pandas索引(分组运算,数据聚合,时间重采样,数据可视化,股票数据分析,时间事件日志)
文章目录
-
- pandas索引
- pandas分组运算
- 数据的聚合运算
- 数据IO
- 时间日期
- 时间重采样
- 数据可视化
- 实例:股票数据分析
- 实例:时间事件日志
pandas索引
1、创建s序列
import pandas as pd
import numpy as np
s = pd.Series(np.random.randn(5),index = list('abcde'))
s
'''
a -0.206894
b 1.042893
c -0.495746
d -0.178118
e 0.531067
dtype: float64
'''
2、s序列的索引
s.index
'''Index(['a', 'b', 'c', 'd', 'e'], dtype='object')'''
s.index.name = 'alpha'
s
'''
alpha
a -0.206894
b 1.042893
c -0.495746
d -0.178118
e 0.531067
dtype: float64
'''
3、创建df的DataFrame
df = pd.DataFrame(np.random.randn(4,3),columns = ['one','two','three'])
df

4、df的行索引,列索引,以及命名
df.index
'''
RangeIndex(start=0, stop=4, step=1)
'''
df.columns
'''
Index(['one', 'two', 'three'], dtype='object')
'''
df.index.name = 'row'
df.columns.name = 'col'
print(df)
'''
col a b c d
row
0 0 7 one 0
1 1 6 one 1
2 2 5 one 2
3 3 4 two 0
4 4 3 two 1
5 5 2 two 2
6 6 1 two 3
'''
5、创建多级索引
a =[['a','a','a','b','b','c','c'],[1,2,3,1,2,2,3]]
t = list(zip(*a))
t
'''
[('a', 1), ('a', 2), ('a', 3), ('b', 1), ('b', 2), ('c', 2), ('c', 3)]
'''
index = pd.MultiIndex.from_tuples(t,names = ['level1','level2'])
index
'''
MultiIndex(levels=[['a', 'b', 'c'], [1, 2, 3]],
codes=[[0, 0, 0, 1, 1, 2, 2], [0, 1, 2, 0, 1, 1, 2]],
names=['level1', 'level2'])
'''
s = pd.Series(np.random.rand(7),index = index)
s
'''
level1 level2
a 1 0.561636
2 0.907344
3 0.782276
b 1 0.674353
2 0.203832
c 2 0.591604
3 0.615422
dtype: float64
'''
df = pd.DataFrame(np.random.randint(1,10,(4,3)),
index = [['a','a','b','b'],[1,2,1,2]],
columns = [['one','one','two'],['blue','red','blue']])
df.index.names = ['row-1','row-2']
df.columns.names = ['col-1','col-2']
df
'''
col-1 one two
col-2 blue red blue
row-1 row-2
a 1 1 1 3
2 4 4 7
b 1 6 4 9
2 2 7 3
'''
type(df.loc['a'])
'''
pandas.core.frame.DataFrame
'''
df.loc['a',1]
'''
col-1 col-2
one blue 1
red 1
two blue 3
Name: (a, 1), dtype: int32
'''
#交换
df2 = df.swaplevel('row-1','row-2')
print(df2)
'''
col-1 one two
col-2 blue red blue
row-2 row-1
1 a 1 1 3
2 a 4 4 7
1 b 6 4 9
2 b 2 7 3
'''
#排序
df2.sort_index(1)
'''
col-1 one two
col-2 blue red blue
row-2 row-1
1 a 1 1 3
2 a 4 4 7
1 b 6 4 9
2 b 2 7 3
'''
#求和
print(df.sum(level = 0))
'''
col-1 one two
col-2 blue red blue
row-1
a 5 5 10
b 8 11 12
'''
df = pd.DataFrame({
'a':range(7),
'b':range (7,0,-1),
'c':['one','one','one','two','two','two','two'],
'd':[0,1,2,0,1,2,3]})
df
'''
a b c d
0 0 7 one 0
