计算机视觉之卷积神经网络原理

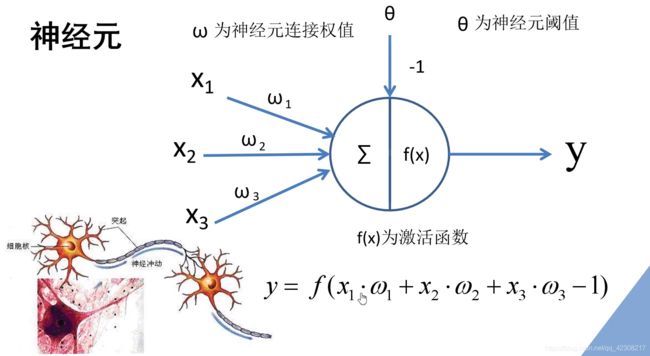
一个简单的神经元:左边有三个激励,分别将激励乘以对应的权重,接着对其求和再加上相应的偏置,最后通过激励函数就得到最终的输出y
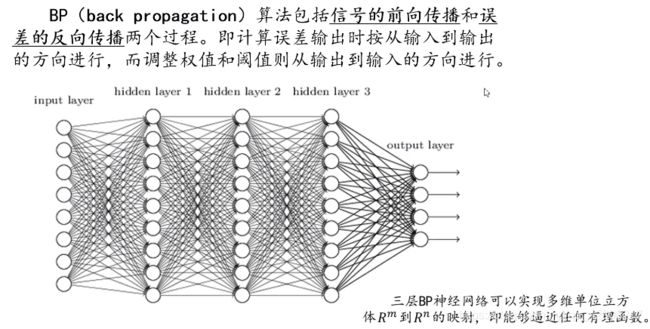
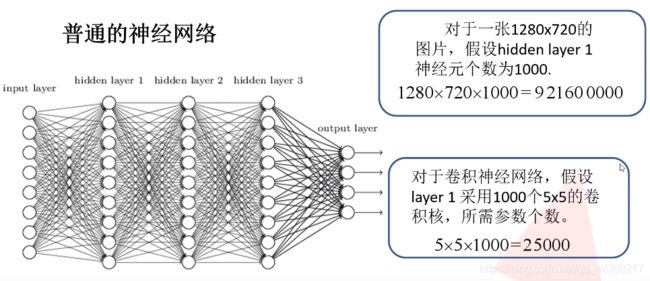
如果我们将神经元按列进行排列,列与列之间进行全连接,就得到一个BP神经网络:在BP神经网络的算法中,主要包括两个部分,信号的向前传播和误差反向传播。正常情况下从左到右会得到一个输出值,将输出值和所期望的值进行对比就能得到误差值,通过计算每个结点的偏导数就能得到每个结点的误差梯度,将损失值反向应用到误差梯度上就实现了误差的反向传播。
卷积的目的:进行图像的特征提取,其因为以滑动窗口的形式而具有局部感知的机制,且滑动的过程中卷积核不会变化,因此具有权值共享的机制。下图说明了权值共享机制的好处:
#必须要明白的地方:
一个图片做卷积,结果也可以理解为另一张图片,这里的卷积和数字信号处理中的卷积千差万别。在信号类教材中,做元素乘积求和之前将卷积核沿对角线翻转也就是卷起来(不是旋转),之后再进行乘积求和,但在计算机视觉中跳过了这个镜像操作,这样可以简化代码并使得神经网络正常工作,从技术上讲,这里实际做的是互相关而不是卷积,在深度学习文献中,按照惯例,这里叫做卷积操作。
!垂直检测核可以检测出垂直边缘,如果原始图像较小,检测出来的边缘较宽,但当图片较大时,可以很好的检测出来垂直边缘,水平同理。
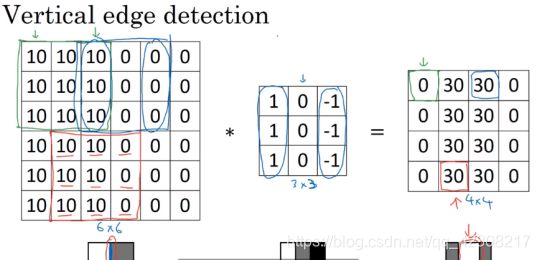
!在深度学习的领域里,要检测复杂图形的边缘,不一定要去选择研究者们给出的九个数字(卷积模板),而是把这九个数字当成九个参数,并利用反向传播算法,去理解这九个参数,通过数据反馈,让神经网络自动的去学习它们,神经网络可以学习一些如边缘这样低级的特征,可以检测书任何角度的边缘。这就是卷积神经网络要干的事情。
!卷积层的目的:参数共享(研究发现,提取图像一个特征时,一个卷积核可以适用于整幅图像,其可以在图片不同区域中使用相同的参数)和稀疏连接(其他卷积输出的像素值不会对某一个输出产生影响),这样可以用更少的参数进行训练,预防过拟合。
!Padding:n×n的图像、f×f的边缘检测卷积核卷积后可以得到(n-f+1)×(n-f+1)大小的图像,这有两个缺点:①每次做完卷积操作图像就会缩小,我们并不想让我们的图片特征缩小(比如100层网络,最后得到很小的特征无用)。②角落、边缘的像素在输出中采用较少,这意味着丢掉了图像边缘为位置的许多信息。解决办法:在卷积操作之前填充图像,习惯上可以用0去填充,如果p是填充外围像素的层数,输出图像大小也就变成了(n+2p-f+1)×(n+2p-f+1)。至于填充多少像素,通常有两个选择:Valid卷积和Same卷积,Valid卷积不填充像素,输出图像尺寸会减小;Same卷积意味着输入大小和输出大小是一样的。
