六万字带你一次性速通python爬虫基础
目录
I. python基础篇
I.I python运行方式及pycharm配置
pip指令的使用
python的三种运行方式
pycharm的基础配置
I.II python注释及变量类型
python注释写法
python变量类型
I.III python类型查询与类型转换
python数据类型查询
python类型转换
I.IV python运算符
算术运算符
赋值运算符
比较运算符
逻辑运算符
I.V python读入与格式化输出
输出与格式化输出
读入
读入和输出组合小demo
I.VI python流程控制语句
if-elif-else流程控制
for循环流程控制
I.VII python字符串高级应用
I.VIII python列表、元组、字典高级
列表的高级使用
元组的高级使用
切片
字典的高级使用
I.IX python函数的使用介绍
函数的定义
函数的传参
函数的返回值
局部变量与全局变量
I.X python文件基础操作
文件的创建和写入
文件的读出
文件的序列化与反序列化
I.XI python异常处理介绍
II. python爬虫篇
II.I urllib库的使用介绍
初识urlliib库:爬取某网站的源代码
HttpResponse响应的六种常见的读取方法
urllib库之下载图片、音频、视频
urllib库之定制请求头
urllib库之GET请求的爬虫操作
urllib库之POST请求的处理
GET请求与POST请求处理的区别
urllib库之handler处理器
urllib库之代理ip与代理池
urllib库的异常处理
II.III requests库的学习
requests库的介绍与安装
requests库的基本语法
requests库的GET请求
requests库的POST请求
requests库的代理ip方法
requests库小结
II.IV 爬虫解析方法之xpath解析
xpath的安装
xpath的基本语法
II.V 爬虫解析方法之jsonpath解析
jsonpath的介绍
jsonpath的安装
jsonpath的基础语法介绍
II.VI 爬虫解析方法之bs4解析
bs4的介绍
bs4的安装
bs4的基本语法使用
bs4处理服务器响应文件
II.VII selenium库的介绍
selenium库的安装及相关浏览器工具的下载
selenium库的基本语法
selenium爬虫实战案例:获取网页源码
selenium无界面浏览器的学习
II.VIII scrapy框架的使用介绍
scrapy框架的工作原理介绍
scrapy框架的安装
用scrapy框架搭建并运行第一个项目
scrapy框架的项目结构
robots协议
scrapy框架的基本语法介绍
scrapy框架管道学习
scrapy框架的日志级别与推荐级别方案
II.IX 爬虫补充内容之Excel文件的读写
安装相关库
Excel文件的读写操作
完整的Excel操作示例代码
Excel读写常见报错解决方案
序言:
本文是我的原创博客专栏【python爬虫学习笔记】的精简整合版,尽管是精简版,仍然有6w字,所以大家可以先收藏;与专栏一致,本文的受众也是小白,并且保证小白通过本文能上手爬虫基础。
另,因为篇幅原因,如果有空的朋友也可以去看一看专栏,如果不想麻烦的本文的内容也是足够的!
最后是我的经典开场白:高产量博主,点个关注不迷路!
I. python基础篇
I.I python运行方式及pycharm配置
pip指令的使用
首先简单介绍一下pip指令是什么:
pip(Python Package Index)是一个以 Python 语言写成的软件包管理系統,使用 pip 可以非常方便的安装和管理 python 软件包。
pip常用的指令有:
1️⃣ 安装指令(-i及后面的网址可以加也可以不加,加上后改用国内的源)
pip install 名称 -i https://pypi.douban.com/simple2️⃣ 卸载指令
pip uninstall 名称 3️⃣ 查看已安装的文件
pip listpython的三种运行方式
1️⃣ 终端打代码运行:
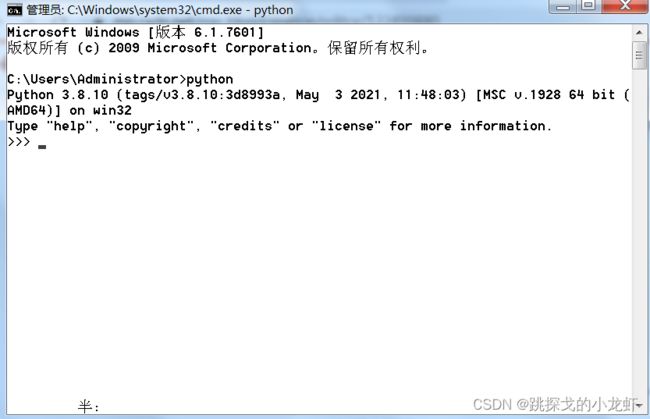
首先运行终端:快捷键Win + R,输入 cmd,弹出终端:

输入指令:
python运行后出现这样的提示和画面:
之后就可以正常运行python的代码,例如我们打印一个 跳探戈的小龙虾 字符串:
print('跳探戈的小龙虾')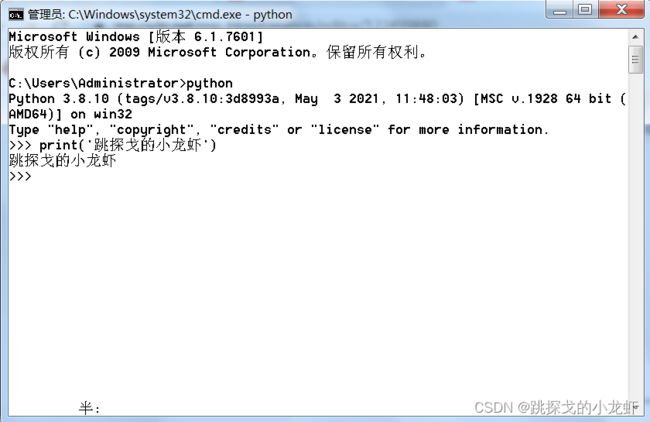
终端退出python的指令是:
exit()执行之后,我们就回到了正常的终端状态:
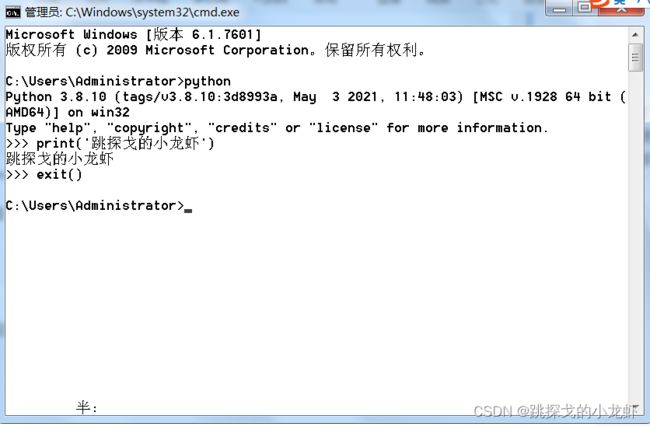
2️⃣ 终端运行py文件:
提前准备一个.py文件,之后我们输入指令:
python 文件路径即可运行。其中文件路径如果手打不方便,可以直接把文件拖动到终端,它会自动转成路径。
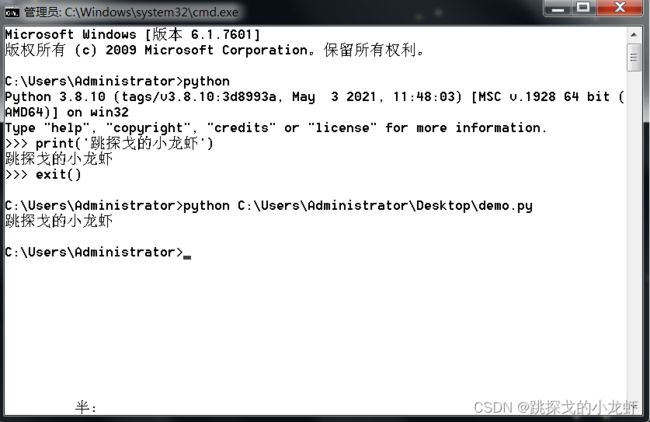
3️⃣ 使用IDE运行:
首先介绍一下IDE:
集成开发环境(IDE,Integrated Development Environment )是用于提供程序开发环境的应用程序,一般包括代码编辑器、编译器、调试器和图形用户界面等工具。集成了代码编写功能、分析功能、编译功能、调试功能等一体化的开发软件服务套。所有具备这一特性的软件或者软件套(组)都可以叫集成开发环境。
使用IDE才是最终开发采用的方法,因为我们的代码文件需要有可修改性。
一般来说pycharm是我们首选的IDE,也有其他的选择,这里我采用pycharm。
pycharm的基础配置
1️⃣ 设置字体字号:
选择 File->Settings
之后点击 Editor->Font,即可修改