1 1 6 one 1
2 2 5 one 2
3 3 4 two 0
4 4 3 two 1
5 5 2 two 2
6 6 1 two 3
'''
print(df2.reset_index().sort_index('columns'))
'''
col-1 one row-1 row-2 two
col-2 blue red blue
0 1 1 a 1 3
1 4 4 a 2 7
2 6 4 b 1 9
3 2 7 b 2 3
'''
pandas分组运算
1、分组计算三部曲:
拆分、应用、合并
拆分:根据什么进行分组
应用:每个分组进行什么样的计算
合并:把每个分组的计算结果合并起来。
2、对Series,DataFrame的分组
import pandas as pd
import numpy as np
df = pd.DataFrame({'key1':['a','a','b','b','a'],
'key2':['one','two','one','two','one'],
'data1':np.random.randint(1,10,5),
'data2':np.random.randint(1,10,5)})
print(df)
'''
key1 key2 data1 data2
0 a one 9 3
1 a two 3 8
2 b one 2 5
3 b two 3 4
4 a one 9 7
'''
对Series的分组
df['data1'].groupby(df['key1']).mean()
'''
key1
a 7.0
b 2.5
'''
#自己创建key
key = [1,2,1,1,2]
df['data1'].groupby(key).mean()
'''
1 4.666667
2 6.000000
'''
#自己创建的key可为多层列表(求和)
df['data1'].groupby([df['key1'],df['key2']]).sum()
'''
key1 key2
a one 18
two 3
b one 2
two 3
'''
#求个数
df['data1'].groupby([df['key1'],df['key2']]).size()
key1 key2
a one 2
two 1
b one 1
two 1
Name: data1, dtype: int64
#key1,key2分组求和转化成DataFrame
mean = df.groupby(['key1','key2']).sum()['data1']
mean
'''
key1 key2
a one 18
two 3
b one 2
two 3
'''
print(mean.unstack())
'''
key2 one two
key1
a 18 3
b 2 3
'''
#for迭代
for name,group in df.groupby('key1'):
print (name)
print (group)
'''
a
key1 key2 data1 data2
0 a one 9 3
1 a two 3 8
4 a one 9 7
b
key1 key2 data1 data2
2 b one 2 5
3 b two 3 4
'''
#转化成字典
dict(list(df.groupby('key1')))
'''
{'a': key1 key2 data1 data2
0 a one 9 3
1 a two 3 8
4 a one 9 7, 'b': key1 key2 data1 data2
2 b one 2 5
3 b two 3 4}
'''
#每一列的数据类型
df.dtypes
'''
key1 object
key2 object
data1 int32
data2 int32
'''
#根据dtypes按列分组
df.groupby(df.dtypes,axis = 1).sum()
'''
int32
0 27
1 19
2 26
3 24
4 24
'''
3、通过函数进行分组
df = pd.DataFrame(np.random.randint(1,10,(5,5)),
columns = ['a','b','c','d','e'],
index = ['Alice','Bob','Candy','Dark','Emily'])
df.ix[1,1:3] = np.NaN
df
'''
a b c d e
Alice 6 3.0 3.0 9 3
Bob 7 NaN NaN 2 3
Candy 9 6.0 3.0 7 8
Dark 3 9.0 9.0 3 7
Emily 3 5.0 6.0 3 3
'''
mapping = {'a':'red','b':'red','c':'blue','d':'orange','e':'blue'}
grouped = df.groupby(mapping,axis = 1)
grouped.sum()
'''
blue orange red
Alice 3.0 6.0 7.0
Bob 2.0 7.0 8.0
Candy 6.0 9.0 4.0
Dark 5.0 8.0 8.0
Emily 8.0 3.0 7.0
'''
grouped.size()
'''
blue 2
orange 1
red 2
'''
grouped.count()
'''
blue orange red
Alice 2 1 2
Bob 1 1 1
Candy 2 1 2
Dark 2 1 2
Emily 2 1 2
'''
通过索引级别进行分组(多级索引分组)
