widerface转换为VOC数据集
注意:VM虚拟机无法使用物理机显卡,建议用docker
有大兄弟表示运行完 train.txt 没有内容,解决方法为路径不能有中文。
一、下载widerface数据集
widerface数据集下载地址:http://shuoyang1213.me/WIDERFACE/
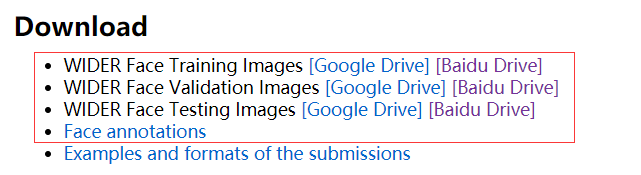
wider_face_split.zip widerface的标注文件(只有train和val的标注文件)
WIDER_test.zip、WIDER_val.zip、WIDER_train.zip分别为图像文件
二、相关文件配置
1、设置一个根目录(本人:/home/roy/TF/widerface)
2、将下载的四个文件解压
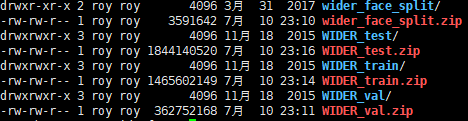
3、创建三个文件夹
Annotations 标注文件夹
ImageSets/Main/train.txt 图片文件名
JPEGImages 图片源文件
![]()
其中ImageSets内还要创建一个Main文件夹
三、转换脚本
注意修改脚本中地址
rootdir = "/home/roy/TF/widerface"
gtfile = "/home/roy/TF/widerface/wider_face_split/wider_face_train_bbx_gt.txt"
im_folder = "/home/roy/TF/widerface/WIDER_train/images"
fwrite = open("/home/roy/TF/widerface/ImageSets/Main/train.txt", "w")
import os,cv2,sys,shutil,numpy
from xml.dom.minidom import Document
import os
# 本程序可以讲widerface转为VOC格式的数据
def writexml(filename, saveimg, bboxes, xmlpath):
doc = Document()
annotation = doc.createElement('annotation')
doc.appendChild(annotation)
folder = doc.createElement('folder')
folder_name = doc.createTextNode('widerface')
folder.appendChild(folder_name)
annotation.appendChild(folder)
filenamenode = doc.createElement('filename')
filename_name = doc.createTextNode(filename)
filenamenode.appendChild(filename_name)
annotation.appendChild(filenamenode)
source = doc.createElement('source')
annotation.appendChild(source)
database = doc.createElement('database')
database.appendChild(doc.createTextNode('wider face Database'))
source.appendChild(database)
annotation_s = doc.createElement('annotation')
annotation_s.appendChild(doc.createTextNode('PASCAL VOC2007'))
source.appendChild(annotation_s)
image = doc.createElement('image')
image.appendChild(doc.createTextNode('flickr'))
source.appendChild(image)
flickrid = doc.createElement('flickrid')
flickrid.appendChild(doc.createTextNode('-1'))
source.appendChild(flickrid)
owner = doc.createElement('owner')
annotation.appendChild(owner)
flickrid_o = doc.createElement('flickrid')
flickrid_o.appendChild(doc.createTextNode('muke'))
owner.appendChild(flickrid_o)
name_o = doc.createElement('name')
name_o.appendChild(doc.createTextNode('muke'))
owner.appendChild(name_o)
size = doc.createElement('size')
annotation.appendChild(size)
width = doc.createElement('width')
width.appendChild(doc.createTextNode(str(saveimg.shape[1])))
height = doc.createElement('height')
height.appendChild(doc.createTextNode(str(saveimg.shape[0])))
depth = doc.createElement('depth')
depth.appendChild(doc.createTextNode(str(saveimg.shape[2])))
size.appendChild(width)
size.appendChild(height)
size.appendChild(depth)
segmented = doc.createElement('segmented')
segmented.appendChild(doc.createTextNode('0'))
annotation.appendChild(segmented)
for i in range(len(bboxes)):
bbox = bboxes[i]
objects = doc.createElement('object')
annotation.appendChild(objects)
object_name = doc.createElement('name')
object_name.appendChild(doc.createTextNode('face'))
