【论文解读】Learning to Deceive with Attention-Based Explanations 注意力机制作为模型的可解释性存疑
Learning to Deceive with Attention-Based Explanations
这是一篇发表于ACL2020的关于注意力机制用作模型可解释性的论文。
原文:[link](https://arxiv.org/pdf/1909.07913.pdf)
原文下载
目录
- Learning to Deceive with Attention-Based Explanations
- 前言
- 一、引言
- 二、模型
-
- 1.符号设置与掩码的定义
- 2.变种损失函数
-
- 单层注意力与多头注意力
- 变种多头注意力
- 三、实验
-
- 分类实验
-
- 数据集
-
- 职业分类
- 基于代词的性别认同
- 带干扰句的情感分析
- 研究生推荐信
- 汇总
- Example
- 用到的分类模型
-
- Embedding + Attention
- BiLSTM + Attention
- BERT Models
- 分类实验结果
- 人类研究
-
- 研究结果
- seq2seq 任务
-
- 序列任务
- 机器翻译(英德)
- Seq2seq 中使用的模型
- seq2seq实验结果
- 四、总结
前言
一直以来我们都习惯解释注意力机制的权重为这个 token 的重要性显示,比如一个 embedding 对应的注意力权重大,那么我们就会说他和 query 的关系更相关。本文就阐述说我们在解释注意力分数作为模型内部工作过程或者输入 tokens 重要性的时候要小心一点。首先,作者证明注意力分数很容易被操作(/更改),通过增加一个惩罚项于训练对象。在不显著影响预测的情况下,人们可以轻松地操纵注意力,这表明,即使一个普通模型的注意力权重赋予了一些洞察力(这仍然是一个开放而模糊的问题),这些洞察力也将依赖于知道模型所训练的准确目标。第二,研究者们通常忽略注意力机制基于最后的层级表示而不是每个 word 的事实,这些表示通常包括邻近单词的信息。
注意力机制分数并没有我们认为的那样那么的反映了一个 token 的重要性。
一、引言
一般来说人们总结注意力机制的好处主要有两点:
1、提高预测准确度
2、注意力权重经常被认为提供了可解释性。
作者通过演示一种简单的方法来训练模型来产生欺骗性的注意面具,从而对第二种注意机制的使用优点提出质疑。
作者的方法减少了分配给指定的不允许令牌的总权重,即使模型可以被证明仍然依赖于这些特征来驱动预测。在多个模型和任务中,作者的方法在控制注意力权重的同时,在精确度方面付出的代价少得令人惊讶。通过一项人类研究,作者表明,被操纵的基于注意力的解释欺骗了人们,让他们认为一个对性别少数群体有偏见的模型做出的预测并不依赖于性别。因此,我们的结果让人怀疑,在公平和负责任的背景下,注意力作为审计算法的工具的可靠性。
二、模型
1.符号设置与掩码的定义
给定一个单词序列:S=W1,W2,…Wn 表示一个长度为n的单词序列。
假设对于每个任务给定一个不允许令牌集
定义一个长度为n的二进制向量掩码m,使得
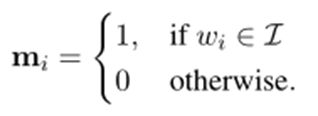
此外,设![]()
表示模型分配给单词序列S中的每个单词的注意力。并且满足:![]()
也就是说一个长度为n的序列的注意力的总和为1。
2.变种损失函数
单层注意力与多头注意力
对于任一特定于任务的损失函数 ![]()
我们定义了一个新的目标函数 ![]() 其中R是一个附加惩罚项,其目的是惩罚将注意力分配到不允许的单词的模型。
其中R是一个附加惩罚项,其目的是惩罚将注意力分配到不允许的单词的模型。
对于不同的注意力使用方式有不同的R的设置:

变种多头注意力
当一个模型有很多注意头时,审核员可能不会查看分配给某些单词的平均注意,而是会并排查看以了解其中是否有大量注意力分配给不允许的单词。预期到这一点,我们还探索了一种处理多头注意力的方法的变体,其中我们惩罚了对不允许的单词(在所有头中)给予的最大注意量,如下所示R的表示:

三、实验
分类实验
本文使用四种分类任务,下面是对应的分类数据集和对应的不允许词集:
数据集
职业分类
我们使用De-Arteaga等人收集的传记。研究职业分类模型中针对性别少数群体的偏见。我们完成了 从多类职业预测设置中区分外科医生和非外科医生的二分类任务。
我们选择此子任务是因为两个行业的传记使用相似的词,并且数据集中的大多数外科医生(> 80%)是男性。我们进一步将少数族裔类别(女性外科医生和男性医师)降低了十倍,以鼓励模型使用与性别相关的标记。原始模型在任务上的准确率达到96.4%,而当传记中的性别代词匿名时则降低到93.8%。
因此,这些模型(在未匿名数据上训练)利用性别指标来获得更高的任务绩效。
因此,我们认为性别指标是这项任务不允许的标记。
基于代词的性别认同
我们从Wikipedia构造了由传记组成的数据集,在其中,我们仅根据性别代词的存在就自动将传记标记为性别(男女)。为此,我们使用预先指定的性别代词列表。不含性别代词或涵盖这两个类别的代词的传记都将被丢弃。创建此数据集的基本原理是,由于创建数据集的方式不同,如果模型使用代词的信息,则达到100%的分类精度是轻而易举的。但是,如果没有代词,可能无法达到完美的准确性。
带干扰句的情感分析
我们使用Stanford Sentiment Treebank(SST)的二进制版本
包含10,564条电影评论。
然后从一组Wikipedia页面的开头句子中为每个评论添加
一个随机选择的“干扰因素”句子。
在此,在不依赖于SST句子中的标记的情况下,
模型不应胜过随机猜测
研究生推荐信
我们获得了一个为研究生课程录取目的而写的推荐信的数据集。
任务是预测写这封信的学生是否被录取。
这些信件包括招生委员会成员所依赖的学生排名和导师标记的 百分位数分数。
事实上,除了推荐信之外,当使用等级和百分位数特征时,
我们注意到准确率有所提高。因此,
我们将百分位和等级标签(附加在字母文本的末尾)视为不允许的标记。
汇总
不同数据集和其对应的不允许词集以及分类目标

