深度学习TF—8.经典CNN模型—LeNet-5、VGG13、AlexNet、GoogLeNet、ResNet、DenseNet
文章目录
-
-
- 一、LeNet-5
-
- 1.LeNet-5对cifar10分类实战
- 二、VGG13
-
- 1.VGG13对cifar10分类实战
- 三、AlexNet
- 四、GoogLeNet
- 五、ResNet—深度残差网络
-
- 1.ResNet18实战cifar10—自定义
- 六、DenseNet网络
-
一、LeNet-5
1998年,LeCun发布了LeNet-5网络架构,权值共享这个词最开始是由LeNet-5模型提出来的。虽然现在大多数人认为,2012年的AlexNet网络是深度学习的开端,但是CNN的开端可以追溯到LeNet-5模型。
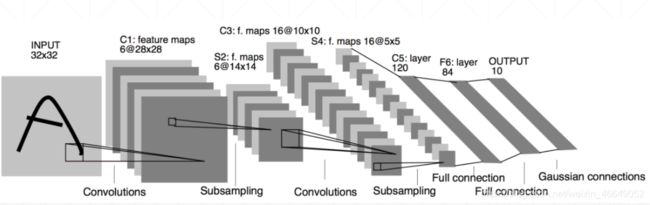
输入尺寸为32×32
卷积层为2层
池化层为2层
全连接层为2层
输出为10个类别(数字0-9的概率)
C1层为卷积层,卷积核大小为5×5,有6个卷积核(提取6种局部特征),卷积层输出大小为28×28×6,strides=1
S2层为池化层,池化框为2×2,strides=1,在减小数据量的同时也保留了有用的信息。
C3层为卷积层,卷积核大小为5×5,有16个卷积核(提取16种局部特征),卷积层输出大小为10×10×16,strides=1
S4层为池化层,池化框为2×2,strides=1,在减小数据量的同时也保留了有用的信息。
C5为全连接层,神经元个数为120个
F6为全连接层,神经元个数为84个
1.LeNet-5对cifar10分类实战
数据格式为numpy格式
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
# GPU
from tensorflow.compat.v1 import ConfigProto, InteractiveSession
config = ConfigProto()
config.gpu_options.allow_growth = True
session = InteractiveSession(config=config)
import random
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, metrics, optimizers, losses, Sequential, datasets
import matplotlib.pyplot as plt
# 随机数种子
def seed_everying(SEED):
os.environ['TF_DETERMINISTIC_OPS'] = '1'
os.environ['PYTHONHASHSEED'] = str(SEED)
random.seed(SEED)
np.random.seed(SEED)
tf.random.set_seed(SEED)
seed_everying(42)
# 加载数据集
(x, y), (x_test, y_test) = datasets.cifar10.load_data()
print('shape =', x.shape, y.shape, x_test.shape, y_test.shape)
# shape = (50000, 32, 32, 3) (50000, 1) (10000, 32, 32, 3) (10000, 1)
x = tf.cast(x, dtype=tf.float32)
y = tf.cast(y, dtype=tf.int32)
x_test = tf.cast(x_test, dtype=tf.float32)
y_test = tf.cast(y_test, dtype=tf.int32)
# 分割数据集
x_train, x_val = tf.split(x, num_or_size_splits=[40000, 10000])
y_train, y_val = tf.split(y, num_or_size_splits=[40000, 10000])
x_train, x_val, x_test = x_train / 255.0, x_val / 255.0, x_test / 255.0
y_train = tf.one_hot(y_train, depth=10)
y_train = tf.reshape(y_train, (-1, 10))
y_val = tf.one_hot(y_val, depth=10)
y_val = tf.reshape(y_val, (-1, 10))
y_test = tf.one_hot(y_test, depth=10)
y_test = tf.reshape(y_test, (-1, 10))
print(y_test.shape)
# 构建网络
def LeNet_5():
input = tf.keras.Input(shape=(32, 32, 3))
network = Sequential([
# 2* conv2d and pool
layers.Conv2D(6, kernel_size=(5, 5), padding='same', activation=tf.nn.relu),
layers.MaxPool2D(pool_size=(2, 2), padding='same', strides=1),
layers.Conv2D(16, kernel_size=(5, 5), padding='same', activation=tf.nn.relu),
layers.MaxPool2D(pool_size=(2, 2), padding='same', strides=1),
])
conv = network(input)
out = tf.reshape(conv, (-1, 32 * 32 * 16))
# 两个全连接层
out = layers.Dense(120, activation=tf.nn.relu)(out)
out = layers.Dense(84, activation=tf.nn.relu)(out)
output = layers.Dense(10, activation=tf.nn.softmax)(out)
model = tf.keras.Model(inputs=input, outputs=output)
return model
network = LeNet_5()
# 编译模型
network.compile(optimizer=optimizers.Adam(learning_rate=0.001),
loss=losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
# 训练模型
early_Stopping = keras.callbacks.EarlyStopping(monitor='val_accuracy', patience=3)
history = network.fit(x=x_train, y=y_train, batch_size=128, epochs=30,
validation_data=(x_val, y_val),
callbacks=[early_Stopping])
# 打印迭代图
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
epochs_range = np.arange(len(acc))
fig = plt.figure(figsize=(15, 5))
fig.add_subplot()
plt.plot(epochs_range, acc, label='Train acc')
plt.plot(epochs_range, val_acc, label='Val_acc')
plt.legend(loc='upper right')
plt.title('Train and Val acc')
plt.show()
# 预测
y_pred = network.predict(x_test)
y_pred = np.argmax(y_pred, axis=1)
y_true = np.argmax(y_test, axis=1)
correct = tf.reduce_sum(tf.cast(tf.equal(y_pred,y_true),dtype=tf.int32))
print(int(correct) / len(y_test))

数据格式为张量格式
#!usr/bin/env python
# -*- coding:utf-8 -*-
"""
@author: admin
@file: 1.py
@time: 2021/02/25
@desc:
"""
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
# GPU
from tensorflow.compat.v1 import ConfigProto, InteractiveSession
config = ConfigProto()
config.gpu_options.allow_growth = True
session = InteractiveSession(config=config)
import random
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, metrics, optimizers, losses, Sequential, datasets
import matplotlib.pyplot as plt
# 随机数种子
def seed_everying(SEED):
os.environ['TF_DETERMINISTIC_OPS'] = '1'
os.environ['PYTHONHASHSEED'] = str(SEED)
random.seed(SEED)
np.random.seed(SEED)
tf.random.set_seed(SEED)
seed_everying(42)
def proprecess(x, y):
x = 2 * tf.cast(x, dtype=tf.float32) / 255.0 - 1 # (-1,1)
y = tf.cast(y, dtype=tf.int32)
y = tf.one_hot(y, depth=10)
# 从张量中移去尺寸为1的维度
y = tf.squeeze(y)
return x, y
# 加载数据集
(x, y), (x_test, y_test) = datasets.cifar10.load_data()
print('shape =', x.shape, y.shape, x_test.shape, y_test.shape)
# shape = (50000, 32, 32, 3) (50000, 1) (10000, 32, 32, 3) (10000, 1)
# 分割数据集
x_train, x_val = tf.split(x, num_or_size_splits=[40000, 10000])
y_train, y_val = tf.split(y, num_or_size_splits=[40000, 10000])
# 构建张量
db_train = tf.data.Dataset.from_tensor_slices((x_train, y_train))
db_train = db_train.map(proprecess).shuffle(40000).batch(128)
db_val = tf.data.Dataset.from_tensor_slices((x_val, y_val))
db_val = db_val.map(proprecess).shuffle(10000).batch(128)
db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test))
