C++ 实现并行计算的K-Means聚类算法
一、介绍
聚类是拥有相同属性的对象或记录的集合,属于无监督学习,K-Means 聚类算法是其中较为简单的聚类算法之一,具有易理解,运算速度快的特点。
1.1 内容
通过本次课程我们将使用 C++ 语言实现一个完整的面向对象的可并行K-Means算法。这里我们一起围绕着算法需求实现各种类,最终打造出一个健壮的程序。所以为了更好地完成这个实验,需要你有 C++ 语言基础,会安装一些常用库,喜欢或愿意学习面向对象的编程思维。
1.2 实验知识点
- C++ 语言语法
- K-Means 算法思路与实现
- 并行计算思路与实现
- boost 库的常用技巧(Smart Pointers,Variant,tokenizer)
1.3 环境
- boost 1.68.0
- mpich 3.2.1
1.4 适合人群
本课程适合有 C++ 语言基础,对聚类算法感兴趣并希望在动手能力上得到提升的同学。
1.5 代码获取
下载本次实验的代码,由于文件较多,我们主要参照下载的代码进行讲解。
$ cd /home/shiyanlou
$ wget http://labfile.oss.aliyuncs.com/courses/1193/MPIK-Means.zip
$ unzip MPIK-Means.zip1.6 效果图
完成时间显示:
- 单进程

- 四进程

输出结果文件:


1.7 项目结构与框架
项目的整个文件目录:
├── clusters
│ ├── distance.hpp
│ └── record.hpp
├── datasets
│ ├── attrinfo.hpp
│ ├── dataset.hpp
│ └── dcattrinfo.hpp
├── mainalgorithm
│ ├── mpikmean.hpp
│ └── mpikmeanmain.cpp
└── utilities
├── datasetreader.hpp
├── exceptions.hpp
├── null.hpp
└── types.hpp这里简单介绍一下功能模块,在具体实践每一个类的时候会有详细UML图或流程图。
主要分为4个模块:实用工具类,数据集类,聚集类,算法类。
-
实用工具类:定义各种需要的数据类型;常用的异常处理;文件读取。
-
数据集类:将文件中的数据通过智能指针建立一个统一数据类,拥有丰富的属性和操作。
-
聚集类:在数据类基础上实现中心簇。
-
算法类:完成对聚集类的初始化,通过算法进行更新迭代,最终实现数据集的聚类并输出聚类结果。
二、实验原理
这一章我们将配置好实验环境并介绍一些基础知识。
2.1 依赖库安装
安装boost和mpich2,安装时间可能会有点久,安装完毕后记得保存实验环境!
mpich2下载(由于配置和编译需要很长的时间,所以我们提供了编译好的安装包,下载然后安装就可以了):
$ cd /home/shiyanlou
$ wget http://labfile.oss.aliyuncs.com/courses/1193/mpich-3.2.1.zip
$ unzip mpich-3.2.1.zip
安装:
$ cd mpich-3.2.1
$ sudo make install
boost下载:
$ wget http://labfile.oss.aliyuncs.com/courses/1193/boost_1_68_0.tar.gz
解压
$ tar xvfz boost_1_68_0.tar.gz
$ cd boost_1_68_0
编译:
$ sh bootstrap.sh
修改 project-config.jam 文件,在第22行后添加一句: using mpi ; 如下图所示,注意添加位置,以及 mpi 和 ; 之间需要一个空格。
安装(此处安装时间比较长约20分钟左右,请耐心等待!):
$ sudo ./bjam --with-program_options --with-mpi install
mpi 支持的进程数和计算机的配置有关,通过cat /proc/cpuinfo |grep "processor"|wc -l命令,可以查看得知实验楼最多支持4个进程。
检验 boost 是否安装成功,可以检测一下,这里我们测试开启3个进程,运行/home/shiyanlou/MPIK-Means/test/mpitest.cpp:
$ cd /home/shiyanlou/MPIK-Means/test
$ mpic++ -o mpitest mpitest.cpp -L/usr/local/lib -lboost_mpi -lboost_serialization
$ mpirun -np 3 ./mpitest若结果如下,有三个Process则证明安装成功!
