前言
最近刚开始接触机器学习,记录下目前的一些理解,以及看到的一些好文章mark一下
1.MINST数据集
MNIST 数据集来自美国国家标准与技术研究所, National Institute of Standards and Technology (NIST). 训练集 (training set) 由来自 250 个人手写的数字构成, 其中 50% 是高中学生, 50% 来自人口普查局 (the Census Bureau) 的工作人员. 测试集(test set) 也是同样比例的手写数字数据.
MINST手写字体识别,大概相当于机器学习领域的"Hello World"的存在
1.1数据集的下载即载入
1.2可以去官网下载MNIST handwritten digit database, Yann LeCun, Corinna Cortes and Chris Burges

2.1.通过pytorch的dataloader直接下载
# 设置训练数据集
data_train = torchvision.datasets.MNIST(
root='./data',
train=True,
transform=torchvision.transforms.ToTensor(),
download=True)
#将训练数据集载入DataLoader
train_loader = torch.utils.data.DataLoader(data_train, batch_size=100, shuffle=True)
2.2.1torchvision.datasets
torchvision.datasets是pytorch中集成的可以加载多个数据集的工具,包含图片分类,语义分割,视频等数据集,详情见
[Datasets — Torchvision 0.12 documentation (pytorch.org)](https://pytorch.org/vision/stable/datasets.html?highlight=utils data dataloader)进入该页面我们找到MINST就可以查看到使用MINST所需要的参数
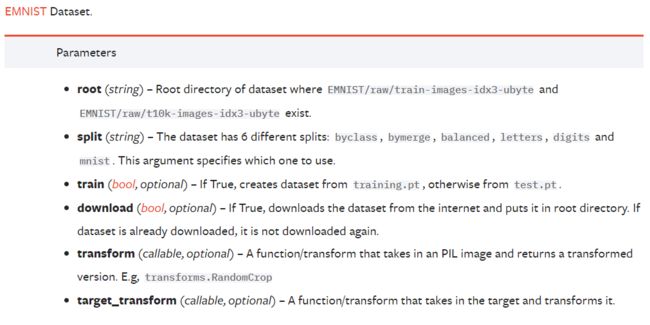
也可以在pycharm中定位到这个代码,按Ctrl+P查看需要的参数,我们重点关注这几个

1.root指定数据集的路径,2.train设置该数据是否用来训练,3.download参数用来设置是否下载该数据集默认False
4.transform在pytorch封装了许多图像处理的方法,如填充(Pad),Resize,CenterCrop(中心裁剪),Grayscale(灰度图),更多方法见:Illustration of transforms — Torchvision 0.12 documentation (pytorch.org)
而这里的ToTensor是常用的步骤,可以实现将PIL格式或者numpy.ndarray格式的输入转化为tensor数据类型
2.3data.DataLoader
DataLoader的意义就是做数据打包,参数含义重点关注这几个

首先的1. dataset用来指定传入的数据集,2. batch_size用来指定多少个数据为一组(如=64代表一次传入64张图片),太大可能爆显存,3. shuffle用来设置是否随机采样(可以理解为图片顺序打乱?),4. num_workers代表任务数量(理解为线程数),5. drop_last设置是否丢弃最后的图片(当最后几张图片不满一个batch_size时丢弃)
3.MINST的内容的展示
(22条消息) MNIST数据集转为图片形式输出_zzZ_CMing的博客-CSDN博客_mnist图片 这篇博客有写怎么将MINST的数据保存到本地
显示几个数据
#enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标
examples = enumerate(train_loader)
#next() 返回迭代器的下一个项目。
batch_idx, (example_data, example_targets) = next(examples)
# 绘制查看数据集内容
fig = plt.figure()
for i in range(16):
plt.subplot(4,4,i+1) #设置图像显示为2行3列
plt.tight_layout() #tight_layout会自动调整子图参数,使之填充整个图像区域。
plt.imshow(example_data[i][0], cmap='gray')
plt.title("Truth Number: {}".format(example_targets[i]))
plt.xticks([]) #不显示横纵坐标
plt.yticks([])
plt.show()