db_test = db_test.map(proprecess).batch(128)
# 构建网络
def LeNet_5():
input = tf.keras.Input(shape=(32, 32, 3))
network = Sequential([
# 2* conv2d and pool
layers.Conv2D(6, kernel_size=(5, 5), padding='same', activation=tf.nn.relu),
layers.MaxPool2D(pool_size=(2, 2), padding='same', strides=1),
layers.Conv2D(16, kernel_size=(5, 5), padding='same', activation=tf.nn.relu),
layers.MaxPool2D(pool_size=(2, 2), padding='same', strides=1),
])
conv = network(input)
out = tf.reshape(conv, (-1, 32 * 32 * 16))
# 两个全连接层
out = layers.Dense(120, activation=tf.nn.relu)(out)
out = layers.Dense(84, activation=tf.nn.relu)(out)
output = layers.Dense(10, activation=tf.nn.softmax)(out)
model = tf.keras.Model(inputs=input, outputs=output)
return model
network = LeNet_5()
# 编译模型
network.compile(optimizer=optimizers.Adam(learning_rate=0.001),
loss=losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
# 训练模型
early_Stopping = keras.callbacks.EarlyStopping(monitor='val_accuracy', patience=5)
history = network.fit(db_train, epochs=50,
validation_data=db_val, validation_freq=1,
callbacks=[early_Stopping],verbose=2)
# 打印迭代图
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
epochs_range = np.arange(len(acc))
fig = plt.figure(figsize=(10, 8))
fig.add_subplot()
plt.plot(epochs_range, acc, label='Train acc')
plt.plot(epochs_range, val_acc, label='Val_acc')
plt.legend(loc='upper right')
plt.title('Train and Val acc')
plt.show()
# 预测
y_pred = network.predict(db_test)
y_pred = np.argmax(y_pred, axis=1)
correct = tf.reduce_sum(tf.cast(tf.equal(y_pred,tf.squeeze(y_test)),dtype=tf.int32))
print(int(correct) / len(y_test))

shape = (50000, 32, 32, 3) (50000, 1) (10000, 32, 32, 3) (10000, 1)
Epoch 1/100
313/313 - 8s - loss: 2.1210 - accuracy: 0.3333 - val_loss: 0.0000e+00 - val_accuracy: 0.0000e+00
Epoch 2/100
313/313 - 6s - loss: 2.0361 - accuracy: 0.4209 - val_loss: 2.0027 - val_accuracy: 0.4578
Epoch 3/100
313/313 - 6s - loss: 1.9920 - accuracy: 0.4664 - val_loss: 1.9975 - val_accuracy: 0.4600
Epoch 4/100
313/313 - 6s - loss: 1.9588 - accuracy: 0.5001 - val_loss: 1.9713 - val_accuracy: 0.4873
Epoch 5/100
313/313 - 6s - loss: 1.9379 - accuracy: 0.5201 - val_loss: 1.9473 - val_accuracy: 0.5096
Epoch 6/100
313/313 - 6s - loss: 1.9242 - accuracy: 0.5352 - val_loss: 1.9736 - val_accuracy: 0.4797
Epoch 7/100
313/313 - 6s - loss: 1.9075 - accuracy: 0.5513 - val_loss: 1.9341 - val_accuracy: 0.5234
Epoch 8/100
313/313 - 6s - loss: 1.8852 - accuracy: 0.5735 - val_loss: 1.9385 - val_accuracy: 0.5187
Epoch 9/100
313/313 - 6s - loss: 1.8695 - accuracy: 0.5908 - val_loss: 1.9218 - val_accuracy: 0.5368
Epoch 10/100
313/313 - 6s - loss: 1.8553 - accuracy: 0.6045 - val_loss: 1.8971 - val_accuracy: 0.5582
Epoch 11/100
313/313 - 6s - loss: 1.8128 - accuracy: 0.6484 - val_loss: 1.8627 - val_accuracy: 0.5949
Epoch 12/100
313/313 - 6s - loss: 1.7856 - accuracy: 0.6752 - val_loss: 1.8788 - val_accuracy: 0.5801
Epoch 13/100
313/313 - 6s - loss: 1.7691 - accuracy: 0.6921 - val_loss: 1.8632 - val_accuracy: 0.5946
Epoch 14/100
313/313 - 6s - loss: 1.7591 - accuracy: 0.7017 - val_loss: 1.8508 - val_accuracy: 0.6060
Epoch 15/100
313/313 - 6s - loss: 1.7500 - accuracy: 0.7115 - val_loss: 1.8601 - val_accuracy: 0.5976
Epoch 16/100
313/313 - 6s - loss: 1.7379 - accuracy: 0.7234 - val_loss: 1.8519 - val_accuracy: 0.6064
Epoch 17/100
313/313 - 6s - loss: 1.7302 - accuracy: 0.7308 - val_loss: 1.8653 - val_accuracy: 0.5964
Epoch 18/100
313/313 - 6s - loss: 1.7190 - accuracy: 0.7422 - val_loss: 1.8458 - val_accuracy: 0.6122
Epoch 19/100
313/313 - 6s - loss: 1.7134 - accuracy: 0.7481 - val_loss: 1.8573 - val_accuracy: 0.6043
Epoch 20/100
313/313 - 6s - loss: 1.7047 - accuracy: 0.7568 - val_loss: 1.8484 - val_accuracy: 0.6091
Epoch 21/100
313/313 - 6s - loss: 1.6943 - accuracy: 0.7671 - val_loss: 1.8467 - val_accuracy: 0.6089
Epoch 22/100
313/313 - 6s - loss: 1.6915 - accuracy: 0.7694 - val_loss: 1.8503 - val_accuracy: 0.6080
Epoch 23/100
313/313 - 6s - loss: 1.6841 - accuracy: 0.7777 - val_loss: 1.8555 - val_accuracy: 0.6003
0.5982
二、VGG13
2014年,Simonyan等人在其发表的文章中探讨了“深度”对于CNN网络的重要性,该文通过在现有的网络结构中不断增加具有3×3卷积核的卷积层来增加网络的深度,实验结果表明,当权值层数达到16~19时,模型的性能能够得到有效的提升,该文中的模型也被称为VGG模型。VGG模型用具有小卷积核的多个卷积层替换一个具有较大卷积核的卷积层,如用大小均为3×3卷积核的3层卷积层代替一层具有7×7卷积核的卷积层,这种替换方式减少了参数的数量,而且也能够使决策函数更具有判别性。

卷积层为10层,卷积核的大小为3×3,卷积核的个数分别为:64,64,128,128,256,256,512,512,512,512,strides=1,padding=same
池化层为5层,每层池化框大小为2×2,strides=2,padding=same
1.VGG13对cifar10分类实战
#!usr/bin/env python
# -*- coding:utf-8 -*-
"""
@author: admin
@file: VGG13.py
@time: 2021/02/25
@desc:
"""
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
# 内存自动增长
from tensorflow.compat.v1 import ConfigProto
from tensorflow.compat.v1 import InteractiveSession
config = ConfigProto()
config.gpu_options.allow_growth = True
session = InteractiveSession(config=config)
import random
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, optimizers, datasets, Sequential
import matplotlib.pyplot as plt
# 随机数种子
def seed_everying(SEED):
os.environ['TF_DETERMINISTIC_OPS'] = '1'
os.environ['PYTHONHASHSEED'] = str(SEED)
random.seed(SEED)
np.random.seed(SEED)
tf.random.set_seed(SEED)
seed_everying(42)
def proprecess(x, y):
# [0-1]
x = tf.cast(x, dtype=tf.float32) / 255.