2️⃣ 自动生成指定的注释:
像这样的一段注释,可以在pycharm里设置为每次新建文件默认生成:
# _*_ coding : utf-8 _*_
# @Time : 2022/1/14 15:27
# @Author : Lobster
# @File : pythonDemo2
# @Project : python基础首先,仍然是点击File->Settings:
之后,点击 Editor->File and Code Templates->Python Script,里面的内容会作为默认生成的注释:
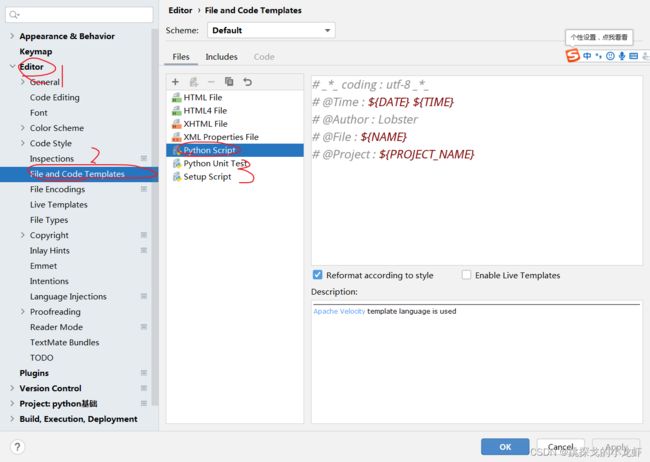
这里给一下常用的默认注释,大家修改一下AuthorName为自己的名字即可,其他的部分可直接复制。修改后新建的py文件都会生成这段注释。
# _*_ coding : utf-8 _*_
# @Time : ${DATE} ${TIME}
# @Author : AuthorName
# @File : ${NAME}
# @Project : ${PROJECT_NAME}I.II python注释及变量类型
python注释写法
在python中,分为单行注释和多行注释两种注释模式:
1️⃣ 单行注释:
单行注释在python中的语法是这样的:
# 单行注释2️⃣ 多行注释:
多行注释在python中的语法是这样的:
'''
多
行
注
释
'''python变量类型
在python中,有六种变量类型:
1️⃣ 数字(Numbers)
数字类型下,又细分为两种子数据类型:
️ 整型数据:
money = 100️ 浮点数:
money = 100.52️⃣ 布尔值(Boolean)
布尔型变量有两个取值,分别定义如下:(True和False一定要大写!)
a = True
b = False3️⃣ 字符串(String)
字符串即多个字符连接成的变量,在python中一个字符也是一个字符串,可以用单引号或双引号表示:
a = 'Python yyds'
b = "Python yyds"4️⃣ 列表(List)
列表也是python中的一个常见的数据类型,它的定义格式如下:
#list
name_list = ['A','B']
print(name_list)学过其他编程语言的朋友能够发现,它的格式和定义一个数组很相似。
5️⃣ 元组(Tuple)
元组在python爬虫中有很大的意义,同时它也与上面的列表类型有所不同,现阶段最大的不同在于它们的定义格式:
# tuple
age_tuple = (18,19,20,21)
print(age_tuple)6️⃣ 字典(Dict)
字典是爬虫技术中最重要的数据类型,是一个键值对的结构,它的定义如下:
# dict
# 格式:变量的名字 = {key1 : value1,key2 : value2}
dict_demo = {'key1' : 'value1','key2' : 'value2'}
print(dict_demo)上面的六种数据类型是python必须掌握的数据类型,也是服务于后面的爬虫技术的基础!
I.III python类型查询与类型转换
python数据类型查询
python,众所周知,是一个弱类语言,也即它在定义变量的时候,不会事先声明变量的类型,变量的类型真正被确定的地方是在变量的赋值处。
在python中,函数type()可以返回变量的数据类型,例如下面的代码示例:
# int
a = 1
print(a)
print(type(a))
# float
b = 1.2
print(b)
print(type(b))
# boolean
c = True
print(c)
print(type(c))
# string
d = '跳探戈的小龙虾'
print(d)
print(type(d))
# list
e = [1,2,3,4,5]
print(e)
print(type(e))
# tuple
f = (1,2,3,4,5)
print(f)
print(type(f))
# dict
g = {'name' : '张三'}
print(g)
print(type(g))通过type(),在变量赋值步骤被隐藏时,能够很快地找出变量的类型,这在爬虫技术中非常常用(爬取的数据进行类型查询)。
python类型转换
类型转换在python中也非常的常见,通常情况下类型转换分为这几个情况:
1️⃣ 其他类型转整型(int)
a = '123'
print(type(a))
b = int(a)
print(type(b))
print(b)
# float --> int
c = 1.63
print(type(c))
# float转成整数,会返回小数点前的整数,不涉及四舍五入
d = int(c)
print(type(d))
print(d)
# boolean --> int
# True 代表 1,False 代表 0
e = True
print(type(e))
f = int(e)
print(type(f))
print(f)
g = False
h = int(g)
print(h)这部分有两个注意事项:
️ 在float转int过程中,不涉及四舍五入,只是单单的把小数点后面的数据抹掉了(丢失精度)
️ 布尔型变量True转int后的值是 1,False转int后的值是 0
2️⃣ 其他类型转浮点数(float)
a = '12.34'
print(type(a))
b = float(a)
print(type(b))
print(b)
c = 666
print(type(c))
d = float(c)
print(type(d))
print(d)这部分本身没有需要注意的地方,但是要点名的是,第一句 a = '12.34' 的变量a,是不能直接由字符串转成整型int类型的,只能直接转浮点数float(即转int的字符串本身不能包含特殊字符)
3️⃣ 其他类型转字符串(string)
# int -> string
a = 80
print(type(a))
b = str(a)
print(type(b))
print(b)
# float -> string
c = 1.2
print(type(c))
d = str(c)
print(type(d))
print(d)
# boolean -> string
e = True
print(type(e))
f = str(e)
print(type(f))
print(f)要注意的是,布尔型转string的时候,不是转成0或1,而是转成字符串'False'或'True'。
4️⃣ 其他类型转布尔型(boolean)
# int -> boolean
a = 1
print(type(a))
b = bool(a)
print(type(b))
print(b)
# 非0的整数都是true,包括负整数和正整数
c = 0
print(type(c))
d = bool(c)
print(type(d))
print(d)
e = -1
print(type(e))
f = bool(e)
print(type(f))
print(f)
# float -> boolean
g = 1.0
print(type(g))
h = bool(g)
print(type(h))
print(h)
# 0.0相当于0,所以0.0是false,除了0.0的浮点数无论正负都是false
i = 0.0
print(type(i))
j = bool(i)
print(type(j))
print(j)
# string -> boolean
# 只要字符串有内容,都是True(内容甚至包括空格),但是没有内容的,就是False
k = '跳探戈的小龙虾'
print(type(k))
l = bool(k)
print(type(l))
print(l)
# 这个就是包含空格,运行结果是True
m = ' '
print(type(m))
n = bool(m)
print(type(n))
print(n)
# list -> boolean
# 只要列表有数据,就是True
o = ['a','b','c']
print(type(o))
p = bool(o)
print(type(o))
print(p)
# 空列表是False
q = []
print(type(q))
r = bool(q)
print(type(r))
print(r)
# tuple -> boolean
# 只要元组有数据,就是True
s = ('a','b')
print(type(s))
t = bool(s)
print(type(t))
print(t)
# 空元组是False
u = ()
print(type(u))
v = bool(u)
print(type(v))
print(v)
# dict -> boolean
# 只要字典有数据,就是True
w = {'a' : '1','b' : '2'}
print(type(w))
x = bool(w)
print(type(x))
print(x)
# 空字典是False
y = {'a' : '1','b' : '2'}
print(type(y))
z = bool(y)
print(type(z))
print(z)这部分的所有规定全部注释在代码中,可认真观察代码学习!
I.IV python运算符
算术运算符
算术运算符是python中最基础的一类运算符,表示的是运算的关系,示例代码如下:
# 算术运算符
a = 3
b = 2
# 加法
print(a + b)
# 减法
print(a - b)
# 乘法
print(a * b)
# 除法 默认是保留小数
print(a / b)
# 取整
print(a // b)
# 取余
print(a % b)
# 幂运算
print(a ** b)
# 字符串加法:字符串拼接
c = '123'
d = '456'
print(c + d)
# 在Python中,字符串做加法时,加号两端必须两端都是字符串,若只有一端是字符串,则会报错:
e = '123'
f = 456
#print(e + f) # 此行会报错
print(e + str(f)) # 这是出现这种情况的处理策略:先转成str再来
# 在python中,还支持字符串乘法:
g = 'hello world '
print(g * 3)
其中,想要强调两个细节:
1️⃣ 首先是两个字符串相加,相当于做了字符串拼接,不过这一点在其他编程语言中也是如此。
2️⃣ 其次是与其他编程语言不同,python不支持string类型与int类型直接做加法,这样做会报错!
赋值运算符
赋值运算符是我们常说的把一个值赋给变量,示例代码如下:
# 赋值运算符
a = 10
print(a)
# 多个变量赋同一个值
b = c = 20
print(b)
print(c)
# 多个变量同时赋值
d,e,f = 1,2,3
print(d)
print(e)
print(f)
# 复合赋值运算符
a = 1
a = a + 4
print(a)
a += 2
print(a)
a -= 2
print(a)
a *= 2
print(a)
a /= 2
print(a)
a //= 2
print(a)
a %= 2
print(a)
a **= 2
print(a)这部分有意思的地方在于python支持多个变量同时赋不同的值,但是变量间和值之间都要用逗号隔开!
比较运算符
比较运算符是表示两个变量之间关系的运算符,返回值是布尔值(boolean),示例代码如下:
# 比较运算符
a = 10
b = 10
print(a == b)
print(a != b)
print(a > b)
print(a < b)
print(a >= b)
print(a <= b)逻辑运算符
逻辑运算符在python中一共有三个,即 与、或、非(取反),示例代码如下:
# 逻辑运算符 and or not
# and 与 , 没错python中的and是手打一个and,不是||
print(10 > 20 and 10 > 11)
# or 或者
print(10 > 20 or 10 > 21)
# not 非 取反
print(not True)
print(not False)
a = 36关于逻辑运算符,python有别于其他编程语言的地方在于它是用英文单词表示逻辑关系,其他编程语言可能用 & | ! 这样的符号表示。另外关于逻辑运算符的短路示例代码如下:
# and 的性能优化:
# 左侧是False,因而右侧不再执行(短路and)
a < 10 and print('hello world')
# or的性能优化:
# 左侧是True,因而右侧不再执行(短路or)
a = 38
a > 37 or print('你好世界')短路的设定,优化了逻辑运算符的执行效率!
I.V python读入与格式化输出
输出与格式化输出
python中,普通的输出在前面的笔记中已经是经常使用了,因而不再介绍,示例代码如下:
# 普通输出
print('跳探戈的小龙虾')在python中,支持类似于C、C++的格式化输出,它的具体格式如下示例代码:
# 格式化输出:后续爬虫scrapy框架中会使用,将爬取的内容存入 Excel、MySQL、Redis
age = 20
name = 'Lobster'
# 格式化输出时,%s 代表字符串,%d 代表数字,其他的数据类型的格式化输出爬虫中一般不使用,
# 不做介绍。格式化输出的格式如下:
# 在需要放置输出变量的位置根据类型放置对应的符号,之后在print函数引号后面用一个百分号把
# 变量名放入即可,一个变量名时无需加括号,多个变量名用一个括号按顺序括起来,逗号隔开
print('昵称:%s,年龄:%d' % (name,age))读入
读入在python中通过调用input()函数实现,它的具体格式示例如下:
# python输入
nickname = input('请输入你的昵称')input()函数内的字符串会作为读入的提示语句显示在控制台。
读入和输出组合小demo
最后是实现一个简单的读入和格式化输出组合的小demo,功能是读入昵称后,回显昵称:
# python输入
nickname = input('请输入你的昵称')
# 输入内容结合格式化输出
print('昵称:%s' % nickname)这部分是关于python的格式化输出和读入的内容!
I.VI python流程控制语句
if-elif-else流程控制
python爬虫中最常用的第一种流程控制语句是if-elif-else控制语句。学过其他编程语言的朋友会觉得elif很陌生,其实elif就是其他编程语句中else if 的缩写而已。具体的示例代码如下:
# python流程控制
# if、else、elif的语法结构:if 条件:
# 四个空格缩进 具体执行内容(if的第二行一定要有缩进,否则会报错,四个空格是一个习惯性写法,不是四个也可运行但不规范)
# else:
# 四个空格缩进 具体执行内容(同缩进)
score = 80
if score >= 90:
print('优秀')
elif score >= 80:
print('良好')
elif score >= 70:
print('一般')
elif score >= 60:
print('及格')
else:
print('不及格')注意一下,python的if-elif-else结构中不含其他编程语言的大括号,因而要注意缩进要有并且要正确地缩进,否则逻辑会发生错误!
最后补一个if-elif-else与读入、输出结合的小demo,实现功能为读入成绩,返回打印成绩的等级:
# if、else流程控制小demo:读入分数,判断成绩等级,并输出结果
# 这里注意,input读入函数默认读入的类型是字符串,
# 而python本身不支持字符串与整型比较,因此跟整型比较时,要做一步转换,否则会报错:
score = int(input('输入成绩:'))
if score >= 90:
print('优秀')
elif score >= 80:
print('良好')
elif score >= 70:
print('一般')
elif score >= 60:
print('及格')
else:
print('不及格')这里注意一个小细节:print()函数读入的内容默认是字符串(string)类型的,我们要先做一步强制类型转换为整型(int),而后与int型数值进行比较,否则会报错。(python不支持int和string直接比较!)
for循环流程控制
第二类爬虫中常用的是for循环流程控制语句。它的基本格式如下:
# python流程控制
# for循环格式:
# for 变量 in 要遍历的数据:
# 方法体
s = 'china'
# 在字符串类型遍历时,i代表了字符串中的单个字符,s代表要遍历的数据
for i in s:
print(i)for循环通常结合range()函数一起使用,它的格式如下:
# range(n),它是一个左闭右开区间
# range方法的结果:一个可以遍历的对象,
# 如果里面是一个数字,会从0到这个数字-1
for i in range(5):
print(i) # 输出:0 1 2 3 4
# 如果里面有两个数字,那么有:
# 其中第一个代表起始数字,第二个代表末尾数字,返回这其中的数字
for i in range(1,5):
print(i) # 输出:1 2 3 4
# 如果里面有三个数字,前两个是起始数字和末尾数字,
# 最后一个数字代表间隔值或步长
for i in range(1,10,3):
print(i) # 输出:1 4 7 注意没有10,因为是左闭右开区间以上三种是range()函数的三种传参的方式,我们通常结合range()函数对字典、元组、列表进行循环打印。另外要注意range()函数是左开右闭的一个范围!
最后附一个for循环结合列表的小demo,循环打印列表:
# for循环小demo,循环打印一个列表
a_list = ['J','L','T'];
for i in a_list:
print(i) # 这里的i代表了列表的每一项
I.VII python字符串高级应用
python中,字符串有很多内置的函数,详细见下面的示例:
# 字符串高级:字符串常见的函数
# 1.获取长度:len(),返回整型
s = 'Lobster'
print(len(s))
# 2.获取某个字符在字符串中第一次出现的位置索引值(区分大小写): s.find(''),返回整型
print(s.find('L'))
# 3.判断是否以某个字符开头、结尾:s.startswith(''),s.endswith(''),返回布尔值
print(s.startswith('O'))
print(s.endswith('r'))
# 4.查找某个字符的个数:s.count('')
print(s.count('o'))
# 5.替换某个字符:s.replace('','')
print(s.replace('L','l'))
# 6.切割字符串:s.split(''),意思是以传入的字符为切割位把原字符串切开,
# 传入这个字符会变成空格
print(s.split('o'))
# 7.大小写转换:s.upper(),s.lower(),整个字符串转成大写或小写
print(s.upper())
print(s.lower())
# 8. 去掉字符串空格的函数:strip(),能把整个字符串所有空格去掉
s1 = ' Lobster '
print(len(s1))
print(len(s1.strip())) # 刚好是Lobster的长度7
# 9. join()函数,了解即可,是把一个字符串插入
# 到另一个字符串的每一位的后面,而不是简单的拼接,不是很常用:
s2 = 'aaaaaa'
s3 = 'bb'
print(s3.join(s2)) # 输出:abbabbabbabbabba这上面最后一种函数,意义不是很大,不需要太关心,感兴趣的可以跑一跑代码感受一下,其他的八种函数,需要掌握!
I.VIII python列表、元组、字典高级
列表的高级使用
对于列表来说,它的高级使用将从 增删改查 四个角度进行介绍,下面的示例代码:
# 列表高级:添加
# 1. append 追加,在列表的最后一位添加一个对象/数据
food_list = ['apple', 'banana']
print(food_list)
food_list.append('cock')
print(food_list)
# 2. insert 插入,两个参数,第一个参数代表想要插入的下标位置,
# 第二个参数代表你要插入的对象/数据
char_list = ['a','c','d']
print(char_list)
char_list.insert(1,'b')
print(char_list) # a b c d
# 3. extend 继承,传入的是一个列表,把传入的列表整个插入到
# 调用extend()函数的列表的末尾:
num_list = [1,2,3]
num_list2 = [4,5,6]
num_list.extend(num_list2)
print(num_list)
# 列表高级:修改
# 将列表中的元素的值修改
# 实现的方法类似于其他编程语言中给数组某一位赋一个新的值覆盖旧值:
city_list = ['Beijing','Shanghai','Shenzhen','Henan']
print(city_list)
# 假设想要修改第三位,Shenzhen,其索引值是2:
city_list[2] = 'Changchun'
print(city_list)
# 列表高级:查询
# 判断已知数据是否在列表内:
# 用关键字:in或者not in即可,in/not in的前面是待查询的元素,in/not in后面是一个列表
# 1. in代表待查询的元素在列表中:
# 存在时返回true,不存在返回false
food_list = ['apple', 'banana','cock']
food = 'apple'
if food in food_list:
print('存在')
else:
print('不存在')
# 2. not in也是查询的关键字,代表待查询的元素不在列表中:
# 不存在时返回true,存在时返回false
ball_list = ['Basketball','Football']
ball = 'pingpang'
if ball not in ball_list:
print('不存在')
else:
print('存在')
# 列表高级:删除
# 1. 根据下标删除列表中的元素
a_list = [1,2,3,4,5]
print(a_list)
# 例如要删除下标为2的元素3,使用关键字del 加列表 加对应索引:
del a_list[2]
# 2. 删除列表的最后一位元素,使用关键字
b_list = [1,2,3,4,5]
print(b_list)
# 使用pop()函数能够删除最后一位元素:
b_list.pop()
print(b_list)
# 3. 根据元素的值,删除元素
c_list = [1,2,3,4,5]
print(c_list)
# 例如想要删除元素值为3的元素,使用remove()函数即可,传入值:
c_list.remove(3)
print(c_list) # 打印结果:1 2 4 5,如果是索引,那应是 1 2 3 5要注意的是,对于增和删,有几种不同的模式,每种模式适用于不同的场景!
元组的高级使用
元组的高级使用,介绍的思路是从元组与列表的联系与区别入手,它们有如下联系与区别:
# 元组高级:与列表区别与联系:
# 首先,元组是圆括号(),列表是[]
a_tuple = (1,2,3,4)
a_list = [1,2,3,4]
# 其次,元组和列表访问某个元组的格式是一样的,
# 都是 变量名[index]
print(a_tuple[0])
print(a_list[0])
# 最后,元组的元素不可修改,列表的元素显然可以修改
# a_tuple[0] = 2 #这句话会报错,因为元组不可修改
a_list[0] = 2 # 但是列表支持修改
# 补充:当元组中只有一个元素的时候,它是一个整型数据
b_tuple = (5)
print(type(b_tuple)) # int
# 如果这时候只有一个元组,还想让它是元组类型,需要在数据后面加一个逗号:
c_tuple = (5,)
print(type(c_tuple)) # tuple由上述可以看出,元组更像其他编程语言中的 constant 变量,也即声明之后就不能再修改的变量类型。
切片
切片是一种经常运用于字符串、列表和元组中的技术方法,它的意思是将字符串、列表和元组中的元素切割成不同的片段,并把这些片段返回。下面的示例代码以字符串的切片为例,列表和元组的使用方法大同小异:
# 切片:适用于字符串、列表和元组,这里以字符串为例
# 列表和元组使用方法完全相同:
s = 'hello world'
# 1.在[]中直接写下标,此时可以看做切片,也可以看做对单个元素的访问:
print(s[4])
# 2.在[]中写起始位索引 : 终止位索引,
# 此时切片是从起始位到终止位的字符串,且 【左闭右开】
print(s[0 : 4])
# 3. 在[]中写 n :
# 此时表示从第n位索引对应元素开始,一直到最后一位
print(s[1 :])
# 4. 在[]中写 : n
# 此时表示从第0位索引对应元素开始,到第n位索引,且【左闭右开】
print(s[: 3])
# 5. 在[]中写 n : m : o
# 从下标为 n 的位置开始,到下标为 m 的位置结束,且【左闭右开】
# 步长是 o (每次增加的位置数),且【左闭右开】
print(s[0:5:2]) # hlo,代表索引 0 2 4字典的高级使用
字典的高级使用,和列表类似,思路是从字典的增删改查入手,并且增加了一项,那就是对字典的不同遍历方法,下面是五种操作的详细示例代码(增删改查+遍历):
# 字典高级
# 定义一个字典:
person = {'name' : '跳探戈的小龙虾', 'age' : 20}
# 字典高级:查询
# (1). 字典变量名['key'] 查询元素
print(person['name'])
print(person['age'])
# 当访问不存在的'key'值时,出现的情况是会报错:
# print(person['sex'] 会报错 key error
# (2). get()函数 查询元素
print(person.get('name'))
print(person.get('age'))
# 字典高级:修改
# 例如修改上例中 'name' 键的值为 '张三'
person['name'] = '张三'
print(person['name'])
# 字典高级:添加
# 例如添加一个新的 键值对:'sex' 'nan'
person['sex'] = 'nan'
# 添加的格式与修改相同,只是此时 键 key 是不存在的,
# 因此会新建该键值对,如果该键存在,那就是修改操作
# 字典高级:删除
# (1) del 关键字删除:删除字典中指定的某一个元素
del person['sex']
print(person)
# (2) del 关键字删除:删除整个字典,包括字典对象本身
del person
# print(person) # 这时打印会报错,因为person字典已经不存在了
# (3) clear 清空字典内容,但是保留字典对象
person = {'name' : '跳探戈的小龙虾', 'age' : 20}
person.clear()
print(person) # 此时打印的结果只有一个 {},因为内容已被清空!但不会报错
# 字典高级:遍历
# (1) 遍历字典的key
# 字典.keys() 方法,获取字典所有的key值,而后用
# for循环即可,用一个临时变量进行遍历
person = {'name' : '跳探戈的小龙虾', 'age' : 20}
for key in person.keys():
print(key)
# (2) 遍历字典的value
# 字典.values() 方法,获取字典所有的value值,而后用
# for循环即可,用一个临时变量进行遍历
for value in person.values():
print(value)
# (3) 遍历字典的key和value
# 字典.items() 方法,获取所有的key value键值对,
# 并且用两个临时变量通过for循环遍历
for key,value in person.items():
print(key,value)
# (4) 遍历字典的项/元素
# 仍然是字典.items() 方法,但是此时只用一个临时变量去循环遍历
# 即可获取字典的每一项,这与上一种的区别在于获取的
# 键值对会用一个()包围,即打印的结果是(key,value)
for item in person.items():
print(item)最后关于遍历的最后一种方式,也即遍历字典的项,这里稍作说明:
遍历字典的项,它和前一种遍历key和value很相似,区别在于遍历项的结果被包含进了括号里面,也即遍历的结果是:(key,value) 的形式,这更符合‘项’的定义。
I.IX python函数的使用介绍
函数的定义
在python中,为了减少代码块的重复性,与其它编程语言一样,也有函数的相关概念与实现方式,首先介绍python中函数的定义,它的格式是这样的:
# python 函数
# 定义函数
# 格式为:def 函数名():
# 四个空格 函数体
def f_1():
print('Hello,Function')
# 函数体前面的空格个数也可以不是4个,但是为了标准起见,尽量保持四个空格!
# 调用函数
# 格式为:函数名() 即可
f_1()函数定义的时候,要注意缩进的规范性,尽量按照统一标准,有四个空格或者一个tab键的缩进(用pycharm打完def关键字后,会车会自动生成四个空格的缩进,不需要手动敲四个空格)。调用时,与其他编程语言类似,也是直接放一个函数名()即可。
函数的传参
在python中,函数同样支持传参,只不过与其他编程语言不同的是传参是不包含类型的,这也是python的特色。函数传参的格式如下:
# 函数的参数
# 定义格式为:
# def 函数名(参数1,参数2,参数3...)
def sum(a,b):
c = a + b
print(c)
# 调用时,有两种传参方法:
# 1. 位置传参,即直接传递参数,按照函数定义参数的顺序传参
sum(1,9)
# 2. 关键字传参,即按照函数定义的参数名称进行传参
sum(b = 1, a = 9)第二种关键字传参的方式,实际开发中运用很少,了解即可。另外关于传参,对小白稍微解释一下:定义函数时,书写的参数叫做形参;调用函数时,书写的参数叫实参或传参。
函数的返回值
返回值这块,python的格式与其他编程语言也类似,区别仍然在于python没有类型,因而即使有返回值,在定义函数时也无需提前声明。它的具体格式如下:
# 函数的返回值
# 返回值的格式为:
# def 函数名():
# return 返回值
def sum(a,b):
c = a + b
return c局部变量与全局变量
在函数部分的最后,简单聊一下局部变量与全局变量,这部分仅面向小白,有其他语言基础的可以跳过。对于函数来说,在函数体内定义的变量称为局部变量,它的作用域仅限于函数体内,在函数体外该变量等价于不存在;在函数体外定义的变量称为全局变量,它的作用域是全局,也即既可以在函数体内使用,也可以在函数体外使用。下面是一个简单的demo演示:
# 局部变量和全局变量
# 局部变量:在函数的内部定义的变量,我们称为局部变量
# 特点:作用域范围是函数内部,在外部不可用
def f1():
a = 1
print(a)
# 在外部,就不能再次print(a),因为a只在函数f1()可用
# 全局变量:定义在函数外部的变量,我们称之为全局变量
# 特点:可以在函数的外部或内部使用
a = 1
print(a)
def f2():
print(a)
f2()以上是关于python函数的基础知识介绍。
I.X python文件基础操作
文件的创建和写入
python中,一个文件可以被创建和写入,它的示例代码如下:
# python文件操作
#
# 创建/打开一个文件:test.txt
# 格式为:open(文件的路径;文件的模式)
# 模式有:w 可写 r 可读 a 追加
fp = open('demo/test.txt','w')
# 文件的关闭
# 执行打开、读写操作后要及时关闭文件,释放内存!
fp.close()
# 文件的读写
# 向文件内写入内容:
# 格式为 文件对象.write('内容')
fp_w = open('demo/test1.txt', 'w')
fp_w.write('hello,world\n' * 5)
fp_w.close()
# 在w 写入模式下,每一次打开后,写入的位置都是开头,也即会覆盖之前的内容
# 在a 追加模式下,每一次会紧接着上一次写入的内容,不会覆盖:
fp_a = open('demo/test2.txt', 'a')
fp_a.write('hello\n' * 5)
fp_a.close()需要注意的是,当文件在路径下不存在的时候,运行'w'写入模式时会自动创建文件并定为写入模式;'a'追加模式下,我们才可以每一次接着前一次的结尾写入,否则'w'模式下每一次都会覆盖前一次写入的内容!
文件的读出
文件的读操作有很多不同的类型,它的示例代码如下:
# 读取文件的内容
# read函数是按每字节读取,效率较低
fp_r = open('demo/test2.txt', 'r')
content = fp_r.read()
print(content)
fp_r.close()
# readline函数是一行一行的读取,但是调用一次只能读取一行:
fp_l = open('demo/test2.txt','r')
line = fp_l.readline()
print(line)
fp_l.close()
# readlines函数也是按照行来读取,并且可以一次性把所有行都读取到,
# 并返回一个列表的形式:
fp_ls = open('demo/test2.txt','r')
lines = fp_ls.readlines()
print(lines)
fp_ls.close()
需要注意的是,当文件不存在时,运行'r'读出模式是不会新建文件的,反而会抛出异常,因此要注意先新建好文件再读出。
文件的序列化与反序列化
最后介绍一下序列化和反序列化,先介绍一下序列化和反序列化的定义:
序列化:将列表、元组、字典等对象转成有序的字符串类型数据。
反序列化:将字符串类型数据转回列表、元组、字典等对象
下面是具体操作的示例代码:
# 文件的序列化和反序列化
# 默认情况下,只能直接将字符串写入文件,列表、元组、字典等对象无法写入文件:
fp = open('demo/test3.txt','w')
fp.write('hello world')
fp.close()
name_list = ['张三','李四']
fp_1 = open('demo/test4.txt','w')
# fp_1.write(name_list) 这句话就会报错,因为无法直接向文件写入列表对象,
# 只能先进行序列化,而后写入
fp_1.close()
# 序列化:对象 - - - > 字节序列(json字符串)
# 序列化有两种方式:
# (1) dumps() 函数 法
# 首先创建一个文件,并定义一个列表:
fp_2 = open('demo/test5.txt','w')
name_list = ['zhangsan','lisi']
# 导入json模块到python文件:
import json
# 进行序列化:使用json库的dumps()函数进行对象序列化:
names = json.dumps(name_list)
fp_2.write(names)
fp_2.close()
# (2) dump() 函数 法
# 它与dumps()的区别在于
# dump()函数在完成序列化的同时,会指定目标文件,并完成写入操作
# 类似于一步完成dumps()的两个操作:
fp_3 = open('demo/test6.txt','w')
# 这里可以看出,传入的参数多了一个文件对象,也即这就是指定的目标文件,序列化的内容会直接写进去:
json.dump(name_list,fp_3)
fp_3.close()
fp_4 = open('demo/test6.txt','r')
# 此时执行读取,它的结果是一个字符串类型:
content = fp_4.read()
print(type(content))
print(content)
fp_4.close()
# 但是我们的目的是要读出一个列表/元组/字典对象,因此需要做反序列化:
# 反序列化:字节序列 (json字符串)- - - > 对象
# 反序列化也有两种方法:
# (1) loads() 函数 法
fp_5 = open('demo/test6.txt','r')
content = fp_5.read()
# 调用json库中的loads()函数,传入被序列化的字符串变量,返回反序列化的json字符串:
import json
content = json.loads(content)
print(type(content))
print(content)
fp_5.close()
# (2) load()函数 法:
# 此法与dumps和dump的区别一样,也是实现了两步合成一步
# 即读取字符串与字符串转json对象(列表、元组、字典)合并在一步:
fp_6 = open('demo/test6.txt','r')
# 调用json库中的load()函数,同时完成读取+转换json对象:
result = json.load(fp_6)
print(result)
print(type(result))
fp_6.close()之所以要做序列化和反序列化,在代码中有解释,这里再重复一下,原因在于文件的写入操作不支持字典、元组、列表等对象的写入操作,因而需要先序列化后写入文件,而后读出时执行反序列化操作。
I.XI python异常处理介绍
python中,有时候运行一段代码会报错,这时我们使用的IDE会给我们返回错误的类型在控制台,例如这样的情况,在没有创建对应文件的情况下执行读操作:
fp = open('text.txt','r')此时控制台打印出这样的错误:

这固然是错误的类型,但是这样的提示是很不友好的,尤其面向客户开发的过程中,这样的错误提示会让人摸不着头脑。因此我们可以使用python中的try catch语句来自定义抛出异常提示:
# 异常处理:由于代码错误后,默认弹出的错误不利于用户理解,
# 因而在写代码时,对于可能出错的部分,做异常处理,使得弹
# 出的错误能被用户理解为上上策。
# 异常处理格式:
# try:
# 可能出现异常的代码
# except 异常的类型
# 便于用户理解的提示
try:
fp = open('text.txt','r')
except FileNotFoundError:
print('文件可能暂时丢失')此时再次运行,我们能够看到错误的提示是这样的:

这样就更方便我们去查看了!
到这里,python的基础内容介绍完毕,如果是小白看到这里,请认真再复习一下上面的部分,然后可开始下面的部分,python基础扎实的朋友请直接进入下一部分:【python爬虫】!
II. python爬虫篇
II.I urllib库的使用介绍
初识urlliib库:爬取某网站的源代码
urllib库是爬虫常用的一个库,通过这个库的学习,能够了解一些爬虫的基础技术。
下面以爬取某网站首页源码的示例代码介绍urilib库中常用的request()方法:
# 导入urllib库
import urllib.request
# urllib爬取某网站首页的步骤:
# (1) 定义一个url 即目标地址
url = 'http://www.xxx.com'
# (2) 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(url)
# (3) 获取响应中的页面的源码
# 这里read()函数可以获取响应,但是响应的格式是二进制的,需要解码
# 解码:decode('编码格式') 编码格式在 中显示
content = response.read().decode('utf-8')
# (4) 打印数据
print(content)注意上面的解码步骤,如果不解码,获得的内容将会是二进制的格式,不利于我们的正常使用。
HttpResponse响应的六种常见的读取方法
这部分的开头,首先说明通过urllib.request()获取的对象是类型是HttpReponse型的,针对这种类型,有六种常见的读取方法,它们的示例如下:
# HTTPResponse这个类型
# 六个方法:read、readline、readlines、getcode、geturl、getheaders
# response = urllib.request.urlopen(url)
# print(type(response)) # response是HTTPResponse的类型
# (1) 按照一个字节一个字节去读
content = response.read()
print(content)
# 读取具体的n个字节,在read()函数中传参即可
content2 = response.read(5)
print(content2)
# (2) 按行读取,但是只能读取一行
content3 = response.readline()
print(content3)
# (3) 按行读取,并且读取所有行
content4 = response.readlines()
print(content4)
# (4) 返回状态码的方法:200状态码没有问题,其他的状态码可能有问题
print(response.getcode())
# (5) 返回访问的目标的url地址
print(response.geturl())
# (6) 获取的是响应头
print(response.getheaders())上述的response是在第一部分获取的响应变量,大家注意!
urllib库之下载图片、音频、视频
下面介绍一下用urllib.request()方法如何下载文件:
# urllib下载文件的操作
# (1) 下载网页
url_page = 'http://www.baidu.com'
# 使用urillib.request.urlretrieve() 函数,
# 传参分别是url(网页的地址路径)、filename(网页文件的名字)
urllib.request.urlretrieve(url_page,'baidu.html')
# (2) 下载图片
url_img = 'https://xxx'
urllib.request.urlretrieve(url_img,'xxx.jpg')
# (3) 下载视频
url_video = 'https://xxx'
urllib.request.urlretrieve(url_video,'xxx.mov')图片和视频的路径,可以通过在网页中右键、按F12查看网页元素找到。其中视频通常可以通过按F12,之后按ctrl+f查找'。另外所有的第二个传参都代表文件的名字,这个名字是自己起的,因此不用太拘谨,但是要注意后缀.xxx要正确,否则后缀错误导致文件将不可访问!
urllib库之定制请求头
承接前文,此时我们开始在请求中定制我们的请求,也即要开始伪装,下面介绍最基本是一种伪装的方式,也即添加请求头:
# 请求对象的定制:为了解决反爬虫的第一种手段
url = 'https://www.baidu.com'
# 用户代理:UA
headers = {
'user-agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'
}
# urlopen()方法中不能传参字典,因而用户代理UA不能作为传参传入
# 此时需要定制一个请求对象:
# 这里要注意,因为resquest.Resquest()函数有三个传参,这里我们传入两个参数,所以要写成关键字传参
# 如果request = urllib.request.Request(url,headers) 写会报错
request = urllib.request.Request(url = url,headers = headers)
response = urllib.request.urlopen(request)
content = response.read().decode()
print(content)这里再次强调,由于urllib.request.Request()函数有三个传参,但是我们此时只用到了两个,因此我们一定要用关键字传参法去传参,不知道什么是关键字传参的请翻阅本篇博客上面部分python函数介绍。
urllib库之GET请求的爬虫操作
下面是urllib库关于GET请求的用例代码:
# get请求的quote()方法:单个参数的情况下常用该方法进行编解码
# 需求:用get请求的quote()方法获取源码
# (1) 传统方法:
# 找到网页地址url:此时复制的汉字会自动转成unicode编码,如下,即这段编码就是周杰伦三个汉字的编码
url = 'https://www.baidu.com/s?wd=%E5%91%A8%E6%9D%B0%E4%BC%A6'
# 寻找UA
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'
}
# 定制请求对象
request = urllib.request.Request(url = url,headers = headers)
# 模拟浏览器向服务器发起请求
response = urllib.request.urlopen(request)
# 获取响应内容
content = response.read().decode('utf-8')
# 打印内容
print(content)
# (2) get请求的quote()方法:
# 定义固定的url部分
url = 'https://www.xxx.com/s?wd='
# 名字的汉字传入quote()方法做一步unicode进行编解码操作
name = urllib.parse.quote('xxx')
url = url + name
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'
}
request = urllib.request.Request(url = url,headers = headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
# get请求的urlencode()方法:适用于多个参数的编解码,例如下面的案例,有两个参数时这种方法更便捷
# 首先写出基础部分的url
base_url = 'https://www.xxx.com/s?'
# 接下来定义多个参数,这些参数可以是中文的,不需要是unicode码
data = {
'wd' : 'xx',
'sex' : 'xx',
'location' : 'xx'
}
# 此时使用urlencode()把整个多参数全部转成unicode码:
uni_data = urllib.parse.urlencode(data)
# 拼接url即可:
url = base_url + uni_data
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'
}
request = urllib.request.Request(url = url,headers = headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)urllib库之POST请求的处理
这部分主要介绍urllib库对POST请求的处理,下面是urllib库处理POST请求的示例代码:
# post请求:
import urllib.request
url = 'https://xxx'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'
}
data = {
'data':'data'
}
import urllib.parse
# post请求的参数 必须 进行编码
data = urllib.parse.urlencode(data).encode('utf-8')
# post请求的参数是不会拼接在url 的后面的,而是需要放置在请求对象定制的地方
request = urllib.request.Request(url = url,data = data,headers = headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应的数据
content = response.read().decode('utf-8')
import json
# 字符串 - - - > json 对象
obj = json.loads(content)
print(obj)通过上面的示例代码,我们联系之前的GET请求的处理,可以考虑一下二者处理上的区别。示例代码最后部分转换json对象的原因是获取的数据格式是json字符串,我们通过转为json对象能够具体的对获取的数据进行进一步的分析。
GET请求与POST请求处理的区别
下面总结一下urllib处理GET请求与POST请求的区别:
1️⃣ post请求的参数必须编码+转码,也即编码之后,必须调用encode方法:
data = urllib.parse.urlencode(data).encode('utf-8')但get请求的参数只需要进行编码即可,也即:
data = urllib.parse.urlencode(data)2️⃣ post请求的参数放在请求对象的定制过程中,而不是拼接字符串:
request = urllib.request.Request(url = url,data = data,headers = headers)
response = urllib.request.urlopen(request)但get请求的参数使用字符串拼接在url上:
url = base_url + uni_data
request = urllib.request.Request(url = url,headers = headers)
response = urllib.request.urlopen(request)urllib库之handler处理器
首先简单介绍一下handler处理器:
handler处理器是urllib库中继urlopen()方法之后又一种模拟浏览器向服务器发起请求的方法或技术。
它的意义在于使用handler处理器,能够携带代理ip,这为对抗反爬机制提供了一种策略(很多的网站会封掉短时间多次访问的ip地址)。
下面是handler处理器的具体使用方法,其中不含代理ip的部分,代理ip这部分将在下一篇笔记中介绍。
# handler处理器的基础使用
# 需求:使用handler访问百度 获取网页源码
import urllib.request
url = 'http://www.baidu.com'
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'
}
request = urllib.request.Request(url = url,headers = headers)
# handler build_opener open
# 第一步:获取handler对象
handler = urllib.request.HTTPHandler()
# 第二步:通过handler获取opener对象
opener = urllib.request.build_opener(handler)
# 第三步:调用open()函数
response = opener.open(request)
content = response.read().decode('utf-8')
print(content)代码的步骤很清晰,我们可以简化整个过程为三个步骤:首先通过urllib库新建一个handler对象,而后通过urllib库的build_opener()方法新建一个opener对象,其中build_opener()要传入handler对象,最后通过opener的open()方法,获取响应,传参是我们的request定制请求对象。
urllib库之代理ip与代理池
首先先介绍一下什么是代理ip地址:
代理IP地址:代理IP地址一般是说代理服务器的IP地址,就是说你的电脑先连接到代理IP,然后通过代理服务器上网,网页的内容 通过代理服务器,传回你自己的电脑。代理IP就是一个安全保障,这样一来暴露在公网的就是代理IP而不是你的IP了!
以上是对代理ip的介绍,通过介绍可以看出,我们通过代理ip能够防止自己的ip在爬取内容的时候暴露,这样一方面提高了保密性,最重要的点是通过代理ip,我们可以应对ip被封这一反爬机制了!
下面是使用代理ip的示例代码,代码中主要涉及到的知识点是handler处理器的使用(handler处理器使用方式见本文上面部分)
# urllib代理
import urllib.request
url = 'https://www.xxx'
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'
}
proxies = {
'http' : '40.83.102.86:80'
}
request = urllib.request.Request(url = url, headers = headers)
handler = urllib.request.ProxyHandler(proxies = proxies)
opener = urllib.request.build_opener(handler)
response = opener.open(request)
content = response.read().decode('utf-8')
with open('daili.html','w',encoding = 'utf-8') as fp:
fp.write(content)此时我们对比一下之前的handler处理器的基础使用代码,发现只有一个地方发生了变化:
handler = urllib.request.HTTPHandler() => handler = urllib.request.ProxyHandler(proxies = proxies)
这句代码换成了新的ProxyHandler对象后,我们才能把ip地址作为参数传入(proxies是ip地址的变量)。
有了代理ip的基本使用方法,我们可以继续研究一下ip代理池:
所谓代理池,就是很多的ip在一起的一个结构,在这个结构里,我们能够在每一次请求中使用不同的ip地址,从而减少同一个ip的使用频率,以降低ip被封掉的风险,对抗反爬机制!
下面展示了一个简易的代理池示例代码:
# 代理池的使用
import urllib.request
import random
proxies_pool = [
{ 'http' : '27.203.215.138:8060' },
{ 'http': '40.83.102.86:80' },
{'http': '14.215.212.37:9168'}
]
proxies = random.choice(proxies_pool)
url = 'https://www.xxx.com'
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'
}
request = urllib.request.Request(url = url,headers = headers)
handler = urllib.request.ProxyHandler(proxies = proxies)
opener = urllib.request.build_opener(handler)
response = opener.open(request)
content = response.read().decode('utf-8')
with open('dail2.html','w',encoding='utf-8') as fp:
fp.write(content)对比第一段代码,我们这里的区别在于ip地址有三个,组成了一个简单的代理池,我们通过random.choice(),从代理池这一字典对象中随机一个ip地址,而后传入handler对象的创建中,同上!
urllib库的异常处理
在前面提到了python的异常处理,在爬虫中,urllib库的使用过程中会出现几种常见的错误如下:
try:
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
except urllib.error.HTTPError:
print('系统正在升级...')
except urllib.error.URLError:
print('都说了系统在升级...')1️⃣ 第一个错误是HTTPError,这是HTTP请求的错误,我们通过urllib.error.HTTPError这个类型进行匹配,捕捉后对错误进行处理即可,处理方式与之前的笔记介绍的方式相同。
2️⃣ 第二个错误是URLError,这是把url书写错误后的错误,我们通过urllib.error.URLError这个类型进行匹配,捕捉后同样处理错误。
II.II cookie的使用
什么是cookie?
首先,作为这部分的第一部分,先介绍一下什么是cookie:
Cookie 并不是它的原意“甜饼”的意思, 而是一个保存在客户机中的简单的文本文件, 这个文件与特定的 Web 文档关联在一起, 保存了该客户机访问这个Web 文档时的信息, 当客户机再次访问这个 Web 文档时这些信息可供该文档使用。由于“Cookie”具有可以保存在客户机上的神奇特性, 因此它可以帮助我们实现记录用户个人信息的功能, 而这一切都不必使用复杂的CGI等程序 。
举例来说, 一个 Web 站点可能会为每一个访问者产生一个唯一的ID, 然后以 Cookie 文件的形式保存在每个用户的机器上。如果使用浏览器访问 Web, 会看到所有保存在硬盘上的 Cookie。在这个文件夹里每一个文件都是一个由“名/值”对组成的文本文件,另外还有一个文件保存有所有对应的 Web 站点的信息。在这里的每个 Cookie 文件都是一个简单而又普通的文本文件。透过文件名, 就可以看到是哪个 Web 站点在机器上放置了Cookie(当然站点信息在文件里也有保存)
这是某度对cookie的介绍和我对cookie的理解,用一句话总结就是cookie是携带了用户信息的标识,由于我们的HTTP协议是没有记忆的,通过cookie就能够将用户进行点对点的识别。当你进入某个网站并登录后,关闭网站再次进入,如果不需要再次登录而是直接进入登录状态,那么这个网站就是使用了cookie技术。
利用cookie绕过登录
这是我们的重点:利用cookie绕过登录。
需要这么做的原因在于当使用爬虫爬取一些网页时,这些网页对应的网站会将我们对于某个页面请求重定向到网站的登录页面,也就是这样的一个逻辑顺序:
假设我们要爬取页面A,该网站的登录页面是页面B,当我们遇到会重定向到登录页面进行反爬的网站时,会出现:请求A - - - > 返回B 的效果,但是我们需要的效果是:请求A - - - > 返回A,此时就需要cookie绕过登录的操作:
# 数据的采集时,绕过登录,进入某个页面,这是cookie登录
import urllib.request
url = 'https://xxx'
headers = {
# cookie中携带着登录信息,如果有登陆之后的cookie,那我们可以携带者cookie进入到任何页面
'cookie': 'xxx',
# referer 判断当前路径是不是由referer链接进来的 如果不是从这个链接进入,则不可访问
'referer': 'https://xxx',
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36',
}
request = urllib.request.Request(url = url,headers = headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
# 保存本地
with open('xxx.html','w',encoding='utf-8')as fp:
fp.write(content)
cookie的具体值可以通过F12检查网络源代码后获取:按F12 - - - > 选择 Network - - - > Headers - - - > cookie,我以一个网站为例:
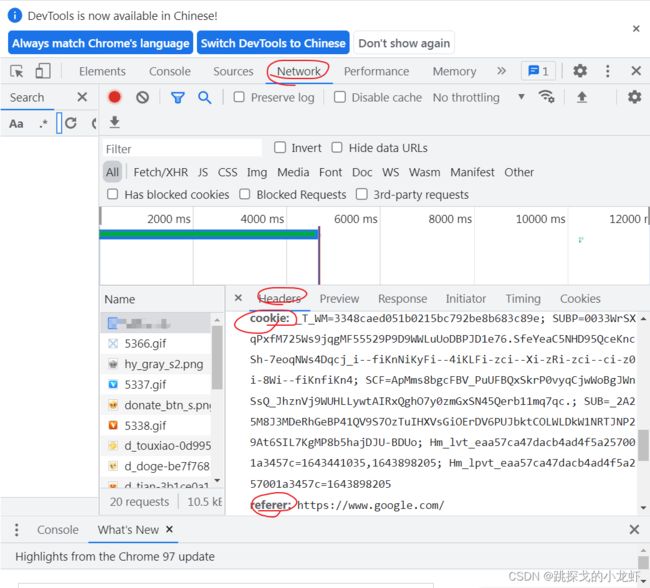
最后简单介绍一下参数referer,这个参数的含义是源url,也就是通过这个源url,我们进入了这个目标页面,因此很多的网站会通过referer这个源url参数来进行一个反爬判定,我们可以添加referer这个参数在headers里,作为对抗这一机制的方法!
II.III requests库的学习
requests库的介绍与安装
首先,了解一下什么是requests库:
它是一个Python第三方库,处理URL资源特别方便,可以完全取代之前学习的urllib库,并且更加精简代码量(相较于urllib库)。
那么话不多说,我们安装一下:
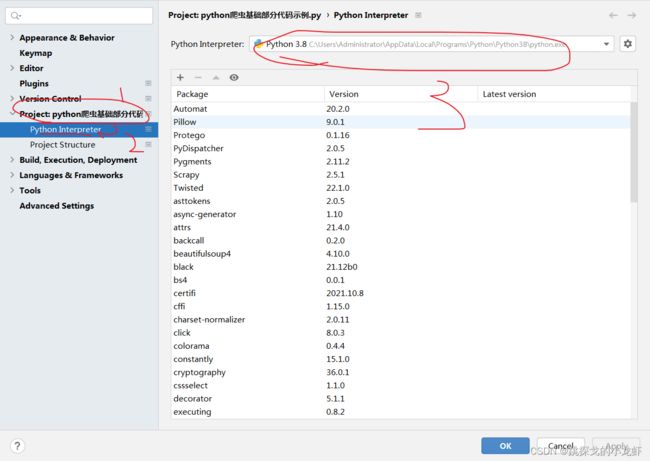
1️⃣ 首先,我们依旧是打开pycharm,查看一下自己的python解释器的安装位置:File - - - > Settings - - - > Project - - - > Python Interpreter
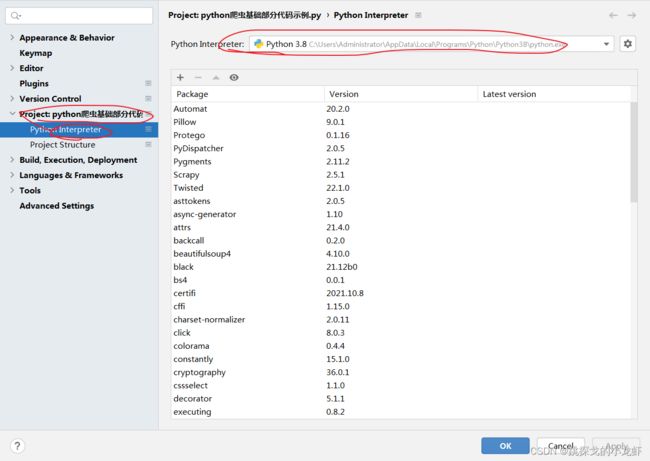
2️⃣ 进入python解释器安装目录下,打开终端: Win + R,输入cmd ,回车,之后输入指令 cd,把Scripts文件夹拖入cd后的光标中并执行切换:
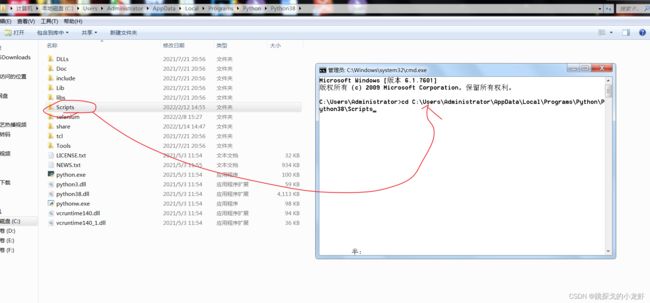
3️⃣ 输入安装指令并执行:
pip install requests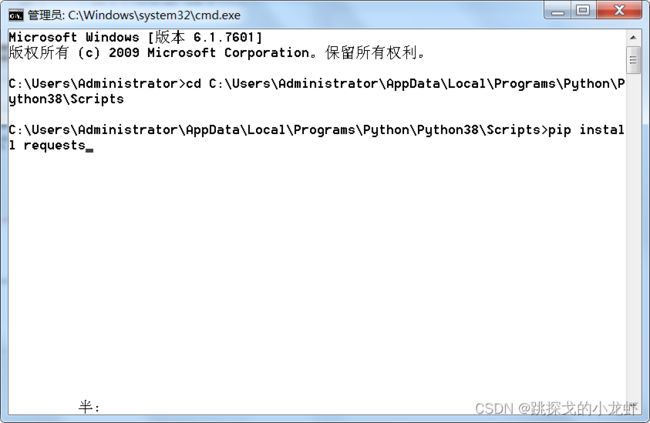
requests库的基本语法
接下来,介绍requests的基本语法,与urllib库类似,requests库的语法大致分为一种类型与六种属性:
首先回忆一下urllib库,在urllib库中,我们通过测试发现,它获取的服务器响应是HTTPResponse的类型,而requests库获取的服务器响应是requests.models.Response的类型。
然后我们用requests库模拟浏览器,向服务器发起一次普通的请求,这次请求只是为了辅助下面的六种属性:
import requests
url = 'http://www.xxx.com'
response = requests.get(url = url)用requests库时,我们发起请求是通过requests.get()函数进行的,传参是目的网页的url(后续会有其他的传参,暂时此处传入一个url),并且用response变量接受服务器的响应。
接下来是requests库的六种属性:
1️⃣ text属性:字符串形式返回网页源码(由于此时编码格式是gbk,中文部分可能会乱码,稍后解决)
# (1) text属性:以字符串形式返回网页源码
print(response.text) # 由于没有设置编码格式,中文会乱码2️⃣ encoding属性:设置相应的编码格式
# (2) encoding属性:设置相应的编码格式:
response.encoding = 'utf-8'这之后的response就不会出现中文乱码现象了。
3️⃣ url属性:返回url地址
# (3) url属性:返回url地址
url = response.url4️⃣ content属性:返回二进制的数据
# (4) content属性:返回二进制的数据
content_binary = response.content5️⃣ status_code属性:返回状态码 200是正常
# (5) status_code属性:返回状态码 200是正常
status_code = response.status_code6️⃣ headers属性:返回响应头
# (6) headers属性:返回响应头
headers = response.headersrequests库的GET请求
requests库的get请求的示例代码如下:
import requests
url = 'https://www.xxx.com'
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'
}
data = {
'data' : 'data'
}
# 三个参数:
# url:请求路径
# params:请求参数
# kwargs:字典
# 不需要请求对象的定制
# 参数使用params进行传递
# 参数无需编码
# 同时不需要请求对象定制
# 请求路径的?字符可以加也可以省略
response = requests.get(url = url,params = data,headers = headers)
response.encoding = 'utf-8'
content = response.text
print(content)从上面可以看出来,requests最省代码的地方在于,它不需要进行请求对象的定制,如果换成urllib库,我们需要先封装一个request请求对象,而后把这个对象传入urllib.request.urlopen()函数中,而在requests库中,我们只需要把三个参数,即url、data和headers传入,即可完成get请求,十分方便!(上面的代码执行的是在百度中搜索‘跳探戈的小龙虾’返回的网页源码)
requests库的POST请求
接下来是requests库的post请求:
# requests_post请求
import requests
url = 'https://www.com'
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'
}
data = {
'data' : 'xxx'
}
# 四个参数:
# url:请求路径
# data:请求参数
# json数据
# kwargs:字典
response = requests.post(url = url,data = data,headers = headers)
content = response.text
import json
obj = json.loads(content.encode('utf-8'))
print(obj)如果说get请求requests库只比urllib库简单一点点的话,那么post请求绝对是requests库更加便捷,它不仅省去的请求对象的定制,而且省略了参数的编码和转码的操作,可以说非常方便,只需要和get请求一样把三个参数url、data和headers传入即可,因此post请求个人强烈推荐用requests库代替urllib库。
requests库的代理ip方法
最后介绍一下requests使用代理ip的方式,它又简化了urllib库,回忆urllib库代理ip,我们需要创建handler处理器,还要定义opener对象,但requests库中,我们只需要把代理ip作为一个普通的参数,传入requests.get()/requests.post()函数即可(简直太方便了!)
# requests_ip代理
import requests
url = 'http://www.baidu.com/s'
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'
}
data = {
'wd' : 'ip'
}
proxy = {
'http:' : '218.14.108.53'
}
response = requests.get(url = url, params = data,headers = headers,proxies = proxy)
content = response.textrequests库小结
最后,简单总结一下requests库,首先对于requests库,不再是六种方法,而是有六个属性;其次是对于get请求和post请求,requests库都不再需要请求对象的定制,而且post请求不再需要编解码操作;最后对于ip代理,不需要定义一些中间对象,直接传入代理ip,作为一个普通参数即可。同时,我们的requests.get()/requests.post()函数,能够传入四个参数:url、data、headers、ip代理。
II.IV 爬虫解析方法之xpath解析
xpath的安装
在第一部分安装的介绍之前,先介绍一下什么是xpath,以及为什么我们要学习xpath:
xpath是一门在XML文档中查找信息的语言。xpath可用来在XML文档中对元素和属性进行遍历。
通俗的说,xpath可以用来精确的定位和切割某个标签,标签指的是我们的html文件的源码中的标签,例如、
那么这个和我们的爬虫有什么关系呢?在之前的笔记中,我们大体上只获得过页面的源代码,这很大程度是不够的,我们需要的是精确的信息,这些信息就需要从混乱的源码中提取出来,而xpath就提供了这样的一种方法。总结,我们用xpath来精确提取html源码中的信息。
下面我们进行xpath的安装:
1️⃣ 在python的解释器所在的文件目录中Script文件夹内安装lxml库:
lxml库包含了我们需要的xpath,因此我们需要先安装lxml库,这个库要怎么安装呢,这里提供了详细的步骤:
首先,我们打开pycharm,选中File - - - > setting:
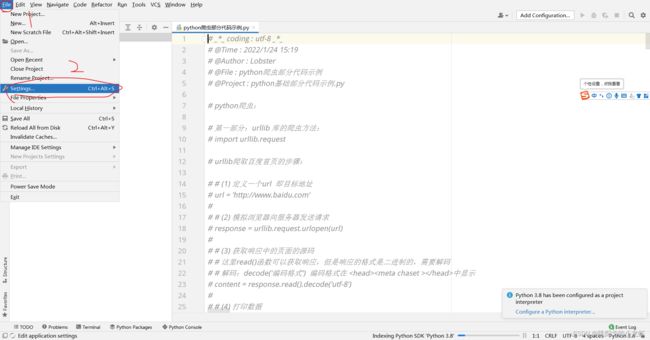
打开后,选择Project - - - > Python Interpreter:
之后能够看到python interpreter 的路径,我们可以选择进入这个路径,也可以稍后手打路径,我这边推荐我们先进入这个路径对应的文件,也即我们进入Python38文件夹。

