PyTorch 分布式训练DDP 单机多卡快速上手
PyTorch 分布式训练DDP 单机多卡快速上手
本文旨在帮助新人快速上手最有效的 PyTorch 单机多卡训练,对于 PyTorch 分布式训练的理论介绍、多方案对比,本文不做详细介绍,有兴趣的读者可参考:
[分布式训练] 单机多卡的正确打开方式:理论基础
当代研究生应当掌握的并行训练方法(单机多卡)
DP与DDP
我们知道 PyTorch 本身对于单机多卡提供了两种实现方式
- DataParallel(DP):Parameter Server模式,一张卡位reducer,实现也超级简单,一行代码。
- DistributedDataParallel(DDP):All-Reduce模式,本意是用来分布式训练,但是也可用于单机多卡。
DataParallel是基于Parameter server的算法,实现比较简单,只需在原单机单卡代码的基础上增加一行:
model = nn.DataParallel(model, device_ids=config.gpu_id)
但是其负载不均衡的问题比较严重,有时在模型较大的时候(比如bert-large),reducer的那张卡会多出3-4g的显存占用。
并且速度也比较慢:
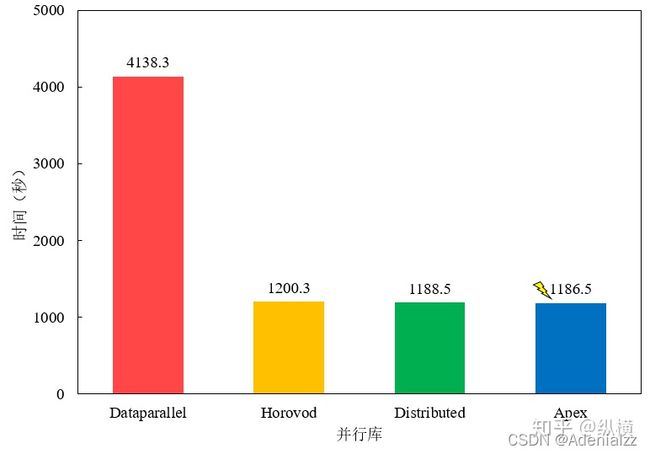
(图像来自:当代研究生应当掌握的并行训练方法(单机多卡)[][])
DistributedDataParallel
官方建议用新的DDP,采用all-reduce算法,本来设计主要是为了多机多卡使用,但是单机上也能用。
首先明确几个概念:
-
rank
多机多卡:代表某一台机器
单机多卡:代表某一块GPU
-
world_size
多机多卡:代表有几台机器
单机多卡:代表有几块GPU
-
local_rank
多机多卡:代表某一块GPU的编号
单机多卡:代表某一块GPU的编号
单机单卡训练代码
我们先给出一个单机单卡训练代码的 demo,简单地跑一下数据流。麻雀虽小,五脏俱全。这个 demo 包含了我们平时深度学习训练过程中的完整步骤。包括模型、数据集的定义与实例化,损失函数,优化器的定义,梯度清零、梯度反传,优化器迭代更新以及训练日志的打印。
接下来我们将会使用 PyTorch 提供的 DistributedDataParallel 把这个单机单卡的训练过程改装为单机多卡并行训练。
import torch
import torch.nn as nn
from torch.optim import SGD
from torch.autograd import Variable
from torch.utils.data import Dataset, DataLoader
import os
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--gpu_id', type=str, default='0,2')
parser.add_argument('--batchSize', type=int, default=32)
parser.add_argument('--epochs', type=int, default=5)
parser.add_argument('--dataset-size', type=int, default=128)
parser.add_argument('--num-classes', type=int, default=10)
config = parser.parse_args()
os.environ['CUDA_VISIBLE_DEVICES'] = config.gpu_id
# 定义一个随机数据集,随机生成样本
class RandomDataset(Dataset):
def __init__(self, dataset_size, image_size=32):
images = torch.randn(dataset_size, 3, image_size, image_size)
labels = torch.zeros(dataset_size, dtype=int)
self.data = list(zip(images, labels))
def __getitem__(self, index):
return self.data[index]
def __len__(self):
return len(self.data)
# 定义模型,简单的一层卷积加一层全连接softmax
class Model(nn.Module):
def __init__(self, num_classes):
super(Model, self).__init__()
self.conv2d = nn.Conv2d(3, 16, 3)
self.fc = nn.Linear(30*30*16, num_classes)
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
batch_size = x.shape[0]
x = self.conv2d(x)
x = x.reshape(batch_size, -1)
x = self.fc(x)
out = self.softmax(x)
return out
# 实例化模型、数据集、加载器和优化器
model = Model(config.num_classes)
dataset = RandomDataset(config.dataset_size)