y = tf.cast(y, dtype=tf.int32)
y = tf.one_hot(y, depth=10)
y = tf.squeeze(y)
return x, y
# 加载数据集
(x, y), (x_test, y_test) = datasets.cifar10.load_data()
print(x.shape, y.shape, x_test.shape, y_test.shape)
# (50000, 32, 32, 3) (50000, ) (10000, 32, 32, 3) (10000, )
# 分割数据集
x_train, x_val = tf.split(x, num_or_size_splits=[40000, 10000])
y_train, y_val = tf.split(y, num_or_size_splits=[40000, 10000])
# 构建张量
db_train = tf.data.Dataset.from_tensor_slices((x_train, y_train))
db_train = db_train.map(proprecess).shuffle(40000).batch(128)
db_val = tf.data.Dataset.from_tensor_slices((x_val, y_val))
db_val = db_val.map(proprecess).shuffle(10000).batch(128)
db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test))
db_test = db_test.map(proprecess).batch(128)
# 构建模型
def VGG13():
input = tf.keras.Input(shape=( 32, 32, 3))
conv_layers = Sequential([ # 5 units of conv + max pooling
# unit 1
layers.Conv2D(64, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),
layers.Conv2D(64, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 2
layers.Conv2D(128, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),
layers.Conv2D(128, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 3
layers.Conv2D(256, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),
layers.Conv2D(256, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 4
layers.Conv2D(512, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),
layers.Conv2D(512, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 5
layers.Conv2D(512, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),
layers.Conv2D(512, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same')
])
conv_out = conv_layers(input)
conv_out = tf.reshape(conv_out, (-1, 512))
# 构建全连接层
fc_net = Sequential([
layers.Dense(256, activation=tf.nn.relu),
layers.Dense(128, activation=tf.nn.relu),
layers.Dense(10, activation=tf.nn.softmax),
])
fc_output = fc_net(conv_out)
model = tf.keras.Model(inputs=input,outputs=fc_output)
return model
model = VGG13()
# 编译模型
model.compile(optimizer=optimizers.Adam(learning_rate=1e-4),
loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
# 训练模型
early_Stopping = keras.callbacks.EarlyStopping(monitor='val_accuracy', patience=5)
history = model.fit(db_train, epochs=100,
validation_data=db_val, validation_freq=1,
callbacks=[early_Stopping], verbose=2)
# 打印迭代图
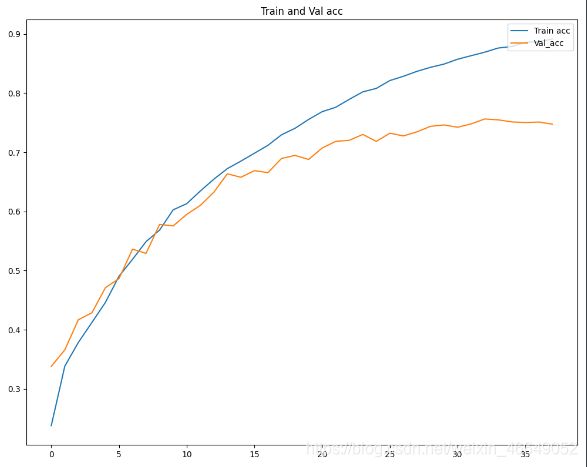
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
epochs_range = np.arange(len(acc))
fig = plt.figure(figsize=(10, 8))
fig.add_subplot()
plt.plot(epochs_range, acc, label='Train acc')
plt.plot(epochs_range, val_acc, label='Val_acc')
plt.legend(loc='upper right')
plt.title('Train and Val acc')
plt.show()
# 预测
y_pred = model.predict(db_test)
y_pred = np.argmax(y_pred, axis=1)
correct = tf.reduce_sum(tf.cast(tf.equal(y_pred, tf.squeeze(y_test)), dtype=tf.int32))
print(int(correct) / len(y_test))
(50000, 32, 32, 3) (50000, 1) (10000, 32, 32, 3) (10000, 1)
<BatchDataset shapes: ((None, 32, 32, 3), (None, 10)), types: (tf.float32, tf.float32)>
Epoch 1/100
313/313 - 33s - loss: 2.2055 - accuracy: 0.2378 - val_loss: 0.0000e+00 - val_accuracy: 0.0000e+00
Epoch 2/100
313/313 - 26s - loss: 2.1124 - accuracy: 0.3383 - val_loss: 2.0863 - val_accuracy: 0.3659
Epoch 3/100
313/313 - 26s - loss: 2.0764 - accuracy: 0.3785 - val_loss: 2.0409 - val_accuracy: 0.4169
Epoch 4/100
313/313 - 26s - loss: 2.0424 - accuracy: 0.4122 - val_loss: 2.0270 - val_accuracy: 0.4286
Epoch 5/100
313/313 - 26s - loss: 2.0098 - accuracy: 0.4462 - val_loss: 1.9817 - val_accuracy: 0.4712
Epoch 6/100
313/313 - 27s - loss: 1.9674 - accuracy: 0.4904 - val_loss: 1.9701 - val_accuracy: 0.4864
Epoch 7/100
313/313 - 26s - loss: 1.9382 - accuracy: 0.5190 - val_loss: 1.9214 - val_accuracy: 0.5362
Epoch 8/100
313/313 - 26s - loss: 1.9090 - accuracy: 0.5490 - val_loss: 1.9258 - val_accuracy: 0.5292
Epoch 9/100
313/313 - 26s - loss: 1.8899 - accuracy: 0.5685 - val_loss: 1.8810 - val_accuracy: 0.5781
Epoch 10/100
313/313 - 27s - loss: 1.8562 - accuracy: 0.6028 - val_loss: 1.8822 - val_accuracy: 0.5755
Epoch 11/100
313/313 - 26s - loss: 1.8458 - accuracy: 0.6131 - val_loss: 1.8642 - val_accuracy: 0.5950
Epoch 12/100
313/313 - 27s - loss: 1.8249 - accuracy: 0.6345 - val_loss: 1.8499 - val_accuracy: 0.6101
Epoch 13/100
313/313 - 27s - loss: 1.8051 - accuracy: 0.6545 - val_loss: 1.8268 - val_accuracy: 0.6324
Epoch 14/100
313/313 - 27s - loss: 1.7875 - accuracy: 0.6724 - val_loss: 1.7986 - val_accuracy: 0.6636
Epoch 15/100
313/313 - 27s - loss: 1.7747 - accuracy: 0.6851 - val_loss: 1.8039 - val_accuracy: 0.6578
Epoch 16/100
313/313 - 27s - loss: 1.7617 - accuracy: 0.6985 - val_loss: 1.7893 - val_accuracy: 0.6690
Epoch 17/100
313/313 - 27s - loss: 1.7487 - accuracy: 0.7118 - val_loss: 1.7968 - val_accuracy: 0.6656
Epoch 18/100
313/313 - 27s - loss: 1.7317 - accuracy: 0.7296 - val_loss: 1.7720 - val_accuracy: 0.6896
Epoch 19/100
313/313 - 27s - loss: 1.7202 - accuracy: 0.7406 - val_loss: 1.7651 - val_accuracy: 0.6948
Epoch 20/100
313/313 - 27s - loss: 1.7054 - accuracy: 0.7556 - val_loss: 1.7699 - val_accuracy: 0.6879
Epoch 21/100
313/313 - 27s - loss: 1.6924 - accuracy: 0.7687 - val_loss: 1.7527 - val_accuracy: 0.7072
Epoch 22/100
313/313 - 27s - loss: 1.6855 - accuracy: 0.7761 - val_loss: 1.7392 - val_accuracy: 0.7185
Epoch 23/100
313/313 - 27s - loss: 1.6719 - accuracy: 0.7895 - val_loss: 1.7389 - val_accuracy: 0.7203
Epoch 24/100
313/313 - 27s - loss: 1.6592 - accuracy: 0.8022 - val_loss: 1.7284 - val_accuracy: 0.7302
Epoch 25/100
313/313 - 27s - loss: 1.6535 - accuracy: 0.8080 - val_loss: 1.7415 - val_accuracy: 0.7185
Epoch 26/100
313/313 - 27s - loss: 1.6401 - accuracy: 0.8213 - val_loss: 1.7267 - val_accuracy: 0.7323
Epoch 27/100
313/313 - 27s - loss: 1.6329 - accuracy: 0.8285 - val_loss: 1.7301 - val_accuracy: 0.7277
Epoch 28/100
