基于深度学习的口罩识别与检测PyTorch实现
基于深度学习的口罩识别与检测PyTorch实现
- 1. 设计思路
-
- 1.1 两阶段检测器:先检测人脸,然后将人脸进行分类,戴口罩与不戴口罩。
- 1.2 一阶段检测器:直接训练口罩检测器,训练样本为人脸的标注信息,戴口罩的,不带口罩的。
- 2. 算法具体实现
-
- 2.1 两阶段口罩识别与检测器设计思路概述
- 2.2 实现代码分析
-
- 2.2.1 训练分类器并且保存模型
- 2.2.2 人脸检测与剪裁,然后进行分类。
- 3. 总结
- 4. 参考链接
1. 设计思路
- 已经完成,两阶段口罩检测的算法设计与实现。主要讲解整体pipeline的设计,即:人脸检测算法+口罩二分类CNN模型。
全文的代码和技术讲解,在这里可以下载。mask_detection代码讲解. - 一阶段口罩检测算法设计与实现。这一部分安排下一个博客讲解。
1.1 两阶段检测器:先检测人脸,然后将人脸进行分类,戴口罩与不戴口罩。
对于这种两阶段方法,是能快速实现的。首先用现有的人脸检测算法,直接对图像进行人脸检测,然后将检测的每一个人脸,单独切割出来,进行是否戴口罩的二分类。
所以只需要训练一个CNN网络,包含两类图像,mask和without_maks。前端接一个face detector,就能应对大多数情况了。单独的讲解文档链接:口罩检测思路讲解文档。

1.2 一阶段检测器:直接训练口罩检测器,训练样本为人脸的标注信息,戴口罩的,不带口罩的。
先对图像中的人脸进行标注,包括了戴口罩的,和不带口罩的两个label的目标。然后进行标注。直接对人脸检测模型进行transfer learning,微调一下模型,就能检测了。
直接对戴口罩和不带口罩的人脸进行标注就可以了。

类似这种标注方法:

2. 算法具体实现
2.1 两阶段口罩识别与检测器设计思路概述
-
用数据集训练一个CNN二分类器。
其中的数据为两类,mask 和without_mask。可以用现成的模型参数,在ImageNet上预训练好的weights,进行finetune。本方法采用的是ResNet18 为backbone,来进行训练。详细代码如下。其中,mask的数据集来这里: Mask Dataset
如果这个数据集链接失效,用这一个:Mask Dataset 备份地址
注意,下载数据集是google drive,科学上网。
对训练好的模型,进行权重参数的保存,用于第二阶段的分类任务。保存为:将训练好的模型保存在pth中,然后在evaluation中,或者在Inference中,直接使用这个模型参数。## 将训练好的模型保存在pth中,然后在evaluation中,或者在Inference中,直接使用这个模型参数。 torch.save(model_ft, 'finetuned_model_resnet18.pth') -
使用人脸检测器,检测人脸,切割人脸。这里如果有必要,需要重点关注戴口罩的人脸的检测效果。
-
对切割的人脸,用上述训练好的分类器,对人脸进行分类:戴口罩和不带口罩的。
-
下面的训练分类器的代码,和人脸检测与分类代码,都在这个链接里面下载。mask_detection代码详细讲解。
2.2 实现代码分析
2.2.1 训练分类器并且保存模型
from __future__ import print_function, division
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import numpy as np
import torchvision
from torchvision import datasets, models, transforms
import matplotlib.pyplot as plt
import time
import os
import copy
import PIL.ImageOps
import requests
from PIL import Image
# Load Data
# Data augmentation and normalization for training
# Just normalization for validation
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
data_dir = 'data/mask'
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x),
data_transforms[x])
for x in ['train', 'val']}
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=4,
shuffle=True, num_workers=4)
for x in ['train', 'val']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
class_names = image_datasets['train'].classes
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
#Visualize a few images
def imshow(inp, title=None):
"""Imshow for Tensor."""
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001) # pause a bit so that plots are updated
# Get a batch of training data
inputs, classes = next(iter(dataloaders['train']))
# Make a grid from batch
out = torchvision.utils.make_grid(inputs)
imshow(out, title=[class_names[x] for x in classes])
def train_model(model, criterion, optimizer, scheduler, num_epochs=25):
since = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# Each epoch has a training and validation phase
for phase in ['train', 'val']:
if phase == 'train':
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
running_loss = 0.0
running_corrects = 0
# Iterate over data.
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward
# track history if only in train
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# backward + optimize only if in training phase
if phase == 'train':
loss.backward()
optimizer.step()
# statistics
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
if phase == 'train':
scheduler.step()
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print('{} Loss: {:.4f} Acc: {:.4f}'.format(
phase, epoch_loss, epoch_acc))
# deep copy the model
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# load best model weights
model.load_state_dict(best_model_wts)
return model
#Visualizing the model predictions
def visualize_model(model, num_images=6):
was_training = model.training
model.eval()
images_so_far = 0
fig = plt.figure()
with torch.no_grad():
for i, (inputs, labels) in enumerate(dataloaders['val']):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
for j in range(inputs.size()[0]):
images_so_far += 1
ax = plt.subplot(num_images//2, 2, images_so_far)
ax.axis('off')
ax.set_title('predicted: {}'.format(class_names[preds[j]]))
imshow(inputs.cpu().data[j])
if images_so_far == num_images:
model.train(mode=was_training)
return
model.train(mode=was_training)
if __name__ == "__main__":
#Finetuning the convnet
#Load a pretrained model and reset final fully connected layer.
model_ft = models.resnet18(pretrained=True)
num_ftrs = model_ft.fc.in_features
# Here the size of each output sample is set to 2.
# Alternatively, it can be generalized to nn.Linear(num_ftrs, len(class_names)).
model_ft.fc = nn.Linear(num_ftrs, 2)
model_ft = model_ft.to(device)
criterion = nn.CrossEntropyLoss()
# Observe that all parameters are being optimized
optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9)
# Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)
model_ft = train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler,
num_epochs=25)
torch.save(model_ft, 'finetuned_model_resnet18.pth')
visualize_model(model_ft)
这是一些数据集的可视化图:

训练后的分类结果展示:

2.2.2 人脸检测与剪裁,然后进行分类。
这里我们采用MTCNN进行人脸检测。
import cv2
from mtcnn.core.detect import create_mtcnn_net, MtcnnDetector
from mtcnn.core.vision import vis_face
if __name__ == '__main__':
### part1: face detection
pnet, rnet, onet = create_mtcnn_net(p_model_path="./original_model/pnet_epoch.pt", r_model_path="./original_model/rnet_epoch.pt", o_model_path="./original_model/onet_epoch.pt", use_cuda=False)
mtcnn_detector = MtcnnDetector(pnet=pnet, rnet=rnet, onet=onet, min_face_size=24)
img = cv2.imread("./s_l.jpg")
img_bg = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
bboxs, landmarks = mtcnn_detector.detect_face(img)
save_name = 'r_1.jpg'
## visulaze the face detection effect.
vis_face(img_bg,bboxs,None, save_name)
### part2: mask classification.
## load classification model.
mask_model = torch.load('finetuned_model_resnet18.pth',map_location='cpu')
mask_list = []
for i in range(bboxs.shape[0]):
bbox = bboxs[i, :4]
print(img.shape)
print(bbox)
## 这里主要是人脸的剪裁,然后数据的转换,mat 格式转换为 numpy。
cropImg1 = img[int(bbox[1]):int(bbox[3]),int(bbox[0]):int(bbox[2])]
cv2.imshow('face',cropImg1)
cv2.waitKey(0)
## 剪裁人脸的格式转换
PIL_image = Image.fromarray(cropImg1)
face_img = data_transforms['val'](PIL_image)
face_img = face_img.to(device).unsqueeze(0)
output = mask_model (face_img)
_, pred = torch.max(output, 1)
mask_list.append(class_names[pred.item()])
print(class_names[pred.item()])
### 可视化的一些操作,包括人脸的rectangle以及putText到图像上。
cv2.rectangle(img, (int(bbox[0]),int(bbox[1])), (int(bbox[2]),int(bbox[3])), (0,255,0), 4)
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(img, class_names[pred.item()], (int(bbox[0]),int(bbox[1])), font, 1, (0,0,255), 2)
cv2.imshow('original',img)
# cv2.imshow('face',cropImg1)
cv2.waitKey(0)
cv2.imwrite('result_new.jpg', img)
img_result = Image.open('result_new.jpg')
plt.imshow(img_result)
算法的效果图
- 先是人脸检测效果:

- 识别分类后的效果:
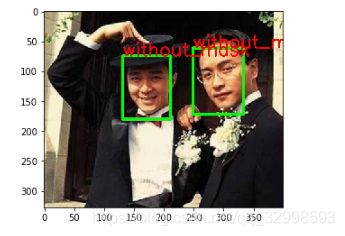
- 大规模实际效果图
用比较强的人脸检测算法,能够检测出来人脸,然后在进行分类。

3. 总结
由于采用两阶段的方法,依赖于人脸检测算法的鲁棒性,如果人脸检测算法,对戴口罩之后的遮挡,大面积遮挡,导致人脸特征减少,导致不能检出人脸。这时候,第二阶段的分类,是没有意义的。因为第一步就检测不出人脸来,性能差主要是第一阶段的能力导致的,而对于分类这一块,分类器没什么大问题。因此主要的精力放在人脸检测器的优化上来。由于原始数据集没有戴口罩的人脸,因此需要对数据分布进行调整。关于这些缺点和对应解决方案的描述文档,在这里。口罩检测描述与解决方案的文档。
下面的图像就是戴口罩之后检测不出例子,当口罩太大,遮住2/3的人脸之后,人脸检测算法检测不出来。
一些原因描述:


解决方法:
- 重新训练人脸检测算法,将戴口罩,不带口罩的人脸,全部标注出来,都标注为人脸,然后训练模型,加强其对戴口罩,遮挡住嘴巴鼻子的这一类人脸的检出率。重点关注这种戴口罩人脸的检测效果。 主要训练人脸检测模型,在普通人脸的数据基础上,增强人脸检测性能,提升戴口罩人脸检测的鲁棒性。
- 当然是直接使用人脸检测算法,将人脸标注为两类目标,戴口罩的,不带口罩的。直接在人脸检测的基础上,进行两类目标的直接检测。
其中绝大部分的问题和解决方法,都在我给的技术文档,ppt,或者下面的链接中,都描述了的,所以认真看一下我给的文件。mask_detection文档与代码讲解。
- 已经完成,两阶段口罩检测的算法设计与实现。
- TODO:一阶段口罩检测算法设计与实现。
4. 参考链接
- https://www.analyticsvidhya.com/blog/2020/08/how-to-build-a-face-mask-detector-using-retinanet-model/
- https://github.com/chandrikadeb7/Face-Mask-Detection
- https://towardsdatascience.com/covid-19-face-mask-detection-using-tensorflow-and-opencv-702dd833515b
- https://www.mygreatlearning.com/blog/real-time-face-detection/
- https://data-flair.training/blogs/face-mask-detection-with-python/
- https://www.pyimagesearch.com/2020/05/04/covid-19-face-mask-detector-with-opencv-keras-tensorflow-and-deep-learning/
- https://www.ideas2it.com/blogs/face-mask-detector-using-deep-learning-pytorch-and-computer-vision-opencv/
如果有用,记得点赞加收藏哦。!!!!