Process 1: a msg from master
Process 2: a msg from master
Process 2:
Process 1:
Process 0: zero one two
Process 0: zero one two
Process 1: zero one two
Process 2: zero one two2.2 boost的小技巧
2.2.1 Smart Pointers
在 Boost 中,智能指针是存储指向动态分配对象的指针的对象。智能指针非常有用,因为它们确保正确销毁动态分配的对象,即使在异常情况下也是如此。事实上,智能指针被视为拥有指向的对象,因此负责在不再需要时删除对象。Boost 智能指针库提供了六个智能指针类模板。表给出了这些类模板的描述。本实验中将大量使用智能指针。
| 类 | 描述 |
|---|---|
| scoped_ptr | 单个对象的简单唯一所有权,不可复制 |
| scoped_array | 数组的简单唯一所有权,不可复制 |
| shared_ptr | 对象所有权在多个指针之间共享 |
| shared_array | 多个指针共享的数组所有权 |
| weak_ptr | shared_ptr 拥有的对象的非拥有观察者 |
| intrusive_ptr | 具有嵌入引用计数的对象的共享所有权 |
表1 智能指针类型简介
2.2.2 Variant versus Any
Boost
variant类模板是一个安全通用的联合容器,和std::vector不同,std::vector是储存单个类型的多个值,variant可以储存多个类型的单个值,本实验中将使用variant储存双精度和整数类型来表示不同类型的数据。
与 variant 一样,Boost any 是另一个异构容器。虽然 Boost any 有许多与 Boost variant 相同的功能。
根据 Boost 库文档,Boost variant 比 Boost any 具有以下优势:
-
variant 保证其内容的类型是用户指定的有限类型集之一。
-
variant 提供对其内容的编译时检查访问。
-
variant 通过提供有效的、基于堆栈的存储方案,可以避免动态分配的开销。
同样 Boost any 也有一些优势:
-
any 几乎允许任何类型的内容。
-
很少使用模板元编程技术。
-
any 对交换操作提供安全的不抛出异常保证。
2.2.3 Tokenizer
Tokenizer 提供了一种灵活而简单的方法通过分割符(如:",")将一个完整的string分隔开。
字符串为:”A flexible,easy tokenizer“
如果通过","分割,则结果为:
[A flexible] [ easy tokenizer]
以" " 为分隔符,分割结果为:
[A] [flexible,] [easy] [tokenizer]
三、数据集的构建
接下来将具体实践各个类,会给出每一个类的声明并解释其成员函数和数据成员以及相关联类之间的继承关系和逻辑关系。涉及到重要的成员函数的实现会给出其定义代码,一些普通的成员函数的源码可以到下载的源文件中查看,里面也会有详细的注解。
数据对于一个聚类算法来说非常重要,在这里我们将一个数据集描述为一个记录(record),一个记录由一些属性(Attribute)表征。因此自然而然将依次建立 attributes,records,最后是数据集 datasets。
在此之前我们需要了解一下我们在聚类中实际接触到的数据类型。 这里有一个示例心脏数据集
//heart.data
70.0,1.0,4.0,130.0,322.0,0.0,2.0,109.0,0.0,2.4,2.0,3.0,3.0,2
67.0,0.0,3.0,115.0,564.0,0.0,2.0,160.0,0.0,1.6,2.0,0.0,7.0,1
57.0,1.0,2.0,124.0,261.0,0.0,0.0,141.0,0.0,0.3,1.0,0.0,7.0,2
64.0,1.0,4.0,128.0,263.0,0.0,0.0,105.0,1.0,0.2,2.0,1.0,7.0,1
74.0,0.0,2.0,120.0,269.0,0.0,2.0,121.0,1.0,0.2,1.0,1.0,3.0,1
65.0,1.0,4.0,120.0,177.0,0.0,0.0,140.0,0.0,0.4,1.0,0.0,7.0,1
......包含13个属性,age,sex,chest pain type(4 values),resting blood pressure......
为了更好地表述不同数据相同属性的差异,我们需要对这些数据进行离散/连续处理,即对于有些数据我们认为它是连续的如:年龄;有些是离散的如:性别。这样我们建立一个描述数据类型的文件:
//heart.names
schema file for heart.dat
///: schema
1, Continuous
2, Discrete
3, Discrete
4, Continuous
5, Continuous
6, Discrete
7, Discrete
8, Continuous
9, Discrete
10, Continuous
11, Discrete
12, Continuous
13, Discrete
14, Class3.1 AttrValue类
AttrValue 类有一个私有变量,有两个友元函数,一个公有成员函数。 _value是一个 variant 类型变量,它可以存储一个双精度或无符号整形的数据,分类数据用无符号整形数据表示。
AttrValue类自身无法存储或获取数据。它的两个友元函数可以获取和修改数据_value。

//MPIK-Means:datasets/attrinfo.hpp
class AttrValue
{
public:
friend class DAttrInfo;//友元函数可以访问_value
friend class CAttrInfo;//友元函数可以访问_value
typedef boost::variant value_type;//可存储双精度和无符号整形数据
AttrValue();
private:
value_type _value;
};
inline AttrValue::AttrValue(): _value(Null()) {
}//构造函数,将_value初始化为Null(定义在utillities/null.hpp中) 3.2 AttrInfo类
AttrInfo 是一个基类,包括了许多虚函数和纯虚函数。这些函数都将在它的派生类中具体实现,基类中仅进行声明和简单定义。
//MPIK-Means:datasets/attrinfo.hpp
//三种数据类型:未知型,连续型(双精度),离散型(无符号整形)
enum AttrType
{
Unknow,
Continuous,
Discrete
};
class DAttrInfo;
class CAttrInfo;
class AttrInfo
{
public:
AttrInfo(const std::string &name,AttrType type);//每一栏的属性名(id,attr,label,...)和该属性的数据类型(离散或连续)
virtual ~AttrInfo(){}//虚析构函数
std::string &name();//返回标签
AttrType type() const;//返回数据类型
virtual Real distance(const AttrValue&,const AttrValue&) const = 0;
virtual void set_d_val(AttrValue&, Size) const;//AttrValue赋值;适用于DAttrInfo
virtual Size get_d_val(const AttrValue&) const;//获取_value
virtual void set_c_val(AttrValue&, Real) const;//AttrValue赋值;适用于CAttrInfo
virtual Real get_c_val(const AttrValue&) const;//获取_value
virtual bool can_cast_to_d() const;//布尔值,对于DAttrInfo类来说其返回值为true,相反为false.在基类的声明中全部初始化为false.