313/313 - 27s - loss: 1.6248 - accuracy: 0.8369 - val_loss: 1.7257 - val_accuracy: 0.7346
Epoch 29/100
313/313 - 27s - loss: 1.6176 - accuracy: 0.8437 - val_loss: 1.7160 - val_accuracy: 0.7439
Epoch 30/100
313/313 - 27s - loss: 1.6120 - accuracy: 0.8492 - val_loss: 1.7143 - val_accuracy: 0.7463
Epoch 31/100
313/313 - 27s - loss: 1.6043 - accuracy: 0.8574 - val_loss: 1.7186 - val_accuracy: 0.7424
Epoch 32/100
313/313 - 27s - loss: 1.5978 - accuracy: 0.8634 - val_loss: 1.7108 - val_accuracy: 0.7480
Epoch 33/100
313/313 - 26s - loss: 1.5925 - accuracy: 0.8693 - val_loss: 1.7056 - val_accuracy: 0.7564
Epoch 34/100
313/313 - 27s - loss: 1.5853 - accuracy: 0.8763 - val_loss: 1.7064 - val_accuracy: 0.7549
Epoch 35/100
313/313 - 26s - loss: 1.5828 - accuracy: 0.8789 - val_loss: 1.7071 - val_accuracy: 0.7514
Epoch 36/100
313/313 - 27s - loss: 1.5753 - accuracy: 0.8860 - val_loss: 1.7100 - val_accuracy: 0.7504
Epoch 37/100
313/313 - 27s - loss: 1.5745 - accuracy: 0.8871 - val_loss: 1.7070 - val_accuracy: 0.7512
Epoch 38/100
313/313 - 26s - loss: 1.5703 - accuracy: 0.8916 - val_loss: 1.7130 - val_accuracy: 0.7476
0.7422
以上代码没有加trick,准确率相较LeNet—5已有很大提升
尝试添加trick
- BatchNormalization—归一化操作
#!usr/bin/env python
# -*- coding:utf-8 -*-
"""
@author: admin
@file: VGG13.py
@time: 2021/02/25
@desc:
"""
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
# 内存自动增长
from tensorflow.compat.v1 import ConfigProto
from tensorflow.compat.v1 import InteractiveSession
config = ConfigProto()
config.gpu_options.allow_growth = True
session = InteractiveSession(config=config)
import random
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, optimizers, datasets, Sequential
import matplotlib.pyplot as plt
# 随机数种子
def seed_everying(SEED):
os.environ['TF_DETERMINISTIC_OPS'] = '1'
os.environ['PYTHONHASHSEED'] = str(SEED)
random.seed(SEED)
np.random.seed(SEED)
tf.random.set_seed(SEED)
seed_everying(42)
def proprecess(x, y):
# [0-1]
x = tf.cast(x, dtype=tf.float32) / 255.
y = tf.cast(y, dtype=tf.int32)
y = tf.one_hot(y, depth=10)
y = tf.squeeze(y)
return x, y
# 加载数据集
(x, y), (x_test, y_test) = datasets.cifar10.load_data()
print(x.shape, y.shape, x_test.shape, y_test.shape)
# (50000, 32, 32, 3) (50000, ) (10000, 32, 32, 3) (10000, )
# 分割数据集
x_train, x_val = tf.split(x, num_or_size_splits=[40000, 10000])
y_train, y_val = tf.split(y, num_or_size_splits=[40000, 10000])
# 构建张量
db_train = tf.data.Dataset.from_tensor_slices((x_train, y_train))
db_train = db_train.map(proprecess).shuffle(40000).batch(128)
db_val = tf.data.Dataset.from_tensor_slices((x_val, y_val))
db_val = db_val.map(proprecess).shuffle(10000).batch(128)
db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test))
db_test = db_test.map(proprecess).batch(128)
# 构建模型
def VGG13():
input = tf.keras.Input(shape=( 32, 32, 3))
conv_layers = Sequential([ # 5 units of conv + max pooling
layers.BatchNormalization(),
# unit 1
layers.Conv2D(64, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),
layers.Conv2D(64, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
layers.BatchNormalization(),
# unit 2
layers.Conv2D(128, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),
layers.Conv2D(128, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
layers.BatchNormalization(),
# unit 3
layers.Conv2D(256, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),
layers.Conv2D(256, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
layers.BatchNormalization(),
# unit 4
layers.Conv2D(512, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),
layers.Conv2D(512, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
layers.BatchNormalization(),
# unit 5
layers.Conv2D(512, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),
layers.Conv2D(512, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same')
])
conv_out = conv_layers(input)
conv_out = tf.reshape(conv_out, (-1, 512))
# 构建全连接层
fc_net = Sequential([
layers.BatchNormalization(),
layers.Dense(256, activation=tf.nn.relu),
layers.BatchNormalization(),
layers.Dense(128, activation=tf.nn.relu),
layers.BatchNormalization(),
layers.Dense(10, activation=tf.nn.softmax),
])
fc_output = fc_net(conv_out)
model = tf.keras.Model(inputs=input,outputs=fc_output)
return model
model = VGG13()
# 编译模型
model.compile(optimizer=optimizers.Adam(learning_rate=1e-4),
loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
# 训练模型
# 训练模型
early_Stopping = keras.callbacks.EarlyStopping(monitor='val_accuracy', patience=5)
history = model.fit(db_train, epochs=100,
validation_data=db_val, validation_freq=1,
callbacks=[early_Stopping], verbose=2)
# 打印迭代图
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
epochs_range = np.arange(len(acc))
fig = plt.figure(figsize=(10, 8))
fig.add_subplot()
plt.plot(epochs_range, acc, label='Train acc')
plt.plot(epochs_range, val_acc, label='Val_acc')
plt.legend(loc='upper right')
plt.title('Train and Val acc')
plt.show()
# 预测
y_pred = model.predict(db_test)
y_pred = np.argmax(y_pred, axis=1)
correct = tf.reduce_sum(tf.cast(tf.equal(y_pred, tf.squeeze(y_test)), dtype=tf.int32))
print(int(correct) / len(y_test))
0.7142
- Dropout
#!usr/bin/env python
# -*- coding:utf-8 -*-
"""
@author: admin
@file: VGG13.py
@time: 2021/02/25
@desc:
"""
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
# 内存自动增长
from tensorflow.compat.v1 import ConfigProto
from tensorflow.compat.v1 import InteractiveSession
config = ConfigProto()
config.gpu_options.allow_growth = True
session = InteractiveSession(config=config)
import random
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, optimizers, datasets, Sequential
import matplotlib.pyplot as plt
# 随机数种子
def seed_everying(SEED):
os.environ['TF_DETERMINISTIC_OPS'] = '1'
os.environ['PYTHONHASHSEED'] = str(SEED)
random.seed(SEED)
np.random.seed(SEED)
tf.random.set_seed(SEED)
seed_everying(42)
def proprecess(x, y):
# [0-1]
x = tf.cast(x, dtype=tf.float32) / 255.