loader = DataLoader(dataset, batch_size=config.batchSize, shuffle=True)
loss_func = nn.CrossEntropyLoss()
if torch.cuda.is_available():
model.cuda()
optimizer = SGD(model.parameters(), lr=0.1, momentum=0.9)
# 若使用DP,仅需一行
# if torch.cuda.device_count > 1: model = nn.DataParallel(model)
# 我们不用DP,而将用DDP
# 开始训练
for epoch in range(config.epochs):
for step, (images, labels) in enumerate(loader):
if torch.cuda.is_available():
images = images.cuda()
labels = labels.cuda()
preds = model(images)
loss = loss_func(preds, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'Step: {step}, Loss: {loss.item()}')
print(f'Epoch {epoch} Finished !')
训练日志输出为:
Step: 0, Loss: 1.4611507654190063
Step: 1, Loss: 1.4611507654190063
...
Step: 7, Loss: 1.4611507654190063
Epoch 0 Finished !
...
修改代码
使用 PyTorch 提供的 DistributedDataParallel 将单机单卡的训练代码为单机多卡的并行训练代码需要以下几个步骤:
-
初始化
torch.distributed.init_process_group(backend="nccl") local_rank = torch.distributed.get_rank() torch.cuda.set_device(local_rank) device = torch.device("cuda", local_rank) -
设置模型并行
model=torch.nn.parallel.DistributedDataParallel(model) -
设置数据并行
from torch.utils.data.distributed import DistributedSampler sampler = DistributedSampler(dataset) # 这个sampler会自动分配数据到各个gpu上 loader = DataLoader(dataset, batch_size=batch_size, sampler=sampler)
在上面单机单卡的代码合适位置中增添这么几行即可。
DDP多卡训练的启动
另外需要注意的是,单机多卡的启动与平时的 python ddp_demo.py 也不一样,需要:
torchrun --nproc_per_node=2 ddp_demo.py --batchSize 64 --epochs 10
其中 --nproc_per_node 是我们要使用的显卡数量。argparse 的参数加在后面即可。
注意 --local_rank 不是由我们手动指定。
DDP多卡训练的日志输出
还有,由于 DDP 多卡训练是多进程进行的,每个进程都会打印一遍日志输出。即会出现类似这种输出:
Step: 0, Loss: 1.4611507654190063
Step: 0, Loss: 1.4611507654190063
Step: 1, Loss: 1.4611507654190063
Step: 1, Loss: 1.4611507654190063
...
Step: 7, Loss: 1.4611507654190063
Step: 7, Loss: 1.4611507654190063
Epoch 0 Finished !
Epoch 0 Finished !
...
因此在训练验证过程中的日志记录输出也要注意:
在启动器启动python脚本后,在执行过程中,启动器会将当前进程的 index 通过参数传递给 python,我们可以这样获得当前进程的 index:即通过命令行参数 --local_rank 来告诉我们当前进程使用的是哪个GPU,用于我们在每个进程中指定不同的device(也有其他的方式来获取当前进程)。进程可以简单理解为运行一个代码,分布式训练采用多GPU多进程的方式,即每个进程都要独立运行一份训练代码,由此,为每个GPU分配一个进程进行分布式训练。通常不需要在每个进程中都有日志或其他信息(模型权重等)的输出,即可以通过--local_rank来指定打印日志或其他信息(模型权重等)的进程。
查看当前设备
我们可以在训练循环里加上一行,来查看当前进程时在哪个GPU上进行计算的:
print(f"data: {images.device}, model: {next(model.parameters()).device}")
注意这里我们的 model.parameters() 实际上是 Python 中的一个生成器,因此,需要用 next() 方法来取得其中一个,查看其所在设备。
部分输出:
Epoch 0 Finished !