virtual bool can_cast_to_c() const;
virtual DAttrInfo& cast_to_d();//返回DAttrInfo本身
virtual bool is_unknown(const AttrValue&) const = 0;
virtual void set_unknown(AttrValue&) const = 0;
private:
std::string _name;
AttrType _type;
};3.3 CAttrInfo 类和 DAttrInfo 类
CAttrInfo 主要是用来表示连续型数据的一些属性和方法。有两个数据成员:_min和_max。表示最小值和最大值属性,在初始化时都将设置为Null。
这两个属性将在归一化的时候用到。CAttrInfo 将会继承 AttrInfo 的一些函数,并且重新定义。
//MPIK-Means:datasets/dcattrinfo.hpp
class CAttrInfo: public AttrInfo
{
public:
CAttrInfo(const std::string& name);//构造函数
Real distance(const AttrValue&,const AttrValue&)const;//两个距离
void set_c_val(AttrValue &, Real) const;
void set_min(Real);//设置最小值
void set_max(Real);//设置最大值
Real get_min() const;//获取最小值
Real get_max() const;//获取最大值
Real get_c_val(const AttrValue&) const;
bool is_unknown(const AttrValue&) const;
bool can_cast_to_c() const;
void set_unknown(AttrValue&) const;
protected:
Real _min;
Real _max;
};
CAttrInfo::CAttrInfo(const std::string& name)
: AttrInfo(name, Continuous) {
_min = Null();
_max = Null();
} DAttrInfo 类有一个私有变量_values,它是一个string类型的 vector,用来存储一些离散的字符串。在 DAttrInfo 对象中所有的离散值都将由字符串转化为唯一的无符号整形。
//MPIK-Means:datasets/dcattrinfo.hpp
class DAttrInfo: public AttrInfo //继承AttrInfo
{
public:
DAttrInfo(const std::string& name);//构造函数,传入属性字符串
const std::string& int_to_str(Size i) const;
Size num_values() const;//获取长度
Size get_d_val(const AttrValue&) const; //接口定义
void set_d_val(AttrValue& , Size)const;//接口定义
Size add_value(const std::string&,
bool bAllowDuplicate = true);//将一组离散值加入到_values中,比如“X,X,Y,Z",
//则values=[X,Y,Z],对应的二进制数字为[0,0,1,2]
//对于属性值,则可以重复,但对于id则具有唯一性,不能重复
DAttrInfo& cast_to_d();
Real distance(const AttrValue&, const AttrValue&) const; //比较两个离散型变量的距离
bool is_unknown(const AttrValue& av) const;//值有缺省
bool can_cast_to_d() const;
void set_unknown(AttrValue&) const;
protected:
std::vector _values;
}; add_value 是一个将字符串转化为无符号整形数据的重要函数,返回值为该字符所表示的整形,并将为出现的字符添加进_values。
| Record | Attribute | AttrValue |
|---|---|---|
| 1 | "A" | 0 |
| 2 | "B" | 1 |
| 3 | "A" | 0 |
| 4 | "C" | 2 |
| 5 | "B" | 1 |
| Record | Attribute |
|---|---|
| 0 | "A" |
| 1 | "B" |
| 2 | "C" |
表2 DAttrInfo 的一个具体实例
通过上面表格中我们可以看到一组字符类型的数据被存储为该字符串所在的 index,如果该字符串第一次出现则为上一个字符串的 index+1。这样相同的字符串都被转化为唯一的无符号整形。_value 这个辅助变量可以帮助实现这一功能。
//MPIK-Means:datasets/dcattrinfo.hpp
Size DAttrInfo::add_value(const std::string& s,
bool bAllowDuplicate) {
Size ind = Null();
//如果该字符串已经出现,则返回该字符串在_values中的index
for(Size i=0;i<_values.size();++i) {
if(_values[i] == s) {
ind = i;
break;
}
}
//如果未出现,则返回_values的大小-1.
//同时对于不允许重复字符串的数据,如ID,当出现重复字符串时则会错误提示.
if(ind == Null()) {
_values.push_back(s);
return _values.size()-1;
} else {
if(bAllowDuplicate) {
return ind;
} else {
FAIL("value "<();
}
}
} 这里需要看一下 distance 这个函数的定义,它返回的是一个双精度类型数值。如果传入的两个数据类型为 Unknow 则返回为 0.0,其中一个 Unknow 则为 1.0,对于两个双精度类型的数据返回其差值。
//MPIK-Means:datasets/dcattrinfo.hpp
Real CAttrInfo::distance(const AttrValue& av1,const AttrValue& av2) const {
if(is_unknown(av1) && is_unknown(av2)){
return 0.0;
}
if(is_unknown(av1) ^ is_unknown(av2)){
return 1.0;
}
return boost::get(av1._value) -
boost::get(av2._value);
} 对于离散型数据,两个离散数据之间的距离定义也会不同,这里主要是考虑到离散型数据都转化为相差为1的整形,所以只要两个 DAttrInfo 的值不同则距离就为 1.0,所以在含有离散型和连续型数据的混合数据中,连续型数据要进行归一化处理以满足量纲统一。
//MPIK-Means:datasets/dcattrinfo.hpp
Real DAttrInfo::distance(const AttrValue& av1,
const AttrValue& av2) const {
if(is_unknown(av1) && is_unknown(av2)) {
return 0.0; //如果两个值都有缺省,则距离为0
}
if(is_unknown(av1) ^ is_unknown(av2)) {