y = tf.cast(y, dtype=tf.int32)
y = tf.one_hot(y, depth=10)
y = tf.squeeze(y)
return x, y
# 加载数据集
(x, y), (x_test, y_test) = datasets.cifar10.load_data()
print(x.shape, y.shape, x_test.shape, y_test.shape)
# (50000, 32, 32, 3) (50000, ) (10000, 32, 32, 3) (10000, )
# 分割数据集
x_train, x_val = tf.split(x, num_or_size_splits=[40000, 10000])
y_train, y_val = tf.split(y, num_or_size_splits=[40000, 10000])
# 构建张量
db_train = tf.data.Dataset.from_tensor_slices((x_train, y_train))
db_train = db_train.map(proprecess).shuffle(40000).batch(128)
db_val = tf.data.Dataset.from_tensor_slices((x_val, y_val))
db_val = db_val.map(proprecess).shuffle(10000).batch(128)
db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test))
db_test = db_test.map(proprecess).batch(128)
# 构建模型
def VGG13():
input = tf.keras.Input(shape=(32, 32, 3))
conv_layers = Sequential([ # 5 units of conv + max pooling
layers.BatchNormalization(),
# unit 1
layers.Conv2D(64, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),
layers.Conv2D(64, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
layers.BatchNormalization(),
# unit 2
layers.Conv2D(128, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),
layers.Conv2D(128, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
layers.BatchNormalization(),
# unit 3
layers.Conv2D(256, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),
layers.Conv2D(256, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
layers.BatchNormalization(),
# unit 4
layers.Conv2D(512, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),
layers.Conv2D(512, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
layers.BatchNormalization(),
# unit 5
layers.Conv2D(512, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),
layers.Conv2D(512, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same')
])
conv_out = conv_layers(input)
conv_out = tf.reshape(conv_out, (-1, 512))
# 构建全连接层
fc_net = Sequential([
layers.BatchNormalization(),
layers.Dropout(0.1),
layers.Dense(256, activation=tf.nn.relu),
layers.BatchNormalization(),
layers.Dropout(0.1),
layers.Dense(128, activation=tf.nn.relu),
layers.BatchNormalization(),
layers.Dropout(0.1),
layers.Dense(10, activation=tf.nn.softmax),
])
fc_output = fc_net(conv_out)
model = tf.keras.Model(inputs=input,outputs=fc_output)
return model
model = VGG13()
# 编译模型
model.compile(optimizer=optimizers.Adam(learning_rate=1e-4),
loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
# 训练模型
# 训练模型
early_Stopping = keras.callbacks.EarlyStopping(monitor='val_accuracy', patience=5)
history = model.fit(db_train, epochs=100,
validation_data=db_val, validation_freq=1,
callbacks=[early_Stopping], verbose=2)
# 打印迭代图
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
epochs_range = np.arange(len(acc))
fig = plt.figure(figsize=(10, 8))
fig.add_subplot()
plt.plot(epochs_range, acc, label='Train acc')
plt.plot(epochs_range, val_acc, label='Val_acc')
plt.legend(loc='upper right')
plt.title('Train and Val acc')
plt.show()
# 预测
y_pred = model.predict(db_test)
y_pred = np.argmax(y_pred, axis=1)
correct = tf.reduce_sum(tf.cast(tf.equal(y_pred, tf.squeeze(y_test)), dtype=tf.int32))
print(int(correct) / len(y_test))
0.7402

trick加上影响不大,原因不知道
三、AlexNet
AlexNet在增加网络深度的同时,采用了很多新技术:采用ReLU代替饱和非线性函数tanh函数,降低了模型的计算复杂度,模型的训练速度也提升了几倍;通过Dropout技术在训练过程中将中间层的一些神经元随机置为0,使模型更具有鲁棒性,也减少了全连接层的过拟合;而且还通过图像平移、图像水平镜像变换、改变图像灰度等方式来增加训练样本,从而减少过拟合。

在两个GPU上训练(由于原网络需要两个GPU,这里就不提供实例进行训练)
单GPU:
输入为224×224×3
第一个卷积层:卷积核为11×11,卷积核个数为96,步长为4,第一个卷积层输出为55×55×96
下面定义各层参考于:从零开始搭建神经网络(五)卷积神经网络(CNN)
import tensorflow as tf
import numpy as np
# 定义各层功能
# 最大池化层
def maxPoolLayer(x, kHeight, kWidth, strideX, strideY, name, padding = "SAME"):
"""max-pooling"""
return tf.nn.max_pool(x, ksize = [1, kHeight, kWidth, 1],
strides = [1, strideX, strideY, 1], padding = padding, name = name)
# dropout
def dropout(x, keepPro, name = None):
"""dropout"""
return tf.nn.dropout(x, keepPro, name)
# 归一化层
def LRN(x, R, alpha, beta, name = None, bias = 1.0):
"""LRN"""
return tf.nn.local_response_normalization(x, depth_radius = R, alpha = alpha,
beta = beta, bias = bias, name = name)
# 全连接层
def fcLayer(x, inputD, outputD, reluFlag, name):
"""fully-connect"""
with tf.variable_scope(name) as scope:
w = tf.get_variable("w", shape = [inputD, outputD], dtype = "float")
b = tf.get_variable("b", [outputD], dtype = "float")
out = tf.nn.xw_plus_b(x, w, b, name = scope.name)
if reluFlag:
return tf.nn.relu(out)
else:
return out
# 卷积层
def convLayer(x, kHeight, kWidth, strideX, strideY,
featureNum, name, padding = "SAME", groups = 1):
"""convolution"""
channel = int(x.get_shape()[-1])
conv = lambda a, b: tf.nn.conv2d(a, b, strides = [1, strideY, strideX, 1], padding = padding)
with tf.variable_scope(name) as scope:
w = tf.get_variable("w", shape = [kHeight, kWidth, channel/groups, featureNum])
b = tf.get_variable("b", shape = [featureNum])
xNew = tf.split(value = x, num_or_size_splits = groups, axis = 3)