之后我们打开终端(Win + R,而后输入cmd),并输入指令:cd
之后我们不必手打后面的路径,而是可以把Scripts文件拖动到cd的光标后(cd后面要留一个空格!) :
拖动后,路径会被自动输入,我们回车确认即可。而后我们通过终端进入了Scripts文件夹,之后我们输入这句指令安装lxml库:
pip install lxml -i https://pypi.douban,com/simple安装后,我们就可以在pycharm中导入lxml库中的xpath了,导入xpath的代码是这样的:
from lxml import etree2️⃣ 接下来我们安装浏览器插件:xpath插件:
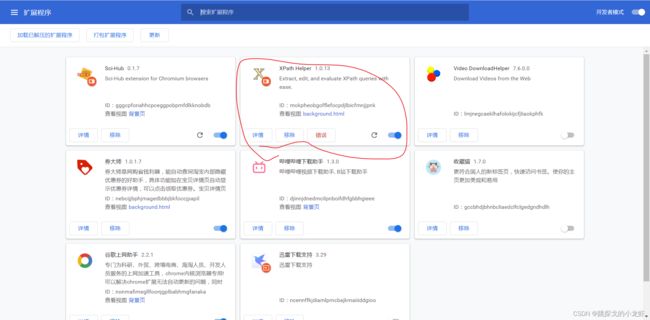
针对谷歌浏览器的朋友,打开自己的扩展程序:
而后保持扩展程序被打开的状态,我们下载xpath的zip文件(提取码:dxzj):
点击链接下载xpath
下载后,不要解压zip,而是把这个zip文件拖入我们刚才打开的扩展程序页面,之后xpath插件就会被自动安装在浏览器上了:
xpath的基本语法
xpath的基本语法,都展示在了下面的示例代码中,这些语法与正则表达式很类似:
# 解析:xpath的基础使用
from lxml import etree
# xpath解析
# 1. 本地文件:etree.parse
# 2. 解析服务器响应的数据 response.read().decode('utf-8') ***** etree.HTML()
# xpath解析本地文件
tree = etree.parse('new.html')
# 查找ul下面的li
li_list = tree.xpath('//body//li')
# 判断列表的长度:length
print(li_list)
print(len(li_list))
# 查找带有id属性的li标签
li_list = tree.xpath('//ul/li[@id]')
print(li_list)
print(len(li_list))
# 获取标签的内容:text()
li_list = tree.xpath('//ul/li[@id]/text()')
print(li_list)
print(len(li_list))
# 获取指定id的标签,属性值id要加引号
li_list = tree.xpath('//ul/li[@id = "l1"]/text()')
print(li_list)
# 查找指定id的标签的class属性值
li_list = tree.xpath('//ul/li[@id = "l1"]/@class')
print(li_list)
# 模糊查询:
(1) id中含有l的li标签
li_list = tree.xpath('//ul/li[contains(@id,"l")]/text()')
print(li_list)
# (2) id的值以l开头的li标签
li_list = tree.xpath('//ul/li[starts-with(@id,"c")]/text()')
print(li_list)
# 逻辑运算:
# (1) 查询id为l1和class为c1的标签:
li_list = tree.xpath('//ul/li[@id = "l1" and @ class = "c1"]/text()')
print(li_list)
# (2) 查询id为l1或l2的标签:
li_list = tree.xpath('//ul/li[@id = "l1"]/text() | //ul/li[@id = "l2"]/text()')
print(li_list)
# xpath解析服务器响应文件:从某网站html文件中提取内容
# (1) 获取源码
import urllib.request
url = "https://xxx.com"
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'
}
request = urllib.request.Request(url = url,headers = headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
# print(content)
# (2) xpath解析服务器响应的文件
from lxml import etree
# 解析服务器响应的文件的核心操作:
tree = etree.HTML(content)
# 注意xpath的返回数据类型是列表,我们可以用索引值:
result = tree.xpath('//input[@id = "su"]/@value')[0]
print(result)最后强调一下,xpath既可以处理本地html文件,也可以处理服务器的响应html文件,这是它的一个特性,这个特性在后面其他的提取技术(jsonpath)中可能不具备!
II.V 爬虫解析方法之jsonpath解析
jsonpath的介绍
首先介绍一下jsonpath是什么:
jsonpath是一种简单的方法来提取给定JSON文档的部分内容。
那么我们为什么要学习jsonpath?原因其实很简单,因为有时候我们拿到的数据是以json为格式的数据,此时我们不再能够使用之前学习的xpath对内容进行解析,因此我们需要一种方法来解析json格式的数据,它就是jsonpath!
jsonpath的安装
在语法介绍之前,先安装一下jsonpath库:
安装的方法是这样的:
1️⃣ 首先,我们打开pycharm,选中File - - - > setting
之后选择 Project:xxxx - - - > Python Interpreter