df = pd.DataFrame(np.random.randint(1,10,(5,5)),
columns = ['a','b','c','d','e'],
index = ['Alice','Bob','Candy','Dark','Emily'])
'''
a b c d e
Alice 1 8 6 6 3
Bob 6 3 8 6 1
Candy 7 7 5 6 5
Dark 9 5 2 5 5
Emily 9 8 7 3 7
'''
def _group_key(idx):
print(idx)
return len(idx)
df.groupby(_group_key).size()
'''
Alice
Bob
Candy
Dark
Emily
Out[32]:
3 1
4 1
5 3
'''
print(df.groupby(len).sum())
'''
a b c d e
3 6 3 8 6 1
4 9 5 2 5 5
5 17 23 18 15 15
'''
columns = pd.MultiIndex.from_arrays([['China','USA','China','USA','China'],
['A','A','B','C','B']],names = ['country','index'])
df = pd.DataFrame(np.random.randint(1,10,(5,5)),columns = columns)
df
'''
a b c d e
Alice 1 8 6 6 3
Bob 6 3 8 6 1
Candy 7 7 5 6 5
Dark 9 5 2 5 5
Emily 9 8 7 3 7
'''
print(df.groupby(level = 'country',axis = 1).sum())
'''
country China USA
0 9 9
1 22 9
2 10 4
3 19 7
4 20 11
'''
print(df.groupby(level = 'index',axis=1).sum())
'''
index A B C
0 4 7 7
1 14 13 4
2 4 8 2
3 9 11 6
4 11 11 9
'''
数据的聚合运算
1、内置聚合函数
df = pd.DataFrame({'key1':['a','a','b','b','a'],
'key2':['one','two','one','two','one'],
'data1':np.random.randint(1,10,5),
'data2':np.random.randint(1,10,5)})
print(df)
#根据key1分组求各类函数计算
df.groupby('key1').describe() #max(),mean(),min(),sum()

2、自定义聚合函数agg
grouped = df.groupby('key1')
def peek_range(s):
print(type(s))
return s.max()-s.min()
grouped.agg(peek_range)
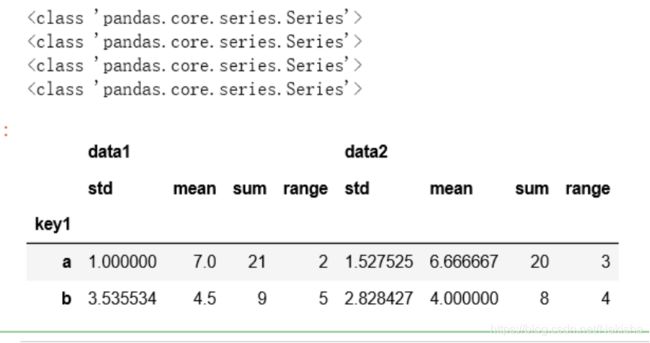
结果如下:

grouped.agg(['std','mean','sum',('range',peek_range)])
结果如下:
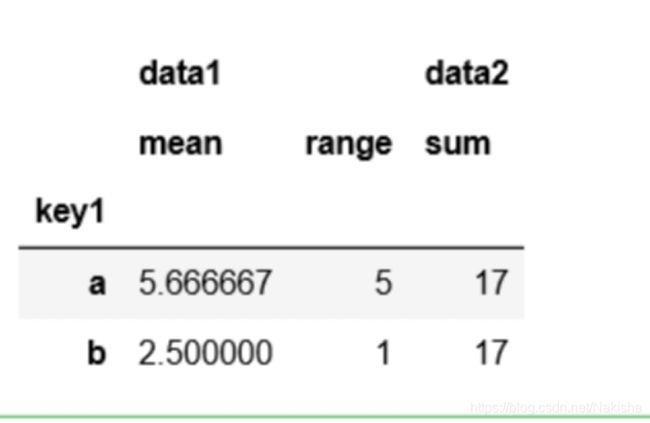
d ={'data1':['mean',('range',peek_range)],
'data2':'sum'}
grouped.agg(d)
结果如下:
#不把key1当做索引
grouped.agg(d).reset_index()
df.groupby('key1',as_index = False).agg(d)
3、不同的列应用不同聚合函数
#新加两列(方法一)
df = pd.DataFrame({'key1':['a','a','b','b','a'],
'key2':['one','two','one','two','one'],
'data1':np.random.randint(1,10,5),
'data2':np.random.randint(1,10,5)})
df
k1_mean = df.groupby('key1').mean().add_prefix('mean_')
k1_mean
pd.merge(df,k1_mean,left_on = 'key1',right_index=True)
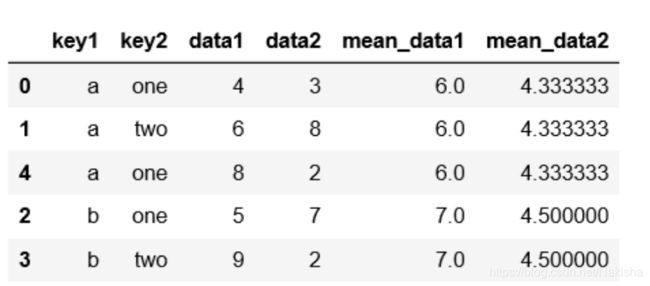
#方法二
k1_mean = df.groupby('key1').transform(np.mean).add_prefix('mean_')
k1_mean
df[k1_mean.columns] = k1_mean
df
结果如下:
用自定义函数调用transform(矩平方)
df = pd.DataFrame(np.random.randint(1,10,(5,5)),
columns = ['a','b','c','d','e'],
index = ['Alice','Bob','Candy','Dark','Emily'])
print(df)
def demean(s):
return s - s.mean()
key = ['one','one','two','one','two']
demeaned = df.groupby(key).transform(demean)
demeaned