wNew = tf.split(value = w, num_or_size_splits = groups, axis = 3)
featureMap = [conv(t1, t2) for t1, t2 in zip(xNew, wNew)]
mergeFeatureMap = tf.concat(axis = 3, values = featureMap)
# print mergeFeatureMap.shape
out = tf.nn.bias_add(mergeFeatureMap, b)
return tf.nn.relu(tf.reshape(out, mergeFeatureMap.get_shape().as_list()), name = scope.name)
class alexNet(object):
"""alexNet model"""
def __init__(self, x, keepPro, classNum, skip, modelPath = "bvlc_alexnet.npy"):
self.X = x
self.KEEPPRO = keepPro
self.CLASSNUM = classNum
self.SKIP = skip
self.MODELPATH = modelPath
#build CNN
self.buildCNN()
# 构建AlexNet
def buildCNN(self):
"""build model"""
conv1 = convLayer(self.X, 11, 11, 4, 4, 96, "conv1", "VALID")
lrn1 = LRN(conv1, 2, 2e-05, 0.75, "norm1")
pool1 = maxPoolLayer(lrn1, 3, 3, 2, 2, "pool1", "VALID")
conv2 = convLayer(pool1, 5, 5, 1, 1, 256, "conv2", groups = 2)
lrn2 = LRN(conv2, 2, 2e-05, 0.75, "lrn2")
pool2 = maxPoolLayer(lrn2, 3, 3, 2, 2, "pool2", "VALID")
conv3 = convLayer(pool2, 3, 3, 1, 1, 384, "conv3")
conv4 = convLayer(conv3, 3, 3, 1, 1, 384, "conv4", groups = 2)
conv5 = convLayer(conv4, 3, 3, 1, 1, 256, "conv5", groups = 2)
pool5 = maxPoolLayer(conv5, 3, 3, 2, 2, "pool5", "VALID")
fcIn = tf.reshape(pool5, [-1, 256 * 6 * 6])
fc1 = fcLayer(fcIn, 256 * 6 * 6, 4096, True, "fc6")
dropout1 = dropout(fc1, self.KEEPPRO)
fc2 = fcLayer(dropout1, 4096, 4096, True, "fc7")
dropout2 = dropout(fc2, self.KEEPPRO)
self.fc3 = fcLayer(dropout2, 4096, self.CLASSNUM, True, "fc8")
def loadModel(self, sess):
"""load model"""
wDict = np.load(self.MODELPATH, encoding = "bytes").item()
#for layers in model
for name in wDict:
if name not in self.SKIP:
with tf.variable_scope(name, reuse = True):
for p in wDict[name]:
if len(p.shape) == 1:
#bias
sess.run(tf.get_variable('b', trainable = False).assign(p))
else:
#weights
sess.run(tf.get_variable('w', trainable = False).assign(p))
四、GoogLeNet
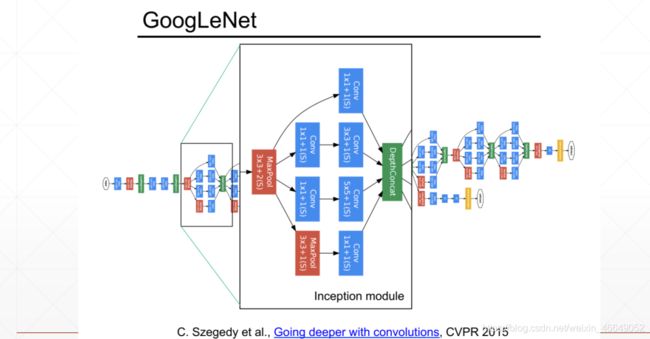
2014年,Szegedy等人大大增加了CNN的深度,提出了一个超过20层的CNN结构,称为GoogleNet。在GoogleNet的结构中采用了3种类型的卷积操作,分别是1×1、3×3、5×5,该结构的主要特点是提升了计算机资源的利用率,它的参数比AlexNet少了12倍,而且GoogleNet的准确率更高,在LSVRC-14中获得了图像分类“指定数据”组的第1名。

五、ResNet—深度残差网络
2015年,He等人采用残差网络(Residual Networks,ResNet)来解决梯度消失的问题。ResNet的主要特点是跨层连接,它通过引入捷径连接技术(shortcut connections)将输入跨层传递并与卷积的结果相加。在ResNet中只有一个池化层,它连接在最后一个卷积层后面。ResNet使得底层的网络能够得到充分训练,准确率也随着深度的加深而得到显著提升。将深度为152层的ResNet用于LSVRC-15的图像分类比赛中,它获得了第1名的成绩。在文献中,还尝试将ResNet的深度设置为1000,并在CIFAR-10图像处理数据集中验证该模型。
网络的层数越深,越有可能获得更好的泛化能力。但是当模型加深以后,网络变得越来越难训练,这主要是由于梯度弥散和梯度爆炸现象造成的。在较深层数的神经网络中,梯度信息由网络的末层逐层传向网络的首层时,传递的过程中会出现梯度接近于0 或梯度值非常大的现象。网络层数越深,这种现象可能会越严重。那么怎么解决深层神经网络的梯度弥散和梯度爆炸现象呢?一个很自然的想法是,既然浅层神经网络不容易出现这些梯度现象,那么可以尝试给深层神经网络添加一种回退到浅层神经网络的机制。当深层神经网络可以轻松地回退到浅层神经网络时,深层神经网络可以获得与浅层神经网络相当的模型性能,而不至于更糟糕。通过在输入和输出之间添加一条直接连接的Skip Connection 可以让神经网络具有回退的能力。以VGG13 深度神经网络为例,假设观察到VGG13 模型出现梯度弥散现象,而10 层的网络模型并没有观测到梯度弥散现象,那么可以考虑在最后的两个卷积层添加SkipConnection,通过这种方式,网络模型可以自动选择是否经由这两个卷积层完成特征变换,还是直接跳过这两个卷积层而选择Skip Connection,亦或结合两个卷积层和Skip Connection 的输出
该网络的架构和 VGGNet 类似,主要包括 3x3 的卷积核。因此可以在 VGGNet 的基础上在层之间添加捷径连接以构建一个残差网络。下图展示了从 VGG-19 的部分早期层合成残差网络的过程。

参考于Tensorflow2.0之深度残差网络resnet18实现
1.ResNet18实战cifar10—自定义
实现18 层的深度残差网络ResNet18,并在CIFAR10 图片数据集上训练与测试,标准的 ResNet18 接受输入为22 × 22 大小的图片数据,我们将ResNet18 进行适量调整,使得它输入大小为32×32,输出维度为10。调整后的ResNet18 网络结构如图所示。

将renet的网络搭建放在一个py文件里,将网络训练放在另一个文件里训练的时候通过import导入进来
实现Basic Block
其中包括两个卷积层
由于梯度的加深导致后面的梯度很难传播到前面的层中,所以增加了短接操作,使得这一层从理论上可以退化为短接线。此时,即使发生过拟合,也可以直接从短接层走,提供了一种深层次网络退化为浅层次网络的能力。

class BasicBlock(layers.Layer):
# 残差类模块
def __init__(self, filter_num, strides=1):
super(BasicBlock, self).__init__()
# f(x)包含两个普通卷积层,创建卷积层1
# # strides=1时,得到output会略小于inputsize,所有需要设置padding=‘same’,保证两者相同
self.conv1 = layers.Conv2D(filter_num, (3, 3), strides=strides, padding='same')
self.bh1 = layers.BatchNormalization()
self.relu = layers.Activation('relu')
# # convolution layer = conv + bn + relu
# 创建卷积层2
self.conv2 = layers.Conv2D(filter_num, (3, 3), strides=1, padding='same')
self.bh2 = layers.BatchNormalization()
# 插入identity——短接层
if strides != 1:
# 下采样
self.downsample = Sequential()
self.downsample.add(layers.Conv2D(filter_num, (1, 1), strides=strides))
else: # 否者就直接连接
self.downsample = lambda x: x
self.stride = stride
# 前向传播
def call(self, inputs, training=None):
# 下采样——残差
residual = self.downsample(inputs)
# 前向传播函数
con1 = self.conv1(inputs)
bh1 = self.bh1(con1)
relu1 = self.relu(bh1)
conv2 = self.conv2(relu1)
bh2 = self.bh2(conv2)
# f(x) + x操作
output = layers.add([bh2, residual])
# 再通过激活函数并返回
output = self.relu(output)
return output
实现Res Block
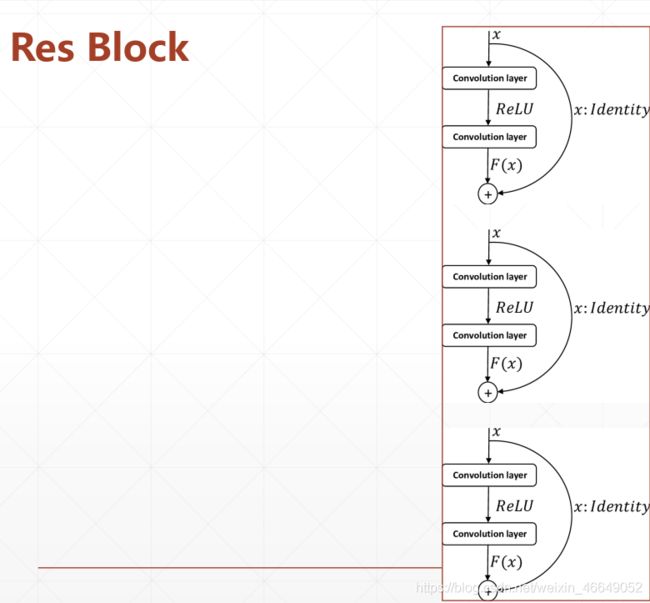
在创建resnet的之前,一般按照特征图高宽ℎ/逐渐减少,通道数逐渐增大的经验法则。可以通过堆叠通道数逐渐增大的Res Block 来实现高层特征的提取,通过build_resblock 可以一次完成多个残差模块的新建。
def build_resblock(s![elf, filter_num, blocks, stride=1):
# 堆叠filter_num个BasicBlock
res_blocks = Sequential()
# 只有第一个BasicBlock 的步长可能不为1,实现下采样
res_blocks.add(BasicBlock(filter_num, stride))
for _ in range(1, blocks):#其他BasicBlock 步长都为1
res_blocks.add(BasicBlock(filter_num, stride=1))