objects.appendChild(object_name)
pose = doc.createElement('pose')
pose.appendChild(doc.createTextNode('Unspecified'))
objects.appendChild(pose)
truncated = doc.createElement('truncated')
truncated.appendChild(doc.createTextNode('0'))
objects.appendChild(truncated)
difficult = doc.createElement('difficult')
difficult.appendChild(doc.createTextNode('0'))
objects.appendChild(difficult)
bndbox = doc.createElement('bndbox')
objects.appendChild(bndbox)
xmin = doc.createElement('xmin')
xmin.appendChild(doc.createTextNode(str(bbox[0])))
bndbox.appendChild(xmin)
ymin = doc.createElement('ymin')
ymin.appendChild(doc.createTextNode(str(bbox[1])))
bndbox.appendChild(ymin)
xmax = doc.createElement('xmax')
xmax.appendChild(doc.createTextNode(str(bbox[0] + bbox[2])))
bndbox.appendChild(xmax)
ymax = doc.createElement('ymax')
ymax.appendChild(doc.createTextNode(str(bbox[1] + bbox[3])))
bndbox.appendChild(ymax)
f = open(xmlpath, "w")
f.write(doc.toprettyxml(indent=''))
f.close()
rootdir = "/home/roy/TF/widerface"
gtfile = "/home/roy/TF/widerface/wider_face_split/wider_face_train_bbx_gt.txt"
im_folder = "/home/roy/TF/widerface/WIDER_train/images"
fwrite = open("/home/roy/TF/widerface/ImageSets/Main/train.txt", "w")
# wider_face_train_bbx_gt.txt的文件内容
# 第一行为名字
# 第二行为头像的数量 n
# 剩下的为n行人脸数据
# 以下为示例
# 0--Parade/0_Parade_marchingband_1_117.jpg
# 9
# 69 359 50 36 1 0 0 0 0 1
# 227 382 56 43 1 0 1 0 0 1
# 296 305 44 26 1 0 0 0 0 1
# 353 280 40 36 2 0 0 0 2 1
# 885 377 63 41 1 0 0 0 0 1
# 819 391 34 43 2 0 0 0 1 0
# 727 342 37 31 2 0 0 0 0 1
# 598 246 33 29 2 0 0 0 0 1
# 740 308 45 33 1 0 0 0 2 1
with open(gtfile, "r") as gt:
while(True):
gt_con = gt.readline()[:-1]
if gt_con is None or gt_con == "":
break;
im_path = im_folder + "/" + gt_con;
print(im_path)
im_data = cv2.imread(im_path)
if im_data is None:
continue
# 可视化的部分
# cv2.imshow(im_path, im_data)
# cv2.waitKey(0)
numbox = int(gt.readline())
# 获取每一行人脸数据
bboxes = []
if numbox == 0: # numbox 为0 的情况处理
gt.readline()
else:
for i in range(numbox):
line = gt.readline()
infos = line.split(" ") # 用空格分割
# x y w h .....
bbox = (int(infos[0]), int(infos[1]), int(infos[2]), int(infos[3]))
# 绘制人脸框
# cv2.rectangle(im_data, (int(infos[0]), int(infos[1])),
# (int(infos[0]) + int(infos[2]), int(infos[1]) + int(infos[3])),
# color=(0, 0, 255), thickness=1)
bboxes.append(bbox) # 将一张图片的所有人脸数据加入bboxes
# cv2.imshow(im_path, im_data)
# cv2.waitKey(0)
filename = gt_con.replace("/", "_") # 将存储位置作为图片名称,斜杠转为下划线
fwrite.write(filename.split(".")[0] + "\n")
cv2.imwrite("{}/JPEGImages/{}".format(rootdir, filename), im_data)
xmlpath = "{}/Annotations/{}.xml".format(rootdir, filename.split(".")[0])
writexml(filename, im_data, bboxes, xmlpath)
fwrite.close()四、运行脚本
python3 widerface_roy.py 运行过程
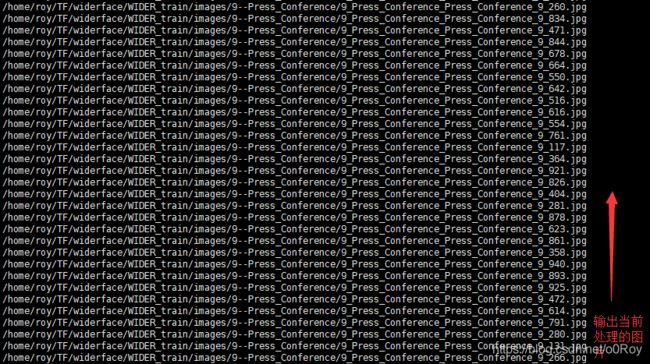
五、运行结果
ImageSets/Main/train.txt 图片文件名
ImageSets为图片原图
Annotations中为VOC的注解文件
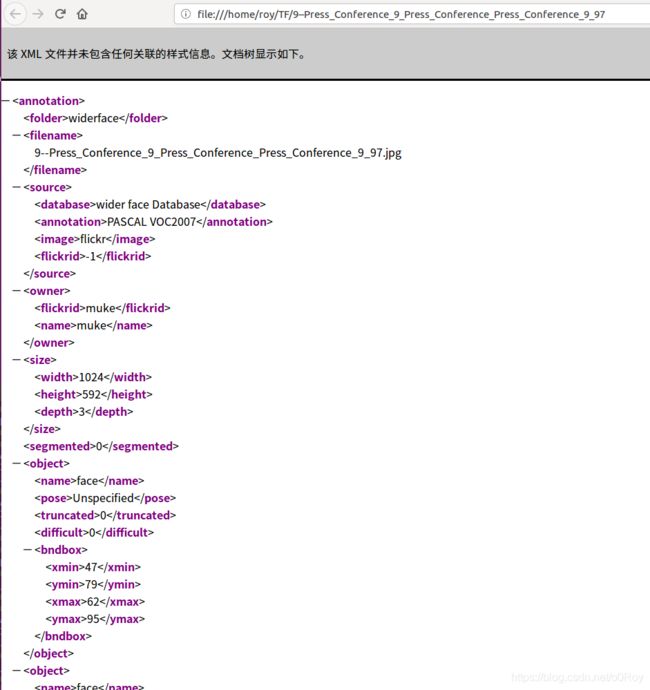
六、补充
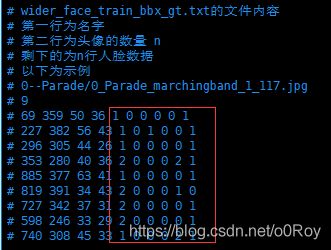
widerface前四位为x y w h 后六位为官网封面上的6个人脸属性