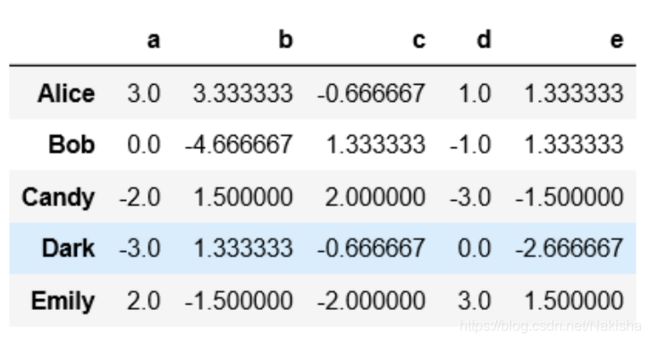
demeaned.groupby(key).mean()

聚合分组运算column方法
df = pd.DataFrame({'key1':['a','a','b','b','a','a','b','a','a','b'],
'key2':['one','two','one','two','one','one','two','one','one','two'],
'data1':np.random.randint(1,10,10),
'data2':np.random.randint(1,10,10)})
print(df)
def top(g,n = 2,column = 'data1'):
return g.sort_values(by = column,ascending = False)[:n]
top(df,n=3)
df.groupby('key1').apply(top,n=3,column = 'data2')
结果如下:

states = ['Ohio','New York','Vermont','Florida',
'Oregon','Nevada','Califrnia','Idaho']
group_key = ['East']*4+['West']*4
data = pd.Series(np.random.randn(8),index = states)
data[['Vermont','Nevada','Idaho']] = np.nan
data
'''
Ohio 1.138370
New York -2.095708
Vermont NaN
Florida 0.845250
Oregon 0.610225
Nevada NaN
Califrnia -0.173735
Idaho NaN
'''
data.groupby(group_key).mean()
'''
East -0.037362
West 0.218245
'''
data.groupby(group_key).apply(lambda g :g.fillna(g.mean()))
'''
Ohio 1.138370
New York -2.095708
Vermont -0.037362
Florida 0.845250
Oregon 0.610225
Nevada 0.218245
Califrnia -0.173735
Idaho 0.218245
'''
数据IO
1、索引:将一个列或者多个列读取出来构成DataFrame。其中涉及是否从文件中读取索引以及列名
2、类型推断和数据转换:包括用户自定义的转换以及缺失值标记
3、日期解析
4、迭代:针对大文件进行逐块迭代。
5、不规整数据问题:跳过一些行,或注释等
数据的导入导出
1、数据的读入:
df = pd.read_csv('cho4/ex5_out.csv')
df
2、数据的导出:
df.to_csv('cho4/ex5_out.csv',index = False,header = None,columns = ['b','c','message'],sep = '|')
时间日期
时间戳timestamp:固定的时刻
固定时期period
时间间隔interval:由起始时间和结束时间来表示。
1、python里的datetime
import pandas as pd
import numpy as np
from datetime import datetime
from datetime import timedelta
now = datetime.now()
now
'''
datetime.datetime(2020, 6, 8, 16, 8, 13, 972841)
'''
now.year,now.month,now.day
'''
(2020, 6, 8)
'''
#时间差
data1 = datetime(2020,4,20)
date2 = datetime(2020,4,16)
delta = data1 - date2
delta
'''
datetime.timedelta(days=4)
'''
delta.days
4
delta.total_seconds()
'''345600.0'''
date2+delta
'''datetime.datetime(2020, 4, 20, 0, 0)'''
date2+timedelta(4.5)
'''datetime.datetime(2020, 4, 20, 12, 0)
'''
date = datetime(2020,3,20,8,30)
date
'''datetime.datetime(2020, 3, 20, 8, 30)'''
str(date)
'''2020-03-20 08:30:00' '''
date.strftime("%y/%m/%d %H:%M:%S")
''
'20/03/20 08:30:00'
'''
datetime.strptime('2020-03-20 09:30','%Y-%m-%d %H:%M')
'''datetime.datetime(2020, 3, 20, 9, 30)
'''
2、时间序列
dates = [datetime(2020,3,1),datetime(2020,3,2),datetime(2020,3,3),datetime(2020,3,4)]
s= pd.Series(np.random.randn(4),index = dates)
s