return 1.0;//如果有一个值缺省,距离为1
}
if(boost::get(av1._value) ==
boost::get(av2._value) ) {
return 0.0;//如果两个值相等,则无差距
} else {
return 1.0;//否则为最大距离1
}
} 3.4 Container 类
Container 类是一个基类模板,有一个 vector 的数据成员_data。add 函数可以将T类型的数据添加进_data,同样 erase 可以删除数据。[]是一个操作符重载,返回索引i对应的数据。
//MPIK-Means:clusters/record.hpp
template
class Container//基类模板
{
public:
typedef typename std::vector::iterator iterator;
iterator begin();
iterator end();
void erase(const T& val);
void add(const T&val);//将val添加到向量中
Size size() const; //返回_data的长度
T& operator[](Size i);//下标索引,建立Schema与data的关系
protected:
~Container(){}
std::vector_data;
}; Record 和 Schema 是继承 Container 类的两个重要的类,它们之间的关系如下:
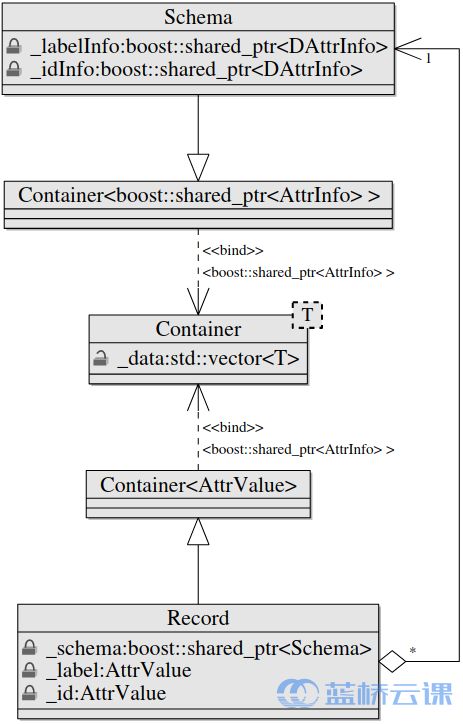
3.5 Schema 类
Schema 有两个保护数据成员_labelInfo,_idInfo,和一个继承父类的成员_data,_data是一个元素为 AttrInfo 的 vector,表示每一个数据的属性(离散/连续)。_labelInfo是一个指向 DattrInfo 的共享指针,其包含了输入数据的分类情况。
Schema 的目的是为一个 Record 对象设置 label 和 id。set_id 和 set_label 函数是为了实现此功能,但是它们又依赖于 Record ,所以我们在 Record 类中具体定义。
//MPIK-Means:clusters/record.hpp
class Record;
class Schema:public Container >
{
public:
const boost::shared_ptr& labelInfo() const;//标签信息,整形
const boost::shared_ptr& idInfo() const;//id信息,整形
boost::shared_ptr& idInfo();//可以修改成员变量,_labelInfo
boost::shared_ptr& labelInfo();//可以修改成员变量,_idInfo
void set_label(const boost::shared_ptr& r,const std::string& val);
//设置记录的label
void set_id(boost::shared_ptr& r,const std::string& val);
//设置记录的id
protected:
boost::shared_ptr _labelInfo;
boost::shared_ptr _idInfo;
};
3.6 Record类
Record 继承带参数 AttrValue 的模板类 Container,有四个私有数据成员_label,_data,id和_schema。_data继承自父类。每一个 Record 类都有一个指向 Schema 类的共享指针,可以将类型为 AttrValue 的数据储存在_data中,同样每一个 record 都有一个 label 和 id。Record 的构造函数需要传入一个指向 Schema 的共享指针,并将_data的长度设置为与_schema一样,将_data里的值设置为默认值。我们就可以通过 Schema 来操控 Record,因为 Schema 的_data类型为 AttrInfo 有很多函数如 add,set_c_val,add_value 等函数可以对离散/类型数据进行操作。所以 Record 和 Schema 的关系为通过 Schema 定义了每一条数据的规范(label,id,每一条属性的类型),然后按照这个规范将数据填充到 record 中,因为 record 直接接触的类型是 AttrValue。
//MPIK-Means:clusters/record.hpp
class Record:public Container
{
public:
Record(const boost::shared_ptr& schema);//构造函数
const boost::shared_ptr& schema() const;
const AttrValue& labelValue() const;
const AttrValue& idValue() const;
AttrValue& labelValue();
AttrValue& idValue();
Size get_id() const;
Size get_label() const;
private:
boost::shared_ptr _schema;//通过_schema创建记录
AttrValue _label;
AttrValue _id;
};
3.7 dataset类
上面已经实现了一条数据的储存就是一个 Record,我们最终需要 n 条数据。这里新定义一个类 Dataset。很明显按照上面的思路,Record 依赖Schema,则 Dataset 依赖 Record。
所以 Dataset 类继承类型为 Record 的 Container。因为最后我们使用的 Dataset 类,我们需要用到的一些属性可以在这里直接给出。num_attr() 返回属性的个数,is_numeric() 判断该列属性值是否是连续行(对于Kmeans算法这里需要连续型数据),为了更加方便的获取每一个数据,使用操作符重载。
//MPIK-Means:datasets/dataset.hpp
inline const AttrValue& Dataset::operator()(Size i, Size j) const {
return (*_data[i])[j];
}
//MPIK-Means:datasets/dataset.hpp
class Dataset:public Container >
{
public:
Dataset(const boost::shared_ptr&);//构造函数,传入含有属性值的schema
Size num_attr() const;//返回属性个数
const boost::shared_ptr &schema() const;//返回_schrma
const AttrValue& operator()(Size i, Size j) const;//返回第i条第j个属性的值
std::vector get_CM() const;
bool is_numeric() const;
bool is_categorical() const;
protected:
boost::shared_ptr _schema;
};
四、创建一个数据实例
前面关于如何构建 dataset 相关类已经花了很多时间,下面就让我们实际操作如何创建一个具体的 dataset。
假设我们有这样的一组数据:
| ID | Attr1 | Attr2 | Attr3 | Label |
|---|---|---|---|---|
| r1 | 1.2 | A | -0.5 | 1 |
| r2 | -2.1 | B | 1.5 | 2 |
| r3 | 1.5 | A | -0.1 | 1 |
表3 数据实例
那么我们如何将以上数据用我们的 dataset 类来表示呢?