debug一下,发现图像的尺寸为[1000,1,28,28],分别代表batch_size为1000,chanel(通道)数为1(灰度图),图像尺寸为28x28

2. MINST的训练和测试方法
2.1定义训练方法
def train(net, epoch=1):
net.train()#设置training mode
run_loss = 0#损失
for num_epoch in range(epoch): #设置训练的轮数为epoch轮
print(f'epoch {num_epoch}')
for i, data in enumerate(train_loader):#i为索引,data为数据
# x, y = data[0], data[1] #也可以这么写
x,y = data #x,y分别代表数据和标注
outputs = net(x) #将数据放入神经网络中
loss = criterion(outputs, y) #计算损失
optimizer.zero_grad() #梯度清零
loss.backward() #反向传播
optimizer.step() #优化器更新参数
run_loss += loss.item()
if i % 100 == 99: #每训练100轮打印一次
print(f'[{(i + 1) * 100} / 60000] loss={run_loss / 100}')
run_loss = 0
test(net)
这段代码初学者肯定比较懵逼,比如说我,下面简单说几个
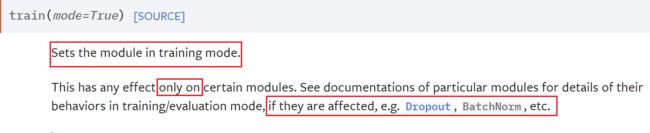
net.train()的作用如下
可以看到,其实设不设置影响都不大,仅当你的模型中有使用Dropout()层或BatchNorm层时会有影响
为什么要梯度清零
由于pytorch的动态计算图,当我们使用loss.backward()和opimizer.step()进行梯度下降更新参数的时候,梯度并不会自动清零。并且这两个操作是独立操作。如果梯度不清零,pytorch中会将上次计算的梯度和本次计算的梯度累加。
有兴趣可以看这里(60 封私信 / 84 条消息) PyTorch中在反向传播前为什么要手动将梯度清零? - 知乎 (zhihu.com)
损失函数
损失函数使用主要是在模型的训练阶段,每个批次的训练数据送入模型后,通过前向传播输出预测值,然后损失函数会计算出预测值和真实值之间的差异值,也就是损失值。得到损失值之后,模型通过反向传播去更新各个参数,来降低真实值与预测值之间的损失,使得模型生成的预测值往真实值方向靠拢,从而达到学习的目的。我们接下来使用的是nn.CrossEntropyLoss()
优化器
优化器或者优化算法,是通过训练优化参数,来最小化(最大化)损失函数。为了使模型输出逼近或达到最优值,我们需要用各种优化策略和算法,来更新和计算影响模型训练和模型输出的网络参数。接下来的我们使用的是Adam(自适应学习率优化算法)。关于各种优化器的对比详情见深度学习之——优化器 - 简书 (jianshu.com)
这几天看别人代码,感觉还是SGD(随机梯度下降)用的比较多
2.2定义测试方法
def test(net):
net.eval()#和上面的net.train()一样
test_loader = torch.utils.data.DataLoader(data_train, batch_size=10000, shuffle=False)
test_data = next(iter(test_loader))
with torch.no_grad():
# x, y = test_data[0], test_data[1]
x,y = data
outputs = net(x)
pred = torch.max(outputs, 1)[1]
print(f'test acc: {sum(pred == y) / outputs.shape[0]}')#计算出损失(每个之和除以数量)
3.定义神经网络
3.1 神经网络
什么是卷积神经网络(CNN),具体可以看这篇文章:一文看懂卷积神经网络-CNN(基本原理+独特价值+实际应用)- 产品经理的人工智能学习库 (easyai.tech)
人工神经网络(Artificial Neural Networks,ANN)是一种模拟生物神经系统的结构和行为,进行分布式并行信息处理的算法数学模型。ANN通过调整内部神经元与神经元之间的权重关系,从而达到处理信息的目的。而卷积神经网络(Convolutional Neural Network,CNN)是一种前馈神经网络,它由若干卷积层和池化层组成,尤其在图像处理方面CNN的表现十分出色。