2020-03-01 -0.929979
2020-03-02 -0.780578
2020-03-03 0.661065
2020-03-04 -0.795269
type(s.index)
pandas.core.indexes.datetimes.DatetimeInde
type(s.index[0])
pandas._libs.tslibs.timestamps.Timestamp
#生成时间戳
pd.date_range('20200320 16:32:38',periods = 10,normalize = True)
DatetimeIndex(['2020-03-20', '2020-03-21', '2020-03-22', '2020-03-23',
'2020-03-24', '2020-03-25', '2020-03-26', '2020-03-27',
'2020-03-28', '2020-03-29'],
dtype='datetime64[ns]', freq='D')
pd.date_range(start = '20200320',periods = 10,freq = 'M')
DatetimeIndex(['2020-03-31', '2020-04-30', '2020-05-31', '2020-06-30',
'2020-07-31', '2020-08-31', '2020-09-30', '2020-10-31',
'2020-11-30', '2020-12-31'],
dtype='datetime64[ns]', freq='M')
p = pd.Period(2010,freq = 'M')
p
Period('2010-01', 'M'
p + 2
Period('2010-03', 'M')
3、生成日期范围和时间频率及其转换
pd.period_range('2020-01','2020-12',freq = 'M')
PeriodIndex(['2020-01', '2020-02', '2020-03', '2020-04', '2020-05', '2020-06',
'2020-07', '2020-08', '2020-09', '2020-10', '2020-11', '2020-12'],
dtype='period[M]', freq='M')
pd.period_range('2020Q1',periods = 10,freq = 'Q')
PeriodIndex(['2020Q1', '2020Q2', '2020Q3', '2020Q4', '2021Q1', '2021Q2',
'2021Q3', '2021Q4', '2022Q1', '2022Q2'],
dtype='period[Q-DEC]', freq='Q-DEC')
a = pd.Period(2020)
a
Period('2020', 'A-DEC')
a.asfreq('M',how = 'start')
Period('2020-01', 'M')
p = pd.Period('2020-04',freq = 'M')
p
Period('2020-04', 'M')
p.asfreq('A-DEC')
Period('2020', 'A-DEC')
p.asfreq('A-MAR')
Period('2021', 'A-MAR')
p = pd.Period('2020Q4','Q-JAN')
p
Period('2020Q4', 'Q-JAN')
#转化后
p.asfreq('M',how = 'start'),p.asfreq('M',how = 'end')
(Period('2019-11', 'M'), Period('2020-01', 'M'))
#获取该季度倒数第二个工作日下午4点20分
(p.asfreq('B')-1).asfreq('T')+16*60+20
Period('2020-01-31 16:19', 'T')
时间重采样
1、降采样:高频率 ——低频率
2、升采样:低频率——高频率
3、其他采样:如每周三(W-WED)转换为每周五(W-FRI)
timestamp和Period相互转换
#时间戳的时间序列转换为基于时期的序列
s = pd.Series(np.random.randn(5),index = pd.date_range('2020-04-01',periods = 5,freq = 'M'))
s
s.to_period()
#时间序列转换为Period
ts = pd.Series(np.random.randn(5),index = pd.date_range('2020-12-29',periods = 5,freq = 'D'))
ts
pts = ts.to_period(freq = 'M')
pts
pts.index
PeriodIndex(['2020-12', '2020-12', '2020-12', '2021-01', '2021-01'], dtype='period[M]', freq='M')
#合并
pts.groupby(level = 0).sum()
#转换成时间戳
pts.to_timestamp(how = 'end')
重采样
ts = pd.Series(np.random.randint(0,50,60),index = pd.date_range('2020-04-25 09:30',periods = 60,freq = 'T'))
ts
#每5分钟的数据
