tensorRT等。
3、 发现了什么(总结结果,补充和理论的关系)?
效果和SECOND差不多,但是快了很多,达到62fps。
摘要:PointPillars网络设计了一个比较适合下游2D CNN网络处理的可学习的特征编码器,类似于VoxelNet中的VFE层。
1、 引言
将点云划分成网格然后提取可学习特征的路线是VoxelNet(太慢)->SECOND(稀疏卷积加速,但是3D卷积依然计算量大)->PointPillars(2D卷积实现3D目标检测)。Pillar是柱子的意思,其划分网格是划分为2D网格,每个网格实际是一个立柱,在每个立柱中用PointNet进行特征提取,这样就避免了在Z轴方向继续划分。
1.1 相关研究
1.1.1 用CNN做目标检测:Faster RCNN,
1.1.2 在激光雷达点云数据集做目标检测:Vote3Deep, 3D FCN, MV3D,AVOD,PIXOR,Complex YOLO,PointNet, VoxelNet,F-PointNet,SECOND等
1.2 贡献
提出的PointPillars可以将每个立柱(pillar)用pointnet提取特征,然后转换适合CNN处理的密集特征图。
2 PointPillars网络
主要包含三部分:1)将点云转换为伪图片的特征提取器。2)处理伪图片的2D卷积主干网络。3)可以检测回归3D框的检测头。
2.1 生成伪图像
首先在俯视图的平面上打网格(H x W)的维度;然后对于每个网格所对应的柱子中的每一个点都取(x,y,z,r,x_c,y_c,z_c,x_p,y_p)9个维度。其中前三个为每个点的真实位置坐标,r为反射率,带c下标的是点相对于柱子中心的偏差,带p下标的是对点相对于网格中心的偏差。每个柱子中点多于N的进行采样,少于N的进行填充0。于是就形成了(D,N,P),D=9, N为点数(设定值,为100),P为HW,实际为12000。
然后学习特征,用一个简化的PointNet从D维中学出C个channel来,变为(C,N,P)然后对N进行最大化操作变为(C,P)又因为P是HW的,我们再展开成一个伪图像形式,H,W为宽高,C为通道数。
2.2 主干网络及检测头
主干网络和检测头就是SSD网络,整个网络框架(包括主干网络细节)如下图所示:
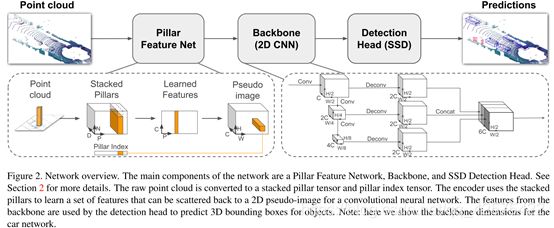
主干网络及检测头(摘自SECOND论文):

3 实现细节
3.1 网络(见上图)
3.2 损失函数,跟SECOND的一样
4 实验设置
4.1 数据集:KITTI
4.2 设置:每个pillar是0.16mX0.16m最大pillar数P=12000,每个pillar最多取N=100个点。
4.3 数据增强
跟SECOND一样,将其他点云中的Car,cyclist实例点随机加到当前点云里来增加实例数目。此外,还有gt实例随机旋转[-9度,+9度],随机平移0.25m。还有SECOND里提到的同时对点云和所有GT框进行的全局增强。
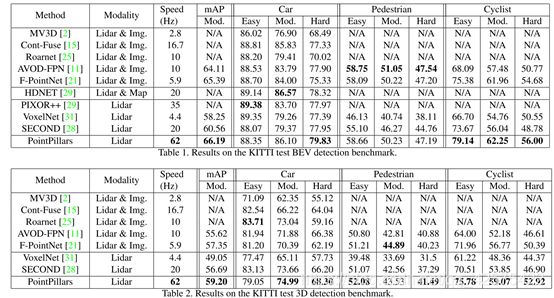
5 实验结果

6 实时推断
PointPillars可以达到62fps(VoxelNet是 4.4FPS, SECOND是20FPS),每帧处理只需要0.16ms,之所以这么快有如下原因:1)是划分立柱而非划分3D网格,3D网格划分会更密集,计算量也更大。2)对立柱里的点云进行特征编码只用了1个pointnet,而VoxelNet里用了2个pointnet,而且提取特征的通道数都相对原来的降了一半。3)用了TensorRT加速,节约一半的时间。
这么快的速度有用吗?
当然有用,实际激光雷达每秒采集20帧数据,但是KITTI数据集中只取车前方的点云数据进行处理,真实的自动驾驶汽车需要对周围所有点云都要处理。需要预留这么多的计算资源。
7 消融实验
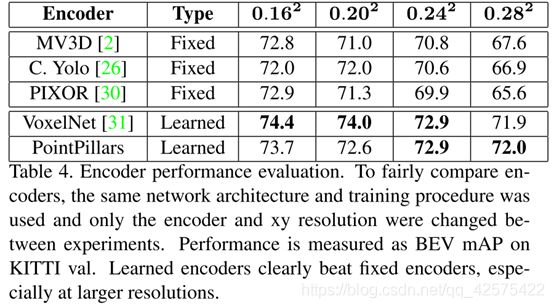
7.1 空间分辨率
不同大小的Pillar对性能及速度影响

7.2 每个框内的数据增强影响不大
7.3 点装饰(除原始点坐标x,y,z,反射率r,还加了pillar中心点等进行额外装饰):提升0.5mAP。
8.结论
提出PointPillars