Example
数据集例子和不允许词集的占比

用到的分类模型
Embedding + Attention
注意力直接放在单词嵌入上。通过加权和(其中权重是关注度分数)聚合单词嵌入以形成上下文向量,该上下文向量然后被馈送到线性层,随后是Softmax以执行预测。对于我们所有的实验,我们使用点积注意力,其中查询向量是一个可学习的权重向量。在此模型中,在计算注意力值之前,允许和不允许的令牌之间不存在交互。嵌入维度大小为128(n)。
BiLSTM + Attention
具有注意力机制的单层双向LSTM模型,随后进行线性变换和Softmax来执行分类。嵌入维度和隐藏维度都设置为128。
BERT Models
使用由12个层组成的基本版本,并且具有自注意力的机制。每个自注意力层都包含12个关注头。每个序列的第一个标记是特殊分类标记[CLS],其最终隐藏状态用于分类任务。为了阻止信息流从可允许的令牌到不可允许的令牌,我们在每一层上将注意力权重乘以自注意掩码M,即大小为n×n的二进制矩阵,其中n为输入序列的大小。元素Mij表示Wi是否和Wj在同一集合内。此外,[CLS]令牌会处理所有令牌,但没有令牌会处理[CLS],以阻止 和 之间的信息流。我们试图将注意力从[CLS]令牌转移到其他令牌,并考虑两种变体一个是我们操纵所有人的最大注意力,另一个是我们操纵平均注意力。
BERT Models 注意力流向图

分类实验结果

各种分类模型的准确性及其在不允许的词集 I上的注意力质量(A.M.)以及损失系数λ的变化值。每个模型类的第一行表示删除/匿名化任务的不允许标记I的情况。对于大多数模型和任务,我们可以在保持原始性能的同时严重减少对不允许的令牌的关注质量(λ= 0表示不进行任何操作)。
人类研究
我们向三名人类受试者呈现了一系列来自BiLSTM模型的输入和输出,训练来预测职业(内科或外科医生),并给出一本简短的介绍。我们根据三种不同方案的注意分数来突出输入标记:
(I)原始点积注意,
(Ii)Wiegreffe和Pinter(2019年)的对抗注意力机制
(Iii)我们提出的注意操纵策略。
(Q1):你认为这个预测受到个人性别的影响吗?(每种方案50个例子)
(Q2) 您认为突出显示的记号有多大程度是驱动模型预测的因素?他们在1到4的范围内回答了这个问题,其中1表示突出显示的记号不决定模型的预测,而4表示它们显著地决定了模型的预测。
我们故意询问参与者一次(接近尾声)基于注意力的解释的可信度,以作为对比。
研究结果

我们评估了注释者之间的一致,并计算出Fleiss’Kappa为0.97,表明几乎完全一致。
seq2seq 任务
序列任务
**双星 翻转(Bigram Flipping)
{w1, w2. . . w2n−1, w2n} → {w2, w1, . . . w2n, w2n−1})
序列拷贝
{w1,w2,….wn-1,wn} -> {w1,w2,….wn-1,wn}
序列反转
{w1, w2. . . wn−1, wn} → {wn, wn−1. . . w2, w1}
**
对于任何给定的目标令牌,我们都准确地知道负责的输入令牌。因此,对于这些任务,黄金对齐在我们的设置中充当不允许的令牌(每个输出令牌不同)。对于这三个任务中的每一个,我们都以编程方式生成100K随机输入训练序列(及其对应的目标序列),长度最长为32。
机器翻译(英德)
Multi30K(数据集)
由于无法实现目标词与源词的比对的黄金目标,因此我们依靠快速对准工具包(Dyer等人,2013)将目标词与源词对准。我们将这些对齐的单词用作不允许的标记。
输入和输出词汇表固定为1000个唯一标记。对于二元语法翻转任务,输入长度被限制为偶数。我们使用两组来自相同分布的100K可用的随机序列作为验证和测试集‘
Seq2seq 中使用的模型
对于所有seq2seq任务,我们使用Encoder-Decoder体系结构。我们的编码器是双向GRU,我们的解码器是单向GRU,在每个解码时间步长上都对源令牌使用点积注意力。我们还进行了
(i)无注意力的消融研究,即仅使用最后一个(或首先)编码器的隐藏状态
(ii)统一注意力,即所有源令牌均经过统一加权。
seq2seq实验结果

说明:序列到序列模型的性能及其在不允许的令牌I上的关注质量(A.M.),具有不同的丢失系数λ值。与分类任务类似,我们可以在保持原始性能的同时,大大减少对不允许的令牌的关注量。所有值均是五次运行的平均值。
四、总结
在将注意力得分视为模型关注重点的实践中,我们发现注意力得分很容易被操纵。我们的简单训练方案产生的模型与先验已知的记号相比显著降低了注意力质量,以便在继续使用它们的同时对预测有用。我们的结果引发了人们对注意力可能被用作审计算法的工具的担忧,因为恶意研究者/开发者可能会使用类似的技术来误导监管机构。