ts.resample('5min',how = 'sum',label = 'right')
ts.resample('5min',how = 'ohlc')
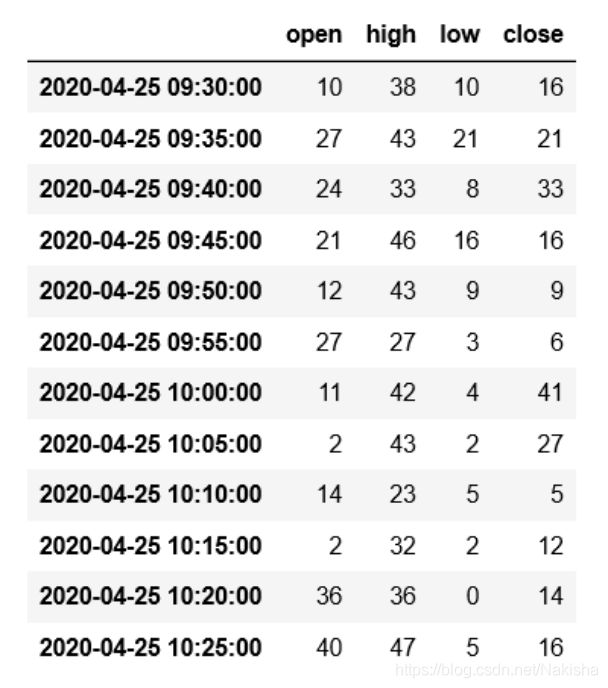
#通过groupby重采样
ts = pd.Series(np.random.randint(0,50,100),index = pd.date_range('2020-03-01 ',periods = 100,freq = 'D'))
ts
ts.groupby(lambda x:x.month).sum()
ts.groupby(ts.index.to_period('M')).sum()
df = pd.DataFrame(np.random.randint(1,50,2),index = pd.date_range('2020-04-22',periods = 2,freq = 'W-FRI'))
df
df.resample('D',fill_method = 'ffill',limit = 3)
df.resample('W-MON',fill_method = 'ffill')
#DataFrame重采样
df = pd.DataFrame(np.random.randint(2,30,(24,4)),
index = pd.period_range('2020-01','2021-12',freq = 'M'),
columns = list('ABCD'))
df
df.resample('A-MAR',how = 'sum')
数据可视化
1、线形图
%matplotlib inline
import pandas as pd
import numpy as np
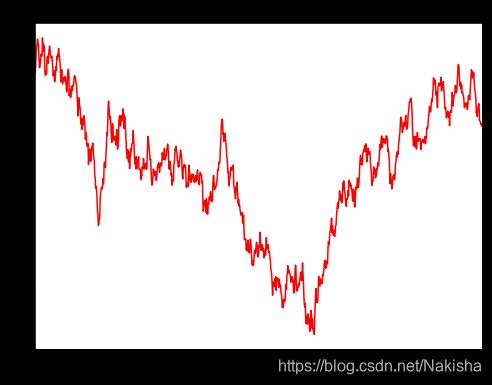
ts =pd.Series(np.random.randn(1000),index = pd.date_range('2000/1/1',periods = 1000))
ts = ts.cumsum()
ts.describe()
'''
count 1000.000000
mean -12.174947
std 10.107622
min -37.407623
25% -17.154878
50% -11.377877
75% -5.015530
max 7.568705
'''
ts.plot(title = 'cumsum',style = 'r-',figsize=(8,6));
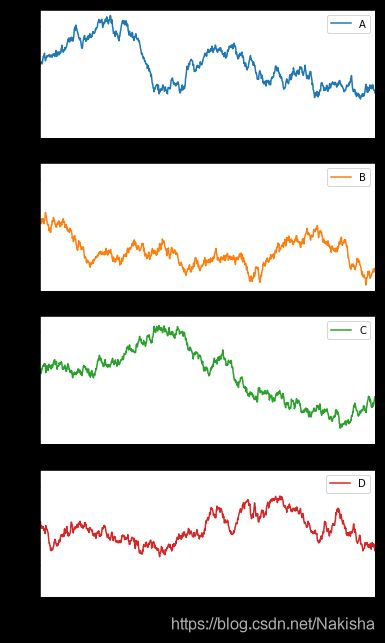
df = pd.DataFrame(np.random.randn(1000,4),index = ts.index,columns = list("ABCD"))
df = df.cumsum()
df.describe()
''' A B C D
count 1000.000000 1000.000000 1000.000000 1000.000000
mean 30.752918 -6.230675 5.665692 3.441014
std 13.410542 6.858038 16.830513 7.712553
min 2.941364 -24.438904 -20.542397 -9.713529
25% 18.600660 -10.927068 -9.766875 -3.046695
50% 30.680158 -7.450857 3.328111 1.749199
75% 40.536079 -1.211294 22.291788 10.100250
max 68.939141 11.776751 39.743450 21.136880
'''
df.plot(subplots = True,figsize =(6,12),sharey = True);
df['ID'] = np.arange(len(df))
print(df.describe())
'''
A B C D ID
count 1000.000000 1000.000000 1000.000000 1000.000000 1000.000000
mean 30.752918 -6.230675 5.665692 3.441014 499.500000
std 13.410542 6.858038 16.830513 7.712553 288.819436
min 2.941364 -24.438904 -20.542397 -9.713529 0.000000
25% 18.600660 -10.927068 -9.766875 -3.046695 249.750000
50% 30.680158 -7.450857 3.328111 1.749199 499.500000
75% 40.536079 -1.211294 22.291788 10.100250 749.250000
max 68.939141 11.776751 39.743450 21.136880 999.000000
'''
df.plot(x = 'ID',y = ['A','C'])
2、柱状图
df = pd.DataFrame(np.random.rand(10,4),columns = ['A','B','C','D'])
df
df.ix[0].plot(kind = 'bar')

df.plot.barh(stacked = True)

3、直方图