注:在计算机视觉中f很多时候为奇数,这样计算一个像素点会很方便且填充的时候不会发生不对称填充。
!卷积步长:卷积核横向纵向移动的距离,计为s,输出图像尺寸变为:[(n+2p-f)/s]+1×[(n+2p-f)/s]+1 ,如果商不是一个整数,则向下取整。
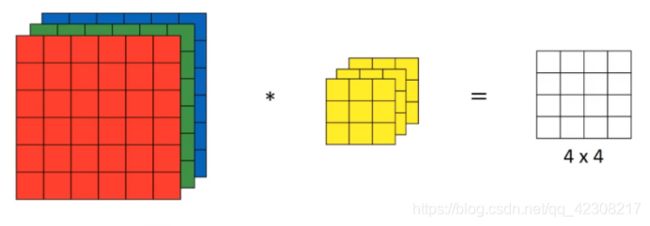
!三维卷积:不仅仅局限于灰度图像,也想检测RGB彩色的图像的特征,则要使用三维卷积核,这里的维数必须和图像的深度匹配(原因在后面)。我们把三位卷积核想象成为一个立方体,在原图像里做平移相乘相加操作,因此三维卷积后输出只有一个通道。如果只想检测一个通道的图像边缘,则可以将第一层核设为一个算子,后两层的核设为0,这样卷积核只会对红色通道有用,所以参数选择不同,就会得到不同的特征检测器。按照计算机视觉的惯例,卷积核的宽高可以和输入图像的宽高不同,但通道数必须一样,理论上我们只关注一个通道是可行的。
总结一下:1.卷积核的通道数与输入特征层的通道数必须相同
2.输出的特征矩阵通道数与卷积核个数相同
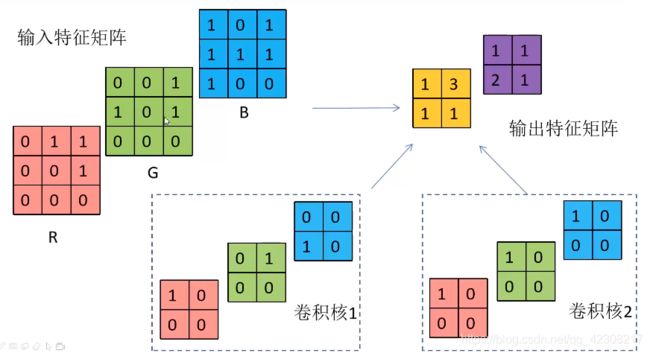
!如果要同时使用多个卷积核怎么办,也就是要检测各个方向的边缘:我们可以把不用的边缘检测卷积核卷积输出的图像堆叠在一起,因此总结以下:如果输入图像是n×n×a,卷积核设为f×f×a,则卷积输出的矩阵就是(n-f+1)×(n-f+1)×卷积核数量—这里步长为1且没有padding。所以输出的通道数等于要检测的特征数。
!如何构建卷积神经网络:不同卷积核和原图卷积后的输出会各自形成一个卷积神经网络层,通过python的广播机制给输出的矩阵每一个值增加相同的偏差,然后应用非线性激活函数,每个卷积后的矩阵输出不同的同尺寸矩阵,再重复之前的步骤,把这些矩阵堆叠起来得到一层的输出。卷积核用变量W1表示,在卷积的过程中,对卷积核的每一个数做乘法,其作用类似于W1a[0],再加上偏差b1,第二个卷积核中W1a[1]+b2,就是神经网络中的z=wx+b,最后所有的卷积核输出经过非线性函数后堆叠形成输出:a[1]。卷积核中每一个元素都是一个权重,一个卷积核共用一个偏差,利用这个可以计算参数个数。不论多大的图片,卷积核确定后参数参数个数就确定了,这就是卷积神经网络的一个特征:避免过拟合。这里不懂往下看图例。
这里公式不好打,直接截图了:


!实例搭建神经网络:为39×39×3的输入图像提取7×7×40个特征,即1960个特征,然后对该卷积层进行处理,将其展开为1960个单元,需要掌握的是:随着神经网络计算深度不断加深,高度和宽度会在一段时间内保持一致,然后随着网络深度的加深而逐渐减小,而信道数量在增加,在许多卷积神经网络中都有这个趋势。