//MPIK-Means:test/datasettest.cpp
#include"../clusters/record.hpp"
#include "../datasets/dataset.hpp"
#include
#include
#include
using namespace std;
int main()
{
boost::shared_ptr schema(new Schema);
boost::shared_ptr labelInfo(new DAttrInfo("Label"));
boost::shared_ptridInfo(new DAttrInfo("id"));
schema->labelInfo() = labelInfo;
schema->idInfo() = idInfo;
stringstream ss;
boost::shared_ptr ai;
for(Size j=0;j<3;++j)
{
ss.str("");
ss<<"Attr"<(new CAttrInfo(ss.str()));
}
else{
ai = boost::shared_ptr(new DAttrInfo(ss.str()));
}
schema->add(ai);
}
boost::shared_ptr ds(new Dataset(schema));
Size val;
boost::shared_ptr r;
r = boost::shared_ptr(new Record(schema));
schema->set_id(r,"r1");
schema->set_label(r,"1");
(*schema)[0]->set_c_val((*r)[0],1.2);
val = (*schema)[1]->cast_to_d().add_value("A");
(*schema)[1]->set_d_val((*r)[1],val);
(*schema)[2]->set_c_val((*r)[2],-0.5);
ds->add(r);
r = boost::shared_ptr(new Record(schema));
schema->set_id(r, "r2");
schema->set_label(r, "2");
(*schema)[0]->set_c_val((*r)[0], -2.1);
val = (*schema)[1]->cast_to_d().add_value("B");
(*schema)[1]->set_d_val((*r)[1], val);
(*schema)[2]->set_c_val((*r)[2], 1.5);
ds->add(r);
r = boost::shared_ptr(new Record(schema));
schema->set_id(r, "r3");
schema->set_label(r, "1");
(*schema)[0]->set_c_val((*r)[0], 1.5);
val = (*schema)[1]->cast_to_d().add_value("A");
(*schema)[1]->set_d_val((*r)[1], val);
(*schema)[2]->set_c_val((*r)[2], -0.1);
ds->add(r);
cout<<"Data: \n";
cout<num_attr(); ++j) {
stringstream ss;
ss<<"Attr("<size(); ++i) {
cout<get_id();
for(Size j=0; jnum_attr(); ++j) {
if((*schema)[j]->can_cast_to_c()) {
cout<get_c_val((*ds)(i,j));
} else {
cout<get_d_val((*ds)(i,j));
}
}
cout<get_label()< 输出结果与我们预想的一样:
Data:
RecordID Attr(1) Attr(2) Attr(3) Label
0 1.2 0 -0.5 0
1 -2.1 1 1.5 1
2 1.5 0 -0.1 0
五、构建簇
构建簇的目的就是为了将 dataset 中的 record 进行重新组合,所以我们定义一个基类 Cluster 直接接触 Record,有一个数据成员 id。
//MPIK-Means:clusters/record.hpp
class Cluster:public Container >
{
public:
virtual ~Cluster() {}
void set_id(Size id);
Size get_id() const;
protected:
Size _id;
};
inline void Cluster::set_id(Size id) {
_id = id;
}
inline Size Cluster::get_id() const {
return _id;
}
定义一个中心簇,来表示一个簇的中心。中心簇只有一个数据成员_center即表示中心簇的指向 Record 的共享指针。
//MPIK-Means:clusters/record.hpp
class CenterCluster : public Cluster
{
public:
CenterCluster(){}
CenterCluster(const boost::shared_ptr& center);//构造函数传入一个record
const boost::shared_ptr& center() const;//返回中心点的record,不可更改
protected:
boost::shared_ptr_center; //成员变量,中心点的record
};
CenterCluster::CenterCluster(const boost::shared_ptr& center):_center(center){}
const boost::shared_ptr& CenterCluster::center()
const {
return _center;
}
为了实现更多丰富的功能,我们需要再定义一个类 PClustering。
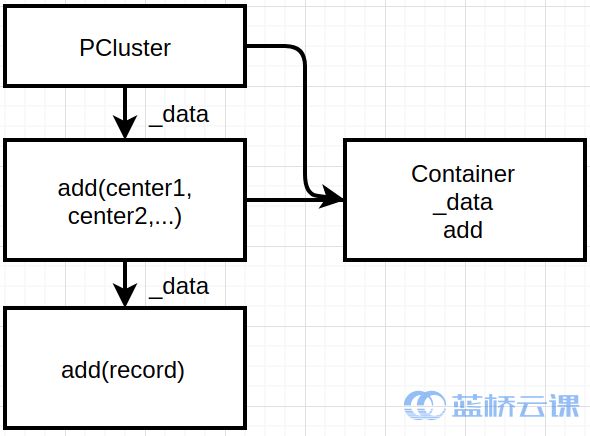
PClustering 继承 Container,通过 add 函数添加了中心簇 Center。Center 也拥有 add 函数,它添加属于和它同一簇的 record,每一个 record 都有自己的 id 信息。这样我们就能通过 PClustering 储存聚类信息。PClustering 的一个数据成员为_CM,是用来储存每一条 record 的所属聚类。如:[1,1,1,2,2,2],同一簇拥有相同的数值。calculate 函数是用来从_data中提取相关聚类信息,然后更新_CM。