return res_blocks
实现resnet网络
class ResNet(keras.Model):
def __init__(self, layer_dims, num_classes=10):
super(ResNet, self).__init__()
# 预处理层
self.stem = Sequential([layers.Conv2D(64, (3, 3), strides=(1, 1)),
layers.BatchNormalization(),
layers.Activation('relu'),
layers.MaxPool2D(pool_size=(2, 2), strides=(1, 1), padding='same')])
# 堆叠4个Block, 每个block包含了多个BasicBlock,设置步长不一样
# 按照经验chanel从小到大,feature_size从大到小
self.layer1 = self.build_resblock(64, layer_dims[0])
self.layer2 = self.build_resblock(128, layer_dims[0], strides=2)
self.layer3 = self.build_resblock(256, layer_dims[0], strides=2)
self.layer4 = self.build_resblock(512, layer_dims[0], strides=2)
# 自适应层
# 原理是对512个通道上面的feature像素值做一个平均,得到一个像素的平均值,将512个像素值送到下一层做均值
self.avgpool = layers.GlobalAveragePooling2D()
# 最后连接一个全连接层分类
self.fc = layers.Dense(num_classes)
def call(self, inputs, training=None):
# 通过根网络
x = self.stem(inputs)
# 一次通过4个模块
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
# 通过池化层
x = self.avgpool(x)
# 通过全连接层
x = self.fc(x)
return x
def build_resblock(self, filter_num, blocks, strides=1):
# 辅助函数,堆叠filter_num个BasicBlock
# 只有第一个BasicBlock的步长可能不为1
res_block = Sequential()
res_block.add(BasicBlock(filter_num, strides))
for _ in range(1, blocks): # 其他BasicBlock步长都为1
res_block.add(BasicBlock(filter_num, strides))
return res_block
通过给ResNet类传参可以构造出resnet18的网络
def resnet18():
return ResNet([2, 2, 2, 2])
def resnet34():
return ResNet([3, 4, 6, 3])
网络完整代码
#!usr/bin/env python
# -*- coding:utf-8 -*-
"""
@author: admin
@file: resnet.py
@time: 2021/02/25
@desc:
"""
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers,Sequential
class BasicBlock(layers.Layer):
# 残差类模块
def __init__(self, filter_num, strides=1):
super(BasicBlock, self).__init__()
# f(x)包含两个普通卷积层,创建卷积层1
self.conv1 = layers.Conv2D(filter_num, (3, 3), strides=strides, padding='same')
self.bh1 = layers.BatchNormalization()
self.relu = layers.Activation('relu')
# 创建卷积层2
self.conv2 = layers.Conv2D(filter_num, (3, 3), strides=1, padding='same')
self.bh2 = layers.BatchNormalization()
# 插入identity
if strides != 1:
# 下采样
self.downsample = Sequential()
self.downsample.add(layers.Conv2D(filter_num, (1, 1), strides=strides))
else: # 否者就直接连接
self.downsample = lambda x: x
self.stride = strides
def call(self, inputs, training=None):
# 下采样——残差
residual = self.downsample(inputs)
# 前向传播函数
con1 = self.conv1(inputs)
bh1 = self.bh1(con1)
relu1 = self.relu(bh1)
conv2 = self.conv2(relu1)
bh2 = self.bh2(conv2)
# f(x) + x操作
output = layers.add([bh2, residual])
# 再通过激活函数并返回
output = self.relu(output)
return output
def build_resblock(self, filter_num, blocks, stride=1):
# 堆叠filter_num 个BasicBlock
res_blocks = Sequential()
# 只有第一个BasicBlock 的步长可能不为1,实现下采样
res_blocks.add(BasicBlock(filter_num, stride))
for _ in range(1, blocks): # 其他BasicBlock 步长都为1
res_blocks.add(BasicBlock(filter_num, stride=1))
return res_blocks
class ResNet(keras.Model):
def __init__(self, layer_dims, num_classes=10):
super(ResNet, self).__init__()
# 根网络预处理
self.stem = Sequential([layers.Conv2D(64, (3, 3), strides=(1, 1)),
layers.BatchNormalization(),
layers.Activation('relu'),
layers.MaxPool2D(pool_size=(2, 2), strides=(1, 1), padding='same')])
# 堆叠4个Block, 每个block包含了多个BasicBlock,设置步长不一样
self.layer1 = self.build_resblock(64, layer_dims[0])
self.layer2 = self.build_resblock(128, layer_dims[0], strides=2)
self.layer3 = self.build_resblock(256, layer_dims[0], strides=2)
self.layer4 = self.build_resblock(512, layer_dims[0], strides=2)
# 通过Pooling层将高管降低为1x1
self.avgpool = layers.GlobalAveragePooling2D()
# 最后连接一个全连接层分类
self.fc = layers.Dense(num_classes)
def call(self, inputs, training=None):
# 通过根网络
x = self.stem(inputs)
# 一次通过4个模块
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
# 通过池化层
x = self.avgpool(x)
# 通过全连接层
x = self.fc(x)
return x
def build_resblock(self, filter_num, blocks, strides=1):
# 辅助函数,堆叠filter_num个BasicBlock
# 只有第一个BasicBlock的步长可能不为1
res_block = Sequential()
res_block.add(BasicBlock(filter_num, strides))
for _ in range(1, blocks): # 其他BasicBlock步长都为1
res_block.add(BasicBlock(filter_num, strides))
return res_block
def resnet18():
return ResNet([2, 2, 2, 2])
网络训练
#!usr/bin/env python
# -*- coding:utf-8 -*-
"""
@author: admin
@file: 训练.py
@time: 2021/02/25
@desc:
"""
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
# 内存自动增长
from tensorflow.compat.v1 import ConfigProto
from tensorflow.compat.v1 import InteractiveSession
config = ConfigProto()
config.gpu_options.allow_growth = True
session = InteractiveSession(config=config)
import random
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, optimizers, datasets, Sequential
from resnet import resnet18
# 随机数种子
def seed_everying(SEED):
os.environ['TF_DETERMINISTIC_OPS'] = '1'
os.environ['PYTHONHASHSEED'] = str(SEED)
random.seed(SEED)
np.random.seed(SEED)
tf.random.set_seed(SEED)
seed_everying(42)
def proprecess(x, y):
# [0-1]
x = tf.cast(x, dtype=tf.float32) / 255.