data: cuda:0, model: cuda:0
data: cuda:1, model: cuda:1
...
data: cuda:0, model: cuda:0
data: cuda:1, model: cuda:1
data: cuda:0, model: cuda:0
data: cuda:1, model: cuda:1
Epoch 1 Finished !
...
可以看到,在我们的DDP多进程单机多卡训练中,在两个设备上都会有训练数据和模型的分布,并且也都会打印出来。
附录:完整DDP训练代码
# ddp_demo.py
import torch
import torch.nn as nn
from torch.optim import SGD
from torch.autograd import Variable
from torch.utils.data import Dataset, DataLoader
from torch.utils.data.distributed import DistributedSample
import os
import argparse
# 定义一个随机数据集
class RandomDataset(Dataset):
def __init__(self, dataset_size, image_size=32):
images = torch.randn(dataset_size, 3, image_size, image_size)
labels = torch.zeros(dataset_size, dtype=int)
self.data = list(zip(images, labels))
def __getitem__(self, index):
return self.data[index]
def __len__(self):
return len(self.data)
# 定义模型
class Model(nn.Module):
def __init__(self, num_classes):
super(Model, self).__init__()
self.conv2d = nn.Conv2d(3, 16, 3)
self.fc = nn.Linear(30*30*16, num_classes)
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
batch_size = x.shape[0]
x = self.conv2d(x)
x = x.reshape(batch_size, -1)
x = self.fc(x)
out = self.softmax(x)
return out
parser = argparse.ArgumentParser()
parser.add_argument('--gpu_id', type=str, default='0,2')
parser.add_argument('--batchSize', type=int, default=64)
parser.add_argument('--epochs', type=int, default=5)
parser.add_argument('--dataset-size', type=int, default=1024)
parser.add_argument('--num-classes', type=int, default=10)
config = parser.parse_args()
os.environ['CUDA_VISIBLE_DEVICES'] = config.gpu_id
torch.distributed.init_process_group(backend="nccl")
local_rank = torch.distributed.get_rank()
torch.cuda.set_device(local_rank)
device = torch.device("cuda", local_rank)
# 实例化模型、数据集和加载器loader
model = Model(config.num_classes)
dataset = RandomDataset(config.dataset_size)
sampler = DistributedSampler(dataset) # 这个sampler会自动分配数据到各个gpu上
loader = DataLoader(dataset, batch_size=config.batchSize, sampler=sampler)
# loader = DataLoader(dataset, batch_size=config.batchSize, shuffle=True)
loss_func = nn.CrossEntropyLoss()
if torch.cuda.is_available():
model.cuda()
model = torch.nn.parallel.DistributedDataParallel(model)
optimizer = SGD(model.parameters(), lr=0.1, momentum=0.9)
# 开始训练
for epoch in range(config.epochs):
for step, (images, labels) in enumerate(loader):
if torch.cuda.is_available():
images = images.cuda()
labels = labels.cuda()
preds = model(images)
# print(f"data: {images.device}, model: {next(model.parameters()).device}")
loss = loss_func(preds, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'Step: {step}, Loss: {loss.item()}')
print(f'Epoch {epoch} Finished !')
启动训练(以两张卡为例):
torchrun --nproc_per_node=2 ddp_demo.py --batchSize 64 --epochs 10
Ref:
https://blog.csdn.net/weixin_44966641/article/details/121015241
https://zhuanlan.zhihu.com/p/98535650
https://zhuanlan.zhihu.com/p/384893917