一般的卷积神经网络结果如下

3.1.1. 卷积层
在pytorch中卷积被封装在nn.Conv2d()中,参数如下,后几个我没用过

关于卷积的输出尺寸怎么计算官网也有给出

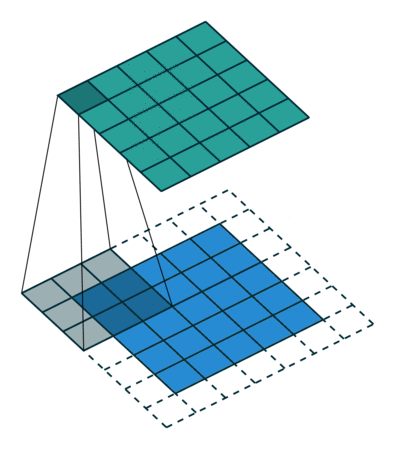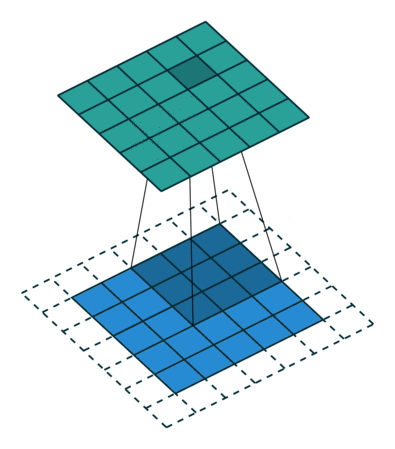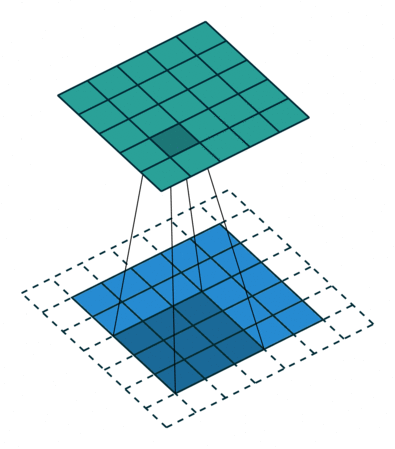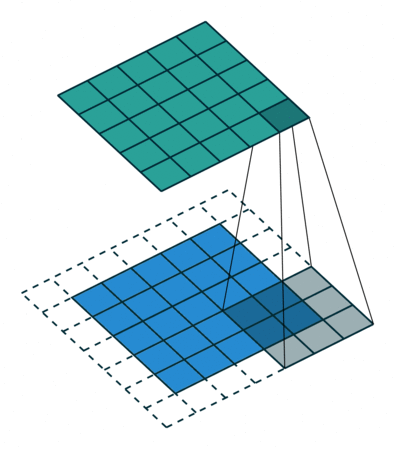
光看这个直接给人看傻了,我们看点直观的例子,如下左图所示,下方灰色的3x3kernel是我们定义的卷积核,下方是我们输入的图像,四周白色的方框代表我们的填充(padding=1),卷积核不断在输入图像上移动并计算,最终得到上方绿色的输出图像
再举个例子来求图像的输出尺寸,如下有一个28x28的输入,我们假设padding=2,步长为1,卷积核为5x5