df = pd.DataFrame({'a':np.random.randn(1000)+1,'b':np.random.randn(1000),
'c':np.random.randn(1000)-1},columns = ['a','b','c'])
df
df['a'].hist(bins = 20)
df.plot.hist(subplots = True,sharex = True,sharey = True);
df.plot.hist(alpha = 0.3,stacked = True)

4、概率密度图
df['a'].plot.kde()

df.plot.kde()
5、散点图
df = pd.DataFrame(np.random.rand(10,4),columns = ['a','b','c','d'])
df
df.plot.scatter(x='a',y='c');

df = pd.DataFrame({'a':np.concatenate([np.random.normal(0,1,200),np.random.normal(6,1,200)]),
'b':np.concatenate([np.random.normal(10,2,200),np.random.normal(0,2,200)]),
'c':np.concatenate([np.random.normal(10,4,200),np.random.normal(0,4,200)])})
df.describe()
df.plot.scatter(x ='a',y='c')

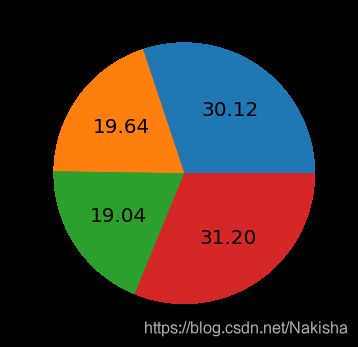
6、饼图
s = pd.Series(3 * np.random.rand(4),index = ['a','b','c','d'],name = 'series')
s
s.plot.pie(figsize =(6,6),labels = ["AA","BB","CC","DD"],autopct = "%0.2f",fontsize = 20)
实例:股票数据分析
股票数据获取
%matplotlib inline
import pandas as pd
import numpy as np
import os
import matplotlib.pyplot as plt
ls yahoo-data
data = pd.read_csv('yahoo-data/600690.csv',index_col = "Date",parse_dates = True)
data
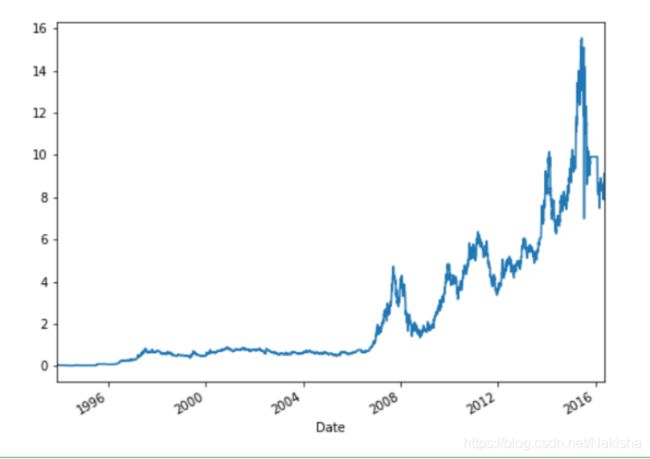
股票波动幅度分析
#除群数据
adj_price = data['Adj Close']
adj_price
#重采样
resampled = adj_price.resample('m',how = 'ohlc')
resampled
#波动幅度 = (最高价-最低价)/最低价
ripple = (resampled.high - resampled.low)/resampled.low
ripple
#取平均值
ripple.mean()
#画图
adj_price.plot(figsize =(8,6))
#最大波动幅度
(adj_price.max()-adj_price.min())/(adj_price.min())
'''
1112.2977809591985
'''
**年平均增长幅度 **
total_growth = adj_price.ix[0]/adj_price.ix[-1]
total_growth
old_date = adj_price.index[-1]
new_date =adj_price.index[0]
old_date.year,new_date.year
#复合增长率
total_growth**(1.0/(new_date.year - old_date.year))
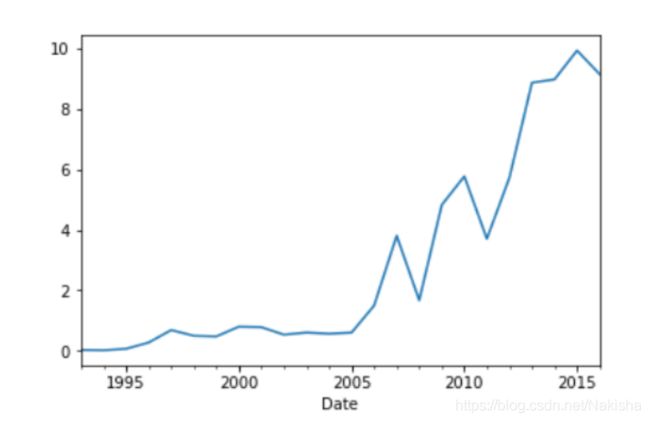
#分组
price_in_year = adj_price.to_period("A").groupby(level=0).first()
price_in_year
#画图
price_in_year.plot()
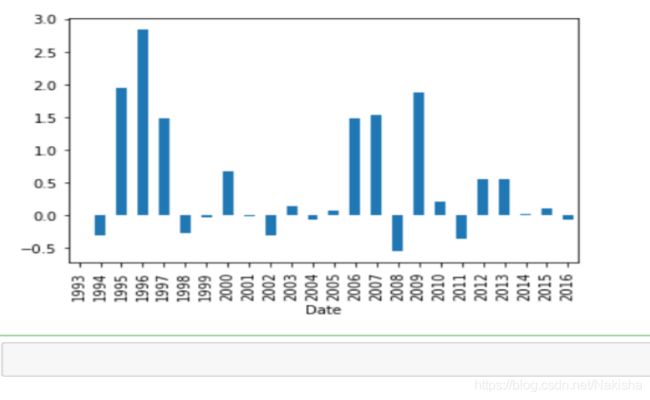
判断每年变化情况
diff = price_in_year.diff()
diff
#每年的增长率
rate = diff/(price_in_year - diff)
rate
#画图
rate.plot(kind = 'bar')
实例:时间事件日志
个人时间统计工具。要点:
使用 dida365.com 来作为 GTD 工具
使用特殊格式记录事件类别和花费的时间,练习数据下载
导出数据
分析数据
数据读取
%matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
# 定义解析函数
from matplotlib.pylab import mpl
mpl.rcParams['font.sans-serif'] = ['Arial Unicode MS'] #指定默认字体
mpl.rcParams['axes.unicode_minus'] = False #解决保存图像是负号‘-’显示为方块的问题
# 定义时间解析函数
def _parse_date(dsstr):
return pd.Timestamp(dsstr).date()