最后按照图中位置,找到自己的python的安装地址,并且进入改地址。

2️⃣ 之后,在地址所示的这个位置,我们按 Win + R,调出终端框,并输入 cd,之后路径还是用拖拽法把Scripts文件夹拖进cd光标后(要在cd后面间隔一个空格):
3️⃣ 最后,在终端框输入下面的指令,安装jsonpath:
pip install jsonpath
jsonpath的基础语法介绍
介绍语法之前,先强调一点,那就jsonpath只能处理本地的json文件,不能直接处理服务器的响应,这是它与xpath的第二点区别(第一点是处理的对象不同)。
然后我们先以下面这个json源码为例子,进行语法介绍:
{
"store": {
"book": [
{
"category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
"price": 8.95
},
{
"category": "fiction",
"author": "Evelyn Waugh",
"title": "Sword of Honour",
"price": 12.99
},
{
"category": "fiction",
"author": "Herman Melville",
"title": "Moby Dick",
"isbn": "0-553-21311-3",
"price": 8.99
},
{
"category": "fiction",
"author": "J. R. R. Tolkien",
"title": "The Lord of the Rings",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"author": "Tony",
"color": "red",
"price": 19.95
}
},
"expensive": 10
}新建一个json文件,把上面的代码拷贝进去,并命名文件,我这里命名为store.json。(或者直接点击这里下载:store.json,提取码:yrso)
1️⃣ 读取一个json文件:
首先介绍如何读入一个json文件,它的语法格式是这样的:
import json
import jsonpath
# 注意,默认打开文件的格式是gbk,但json.load()返回的的对象格式要求编码为utf-8,
# 因此我们要强制编码为utf-8
obj = json.load(open('store.json','r',encoding = 'utf-8'))这里要注意,我们调用函数之前,要先导入json库和jsonpath库;此外,我们通过json.load()函数导入我们的json文件,这个函数的传参不是文件名,而是一个文件对象。
这里多解释一下,也就是说,我们传参是:json.load(文件对象),而不是json.load('store.json'),后者是一个字符串,会报错,至于这个文件对象,我们可以直接用open()函数创建,也可以在外面先用open函数新建一个文件对象,之后将对象传入,二者均可。
2️⃣ 解析json文件:
导入后,我们开始学习jsonpath的语法,首先我们参考下表,对照一下jsonpath的语法与xpath:
| XPath | JSONPath | 描述 |
| / | $ | 根元素 |
| . | @ | 当前元素 |
| / | . or [] | 当前元素的子元素 |
| .. | n/a | 当前元素的父元素 |
| // | .. | 当前元素的子孙元素 |
| * | * | 通配符 |
| @ | n/a | 属性的访问字符 |
注意,第一行的/是根元素的意思,也就是说在jsonpath中,每一句jsonpath语言都要以一个$符号开头,后面的部分按照上面与xpath对照进行理解即可。(n/a表示该项不存在)
基于上面的表格,我们能够对前面提到的store.json做如下的实战演练,加强对jsonpath使用的理解:
import json
import jsonpath
# 注意,默认打开文件的格式是gbk,但json.load()返回的的对象格式要求编码为utf-8,
# 因此我们要强制编码为utf-8
obj = json.load(open('store.json','r',encoding = 'utf-8'))
# 解析书店所有书的作者
book_author_list = jsonpath.jsonpath(obj,'$.store.book[*].author')
print(book_author_list)
# 可以用索引值标注第几本书:
author = jsonpath.jsonpath(obj,'$.store.book[1].author')
print(author)
# 所有的作者,包括自行车
author_list = jsonpath.jsonpath(obj,'$..author')
print(author_list)
# store下面所有的元素
tag_list = jsonpath.jsonpath(obj,'$.store.*')
print(tag_list)
# store下面所有的price
price_list = jsonpath.jsonpath(obj,'$.store..price')
print(price_list)
# 第三个书
book = jsonpath.jsonpath(obj,'$.store.book[2]') # 也可以写作 $..book[2]
print(book)
# 最后一本书
# @相当于this,指代当前的每一个对象
# @.length表示当前的json的字典长度
last_book = jsonpath.jsonpath(obj,'$..book[(@.length-1)]')
print(last_book)
# 前两本书
# 用切片思维:
book_list = jsonpath.jsonpath(obj,'$..book[0,1]')
# 另一种写法:
book_list = jsonpath.jsonpath(obj,'$..book[:2]')
# 过滤包含版本号isbn的书:
# 条件过滤需要在圆括号前面添加一个问号
book_list = jsonpath.jsonpath(obj,'$..book[?(@.isbn)]')
print(book_list)
# 过滤超过十元的书
book_list = jsonpath.jsonpath(obj,'$..book[?(@.price > 10)]')
print(book_list)II.VI 爬虫解析方法之bs4解析
bs4的介绍
首先,介绍一下bs4,它是又一种解析的手段,之前有xpath和jsonpath。bs4的特点是这样的:
BS4全称是Beatiful Soup,它提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。
bs4最舒服的一点是提供了更适合前端开发工作者使用的语言习惯,它的语法很大程度对前端开发工作者是友好的,同时它解析的对象是本地html文件和服务器的响应html文件。
bs4的安装
接下来,我们安装一下bs4:
1️⃣ 首先,我们打开pycharm,选中File - - - > setting
之后选择 Project:xxxx - - - > Python Interpreter
最后按照图中位置,找到自己的python的安装地址,并且进入该地址:
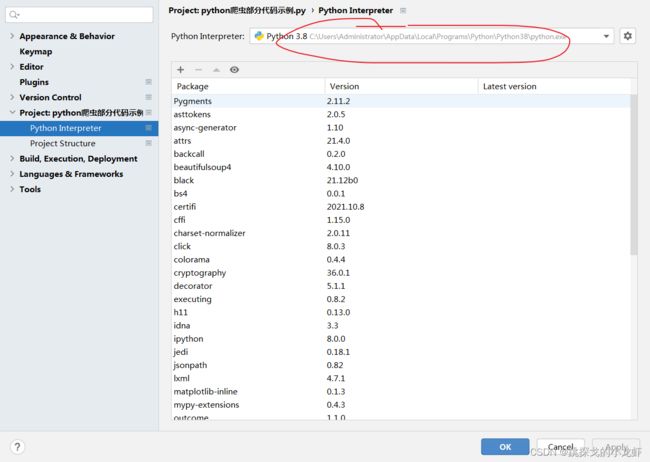
2️⃣ 之后,在地址所示的这个位置,我们按 Win + R,调出终端框,并输入 cd,之后路径还是用拖拽法把Scripts文件夹拖进cd光标后(要在cd后面间隔一个空格):
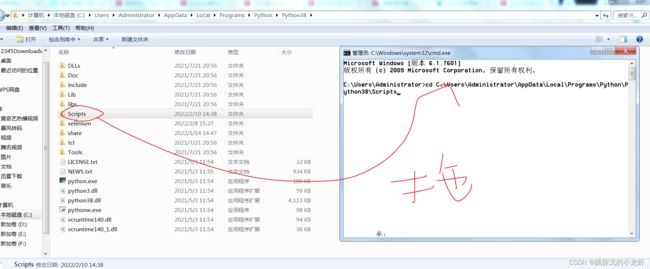
3️⃣ 最后,在终端框输入下面的指令,安装jsonpath:
pip install bs4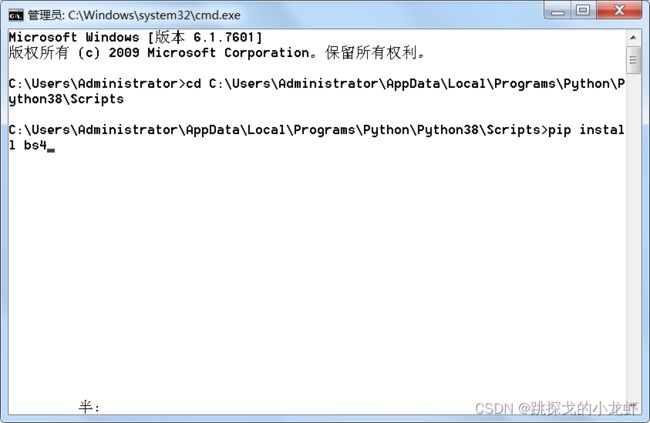
bs4的基本语法使用
前面提到bs4可以解析本地和服务器响应html文件,为了方便介绍bs4的基本语法,我们以本地的html为例,下面是本地html的源码:
soupDemo
- 张三
- 李四
- 王五
- 周六
soupDemo
hhh
soupDemo2
我把这个文件命名为soup.html,后面以这个名字作为读入的名称。
1️⃣ 导入本地html文件:
from bs4 import BeautifulSoup
# 解析本地文件:bs4基础语法的学习
soup = BeautifulSoup(open('soup.html',encoding = 'utf-8'),'lxml')这部分首先肯定要导入bs4,导入的格式是 from bs4 import BeautifulSoup,之后我们把本地的html文件读入即可。之前新建的soup.html文件最好放在与当前的python项目文件同级目录下,方便我们进行路径的输入。
bs4读入本地文件的格式与jsonpath基本上相同,它传入两个参数(比jsonpath多了一个):一个是文件对象,一个是字符串'lxml’,前者是一个变量,后者是一个字符串'lxml',固定的,我们只需要每一次更改文件对象即可操作不同的文件。
2️⃣ bs4的基本操作语法:
from bs4 import BeautifulSoup
# 解析本地文件:bs4基础语法的学习
soup = BeautifulSoup(open('soup.html',encoding = 'utf-8'),'lxml')
# bs4的基础操作:
# (1) 根据标签名查找节点,找到的是第一个符合条件的节点:
print(soup.a) # 返回的是soupDemo而不是soupDemo2
# (2) 获取标签的属性:
print(soup.a.attrs)上面是两个bs4的基础语法,获取标签元素和标签元素的属性,其中属性那一项指的是标签的所有属性,都会被打印出来。另外注意一下,它获取的是第一个符合条件的节点,而不是所有符合条件的节点!(这里的标签就是指的是h5的标签)
3️⃣ bs4常用的六个函数介绍:
from bs4 import BeautifulSoup
# 解析本地文件:bs4基础语法的学习
soup = BeautifulSoup(open('soup.html',encoding = 'utf-8'),'lxml')
# bs4的常见函数:
# (1) find()
# 返回的是第一个符合条件的节点(数据)
print(soup.find('a')) # 返回的是soupDemo而不是soupDemo2
# find()还可以根据标签的属性值查找符合条件的节点,
# 例如下面通过title属性值查找:
print(soup.find('a',title = 's2'))
# class属性也可以被查找,但是注意class本身是python的关键字
# 因此我们要加一个下划线:class_
print(soup.find('a',class_ = "a1"))
# (2) find_all() :返回结果是一个列表,包含了所有目标标签(这里是a标签)
print(soup.find_all('a'))
# 如果想要多标签的数据,需要在find_all中传入列表对象,如下例:['a','span']
print(soup.find_all(['a','span']))
# 如果想要限制返回的标签数量,可以加一个limit,它的值表示查找前n个数据
print(soup.find_all('li',limit = 2)) # 查找前两个数据
# (3) select() (推荐)
# select()返回一个列表,同时和find_all一样返回所有的目标标签
print(soup.select('a'))
# 类选择器(在前端的一种叫法):可以通过加一个 .类名 来筛选class
print(soup.select('.s1'))
# id选择器(也是前端的一种叫法):可以通过加一个 #id名 来筛选id
print(soup.select('#s2'))
# 属性选择器:可以通过属性存在与否、属性的具体值来筛选
print(soup.select('li[id]')) # 这表示查找所有的 li标签 中含有 id 的标签li
print(soup.select('li[id = "l2"]')) # 这表示查找所有的 li标签 中含有 id 且id的值为l2的标签li
# 层级选择器:
# a.后代选择器:一个空格,查找某个标签的后代,包括儿子、孙子标签
print(soup.select('div li'))
# b.子代选择器:一个大于号,只能查找某个标签的儿子标签,不包括孙子标签
print(soup.select('div > ul > li')) # 这里写 div > li,则没有内容返回,因为li是div的孙子标签而非子标签
# 多个标签都拿到:
# 在select()中,我们无需用列表的传参表示多个标签,直接以逗号隔开多个标签即可:
print(soup.select('a,li'))
# (4) 获取节点具体的信息的函数
# a.获取节点的内容
# 注意要加一个索引,因为我们的select会返回一个列表,不加索引,就无法处理成字符串
obj = soup.select('#s2')[0]
# 如果标签对象中只有内容,那么string和 get_text()都可以使用
# 但是如果标签对象中有内容也有标签,那么string就无法使用,只能用get_text()
print(obj.get_text())
# b.获取某个具体的节点(标签)的属性
# 首先获取id值是s2的标签
tag = soup.select('#s2')[0]
# 返回这个标签的名字,例如a标签,就返回一个a
print(tag.name)
# 将所有的标签属性以字典的格式返回
print(tag.attrs)
# 获取某个节点的具体某一个属性,原理是可以根据attrs的字典对象特点,
# 用字典对象的get函数,传入键,来获取某一个键值对的值
print(tag.attrs.get('title')) # 获取id值是s2的标签的title属性
关于最后一条,补充一下,就是说tag.attrs会返回一个字典,这个字典是该标签所有的属性,那么我们需要其中一个属性,可以用字典的一个方法get(),传入键,获得对应的值,这是一个键值对的关系!
bs4处理服务器响应文件
最后,我们学习一下如何用bs4处理服务器响应文件:
from bs4 import BeautifulSoup
soup = BeautifulSoup(content,'lxml')服务器的响应应当用上述的格式进行书写:使用Beautifulsoup()函数,传入两个参数,第一个参数是服务器的响应的内容,第二个参数是'lxml’这个固定的参数。
II.VII selenium库的介绍
selenium库的安装及相关浏览器工具的下载
首先,我们介绍一下什么是selenium库:
selenium是一个自动化测试工具,支持Firefox,Chrome等众多浏览器 在爬虫中的应用主要是用来解决JS渲染的问题。
那我们能用selenium做些什么呢:
1️⃣ 爬虫,selenium能够模拟真人打开浏览器,因此可以更好的获取我们需要的数据。(有时候,使用urllib库模拟浏览器的时候,会被服务器识别,返回的数据有所缺失,因此我们的确需要selenium做爬虫)
2️⃣ 自动化小工具,例如可以帮我们操作一些浏览器的交互等等。
下面我们介绍一下selenium库以及相关的浏览器工具的安装方法:
首先,我们安装selenium库:
1️⃣ 打开pycharm,选择 File - - - > Settings :
之后我们点击 Project - - -> Python Interpreter,查看我们python解释器的位置,进入这个位置。
2️⃣ 进入python解释器安装的位置后,我们 按 Win + R,输入cmd,调出终端:
之后我们在终端输入:cd,并把左侧的Scripts 文件夹拖入cd后的光标中(空一格空格),并执行这指令:
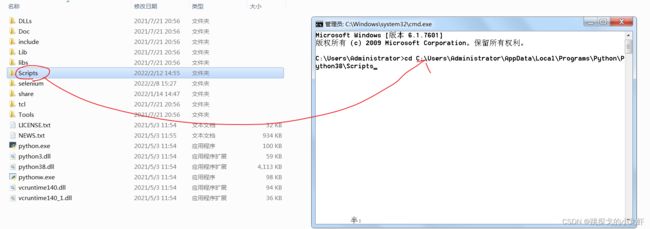
此时我们的终端已经进入了Scripts文件夹中。
3️⃣ 执行安装指令:
pip install selenium==3.4这里注意一下,我们的指令是安装3.4版本的selenium,大家不要省略 == 及之后的部分,否则安装是selenium可能因为版本问题影响后面的语法和操作!
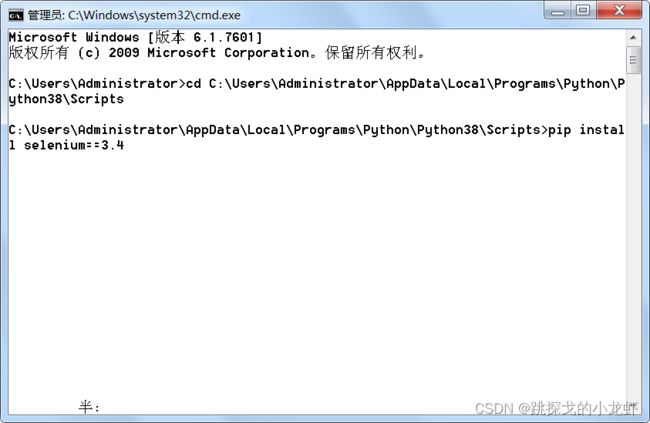
安装selenium库之后,我们接下来安装模拟真人操作浏览器的浏览器工具:
1️⃣ 访问这个地址:浏览器工具下载
之后我们可以看到这样的页面:

2️⃣ 查看自己浏览器的版本:
这里以谷歌浏览器为例,我们任意打开一个页面,点击页面右上角的三个点,之后选择 帮助 - - - > 关于 Google Chrome:
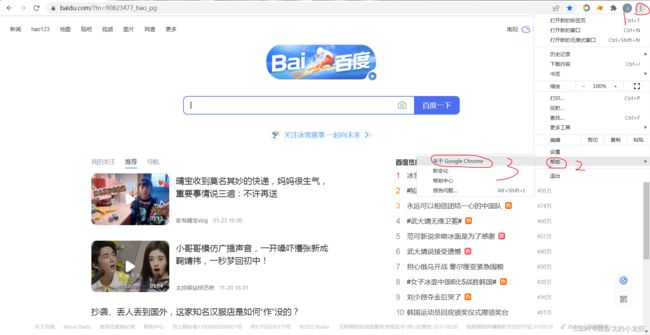
之后我们在下图的页面中获取到浏览器的版本号:
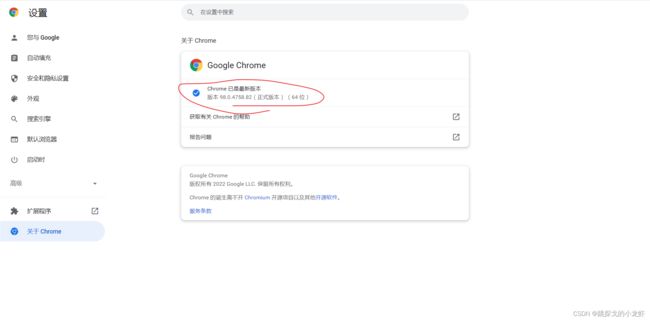
3️⃣ 下载对应版本的浏览器工具:
我们根据上面看到的谷歌浏览器的版本号,在第一步打开的网页中找到对应的版本号的工具下载即可。