则输出的图像尺寸就应该为(28 - 2 * 2 - 1 * (5-1)-1/1)+1 = 28,所有输出的尺寸也应该为28x28,即不变
3.1.2. 池化层
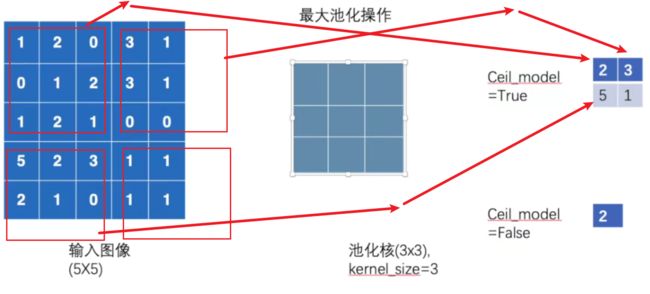
池化层分最大池化层和平均池化层,对应代码中的MaxPool2d,和AvgPool2d,池化层能很好的压缩图片信息,而且保留一部分特征
最大池化层的作用过程如下,输入图像为5x5,我们用一个3x3的核对它做最大池化,每次都求出3x3中的最大值来得到结果,ceil_model为False是用来设定把不满足3x3的结果都丢弃掉(类似之前谈的drop_last)
平均池化也同理,只不过不是求出最大的而是求一个平均
3.1.3. 激励层
激活函数的作用
神经网络中使用激活函数来加入非线性因素,提高模型的表达能力。
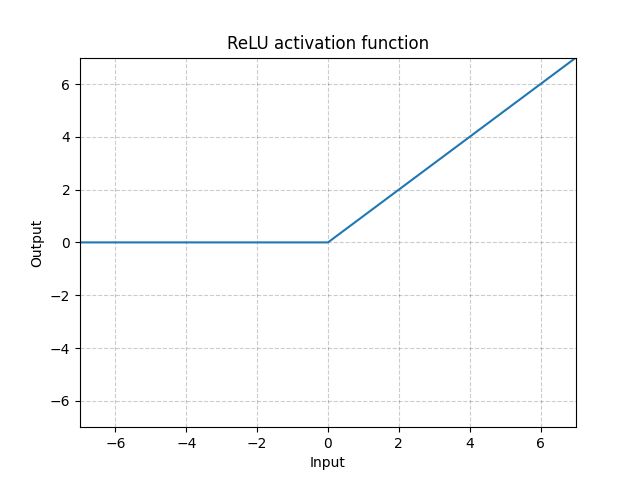
如果不用激励函数(其实相当于激励函数是f(x) = x),在这种情况下你每一层节点的输入都是上层输出的线性函数,很容易验证,无论你神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当,这种情况就是最原始的感知机(Perceptron)了,那么网络的逼近能力就相当有限。正因为上面的原因,需要引入非线性函数作为激励函数,这样深层神经网络表达能力就更加强大(不再是输入的线性组合,而是几乎可以逼近任意函数)。
常用的非线性激活函数有nn.ReLu()和nn.Sigmoid()他们的图像如下,可以看到ReLu在大于0时为x,小于0时为0
3.2 LeNet
关于LeNet的几个版本介绍LeNet:第一个卷积神经网络 (ruanx.net)
LeNet 是几种神经网络的统称,它们是 Yann LeCun 等人在 1990 年代开发的。一般认为,它们是最早的卷积神经网络(Convolutional Neural Networks, CNNs)。模型接收灰度图像,并输出其中包含的手写数字。LeNet 包含了以下三个模型:
- LeNet-1:5 层模型,一个简单的 CNN。
- LeNet-4:6 层模型,是 LeNet-1 的改进版本。
- LeNet-5:7 层模型,最著名的版本。
这里我们使用LeNet5这个经典的神经网络,网络模型如下总共有7层
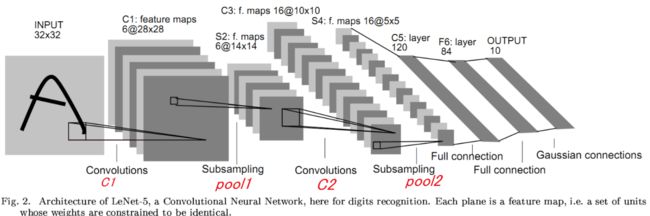
可以发现输入图像是32x32的,但MINST数据集的图像尺寸为28x28,可以得出padding=2,第一个卷积层输入chanel=1,输出chanel=6,第一个池化层从28x28到14x14,推断出kernel为2x2,按上图模型编写代码
class LeNet5(nn.Module):
def __init__(self):
super().__init__()
#这个注释的比较详细
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, padding=2)
# self.pool1 = nn.AvgPool2d(2) #本来LeNet使用的平均池化不如最大池化
self.pool1 = nn.MaxPool2d(kernel_size=2)
self.pool1 = nn.MaxPool2d(2)
self.conv2 = nn.Conv2d(6, 16, 5)
# self.pool2 = nn.AvgPool2d(2)
self.pool2 = nn.MaxPool2d(2)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
#前向传播
def forward(self, x):
# x = torch.tanh(self.conv1(x)) #tanh在这里不如relu
x = torch.relu(self.conv1(x))
x = self.pool1(x)
# x = torch.tanh(self.conv2(x))
x = torch.relu(self.conv2(x))
x = self.pool2(x)
x = x.view(-1, 16 * 5 * 5) #改变矩阵维度
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return x
在LeNet上训练20轮后的acc最高可以达到99.86%可以说相当可以了,
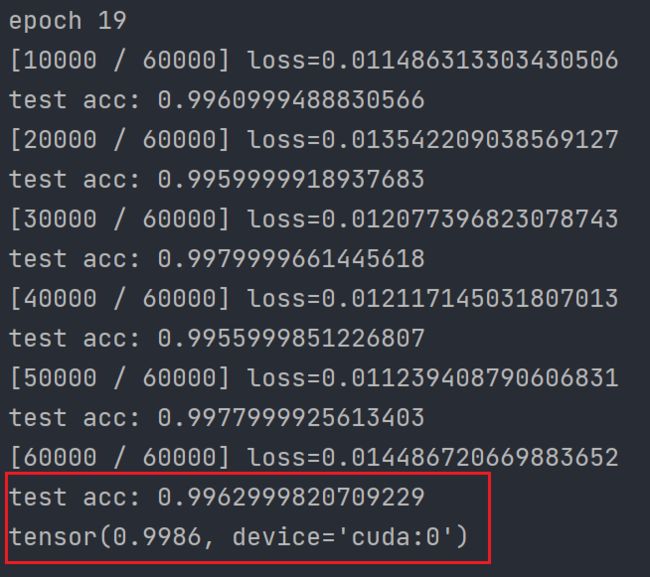
在测试一下,在MINST数据集下的正确率确实很高了