//MPIK-Means:clusters/record.hpp
class PClustering:public Container >
{
public:
PClustering();//构造函数
friend std::ostream& operator<<(std::ostream& os,
PClustering& pc);//操作符重载,输出聚类结构相关信息
void removeEmptyClusters();//移除空的record
void createClusterID();//创建聚类id
void save(const std::string& filename);//保存聚类结果相关信息至文件
private:
void print(std::ostream &os);//打印聚类结果相关信息
void calculate();//更新_CM和_CMGiven
void crosstab();//将一些聚类结果储存为交叉表
bool _bCalculated;/如果数据文件没有标签信息,则不需要计算_numclustGiven
Size _numclust;//聚类数
Size _numclustGiven;//文件提供的label数
std::vector _clustsize;//记录每一簇的数据量
std::vector _clustLabel;//记录原文件中的每个分类的数量
std::vector _CM;//每一条记录数据的所属index
std::vector _CMGiven;//原文件每一条记录所属标签
iiiMapB _crosstab;//交叉表储存数据
};
这里我们介绍一个模板键-值映射类 nnmap(utilities/nnmap.hpp),在这里我们用来储存聚类和原标签的数量信息。如有6条数据,计算的_CM为[1,1,2,2,2,3],所给标签为[0,0,1,1,2,2]。我们需要通过下面_crosstab填充下面的表格:
Cluster ID 1 2 3
0 # # #
1 # # #
2 # # #
_crosstab(1,0)表示聚类为1,标签为0的数量。通过下面的函数,可以为2。同理_crosstab(2,0)=0,_crosstab(3,0) = 0.最终可以打印交叉表:
Cluster ID 1 2 3
0 2 0 0
1 0 2 0
2 0 1 1
如果以标签信息为准的话,则(2,2)那个信息有误,每一行只能有一个数据占据,且不能与之前有相同的列。
//MPIK-Means:clusters/record.hpp
void PClustering::crosstab() {
Size c1, c2;
for(Size i=0; i<_CM.size();++i) {
c1 = _CM[i];
c2 = _CMGiven[i];
if (_crosstab.contain_key(c1,c2)) {
_crosstab(c1,c2) += 1;
} else {
_crosstab.add_item(c1,c2,1);
}
}
}
六、K-Means 算法
算法思路
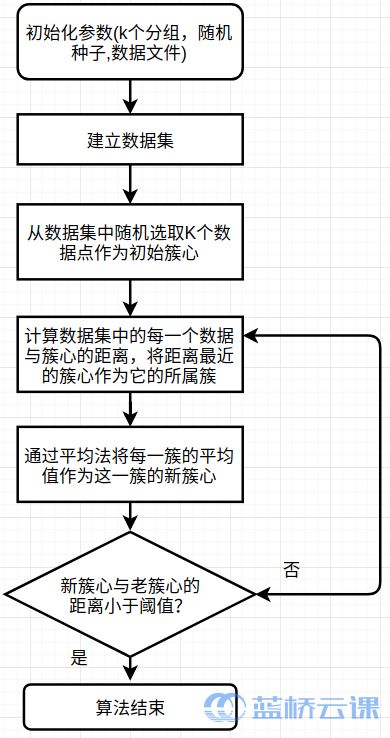
在代码实现中我们还会有一个多次运行循环的结构,这样的目的是通过多次的随机初始化确保能够消除一些极端的情况,最后取这些循环中最好的结果输出.
并行化思路
我们使用一种序列 - 均值算法的思路。即计算所有记录 n 和所有中心之间的距离。p 个进程,让每一个参与计算的进程处理 n/p 条数据。主要步骤如下:
(a)主进程:读取数据文件,并将数据块发送至每一个进程。
(b)主进程:初始化簇中心,并将这些簇中心发送至每一个进程。
(c)所有进程:计算所给数据块与簇中心的距离,并将这些数据块归属到与它距离最近的中心。
(d)所有进程:更新新的簇中心。
(e)所有进程:重复(c)和(d)直至满足停止条件。
(f)主进程:收集聚类结果。
6.1 MPIKmean 类
将所有的中心簇的数据编码成一个向量_clusters,这样可以很方便从第一个进程发送至其它进程。同样_data表示所有的数据的值。
//MPIK-Means:mainalgorithm/mpikmean.hpp
class MPIKmean
{
public:
Arguments& getArguments();//获取初始参数
const Results& getResults() const;//获取结果_CM
void reset() const;//清除结果
void clusterize();//执行计算(初始化,更新,迭代,...)
protected:
void setupArguments();//设置初始参数
void fetchResults() const;//获取结果
virtual void initialization() const;//随机初始中心簇
virtual void iteration() const;//迭代更新
virtual Real dist(Size i, Size j) const;//返回与中心簇的距离
mutable vector _centers;//中心簇的属性值
mutable vector _data;//数据值
mutable Size _numObj;//分发给每一个进程的数据量
mutable Size _numAttr;//数据属性量
mutable vector _CM;//数据的所属簇index
mutable vector >
_clusters;//中心簇
mutable Real _error;//簇之间的总距离
mutable Size _numiter;//迭代次数
mutable Results _results;//结果
boost::shared_ptr _ds;//dataset
Arguments _arguments;
Size _numclust;//聚类数目
Size _maxiter;//最大迭代数目
Size _seed;//种子
boost::mpi::communicator _world;//mpi通信
};
主进程负责初始化中心簇(4-33行),一旦中心簇被初始化,就会将中心簇(_centers)和每个进程的数据的数目(_numRecords)和属性数(_numAttr)发送给所有进程(34-36行).