y = tf.cast(y, dtype=tf.int32)
y = tf.one_hot(y, depth=10)
y = tf.squeeze(y)
return x, y
# 加载数据集
(x, y), (x_test, y_test) = datasets.cifar10.load_data()
print(x.shape, y.shape, x_test.shape, y_test.shape)
# (50000, 32, 32, 3) (50000, ) (10000, 32, 32, 3) (10000, )
# 分割数据集
x_train, x_val = tf.split(x, num_or_size_splits=[40000, 10000])
y_train, y_val = tf.split(y, num_or_size_splits=[40000, 10000])
# 构建张量
db_train = tf.data.Dataset.from_tensor_slices((x_train, y_train))
db_train = db_train.map(proprecess).shuffle(40000).batch(256)
db_val = tf.data.Dataset.from_tensor_slices((x_val, y_val))
db_val = db_val.map(proprecess).shuffle(10000).batch(256)
db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test))
db_test = db_test.map(proprecess).batch(256)
sample = next(iter(db_train))
print('sample:', sample[0].shape, sample[1].shape,
tf.reduce_min(sample[0]), tf.reduce_max(sample[0]))
def main():
# [b, 32, 32, 3] => [b, 1, 1, 512]
model = resnet18()
model.build(input_shape=(None, 32, 32, 3))
model.compile(optimizer=optimizers.Adam(learning_rate=1e-4),
loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
# 训练模型
early_Stopping = keras.callbacks.EarlyStopping(monitor='val_accuracy', patience=5)
history = model.fit(db_train, epochs=100,
validation_data=db_val, validation_freq=1,
callbacks=[early_Stopping], verbose=2)
# 打印迭代图
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
epochs_range = np.arange(len(acc))
fig = plt.figure(figsize=(10, 8))
fig.add_subplot()
plt.plot(epochs_range, acc, label='Train acc')
plt.plot(epochs_range, val_acc, label='Val_acc')
plt.legend(loc='upper right')
plt.title('Train and Val acc')
plt.show()
# 预测
y_pred = model.predict(db_test)
y_pred = np.argmax(y_pred, axis=1)
correct = tf.reduce_sum(tf.cast(tf.equal(y_pred, tf.squeeze(y_test)), dtype=tf.int32))
print(int(correct) / len(y_test))
if __name__ == '__main__':
main()
训练结果为
(50000, 32, 32, 3) (50000, 1) (10000, 32, 32, 3) (10000, 1)
sample: (256, 32, 32, 3) (256, 10) tf.Tensor(0.0, shape=(), dtype=float32) tf.Tensor(1.0, shape=(), dtype=float32)
Epoch 1/100
157/157 - 56s - loss: 1.7597 - accuracy: 0.3667 - val_loss: 0.0000e+00 - val_accuracy: 0.0000e+00
Epoch 2/100
157/157 - 44s - loss: 1.2077 - accuracy: 0.5658 - val_loss: 2.5604 - val_accuracy: 0.1443
Epoch 3/100
157/157 - 45s - loss: 0.8812 - accuracy: 0.6904 - val_loss: 2.2478 - val_accuracy: 0.2889
Epoch 4/100
157/157 - 45s - loss: 0.5679 - accuracy: 0.8080 - val_loss: 1.6933 - val_accuracy: 0.4793
Epoch 5/100
157/157 - 45s - loss: 0.3047 - accuracy: 0.9031 - val_loss: 1.7637 - val_accuracy: 0.5010
Epoch 6/100
157/157 - 45s - loss: 0.1791 - accuracy: 0.9430 - val_loss: 1.8352 - val_accuracy: 0.5466
Epoch 7/100
157/157 - 45s - loss: 0.1145 - accuracy: 0.9646 - val_loss: 2.0367 - val_accuracy: 0.5480
Epoch 8/100
157/157 - 45s - loss: 0.0975 - accuracy: 0.9695 - val_loss: 2.1200 - val_accuracy: 0.5478
Epoch 9/100
157/157 - 45s - loss: 0.1122 - accuracy: 0.9620 - val_loss: 2.2285 - val_accuracy: 0.5350
Epoch 10/100
157/157 - 45s - loss: 0.1264 - accuracy: 0.9566 - val_loss: 2.1866 - val_accuracy: 0.5516
Epoch 11/100
157/157 - 45s - loss: 0.1002 - accuracy: 0.9650 - val_loss: 2.1875 - val_accuracy: 0.5533
Epoch 12/100
157/157 - 45s - loss: 0.0570 - accuracy: 0.9818 - val_loss: 2.2877 - val_accuracy: 0.5549
Epoch 13/100
157/157 - 45s - loss: 0.0432 - accuracy: 0.9858 - val_loss: 2.5048 - val_accuracy: 0.5558
Epoch 14/100
157/157 - 45s - loss: 0.0459 - accuracy: 0.9841 - val_loss: 2.4180 - val_accuracy: 0.5649
Epoch 15/100
157/157 - 45s - loss: 0.1082 - accuracy: 0.9622 - val_loss: 2.4957 - val_accuracy: 0.5413
Epoch 16/100
157/157 - 45s - loss: 0.1177 - accuracy: 0.9596 - val_loss: 2.2915 - val_accuracy: 0.5543
Epoch 17/100
157/157 - 45s - loss: 0.0846 - accuracy: 0.9715 - val_loss: 2.3482 - val_accuracy: 0.5795
Epoch 18/100
157/157 - 45s - loss: 0.0475 - accuracy: 0.9837 - val_loss: 2.2737 - val_accuracy: 0.5816
Epoch 19/100
157/157 - 45s - loss: 0.0490 - accuracy: 0.9838 - val_loss: 2.4608 - val_accuracy: 0.5698
Epoch 20/100
157/157 - 45s - loss: 0.0276 - accuracy: 0.9910 - val_loss: 2.3808 - val_accuracy: 0.5964
Epoch 21/100
157/157 - 45s - loss: 0.0347 - accuracy: 0.9881 - val_loss: 2.6131 - val_accuracy: 0.5756
Epoch 22/100
157/157 - 45s - loss: 0.0434 - accuracy: 0.9854 - val_loss: 2.5044 - val_accuracy: 0.5694
Epoch 23/100
157/157 - 45s - loss: 0.0985 - accuracy: 0.9661 - val_loss: 2.5350 - val_accuracy: 0.5713
Epoch 24/100
157/157 - 45s - loss: 0.0759 - accuracy: 0.9735 - val_loss: 2.4286 - val_accuracy: 0.5650
Epoch 25/100
157/157 - 45s - loss: 0.0415 - accuracy: 0.9863 - val_loss: 2.3778 - val_accuracy: 0.5991
Epoch 26/100
157/157 - 45s - loss: 0.0265 - accuracy: 0.9909 - val_loss: 2.4366 - val_accuracy: 0.5902
Epoch 27/100
157/157 - 45s - loss: 0.0277 - accuracy: 0.9901 - val_loss: 2.5511 - val_accuracy: 0.5897
Epoch 28/100
157/157 - 45s - loss: 0.0423 - accuracy: 0.9858 - val_loss: 2.7998 - val_accuracy: 0.5601
Epoch 29/100
157/157 - 45s - loss: 0.0652 - accuracy: 0.9769 - val_loss: 2.6011 - val_accuracy: 0.5833
Epoch 30/100
157/157 - 45s - loss: 0.0614 - accuracy: 0.9791 - val_loss: 2.6302 - val_accuracy: 0.5737
0.5643

可以看到该网络过拟合严重,所以训练准确率非常低
这一篇文章的准确率高
六、DenseNet网络
参考于https://blog.csdn.net/python_LC_nohtyp/article/details/104477074
Skip Connection 的思想在ResNet 上面获得了巨大的成功,研究人员开始尝试不同的Skip Connection 方案,其中比较流行的就是DenseNet 。DenseNet 将前面所有层的特征图信息通过Skip Connection 与当前层输出进行聚合,与ResNet 的对应位置相加方式不同,DenseNet 采用在通道轴维度进行拼接操作,聚合特征信息。如下图 所示,输入0 通过H1卷积层得到输出1,1与 在通道轴上进行拼接,得到聚合后的特征张量,送入H2卷积层,得到输出2,同样的方法,2与前面所有层的特征信息 1与 进行聚合,再送入下一层。如此循环,直至最后一层的输出4和前面所有层的特征信息:{}= 1 2 3进行聚合得到模块的最终输出。这样一种基于SkipConnection稠密连接的模块叫做Dense Block。
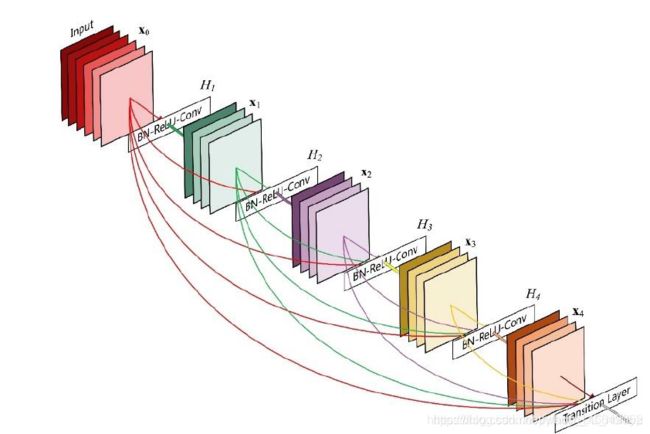
DenseNet 通过堆叠多个Dense Block 构成复杂的深层神经网络

如果对您有帮助,麻烦点赞关注,这真的对我很重要!!!如果需要互关,请评论留言!