但我自己手写了几个,发现正确率不怎么样,原因还不清楚是为什么,难道是我字太丑了?。。。还是说这个模型过拟合了?。。。

还有个坑说一下,一定要转灰度图单通道,不然会莫名其妙报很多错
4.完整代码
是cpu版本的就用cpu训练,有gpu版本的就用gpu训练,要快很多,但是要注意,你用的什么设备训练出来的模型保存再加载的时候要指明设备。意思就是你不能用cpu训练了一个模型,然后你再加载的时候又用cuda来加速
import torch
import torchvision
import torch.nn as nn
import torchvision.transforms as transforms
from torch.nn import ReLU
import torch.nn.functional as F
import numpy as np
import matplotlib.pyplot as plt
from torch.optim import optimizer
from PIL import Image
# 用来记录最佳的acc
best_acc = 0
trans_to_tensor = transforms.Compose([
transforms.ToTensor()
])
data_train = torchvision.datasets.MNIST(
root='./data',
train=True,
transform=torchvision.transforms.ToTensor(),
download=True)
data_test = torchvision.datasets.MNIST(
'./data',
train=False,
transform=trans_to_tensor,
download=True)
train_loader = torch.utils.data.DataLoader(data_train, batch_size=100, shuffle=True)
x, y = next(iter(train_loader))
#MINST的通用训练方法
def test(net):
global best_acc
net.eval()
test_loader = torch.utils.data.DataLoader(data_train, batch_size=10000, shuffle=False)
test_data = next(iter(test_loader))
with torch.no_grad():
# x, y = test_data[0], test_data[1]
# x = x.cuda()
# y = y.cuda()
x, y = test_data
outputs = net(x)
pred = torch.max(outputs, 1)[1]
acc = sum(pred == y) / outputs.shape[0]
if acc > best_acc:
best_acc = acc
print(f'test acc: {acc}')
# net.train()
def train(net, epoch=1):
net.train()
run_loss = 0
for num_epoch in range(epoch):
print(f'epoch {num_epoch}')
for i, data in enumerate(train_loader):
# x, y = data[0], data[1]
x,y = data
# print(data)
outputs = net(x)
loss = criterion(outputs, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
run_loss += loss.item()
if i % 100 == 99:
print(f'[{(i + 1) * 100} / 60000] loss={run_loss / 100}')
run_loss = 0
test(net)
# LeNet5网络模型
class LeNet5(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, padding=2)
# self.pool1 = nn.AvgPool2d(2)
self.pool1 = nn.MaxPool2d(kernel_size=2)
self.conv2 = nn.Conv2d(6, 16, 5)
# self.pool2 = nn.AvgPool2d(2)
self.pool2 = nn.MaxPool2d(2)
self.fc1 = nn.Linear(in_features=16 * 5 * 5, out_features=120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# x = torch.tanh(self.conv1(x))
x = torch.relu(self.conv1(x))
x = self.pool1(x)
# x = torch.tanh(self.conv2(x))
x = torch.relu(self.conv2(x))
x = self.pool2(x)
x = x.view(-1, 16 * 5 * 5)
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return x
if __name__ == '__main__':
# res = []
# classes = ['0','1','2','3','4','5','6','7','8','9']
net_5 = LeNet5().cuda()
criterion = nn.CrossEntropyLoss().cuda()
optimizer = torch.optim.Adam(net_5.parameters())
train(net_5, epoch=20)
print(best_acc)
'''
@以下内容用来保存自己的模型并做验证
torch.save(net_5.state_dict(),'LeNet5_par.pt')#保存模型参数
torch.save(net_5,'LeNet5_all.pt')#保存整个模型
model = torch.load('./LeNet5_all_cpu.pt',map_location=torch.device("cpu"))
print(model)
for i in range(0,7):
image_path = f'./data/imgs/my_nums/{i}.jpg'
img = Image.open(image_path).convert('L')
transform = torchvision.transforms.Compose([torchvision.transforms.Resize([28,28]),
torchvision.transforms.ToTensor()])
image = transform(img)
image = torch.reshape(image, (-1, 1, 28, 28))
model.eval()
with torch.no_grad():
output = model(image)
prediction = torch.softmax(output, dim=1)
prediction = np.argmax(prediction)
plt.imshow(img)
plt.show()
res.append(prediction.item())
print(prediction.item())
print('----------')
print(res)
'''