一旦这些数据被进程接收到,每个进程就会划分自己的数据块数量和剩余量(37-38行)。首先主进程会将第一个数据块分配给自己(40-49行),剩余的数据通过send函数发送给其它进程(51-63行)。其它进程通过recv进行接收数据(67行)。
//MPIK-Means:mainalgorithm/mpikmean.hpp
void MPIKmean::initialization() const {
Size numRecords;
Size rank = _world.rank();
if (rank == 0) {//第4行
numRecords = _ds->size();
_numAttr = _ds->num_attr();
_centers.resize(_numclust * _numAttr);
vector index(numRecords,0);
for(Size i=0;i schema = _ds->schema();
boost::minstd_rand generator(_seed);
for(Size i=0;i<_numclust;++i){
boost::uniform_int<> uni_dist(0,numRecords-i-1);
boost::variate_generator >
uni(generator,uni_dist);
Integer r = uni();
boost::shared_ptr cr = boost::shared_ptr
(new Record(*(*_ds)[r]));
boost::shared_ptr c =
boost::shared_ptr(
new CenterCluster(cr));
c->set_id(i);
_clusters.push_back(c);
for(Size j=0; j<_numAttr; ++j) {
_centers[i*_numAttr + j] =
(*schema)[j]->get_c_val((*_ds)(r,j));
}
index.erase(index.begin()+r);
}
} //第33行
boost::mpi::broadcast(_world, _centers, 0);//第34行
boost::mpi::broadcast(_world, numRecords, 0);
boost::mpi::broadcast(_world, _numAttr, 0);//第36行
Size nDiv = numRecords / _world.size();//第37行
Size nRem = numRecords % _world.size();//第38行
if(rank == 0) {
boost::shared_ptr schema = _ds->schema();//第40行
_numObj = (nRem >0) ? nDiv+1: nDiv;
_data.resize(_numObj * _numAttr);
_CM.resize(_numObj);
for(Size i=0; i<_numObj; ++i) {
for(Size j=0; j<_numAttr; ++j) {
_data[i*_numAttr +j] =
(*schema)[j]->get_c_val((*_ds)(i, j));
}
}//第49行
Size nCount = _numObj;
for(Size p=1; p<_world.size(); ++p) {//第51行
Size s = (p< nRem) ? nDiv +1 : nDiv;
vector dv(s*_numAttr);
for(Size i=0; iget_c_val(
(*_ds)(i+nCount,j));
}
}
nCount += s;
_world.send(p, 0, dv);
}//第63行
} else {
_numObj = (rank < nRem) ? nDiv+1: nDiv;
_CM.resize(_numObj);
_world.recv(0,0,_data);
}
}
进行初始化之后,就开始迭代中心簇。
首先定义一个单元素的vector来控制循环(2行)。在while循环内,定义三个局部变量nChangedLocal,newCenters,newSize。每一个进程将会处理自己的数据块与每一个中心簇的距离(11-30行)。变量newCenters包含了一个聚类中所有数据的和。newSize包含了一个聚类中的数据的数量。一旦所有的数据通过并行处理完毕。all_reduce方法将会对所有的进程的数据进行收集,如
all_reduce(_world, nChangedLocal, nChanged,vplus());
对所有进程中的 nChangedLocal 进行相加(通过操作符 vplus,具体见源文件定义),只有有一个进程的 nChangedLocal>0 (中心簇未收敛)则nChange都会>0,整个迭代都会继续进行(31-36行),在对这些数据进行收集之后会更新_center(37-41行)。
收敛之后,所有进程会将聚类的index_CM发送给主进程。主进程会将自己的_CM添加进去就形成了整个数据集的_CM(47-58行)。
//MPIK-Means:mainalgorithm/mpikmean.hpp
void MPIKmean::iteration() const {
vector nChanged(1,1);//初始化nChanged,表示中心簇是否有变化.//第2行
_numiter = 1;//初始迭代次数
while(nChanged[0] > 0) {
nChanged[0] = 0;
Size s;
Real dMin,dDist;
vector nChangedLocal(1,0);
vector newCenters(_numclust*_numAttr,0.0);
vector newSize(_numclust,0);
for(Size i=0;i<_numObj;++i) {//第11行
dMin = MAX_REAL;
for(Size k=0;k<_numclust;++k) {
dDist = dist(i, k);
if (dMin > dDist) {
dMin = dDist;
s = k;
}
}
for(Size j=0; j<_numAttr; ++j) {
newCenters[s*_numAttr+j] +=
_data[i*_numAttr+j];
}
newSize[s] +=1;
if (_CM[i] != s){
_CM[i] = s;
nChangedLocal[0]++;
}
}//第30行
all_reduce(_world, nChangedLocal, nChanged,
vplus());//第31行
all_reduce(_world, newCenters, _centers,
vplus());
vector totalSize(_numclust,0);
all_reduce(_world, newSize, totalSize, vplus());//第36行
for(Size k=0; k<_numclust; ++k) {//第37行
for(Size j=0; j<_numAttr; ++j) {
_centers[k*_numAttr+j] /= totalSize[k];
}
}//第41行
++_numiter;
if (_numiter > _maxiter){
break;
}
}
if(_world.rank() > 0) {//第47行
_world.send(0,0,_CM);
} else {
for(Size p=1; p<_world.size(); ++p) {
vector msg;
_world.recv(p,0,msg);