!虽然利用卷积层就能很好的搭建网络,但大部分架构师都会添加池化层和全连接层,后两者的设计比卷积层更加容易,池化层的目的:对特征图进行稀疏处理,减少矩阵的运算量,提高计算速度,同时提高所提取特征的鲁棒性。池化有两种:最大池化和平均池化,后者用的较少。
!最大池化:输入可以看作是某些特征的集合,输出的每个元素都是其对应颜色区域的最大值,数字大意味着可能提取了某些特定特征,如果没有提取到某些特征,对应区域的最大值也还是很小,如右上区域,这里步长取2:
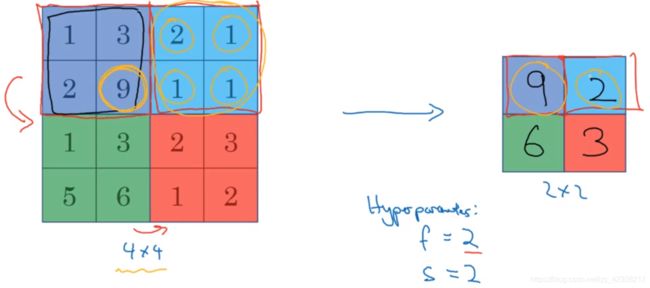
必须承认,人们使用最大池化的主要原因是:此法在很多实验中效果都很好,尽管上面的直观理解一直在被引用,最大池化的输出大小可以同样用公式[(n+2p-f)/s]+1 × [(n+2p-f)/s]+1 表示,其滤波器大小f和步长s被称为超级参数,常常设置为f=2,s=2,其效果相当于高度和宽度缩减一半,另外最大池化时,很少用到padding,即p=0. 除此之外,池化过程中没有需要学习的参数,其只是神经网络某一层的静态属性。
一般情况下,poolsize和stride相同。
拓展一下:输入是几通道的,输出就是几通道的,因为计算最大池化的方法就是分别对每个信道执行刚才的计算过程,每个通道都单独执行最大池化计算。
!平均池化:选取每个区域的平均值而不是最大值,但最大池化比平均池化更常用。需要说明的是:文献中常把池化层和卷积层各作为一层,但也有在统计网络层数时,只计算具有权重的层。
!全连接层:前面的卷积和池化相当于做特征工程,后面的全连接相当于做特征加权,卷积相当于全连接的有意弱化,按照局部视野的启发,把局部之外的弱影响直接抹为零影响,还做了一点强制,不同的局部所使用的参数居然一致。弱化使参数变少,节省计算量,又专攻局部不贪多求全;强制进一步减少参数少即是多。全连接层中的每个神经元与其前一层的所有神经元进行全连接,全连接层可以整合卷积层或者池化层中具有类别区分性的局部信息。最后一层全连接层的输出值被传递给一个输出,可以采用softmax逻辑回归(softmax regression)进行分类,该层也可称为 softmax层。通常,CNN的训练算法也多采用BP算法。
!对于卷积神经网络:池化层无参数;卷积层参数较少;大量的参数存在于全连接层;随着神经网络的加深,激活值数量逐渐变小,如果激活值数量下降太快,也会影响到网络的性能(下降太快,提取的特征也就变少了)。关于激活值的计算:二维卷积核大小f=5,则一个卷积核的激活值有5×5+1,6个卷积核的激活值数量为6×26.
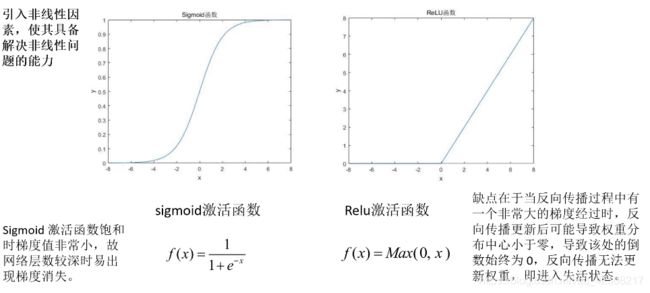
注:为什么要引入激活函数?
引入非线性因素,使网络具备解决非线性问题的能力。 ReLU失活后就无法再激活,因此不建议一开始就使用一个特别大的学习率进行学习,可能导致很多神经元失活。