YOLOv3 从零开始训练自己的数据集
第一部分:准备数据
1.1标注数据
我们在这里使用LabelImg进行数据标注。
LabelImg使用教程可以查看github上的官方的教程
conda install pyqt=5
conda install -c anaconda lxml
pyrcc5 -o libs/resources.py resources.qrc
python labelImg.py
得到标注后的数据
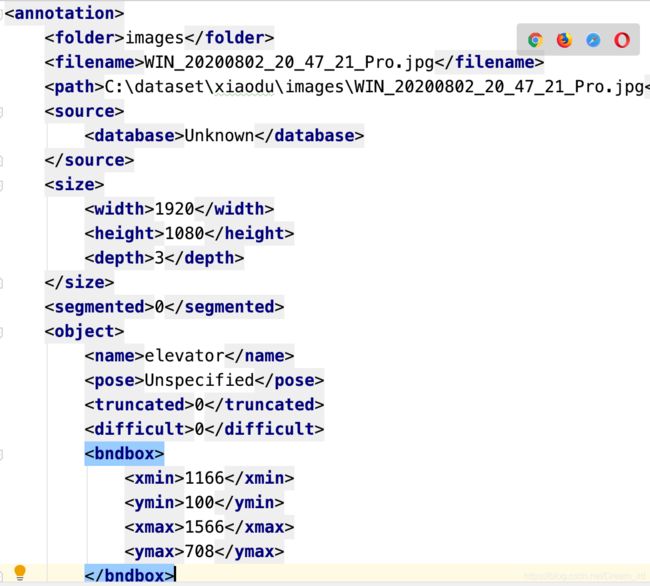
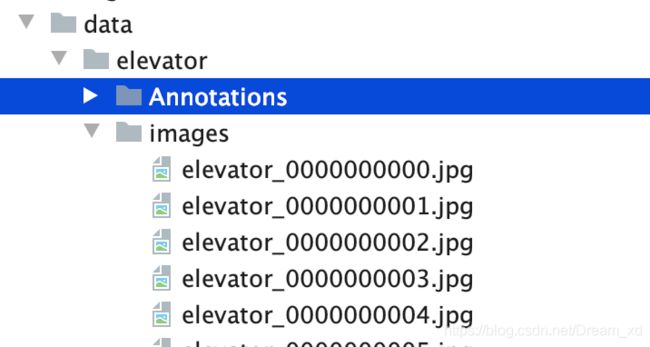
将标注的标签和数据放在data目录下的elevator中,我们这里是要做电梯面板的检测。
1.2 将数据分为训练集和测试集
我们在这里将我们的数据划分为训练集和测试集。
import os
import random
trainval_percent = 0.9
DATA_DIR = "/home/xxx/yolov3/data/elevator" #TODO换成自己的地址
xmlfilepath = os.path.join(DATA_DIR,'Annotations')
txtsavepath = os.path.join(DATA_DIR,'images')
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num*trainval_percent)
trainval = random.sample(list, tv)
ftrainval = open('/home/xxx/yolov3/data/elevator/trainval.txt', 'w')
ftrain = open('/home/xxx/yolov3/data/elevator/train.txt', 'w')
fval = open('/home/xxx/yolov3/data/elevator/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
ftrainval.write(name)
if i in trainval:
ftrain.write(name)
else:
fval.write(name)
ftrainval.close()
ftrain.close()
fval.close()
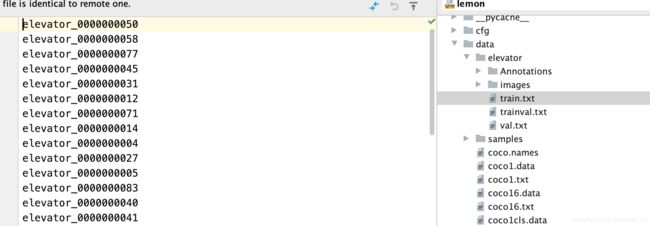
我们得到了上图所示的train.txt和val.txt,里面存储的是文件的名称。
生成labels标签
运行voc_label.py,得到labels的具体内容,这里存储的是train1.txt,val1.txt,与之前的区别是这里包含文件的具体路径,voc_label.py的代码如下所示。
# coding utf-8
import xml.etree.ElementTree as ET
import pickle
import os
sets = ['train', 'val']
classes = ["elevator"]
DATA_DIR = "/home/lemon/CaiRuJia/yolov3/data/elevator"
def convert(size,box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x*=dw
w*=dw
y*=dh
h*=dh
return (x,y,w,h)
def convert_annotation(image_id):
in_file = open(os.path.join(DATA_DIR,"Annotations/%s.xml"%image_id))
out_file = open(os.path.join(DATA_DIR,"labels/%s.txt"%image_id),"w")
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) ==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h),b)
out_file.write(str(cls_id)+" "+ " ".join(str(a) for a in bb) + "\n")
for image_set in sets:
image_ids = open(os.path.join(DATA_DIR,"%s.txt"%image_set)).read().strip().split()
list_file = open(os.path.join(DATA_DIR,"%s1.txt"%image_set),'w')
for image_id in image_ids:
list_file.write("data/elevator/images/%s.jpg\n"%image_id)
print(image_id)
convert_annotation(image_id)
list_file.close()
第二部分:训练yolov3
2.1、下载yolov3
在这里下载的是pytorch版本的yolov3
系统要求:Python>=3.7 and PyTorch>=1.4.
git clone https://github.com/ultralytics/yolov3
cd yolov3
pip install -U -r requirements.txt
2.2 配置
在data目录下新建elevator.data,配置训练的数据,内容如下
classes=1
train = /home/lemon/CaiRuJia/yolov3/data/elevator/train1.txt
valid = /home/lemon/CaiRuJia/yolov3/data/elevator/val1.txt
names = data/elevator.names
backup=backup/
eval=coco
在data目录下新建elevator.names,里面存放我们所要检测的类别。
elevator
2.3 网络结构配置
我们这里用的yolov3-tiny.cfg,我们需要更新cfg文件,修改类别相关信息,我们修改的主要是两个地方,一是classes=1,有n类就修改为n,这里只有电梯面板1类,第二个修改的地方是filters,filters=3*(5+n),n代表的是类别,3代表3gebounding box,5分别代表为,
[convolutional]
size=1
stride=1
pad=1
filters=18
activation=linear
[yolo]
mask = 3,4,5
anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319
classes=1
num=6
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1
2.4 获取官网已经训练好的网络参数yolov3-tiny.weights
下载链接https://pjreddie.com/media/files/yolov3-tiny.weights,导入weights目录下,由于需要进行fine-tune,所以需要对yolov3-tiny.weights进行改造,因而需要下载官网的代码https://github.com/pjreddie/darknet,运行一下脚本,并将得到的yolov3-tiny.conv.15导入weights目录下,脚本如下
./darknet partial cfg/yolov3-tiny.cfg yolov3-tiny.weights yolov3-tiny.conv.15 15
2.5 训练模型
python train.py --data data/elevator.data --cfg cfg/yolov3-tiny-elevator.cfg --epochs 10 --weights yolov3-tiny.conv.15
最后一个是之前训练的参数。
参考
YOLOV3训练自己的数据集(PyTorch版本
pytorch版yolov3训练自己数据集
yolo partial提取已经训练好的网络中的部分权重