不用每一位都对上,前面几位对上都可以兼容。下载后,放在python项目文件夹下,最好与python文件同级,方便后面的引入
selenium库的基本语法
首先我们介绍一下selenium库的基本语法:
1️⃣ 导入selenium库,并初始化浏览器操作对象:
from selenium import webdriver
path = 'chromedriver.exe'
browser = webdriver.Chrome(path)上面的部分一共干了两件事:导入selenium库,初始化了浏览器操作对象。导入时格式是 from selenium import webdriver,导入后,我们可以创建一个字符串变量path,path的值是我们之前安装浏览器工具的路径,如果安装在与此python文件同级目录下,则直接输入其名称即可,否则要使用绝对路径!
最后用webdriver.Chrome()函数,传入路径,创建一个浏览器操作对象browser(名字可以自定义),这个对象会作为我们模拟真人操作浏览器的帮手!
2️⃣ 模拟真人,自动打开浏览器,并获取网页源码:
from selenium import webdriver
path = 'chromedriver.exe'
browser = webdriver.Chrome(path)
url = 'https://www.baidu.com'
browser.get(url)
content = browser.page_source这一步,首先我们定义需要打开的网页的地址,之后使用get()函数,模拟真人打开浏览器并传入url,与此同时,我们的browser对象也与这个url建立了绑定,后续获取源码或者节点的信息都需要通过这个browser对象。最后,通过page_source函数,获取当前url的网页的源码。
3️⃣ 定位元素的几种方法:
# (1) 根据id属性的属性值找到对象_重要:
button = browser.find_element_by_id('su')
print(button)
# (2) 根据name属性的属性值找到对象:
button = browser.find_element_by_name('wd')
print(button)
# (3) 根据xpath的语句找到对象_重要:
button = browser.find_element_by_xpath('//input[@id = "su"]')
print(button)
# (4) 根据标签的名称找到对象
button = browser.find_element_by_tag_name('input')
print(button)
# (5) 根据CSS选择器找到对象,相当于bs4的语法_重要:
button = browser.find_element_by_css_selector('#su')
# (6) 根据链接元素查找对象:
button = browser.find_element_by_link_text('新闻')所谓的定位元素,就是指我们通过一些方法把页面上的元素与实际的代码中的对象(变量)进行绑定,以便于后续通过操作这些对象来获取元素信息、实际控制或操作页面上的元素(如果学过前端js、安卓的朋友可能比较理解这样的模式)。这些上面展示了六种定位元素的办法,其中比较重要的是前三种和第五种,即id、name、xpath语句、CSS选择器这四种方式,其他两种仅作为了解即可。
4️⃣ 元素信息的获取:
# 首先,拿到页面中id值是su的input输入框元素,与变量input建立绑定关系
input = browser.find_element_by_id('su')
# (1) get_attribute()函数获取标签的指定属性的属性值
# 传参是属性的名称,例如class、id等,返回这些属性的属性值
print(input.get_attribute('class'))
# (2) tag_name函数获取元素对应的标签的名称,例如元素是input标签,返回值就是input
print(input.tag_name)
# (3) text函数获取标签的文本,文本指的是标签尖括号的内容:
# 例如: xxx 于是获取的结果是xxx
print(input.text)定位到id值是su的input表单元素之后,我们把这个元素与变量input进行绑定,而后通过操作input,我们能够获取关于这个表单元素的信息,其中重要的信息有两个:一个是元素的属性值,则可以通过get_attribute()函数获取,这个函数的传参是属性的名称,比如class、id等等,返回的是该属性的属性值;另一个是标签内的文本,这可以通过text属性获取。
5️⃣ selenium交互学习:
# (1) 点击按钮:
button.click()
# (2) 文本框输入指定内容:
input.send_keys('content')
# (3) 滑到底部:
js_bottom = 'document.documentElement.scrollTop = 100000'
browser.execute_script(js_bottom)
# (4) 回到上一页:
browser.back()
# (5) 回到下一页:
browser.forward()
# (6) 关闭浏览器:
browser.quit()注意,上面的代码的前提是定义了一个button对象,与页面中的某个按钮对象进行了绑定;定义了一个input对象,与页面中的某个文本框对象进行了绑定;browser是定义的浏览器操作对象。
6️⃣ 句柄切换操作:
首先介绍一下句柄:
句柄(Handle)是一个是用来标识对象或者项目的标识符,可以用来描述窗体、文件等。
对于selenium操作来说,句柄的切换发生在多窗口的切换时:
![]()
上图显示的就是这种情况,此时我们有五个窗口,当在第一个窗口时,我们通过selenium自动化操作点击了一个按钮,打开了第二个窗口,此时我们并不能直接控制第二个窗口的元素,而是需要先切换句柄。
那么我们切换句柄(窗口)的操作是这样的:
windows = browser.window_handles
browser.switch_to.window(windows[index])第一步是获取当前的所有句柄,返回的是一个列表,第二步是传入某个索引值index到windows列表中,关于索引值,是这么定义的:
根窗口,也即第一个窗口,它的索引值永远是0,之后的所有窗口,按照反序号排列,即新打开的窗口的索引值是1,旧的窗口依次往后排列。举个例子,上图的五个窗口,如果打开的顺序是1 - - - > 2 - - - > 3 - - - > 4 - - - >5,那么句柄中对应的索引值分别是 0 4 3 2 1 。
切换了窗口后,其他的操作,包括定义绑定元素、交互,都与之前的操作相同。
selenium爬虫实战案例:获取网页源码
学习了基础之后,我们先做一个简单的爬虫案例:获取网页的源码。
首先解释一下我们为什么要用selenium来做这个实战:当我们使用urllib库的urlopen()函数获取服务器的响应时,由于服务器识别了我们是模拟服务器而非真实服务器,因此返回的数据有大量的缺失,这等价于我们不能使用urllib库获取完整的响应。
于是我们使用下面的代码实现我们想要的效果:
from selenium import webdriver
# 创建浏览器操作对象
path = 'chromedriver.exe'
browser = webdriver.Chrome(path)
# (1) 访问网站,即模拟人的操作,打开浏览器并访问链接,用get()函数:
url = 'https://xxx.com'
browser.get(url)
# (2) page_source获取网页源码:(此时的url是上一步传入的url)
content = browser.page_source
print(content)selenium无界面浏览器的学习
最后简单介绍一下两种无界面浏览器的操作:
之前学的selenium库,是真实打开了浏览器,但是优缺点:速度很慢,有时候我们需要更高速的获得数据或其他事情,因此我们需要了解两种无界面浏览器的操作:
1️⃣ phantomjs
首先,我们需要先下载phantomjs工具,可以点击我的网盘链接下载:phantomjs (提取码:dxzj)
而后,把phantomjs工具放在python文件同级目录下便于后续的导入。
最后,使用下面三行代码,完成phantomjs的导入和浏览器操作对象的创建:
from selenium import webdriver
path = 'phantomjs.exe'
browser = webdriver.PhantomJS(path)上面的三行代码过后,后续的所有操作,都和selenium库的操作相同,因此不需要再做说明,只是此时所有的操作不再会打开浏览器,而且速度十分快(可以自行尝试!)
2️⃣ handless
phantomjs相较于handless,略有过时,现在handless是无界面浏览器的首选:
# selenium_无界面模拟浏览器操作学习之 handless的学习
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# path这里要改成自己的谷歌浏览器的路径:
path = r'C:\Program Files (x86)\Google\Chrome\Application\chrome.exe'
chrome_options.binary_location = path
browser = webdriver.Chrome(chrome_options = chrome_options)上面的部分是handless创建浏览器操作对象的全过程,上面的代码可以直接复制用,唯一修改的地方是path变量需要改成自己的Chrome浏览器的路径。
另外,因为上面的部分对于每一次使用handless都是固定的,我们可以做下面的封装:
def handless_browser():
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# path这里要改成自己的谷歌浏览器的路径:
path = r'C:\Program Files (x86)\Google\Chrome\Application\chrome.exe'
chrome_options.binary_location = path
browser = webdriver.Chrome(chrome_options = chrome_options)
return browser
browser = handless_browser()封装后,每一次我们需要新建handless浏览器操作对象的时候,只需要调用函数,即可完成。
II.VIII scrapy框架的使用介绍
scrapy框架的工作原理介绍
首先介绍一下scrapy框架是什么:
Scrapy是适用于Python的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试
简单的说,scrapy给我们提供了更加简便、高效的爬虫体验,但与此同时它的工作方式和代码与之前学习的urllib库、requests库完全不同,我们需要重新学习。
接下来介绍一下scrapy框架的工作原理:
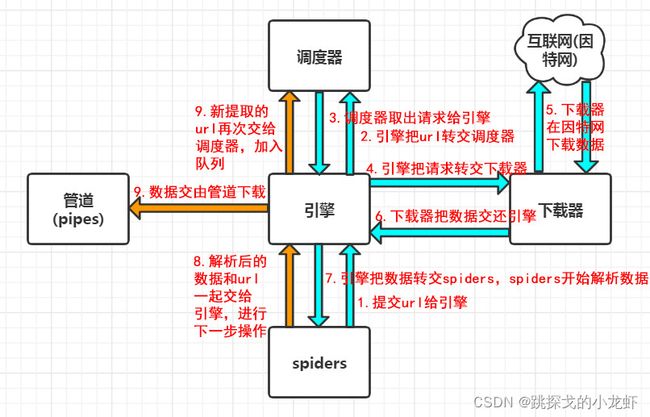
先上一张图,图上表示出了scrapy框架的几个组成部分:
1️⃣ spiders
spiders可以理解为代表了我们人的操作,我们在操作scrapy的时候,实际上就是以spiders的身份在操作,初始的url是我们定义的。
2️⃣ 引擎
引擎是scrapy框架的中枢,从图中可以看出,引擎与所有的其他组件交互,并且交互大多带有指令性的操作,可以理解成一个指挥官。
3️⃣ 调度器
调度器,顾名思义,它是用来做调度的,简单的说就是它会把所有请求的url放入一个队列中,每一次会从队列中取出一个url,这个过程叫做调度。
4️⃣ 下载器
下载器,是用来下载数据的,它下载的是原始数据,可以理解为网页源码,这些源数据通过引擎再次交给我们用户spiders做进一步解析处理。(下载器沟通因特网,数据来源也是因特网)
5️⃣ 管道
管道的工作是下载图片、文件,它的工作与调度器下载源数据不同,它下载的是经过解析后的具体的图片、文件等数据。
最后描述一段scrapy框架的工作过程:
首先,spiders想要在某个url对应的网页下下载图片,于是spiders向引擎递交url,之后引擎把url放入调度器排队;当这个url排到队首的时候,调度器取出这个url请求,交给引擎;这时候引擎把请求给下载器,下载器访问因特网,拿到源数据,交给引擎;引擎再把源数据给spiders。经过这一波操作,源数据被spiders拿到。之后spiders解析数据,并把里面的url和需要下载的数据分离,并一起交给引擎,引擎把url和需下载的数据分别交给调度器和管道,调度器继续重复上述操作,管道下载文件。
scrapy框架的安装
工作过程描述后,我们开始安装scrapy框架:
1️⃣ 首先进入pycharm,选择 File - - - > Settings:
之后选择 project - - - > Python Interpreter:
我们于是知道了python的安装目录。
2️⃣ 进入Python的安装目录:
按Win + R,输入cmd打开终端:

之后输入cd,留一个空格,之后把python安装目录下的Scripts文件夹拖入,生成路径,并回车确认:
3️⃣ 输入安装指令,安装scrapy框架:
pip install scrapy -i https://pypi.douban.com/simple
用scrapy框架搭建并运行第一个项目
安装完成之后,我们开始用scrapy框架搭建第一个项目,要注意的是scrapy框架创建项目不同于平时用pycharm创建项目,它的操作不在pycharm中,而是在终端:
1️⃣ 首先,我们自己选择一个位置,新建一个空的文件夹,命名随意,这里我们创建一个名为scrapy-project的文件夹。
2️⃣ 之后,打开终端,用cd指令进入我们刚才新建的文件夹,方法还是把文件夹拖入cd后光标,自动生成路径:
3️⃣ 输入下面的指令,用scrapy框架生成一个新的项目:
scrapy startproject 项目名称名称任意取,我们这里起名为scrapy_demo1.
4️⃣ 到这里,还差一小步:新建spiders爬虫文件:
上图是我们打开项目文件后在pycharm中看到的结构,上面的结构中,spiders文件夹下,初始只有一个__init__文件,还差一个核心的爬虫文件,这个文件也需要指令生成,但在生成之前,我们需要先用指令进入spiders文件夹,这个文件夹的进入指令是这样的:
cd 项目名称/项目名称/spiders
我们需要cd后 两次输入项目名称中间用一个/隔开,最后加一个/spiders。
终端进入spiders文件夹后,输入下面的指令,生成爬虫文件:
scrapy genspider 爬虫文件的文件名 某个目的url文件名我们任意取,某个目的url我们这里可以用https://www.xxx.com来做演示,名称这里取的是scrapy_xxx。(注意爬虫文件名不能和项目名称一致)。于是我们生成了一个爬虫文件:
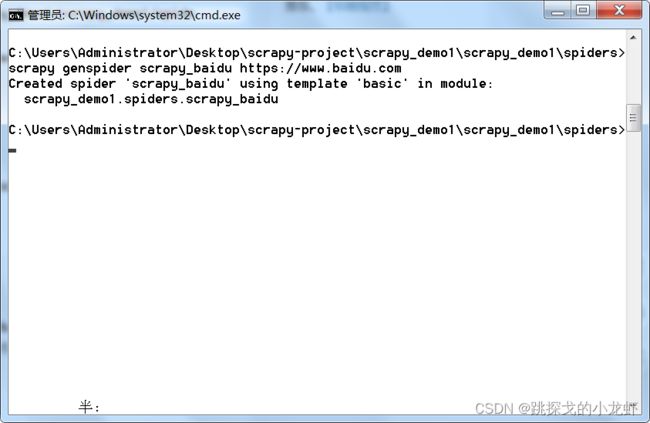
此时我们再次打开pycharm,可以看到这个文件:
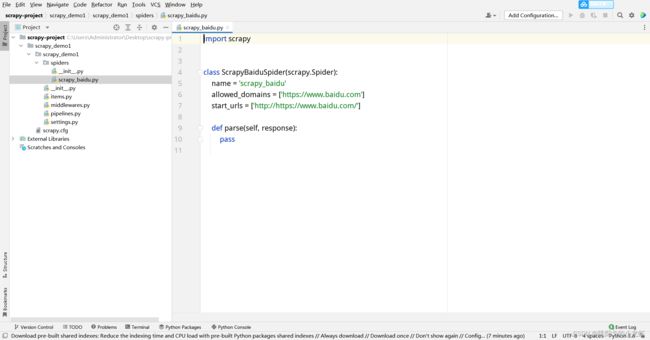
这时候,我们发现里面有一个start_urls和一个allowed_domains,本期篇幅有限,这部分先不介绍,但是我们按照常理思考,start_urls里多了一个http://,我们把http://删去,后面的部分是我们需要的url。
之后,我们打开settings文件,注释掉下面这句话:ROBOTSTXT_OBEY:
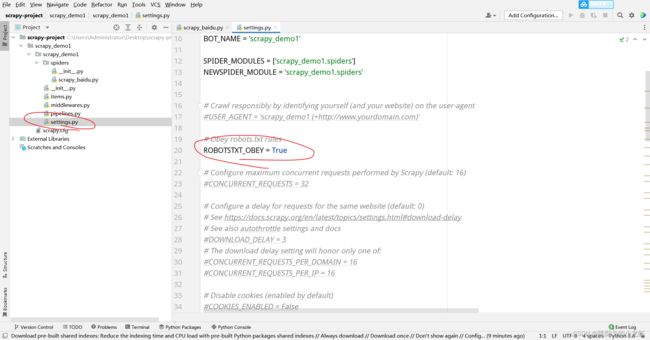
注释的原因本次也不做解释,注释之后,我们可以开始准备运行第一个项目了:
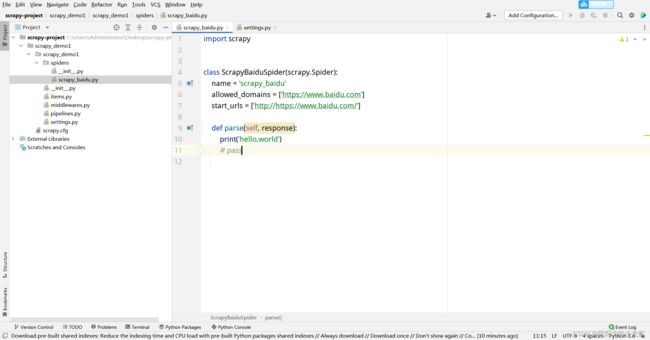
我们再次打开新建的爬虫文件:scrapy_baidu.py,注释掉parse函数下的pass,加上一句print代码,例如这里print一句'hello,scrapy'
最后,我们来运行第一个项目:运行的方式不是点击pycharm的运行按钮,而是在终端输入这句指令:
scrapy crawl scrapy_baidu
最后一个参数是我们的爬虫文件文件名,如果起名不同,需要修改这句指令!
以下是运行结果:
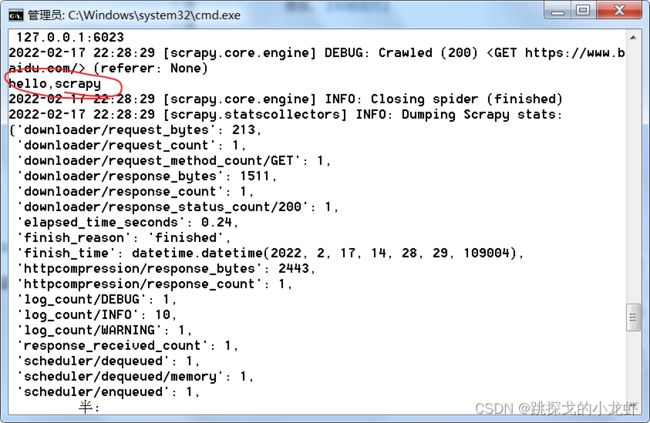
到这里,第一个scrapy项目运行成功!
scrapy框架的项目结构
下面开始学习scrapy框架的项目结构:
首先,我们可以先新建一个scrapy的项目(这里以获取58同 城网页数据为例):
我们先打开终端,cd指令进入上一篇笔记新建的文件夹中(或者任意新建一个空的文件夹也可以),在这个文件夹下,我们运行项目创建指令,创建新的项目:
输入scrapy项目创建指令:
scrapy startproject scrapy_58tc
接下来,跟第一篇笔记相似,我们通过终端进入项目文件夹下的spiders文件夹,并在这里生成我们的爬虫文件:
终端进入spiders文件夹指令:
cd scrapy_58tc/scrapy_58tc/spiders
接下来,在生成爬虫文件之前,我们需要获取目标网页的地址或接口,我们随便打一个url:
https://www.xxx.com终端生成scrapy爬虫文件指令:
scrapy genspider tc https://www.xxx.com
注意,上面的指令运行后,将生成一个名为 tc.py 的爬虫文件。
之后我们用pycharm打开整个项目文件,观察它的项目结构:
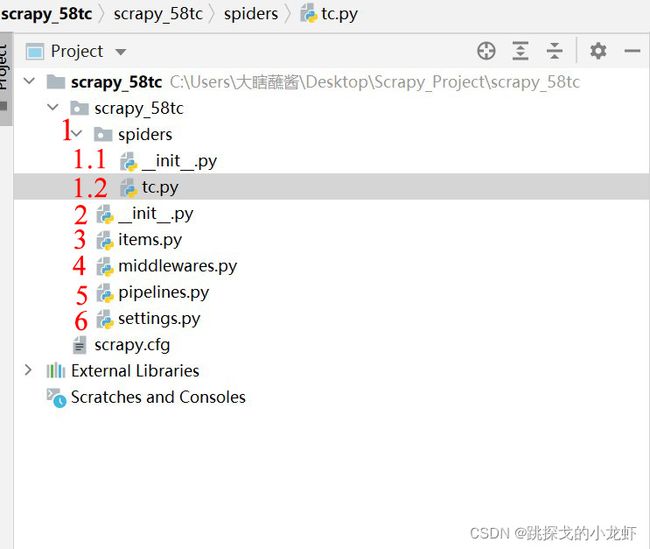
可以大致把项目文件夹下分出六个部分:
1️⃣ Spiders文件夹:这文件夹我们不陌生,因为每一次新建scrapy爬虫项目后,我们都需要终端进入Spiders文件夹,生产爬虫文件。在Spiders文件夹下,又有两个文件,一个是_init_.py文件,一个是tc.py。_init_.py文件是我们创建项目时默认生成的一个py文件,我们用不到这个py文件,因此我们可以忽略它,另一个tc.py文件是我们爬虫的核心文件,后续的大部分代码都会写入这个文件,因此它是至关重要的py文件。
2️⃣_init_.py文件:它和上面提到的Spiders文件夹下的_init_.py一样,都是不被使用的py文件,无需理会。
3️⃣ items.py文件:这文件定义了数据结构,这里的数据结构与算法中的数据结构不同,它指的是爬虫目标数据的数据组成结构,例如我们需要获取目标网页的图片和图片的名称,那么此时我们的数据组成结构就定义为 图片、图片名称。后续会专门安排对scrapy框架定义数据结构的学习。
4️⃣ middleware.py文件:这py文件包含了scrapy项目的一些中间构件,例如代理、请求方式、执行等等,它对于项目来说是重要的,但对于我们爬虫基础学习来说,可以暂时不考虑更改它的内容。
5️⃣ pipelines.py文件:这是我们之前在工作原理中提到的scrapy框架中的管道文件,管道的作用是执行一些文件的下载,例如图片等,后续会安排对scrapy框架管道的学习,那时会专门研究这个py文件。
6️⃣ settings.py文件:这文件是整个scrapy项目的配置文件,里面是很多参数的设置,我们会偶尔设计到修改该文件中的部分参数,例如下一部分提到的ROBOTS协议限制,就需要进入该文件解除该限制,否则将无法实现爬取。
robots协议
接下来介绍一个scrapy框架工作过程中的小知识点:robots协议,首先看看它是什么:
robots协议也叫robots.txt,是一种存放于网站根目录下的ASCII编码的文本文件,它通常告诉网络搜索引擎的漫游器(又称网络蜘蛛),此网站中的哪些内容是不应被搜索引擎的漫游器获取的,哪些是可以被漫游器获取的。
那么简而言之,robots协议就是规定了我们使用爬虫的范围,也被戏称君子协议。
下面我们可以选择打开settings.py文件,把 ROBOTSTXT_OBEY = True 这句代码''解除''注释:
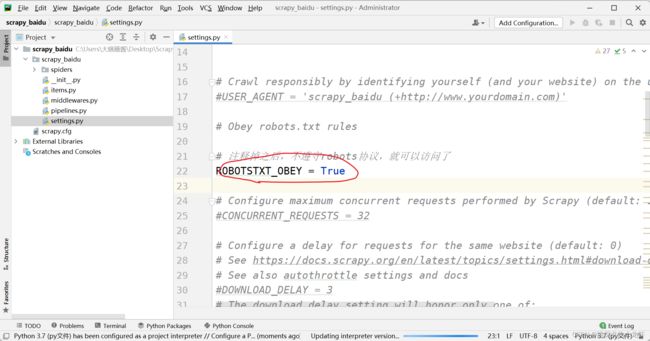
因此,在使用scrapy框架的时候,我们在拿不到数据时,可以考虑是否是robots协议起到了作用,如果是这样,那就把 ROBOTSTXT_OBEY = True 这句代码注释即可!
scrapy框架的基本语法介绍
最后,我们对scrapy框架的基本语法做一个简单的汇总与介绍:
我们回到项目文件中,打开项目文件下的爬虫文件:tc.py:
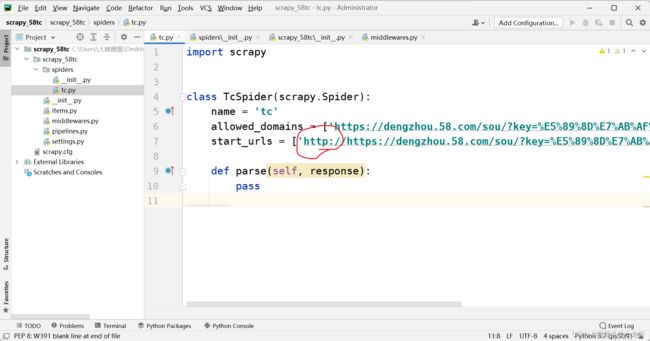
这里,首先我们把额外生产的https协议头去掉,只留下一个https://,即删去红圈内的部分。之后我们可以看到在class中,也即类中,有两个参数:allowed_domains和start_urls,这两个参数有不同的含义:
✳️ allowed_domains:这是scrapy框架中规定爬取的url的范围,简单地说就是,我们只能在这个参数定义的url的范围下获取数据,一旦数据超出范围,那么我们的请求将会失效。
✴️ start_urls:这是scrapy框架起始访问的url,也即在最初向这个url的位置发起请求。
在这个简单的项目中,这两个参数可以是同一个,在后续的项目中,对于两个参数,特别是第一个参数的设置,是有所讲究的。
之后我们的目光聚焦在下面的函数 parse(self,response) 中,这个函数是当我们发起请求成功后的一个回调函数,如果不理解回调函数的不要紧,我们只需要知道,这个函数的触发时机是请求已经被正确处理了。于是我们可以拿到函数的传参:response的值,而这个response的值就是服务器给我们的响应。针对这个response响应,有下面的基础操作:
def parse(self, response):
# (1) response.text属性:获取的是字符串形式的数据
content_str = response.text
print(content_str)
# (2) response.body属性:获取的是二进制形式的数据
content_b = response.body
print("====================")
print(content_b)
# (3) response.xpath()函数可以直接使用xpath解析
# (4) response.extract() 提取selector对象的属性值
# (5) response.extract_first() 提取selector列表的第一个数据
pass可以看到,一共有五个基础的response处理,其中比较重要的是最后三个处理方式:
1️⃣ response.xpath(xpath语句传入):这种方式是对response进行xpath解析,我们在括号内传入xpath语法对应的语句即可,要注意的是,普通的xpath解析,返回的是一个列表,但是在scrapy框架中的xpath解析,返回的是selector对象列表,针对selector对象列表,我们需要进一步的处理,才能真正拿到数据。
2️⃣ response.extract():这种处理,承接了上面的操作,当我们拿到了selector对象列表,通过再执行.extract()函数,即可把selector对象列表转成普通的列表,进而获取数据。
3️⃣ response.extract_first():这是第二种方法的加强版本,可以直接拿到转成的普通列表的第一个元素,在一些情况下更方便。
也就是说,我们通常情况下,拿数据是这样的一句代码:
data = response.xpath(''xpath - - - - -'').extract()/.extract_first()
关于五种response的处理,本文后续的部分进行进一步说明!
scrapy框架管道学习
首先,我们在开始之前,先任意创建一个scrapy框架项目:
打开之前创建过的文件夹,用终端进入这个文件夹(如果之前笔记没有看过的朋友,直接新建一个空文件夹即可,之后用终端进入该文件夹):
运行项目生成指令:
scrapy startproject pipedemo
之后,我们创建对应的爬虫文件:
首先终端进入Spiders文件夹:
cd pipedemo/pipedemo/spiders
运行爬虫文件生成指令:
scrapy genspider demo https://www.xxx其中 demo 是生成的爬虫文件的文件名,大家可以任意起名,url随便打一个即可,因为我们此时并不真正实现下载,而是作为教学使用。
之后我们就完成了项目的创建,接下来我们把目光转向定义“数据结构”:
我们用pycharm打开项目文件,进入到items.py文件:
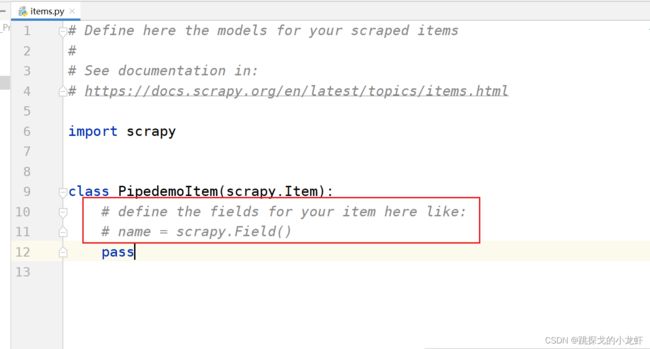
红圈中的注释,其实是告诉我们定义数据结构的语法是怎么样的。我们举一个例子,比如说我们想要下载图片、图片的名字这两项内容,并把图片存成本地的jpg或png格式,图片的名字写入一个json文件中,那么在这里,我们定义数据结构的代码是这样的:
class PipedemoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pic = scrapy.Field()
pic_name = scrapy.Field()
pass可以看出,数据结构的定义代码是很简单的,与注释中的语法完全一致。
下面的部分,我们继续围绕着这个需求去准备:下载图片、图片的名字这两项内容,并把图片存成本地的jpg或png格式,图片的名字写入一个json文件中(多管道同时下载)
解决了数据结构,接下来我们需要封装一下管道:
打开pipelines.py文件:
接下来是一个小知识点:管道的核心代码大部分都在它的名叫 process_item(self,item,spider) 这个函数中。
我们于是锁定这个函数体,第二个小知识点是,process_item(self,item,spider) 函数的传参item,是我们在items.py中定义的数据结构对应的数据,也就是说item本身包含了我们传入的初步数据,回忆scrapy框架的工作原理,管道是对数据的二次处理,所以我们会先在爬虫文件中对数据进行解析,解析后的数据才会放进item中,并传入到process_item(self,item,spider) 函数。
于是这里我们先实现保存图片的名称这一步:
class ScrapyDemoPipeline:
def open_spider(self, sipder):
self.fp = open('pic.json','w',encoding = 'utf-8')
def process_item(self, item, spider):
self.fp.write(str(item))
return item
def close_spider(self,spider):
self.fp.close()解释一下,首先,除了process_item()函数外,open_spider()和close_spider()这两个函数也是常用的、scrapy框架中被定义过的函数,只是它们不会默认生成,需要我们自行书写,同时这两个函数有下面的特点:
open_spider()函数和close_spider()函数分别在项目的启动和终止时各自被调用一次。
有了这个特点,我们可以避免反复打开和关闭文件,而是把打开文件和关闭文件的操作放入这两个函数中,在process_item()函数中执行具体写入操作。
在process_item()中,根据刚才的分析,item应该是已经处理好的数据,那我们只需要直接执行内容写入即可。
下面实现同时下载图片的操作:
所谓同时,指的是我们需要再开启一条管道,与之前的管道同时工作,这在scrapy框架中实现的方法是这样的:
我们复制pipelines.py文件中默认给我们生成的类"ScrapyDemoPipeline",并在类的外面黏贴一份,简单的改一个名字:
新的类,由于执行的是图片的下载,我们无需open和close函数,默认生成的函数足够。最后只需要在process_item()中写入具体的下载代码即可,思路仍然是通过item提供的url,调用urllib库中的urlopen函数执行下载,于是伪代码可以是这样的:
import urllib.request
class ScrapyDemoPipeline2:
def process_item(self, item, spider):
url = str(item)
urllib.request.urlopen(url,'pic_name')
return item上一步,我们封装了管道,那么可能会有一个疑问:我们自己定义的“新管道”,会被执行吗?这里给出肯定的回答:
如果不修改其他的内容,刚才定义的管道,甚至是最开始默认生成的管道,都不会被执行。
于是我们在实现管道下载之前,必须必须必须 要修改settings.py配置文件:
打开settings.py文件,找到被注释的一个字典:ITEM_PIPELINES
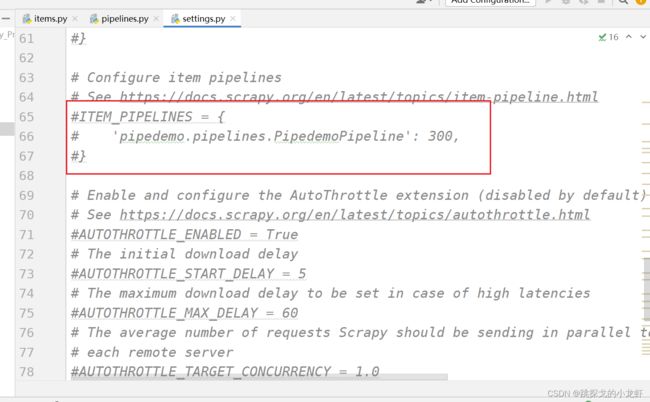
这字典是对默认生成的管道的定义,我们可以发现默认情况下,它是被注释的,于是我们先把它的注释解开,此时默认生成的管道可以工作了。
接下来,我们复制这个字典,黏贴在它的下面,通过观察不难发现,字典里的“键”的部分的最后一截是管道类的类名,于是我们修改类名为我们定义的新管道的类名:
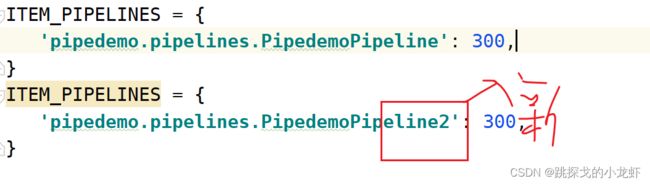
这里对字典的"值"稍作说明:
300,指的是该管道的优先级的大小,这个值在[1,1000]之间,值越小,优先级越高,并且当多个管道同时启用时,该值才有效,我们这里把两个管道都设置为相同优先级即可。
最后一步,我们需要调用管道,开启下载操作。
首先,先想一下为什么需要这步操作:我们回忆一下之前写的scrapy框架项目,会发现每一次我们都是运行的爬虫文件来执行整个项目,也就是说,我们想要使用管道,那么管道必须在爬虫文件中被调用,否则我们封装的管道将失去作用,于是我们转向爬虫文件:demo.py
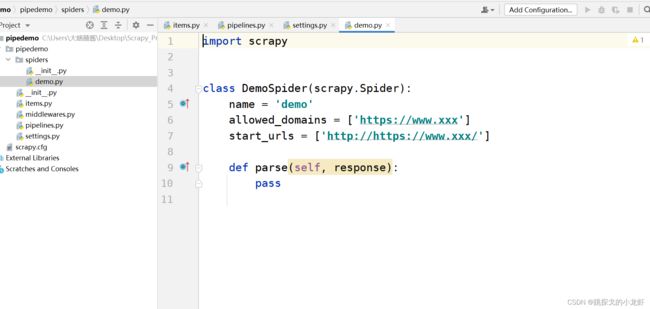
根据之前的经验,我们知道核心代码是写在parse()函数中的,那么我们需要在里面写什么呢:
依照我们前面提到的需求,那么我们需要首先在parse()函数中,提取从服务器发回的响应response,并通过解析response,把合适的数据:图片的url和图片的名称,传给管道,于是伪代码可以这样表示:
def parse(self, response):
pic = response.xpath('...')
pic_name = response.xpath('...')
pass提取数据后,我们传数据到管道之前,还有一小步操作:导入items数据结构:
我们首先再次打开items.py文件,复制一下items.py文件中的类名:
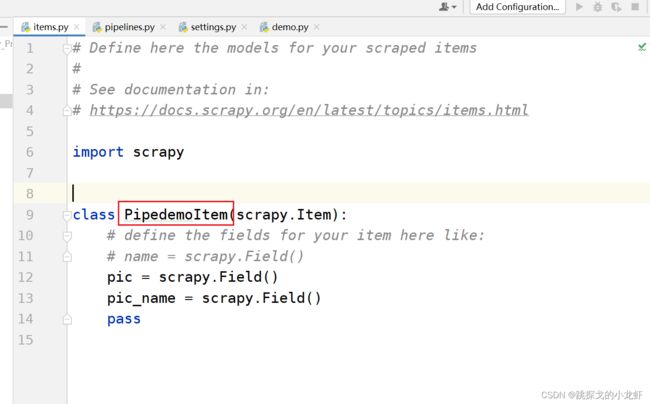
之后回到demo.py文件,在最上面写上导入数据结构的代码:
from pipedemo.items import PipedemoItem这句导入代码的格式是这样的:
from 项目名.items import items文件中的类名
导入数据结构后,我们在传入数据给管道之前,肯定要先定义这个数据,也就是说我们要先定义变量item:
item = PipedemoItem(pic = pic,pic_name = pic_name)我们解释一下传进去的两个参数:pic和pic_name,细心的人应该发现了,这里的pic和pic_name与我们前面在items.py文件中定义的两个数据结构的名字完全一样(因为它们本来就是一回事)。所以我们这里其实是创建了一个对应我们定义的数据结构的对象(面向对象思想)。
最后,我们通过yield关键字,执行item向管道的传入:
yield item没错,只需要一句代码,即可调用管道。那么关于demo.py完整的代码应该是这样的:
import scrapy
from pipedemo.items import PipedemoItem
class DemoSpider(scrapy.Spider):
name = 'demo'
allowed_domains = ['https://www.xxx']
start_urls = ['http://https://www.xxx/']
def parse(self, response):
pic = response.xpath('...')
pic_name = response.xpath('...')
item = PipedemoItem(pic = pic,pic_name = pic_name)
yield item
pass最后,我们再理一下整个的思路:
首先,我们需要定义数据结构
其次,我们需要封装管道
接下来,我们需要在settings配置文件中修改管道配置
最后,我们需要在爬虫文件中完成:响应解析、数据结构对象定义、调用管道
以上是对scrapy框架管道使用的详细介绍。
scrapy框架的日志级别与推荐级别方案
本篇笔记是scrapy框架入门的最后一篇,主要对scrapy框架的日志级别和显示效果进行介绍。
首先,我们任意运行一个之前的scrapy框架项目:
这项目的运行效果是在终端打印'+'号,于是在终端中能看到这样的内容:
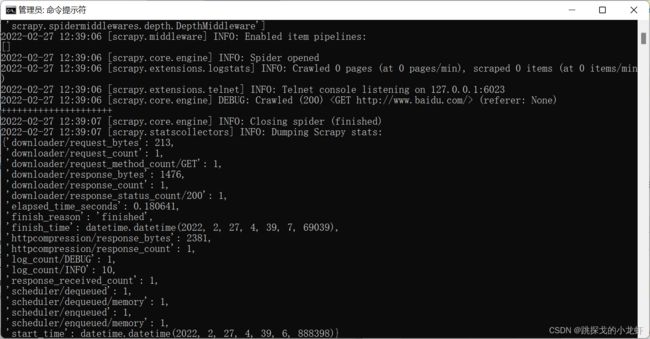
此时终端除了加号之外,其他显示的内容叫做"日志",通俗的讲,就是本次运行的相关信息,这些信息中包含了例如错误信息等重要内容,在我们debug的时候很有作用。
但与此同时,我们在运行的时候,更想看到清爽的结果:只显示一行加号,这时候我们可以通过修改scrapy框架的日志级别来实现。scrapy框架的日志级别有这几种:
| 日志级别 | 中文解释 |
| ERROR | 一般错误 |
| WARNING | 警告 |
| INFO | 一般的信息 |
| DEBUG | 调试信息 |
修改日志级别的位置在settings.py配置文件,它的格式是这样的:
LOG_LEVEL = '对应级别的大写英文'下面我们分别演示四种级别下的显示效果:
1️⃣ ERROR:
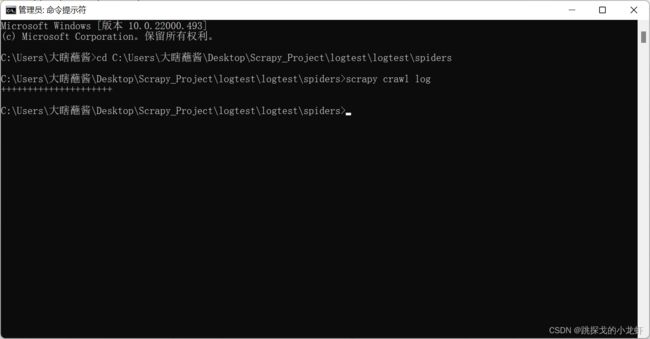
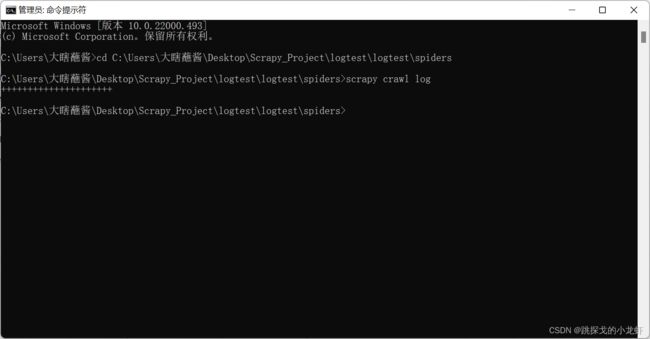
2️⃣ WARNING:
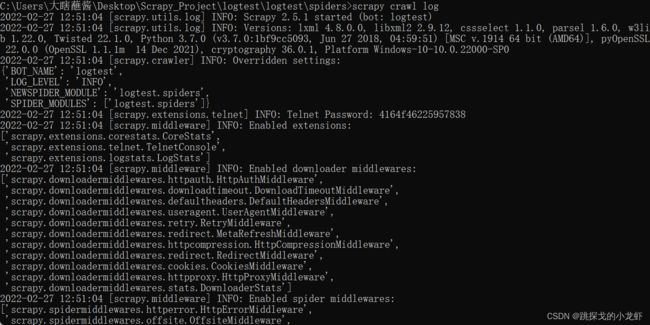
3️⃣ INFO:
4️⃣ DEBUG:
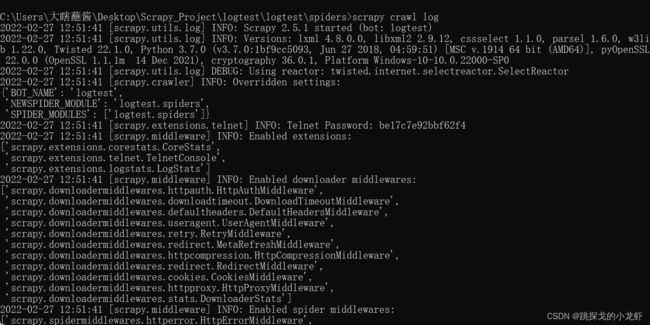
可以看出,越高的日志级别,显示的内容越少,这说明日志级别是向上扩展的,只会显示该级别及以上的日志内容,这时一个自然的结论是我们使用WARNING甚至是ERROR级别是最优的选择。
当我们选择了WARNING或者ERROR级别,存在的一个隐患是我们对于bug的提示信息也会被隐藏,不利于我们debug,于是最优的选择是不添加日志级别,而是添加这样一行代码在settings.py:
LOG_FILE = 'xxxx.log'其中的xxxx我们根据需要自己起一个名字,后缀要保证是log,这样的一句代码,指定了两件事:
首先是不在终端显示日志,即还我们一个清爽的终端显示;
其次是把日志保存在spiders文件夹下的xxxx.log文件中,供我们查看:

因此在scrapy框架开发中,选择把日志写入日志文件,是上上策。
II.IX 爬虫补充内容之Excel文件的读写
安装相关库
首先,我们需要安装一下有关Excel读写的相关库:
我们先创建一个python文件,并打开pycharm,查看一下自己的python解释器的位置:
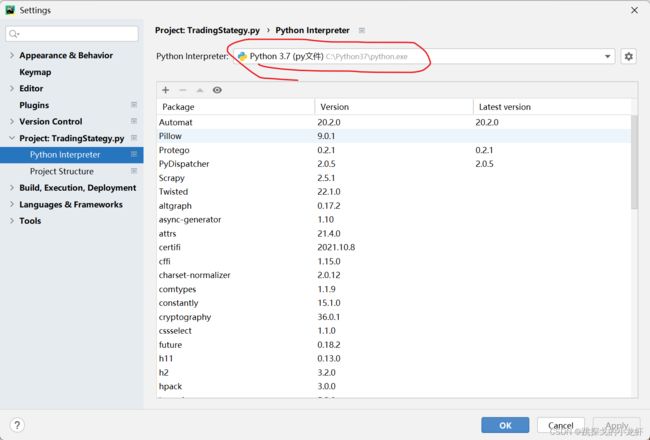
之后,我们进入该路径,找到路径下的scripts文件夹,打开终端,用终端进入该scripts文件夹:
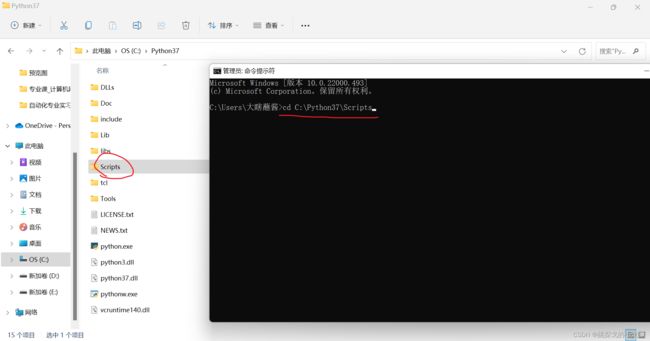
最后,分别执行下面的两句安装指令,安装读和写Excel的库(两个都要执行):
pip install xlrdpip install xlsxwriterExcel文件的读写操作
上面的两个库都安装成功之后,我们按照下面的顺序一点一点的介绍Excel的读写操作,进度不会太快,基础不是很好的朋友的也不需要担心:
1️⃣ 导入两个包:
第一部分,我们先介绍导入包的代码格式:
import xlrd
import xlsxwriter这里要注意一下,两个包的作用是不同的:
xlrd 这个包是当我们需要打开或者读出一个Excel文件时需要依赖的包,我们的写入操作是不需要它的。
xlsxwriter 这个包从拼写就可以看出它是专供写入Excel使用的包。
2️⃣ 创建一张空表:
接下来,我们演示一下如何创建一张新表:
import xlsxwriter
excel_file_writer = xlsxwriter.Workbook(r'./demo.xlsx')
excel_file_writer.close()我们可以发现,表的创建工作只需要xlsxwriter包即可,无关另一个包。它的过程是首先我们新建一个文件操作对象(excel_file_writer),并在创建时传入文件的路径和文件名称(注意后缀只能是"xlsx")。
另外,一定不要忘记最后执行close()函数,否则创建的表不会真正被保存在本地,也就是找不到创建的新表。
执行之后,我们就可以看到一张空表出现在指定的位置:

3️⃣ 向表中写入数据:
我们仍然以面向小白为主,以简单的例子切入。首先我们定义四个变量:
student_name_1 = 'Lobster'
grade_1 = 99
student_name_2 = 'Zhangsan'
grade_2 = 66这四个变量定义之后,我们现在想要把这四个数据放入一张Excel的工作表中,并按照下面的位置摆放:
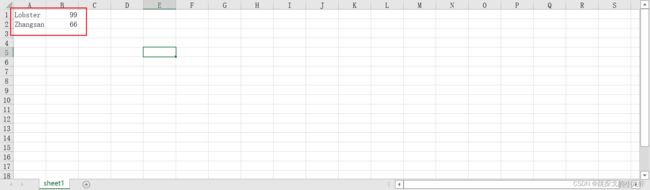
于是这个需求可以类比把大象塞入冰箱一样,先拆分一下,拆成两个动作:
(1) 新建一张工作表
(2) 向这张工作表写入上面的内容
这时候可能对Excel不熟悉的朋友有疑惑了,我们不是已经创建了一个Excel表?有这个疑惑的朋友,我稍作解释:我们新建的是一个Excel文件,一个Excel可以包含多张工作表,我们平时说的Excel表其实就是指的Excel的工作表,它是长这样的:
新建一张Excel工作表,我们需要执行下面这行代码:
excel_worksheet_writer = excel_file_writer.add_worksheet('sheet1')excel_worksheet_writer是我们定义的工作表操作对象,调用excel表操作对象excel_file_writer的add_worksheet()函数,传入的字符串代表我们新建的工作表的名称。
此时我们执行下面的四句代码,完成前面的四个变量的写入:
excel_worksheet_reader.write(0,0,student_name_1)
excel_worksheet_reader.write(0,1,grade_1)
excel_worksheet_reader.write(1,0,student_name_2)
excel_worksheet_reader.write(1,1,grade_2)之所以举例子用四个变量,是想更具体的展示写入函数write()的三个传参的意思:
write(工作表的行数,工作表的列数,写入的数据)
掌握了上面的基础写入操作,我们可以尝试一个爬虫中常用的循环写入列表数据的实例:
import xlsxwriter
excel_file_writer = xlsxwriter.Workbook(r'./demo.xlsx')
excel_worksheet_writer = excel_file.add_worksheet('sheet1')
student_name_list = ['a','b','c','d','e']
grade_list = [60,70,80,90,100]
for i in range(len(student_name_list)):
excel_worksheet_writer.write(i,0,student_name_list[i])
excel_worksheet_writer.write(i,1,grade_list[i])
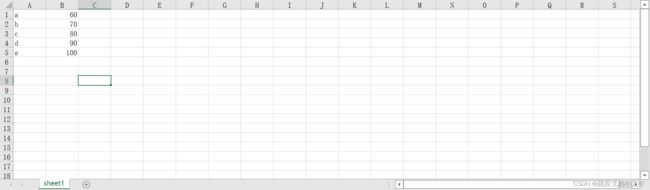
excel_file_writer.close()上面定义了两个列表,在爬虫中,我们很多数据都是列表形式返回,因此上面的例子很具有实战意义,执行之后,我们在Excel表中能看到下面的数据:

4️⃣ 关联已存在的Excel工作表:
我们为了方便起见,直接拿上一步创建的Excel表作为读取的表样例,此时我们待读取的表的名称是"demo.xlsx",它的内容是这样的:
读取的第一步,我们要导入前面提到的作用于读取的一个python库:
import xlrd之后,我们类比写入操作,分析一下不难得出现在应该要创建一个Excel文件操作对象,这个对象关联一张已存在的excel表:
excel_file_reader = xlrd.open_workbook(r'./demo.xlsx')这一步,我们成功的定义了一个Excel文件操作对象,并与我们前面创建的"demo.xlsx"相关联。
接下来,还是参考写入的流程,那么我们要干的事情就又可以拆分成两步:
(1) 创建一个工作表操作对象,关联一张工作表
(2) 向这张工作表写入上面的内容
所以我们通过下面这行代码,实现新建一个工作表操作对象,并关联一张工作表(注意,整个讲述过程中,我有意在区分Excel表和Excel工作表,大家也一定要区分开,如果区分不开的朋友,回看上面的解释):
excel_worksheet_reader = excel_file_reader.sheets()[0]这里注意了,调用了sheets()函数后,后面有一个索引值,这个值代表了关联的是第几张工作表:
第一张表索引值是0,以此类推即可。
下面就剩下把数据读出去了,这又可以做一些简单的细分:
5️⃣ 按整行或整列读取:
下面的代码展示了按照整行/整理读取的方式,其中row_values代表按行读取,col_values代表案列读取:
row = excel_worksheet_reader.row_values(0)
col = excel_worksheet_reader.col_values(0)读取之后,我们打印一下看看它们分别是不是我们想要的结果:

可以看到,它的确分别打印了工作表的第一行和第一列,之后我们可以尝试修改参数为任意的行数、列数,并实现我们需要的任何需求(补充说明:与索引值类似,表的第一行、第一列的索引值也是从0开始的,后面以此类推。)
6️⃣ 读取的一些其他方式简单介绍:
如果是单看上面的内容,其实已经几乎能够满足我们需要的读取操作了,不过作为一篇全面介绍性文章,还是要把一些其他的读取方式进行简单介绍:
(1) 读取某一列的某几行:
col_ = excel_worksheet_reader.col_values(0,0,3)其中,第一个参数代表是第几列,第二个参数表示行的起始索引,第三个参数表示行的终止索引 + 1,也就是说上面这行代码最终读取的是 第0列的第0行至第2行(左闭右开区间)。
(2) 读取某一行的某几列:
row_ = excel_worksheet_reader.row_values(0,0,2)其中,第一个参数代表是第几行,第二个参数表示列的起始索引,第三个参数表示列的终止索引 + 1,也就是说上面这行代码最终读取的是 第0列的第0行至第1行(左闭右开区间)。
下面是上面两行代码的运行结果,大家可以对照上面展示的表内容,证明结果的确是正确的。

(3) 读取某一个单元格的内容:
cell_ = excel_worksheet_reader.cell(1,0).value调用的cell()函数,其中第一个参数代表行数,第二个参数代表了列数(行数和列数唯一确定一个数据),因此上面执行的代码把第1行第0列的数据存入变量cell_中,那么打印的结果应该是:

完整的Excel操作示例代码
最后,附上本次介绍所涉及的完整示例代码:
## 创建Excel表并写入内容部分
import xlsxwriter
excel_file_writer = xlsxwriter.Workbook(r'./demo.xlsx')
excel_worksheet_writer = excel_file_writer.add_worksheet('sheet1')
student_name_list = ['a','b','c','d','e']
grade_list = [60,70,80,90,100]
for i in range(len(student_name_list)):
excel_worksheet_writer.write(i,0,student_name_list[i])
excel_worksheet_writer.write(i,1,grade_list[i])
excel_file_writer.close()
## 读取Excel表的部分
import xlrd
excel_file_reader = xlrd.open_workbook('demo.xlsx')
excel_worksheet_reader = excel_file_reader.sheets()[0]
row = excel_worksheet_reader.row_values(0)
col = excel_worksheet_reader.col_values(0)
for i in row:
print(i)
for j in col:
print(j)
col_ = excel_worksheet_reader.col_values(0,0,3)
row_ = excel_worksheet_reader.row_values(0,0,2)
for i in col_:
print(i)
for j in row_:
print(j)
cell_ = excel_worksheet_reader.cell(1,0).value
print(cell_)Excel读写常见报错解决方案
在运行上面的Excel读取操作(写入应该不会有错误)时,可能会提示下面的错误信息:
File"C:\Python37\lib\site-packages\xlrd\__init__.py", line 170,in open_workbook raise XLRDError(FILE_FORMAT_DESCRIPTIONS[file_format]+'notsupported')xlrd.biffh.XLRDError: Excel xlsx file; not supported
这个错误的原因是安装的xlrd的版本太高,不再支持读取操作,因而解决的方案是卸载原来安装的xlrd,并安装指定版本:1.2.0的xlrd:
1️⃣ 到达之前提到的python解释器的位置,终端进入Scripts文件夹,先运行下面的卸载指令:
pip uninstall xlrd2️⃣ 运行下面这行指令,安装指定版本的xlrd:
pip install xlrd==1.2.0本文的全部内容到此结束啦,如果有帮助,可以三连支持一下博主,你的三连是我更新的动力!