for(Size j=0; j 其它几个函数的定义就不再赘述,相信通过看源文件 /home/shiyanlou/MPIK-Means 一定可以看懂。
6.2 主函数
从前面建立数据集,到构建簇类,编写一些辅助类到算法的实现。最后我们将具体对一个文件数据进行聚类。
代码如下:
//MPIK-Means:mainalgorithm/mpikmeanmain.cpp
#include
#include
#include
#include
#include
#include
#include
#include "mpikmean.hpp"
#include "../utilities/datasetreader.hpp"
using namespace std;
using namespace boost::program_options;
namespace mpi=boost::mpi;
int main(int ac, char* av[]){
try{
mpi::environment env(ac, av);
mpi::communicator world;
options_description desc("Allowed options");
desc.add_options()
("help", "produce help message")
("datafile", value(), "the data file")
("k", value()->default_value(3),
"number of clusters")
("seed", value()->default_value(1),
"seed used to choose random initial centers")
("maxiter", value()->default_value(100),
"maximum number of iterations")
("numrun", value()->default_value(1),
"number of runs");
variables_map vm;
store(parse_command_line(ac, av, desc), vm);
notify(vm);
if (vm.count("help") || ac==1) {
cout << desc << "\n";
return 1;
}
Size numclust = vm["k"].as();
Size maxiter = vm["maxiter"].as();
Size numrun = vm["numrun"].as();
Size seed = vm["seed"].as();
string datafile;
if (vm.count("datafile")) {
datafile = vm["datafile"].as();
} else {
cout << "Please provide a data file\n";
return 1;
}
boost::shared_ptr ds;
if (world.rank() ==0) {
DatasetReader reader(datafile);
reader.fill(ds);
}
boost::timer t;
t.restart();
Results Res;
Real avgiter = 0.0;
Real avgerror = 0.0;
Real dMin = MAX_REAL;
Real error;
for(Size i=1; i<=numrun; ++i) {
MPIKmean ca;
Arguments &Arg = ca.getArguments();
Arg.ds = ds;
Arg.insert("numclust", numclust);
Arg.insert("maxiter", maxiter);
Arg.insert("seed", seed);
if (numrun == 1) {
Arg.additional["seed"] = seed;
} else {
Arg.additional["seed"] = i;
}
ca.clusterize();
if(world.rank() == 0) {
const Results &tmp = ca.getResults();
avgiter +=
boost::any_cast(tmp.get("numiter"));
error = boost::any_cast(tmp.get("error"));
avgerror += error;
if (error < dMin) {
dMin = error;
Res = tmp;
}
}
}
double seconds = t.elapsed();
if(world.rank() == 0) {
avgiter /= numrun;
avgerror /= numrun;
std::cout<<"completed in "<(Res.get("pc"));
std::cout< 编译:
$ cd /home/shiyanlou/MPIK-Means/mainalgorithm
$ mpic++ -o mpikmean mpikmeanmain.cpp -L/usr/local/lib -lboost_program_options -lboost_mpi -lboost_serialization
运行时需要传入一些参数:datafile(文件路径),k(聚类数目),seed(随机初始化种子),maxiter(最大迭代次数),numrun(运行次数)。除了datafile之外其它参数在主函数中均有默认值。下面我们进行一个15000条数据的20聚类,执行5次。
运行:
$ cd /home/shiyanlou/MPIK-Means/mainalgorithm
$ mpirun -np 4 ./mpikmean --datafile=../testdata/15000points.csv --k=20 --numrun=5
6.3 结果分析
运行结果分两部分,一部分位于终端显示,包括运行时间和聚类结果交叉表。还有一个输出文件,和读取的数据文件处于同一目录,也就是MPIK-Means/testdata,这里生成的是具体的聚类结果文件。
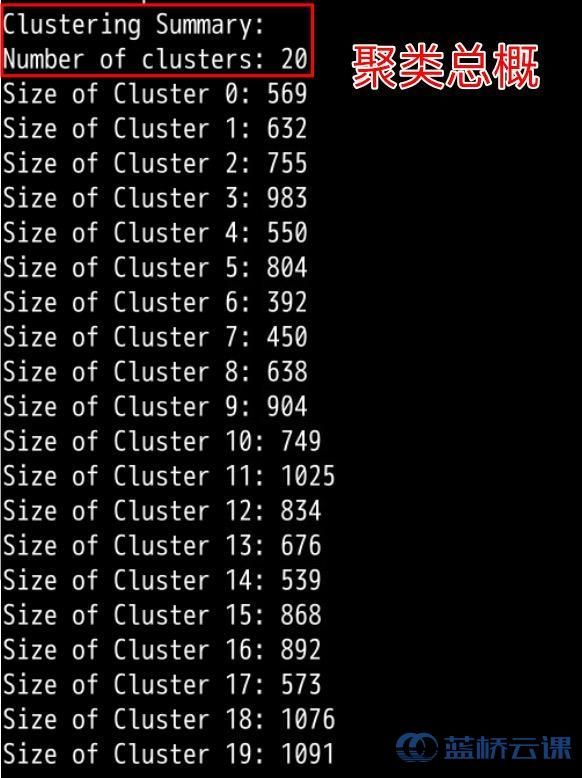


输出结果文件的组成为 读入数据文件名+kmean+k聚类数+s初始随机种子值。实验中就会生成名称类似于15000points-kmean-k20-s1.txt的文件。它表示的是,读入文件为15000points.data,算法是kmean,聚类数为20,随机种子为1。
使用多进程之后,总体时间可以分为两部分:计算时间+进程之间进行数据传输数据时间。如果后者时间大于前者,那么多进程的效率会不如单进程。所以为了体现多进程的效果,这里我们将分类数目k设置的比较大,这样的目的是为了让计算时间超过进程数据传输时间。
可以自己实验比较不同的 聚类数目 和不同的 进程数 带来的效率变化。可以发现运行效率和进程数之间并没有出现倍数的关系。这是因为单进程和多进程的运行时间组成不一样,不同的数据时间占比也不一样,希望这一点大家可以理解。
对于小数据集,I/O操作的开销与数据计算开销相差无几,多进程没有明显优势。对于大数据集,多分类,I/O操作开销会小于数据计算的时间,这时候多进程会带来效率上的提升。
七、总结
到此,我们的 K-Means 算法的实验就结束了。由于考虑到整个内容的繁杂度,有很多小的细节可能没有拿出来细讲,如果小伙伴对有些地方没有弄懂,希望自己能够继续从源码中寻找答案。虽然我们最后只实现了一个简单的聚类算法,但前面介绍的关于构建聚类数据集却具有一定的通用性,对于其它聚类算法也很适用,如果小伙伴愿意尝试其它聚类算法,也可以按照此思路进行改写。并行处理是一种技巧,如果使用恰当,能够给计算效率带来很大的提升,本例的并行处理思路同样可以推广到其它算法当中。
感谢你能够看到最后,希望你有所收获!