ata = pd.read_csv('data/dida365.csv', header=3, index_col='Due Date', parse_dates=True, date_parser=_date_parser)
ata
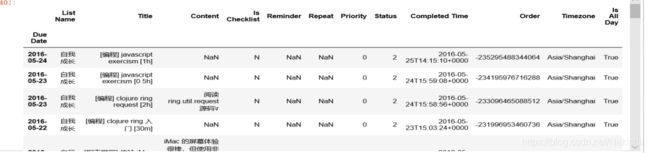
数据清洗
只关心己完成或己达成的事件,即 status != 0 的事件
只需要 List Name 和 Title 字段
df = data[data.Status != 0][['List Name','Title']]
df
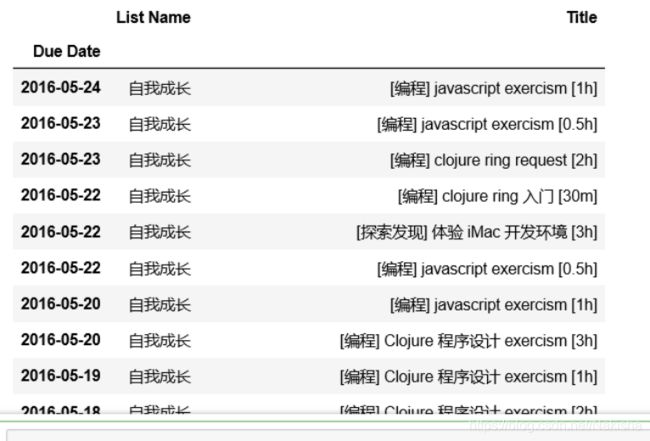
数据解析
解析事件类别和和花费的时间
import re
# 定义标签解析函数
def parse_tag(value):
m = re.match(r'^(\[(.*?)\])?.*$', value)
if m and m.group(2):
return m.group(2)
else:
return '其他'
# 定义时间解析函数
def parse_duration(value):
m = re.match(r'^.+?\[(.*?)([hm]?)\]$', value)
if m:
dur = 0
try:
dur = float(m.group(1))
except e:
print('parse duration error: \n%s' % e)
if m.group(2) == 'm':
dur = dur / 60.0
return dur
else:
return 0
titles = df['Title']
df['Tag'] = titles.map(parse_tag)
df['Duration'] = titles.map(parse_duration)
df.head()

df.count()
[Out:]
List Name 232
Title 232
Tag 232
Duration 232
dtype: int64
# 数据起始时间
start_date = df.index.min().date()
start_date
[Out:]
datetime.date(2015, 12, 2)
# 截止时间
end_date = df.index.max().date()
end_date
[Out:]
datetime.date(2016, 5, 24)
数据分析
时间总览
平均每天投资在自己身上的时间是多少?-> 全部时间 / 总天数
end_date - start_date
[Out:]
datetime.timedelta(174)
df['Duration'].sum()
[Out:]
482.19999999999999
df['Duration'].sum() / (end_date - start_date).days
2.7712643678160918
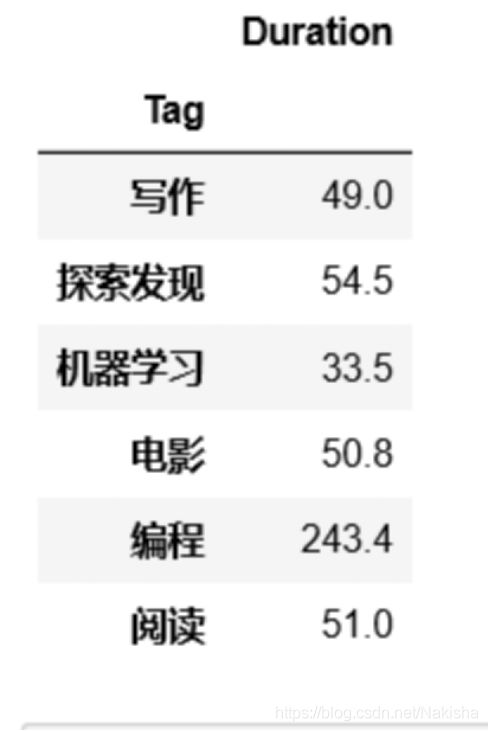
精力分配
tag_list = df.groupby(['Tag']).sum()
tag_list
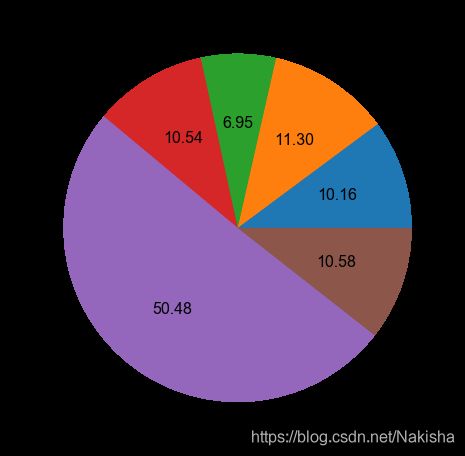
tag_list.Duration.plot(kind = 'pie',figsize = (8,8),fontsize = 16,autopct = '%1.02f')
专注力
长时间学习某项技能的能力
programming = df[df.Tag == '编程']
programming
programming.Duration.plot(kind = 'bar',figsize =(16,8))
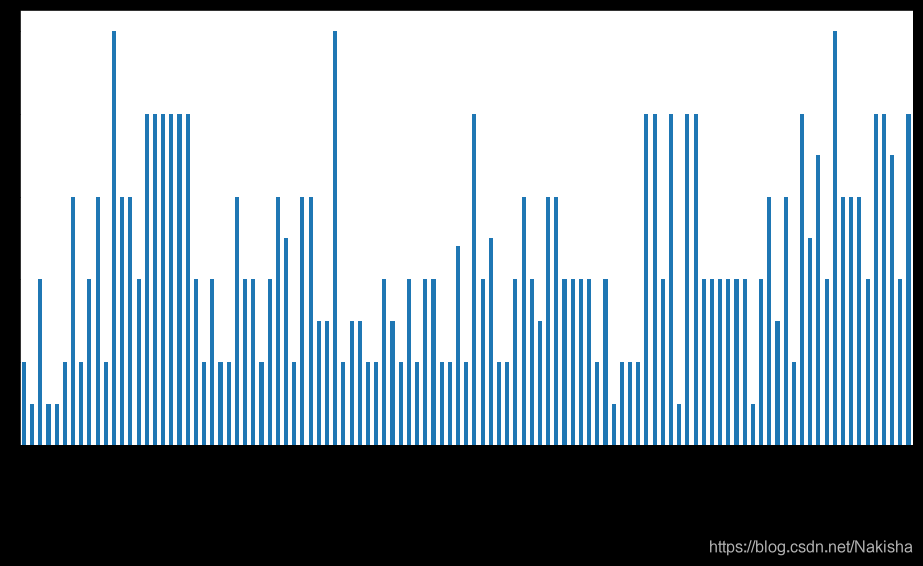
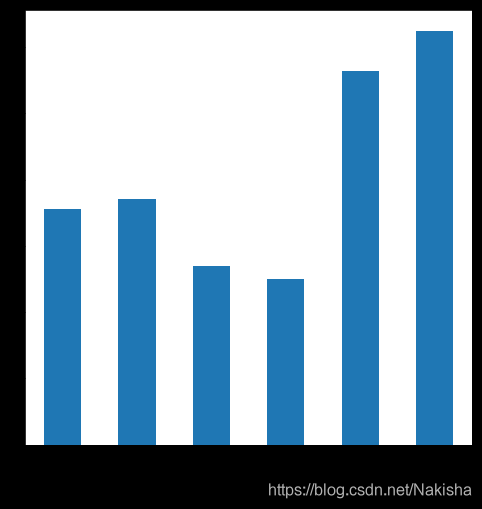
m = programming.resample('m',how ='sum').to_period(freq ='m')
m
m.Duration.plot(kind ='bar',figsize = (8,8))
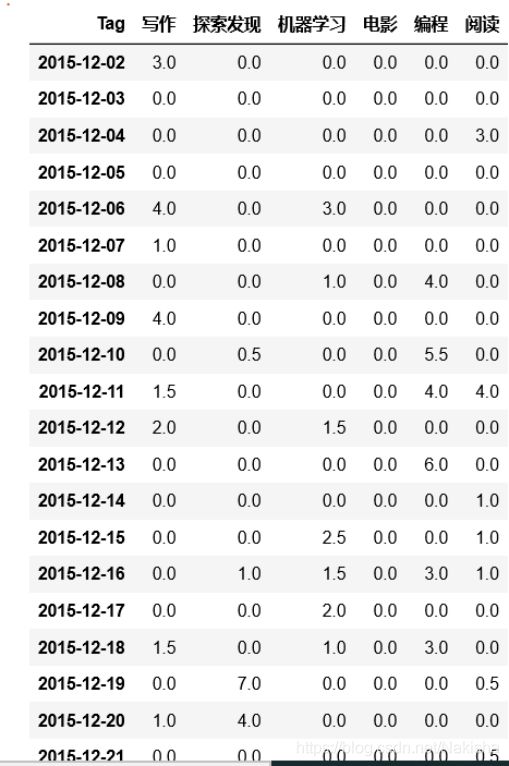
df.ix[-6:-1].pivot(columns ='Tag',values = 'Duration')
df2 = df.reset_index().groupby(['Due Date','Tag']).sum()
df2
df3 = df2.reset_index().pivot(index = 'Due Date',columns = 'Tag',values = 'Duration')
df3
df3.fillna(0)
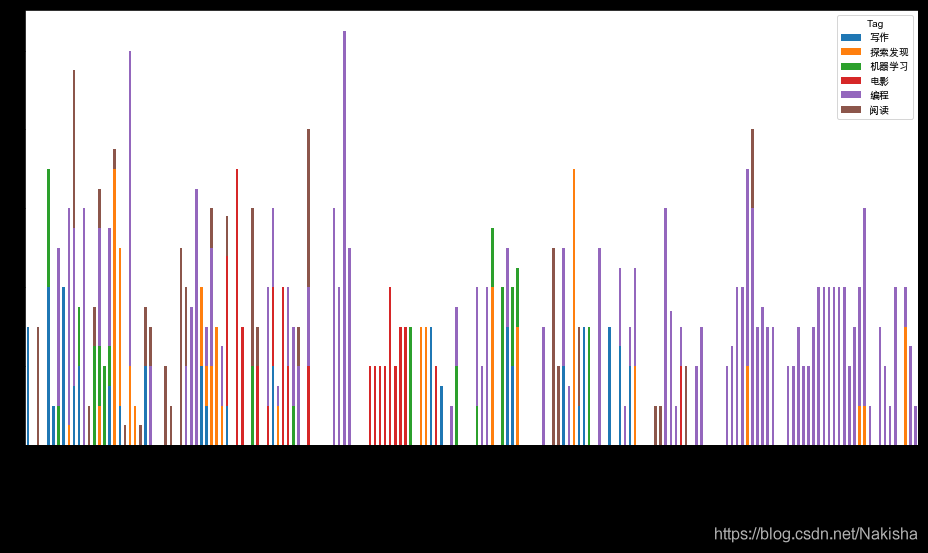
# 补足连续时间,可以看到哪些天没有在学习
df4 = df3.reindex(pd.date_range(start_date,end_date)).fillna(0)
df4
# 画出柱状图
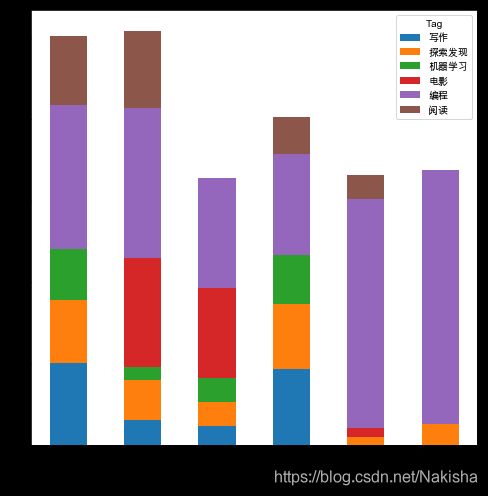
full_dates.plot(kind='bar', stacked=True, figsize=(16, 8))
df4.resample('m',how = 'sum').to_period(freq = 'm').plot(kind = 'bar',figsize = (8,8),stacked = True)