小 T 导读:在欧圣达的物联网智能设备平台项目中,需支持数百万以上物联网表具和智能终端的接入管理,支持分布式部署且具备良好扩展性。在规则引擎场景下,TDengine 提供了很好的查询和存储性能,成为本项目实现实时告警和监控服务的重要一环。本篇文章分享了欧圣达在数据库调研和搭建阶段的思考和经验,供参考。

公司简介
哈工欧圣达是深圳市欧圣达科技有限公司和哈工大机器人集团的合资公司,总公司深圳市欧圣达科技有限公司成立于 2010 年 5 月,总部位于深圳,下设合肥研发中心、华东分公司(合肥)和西南分公司(成都)。公司始终致力于燃气、供热等公共事业领域的智慧化解决方案研发和应用推广,拥有超过 10 余项自主知识产权的、基于 5G/NB-IoT 和大数据的“一体化平台+智能安全终端”智慧燃气解决方案,作为核心成员参与制定并发布 2019、2020 年 5G 智慧燃气行业标准。
某燃气公司拟建设一套物联网智能设备平台来满足各类物联网设备接入以及数据的采集、存储、分析、展示等各类需求,项目需包括数据采集模块、数据分析模块、监控告警模块、预付费实时结算模块、API 接口模块、大屏\地图显示模块、后台管理模块、手机 App 功能模块。
该平台的搭建目的是为了取代各燃气表厂原有的数据接收服务器,实现对各表厂物联网表具(含 FSK、GFSK、LoRa、GPRS、4G、5G、NB-IoT 等技术标准)读数、压力、温度、监控报警、气价调整、系统参数设置等远传控制和管理。系统需支持数百万以上物联网表具和智能终端的接入管理, 1 秒内瞬时并发连接数不低于 5 万,系统支持分布式部署,且具备良好的扩展性,能够根据业务需要,灵活的扩展系统性能和接入能力。
一、选型调研
以上是典型的时序物联网场景,因此我们调研了国外的主流时序数据库 InfluxDB,但考虑到国家基础设施建设安全,我们最终把目光投向了国产开源数据库 TDengine。我们结合业务数据量对 TDengine 进行了数百万设备的压测,满足本项目的数据存储和性能要求。具体测试结果如下:
从测试结果来看,TDengine 的整体硬件消耗资源比较低,且能满足数百万设备的并发写入。此外相比 MongoDB,其压缩率可以提升至 1/10 – 1/20,也为我们节约了大量存储成本。最有吸引力的一点是 TDengine 具有完善的开源社区生态,不仅支持集群版部署,更有完善的中国服务团队及多元化的服务模式,可以做到实时响应。
二、业务架构部署
在具体搭建上,我们将不同厂家、不同型号设备定义为产品,不同产品的通信机制、上报数据项、指令内容、上报频次都是不同的,我们使用 TDengine 对不同产品创建对应的超级表,使用设备 ID 创建子表。
技术架构图如下图所示:
具体路径上,传感器数据经过 MQ 缓存、结构化解析后进入到 TDengine,供后续业务进行查询使用。规则引擎根据已有的规则参数,进行传感器数据订阅,实时判断传感器是否触发了报警规则,从而实现项目的实时监控和报警需求。同时,规则引擎还会根据传感器数据,触发对应的指令操作(如恢复服务、暂停服务指令),通过 MQ 异步传达给传感器。TDengine 在规则引擎场景下,提供了很好的查询性能,是实现实时告警和监控服务的重要一环。
建模思路
在本项目中,每种设备的协议及上报数据参数都是不同的,我们将公共属性(如所属公司、所属分公司、所属厂家、是否预付费等)作为超级表 tags,将共有参数(如阀门状态、最新读数、抄表时间、温度、压力、电量、信号强度等)作为普通列,通信时间戳+时间漂移作为 TDengine 主键,其他非共有参数(如一些设备会上报瞬时工况流量、一些会上报抄表模块电池电量等)作为子表字段。以本项目的其中一张表作为示例,结构如下:
show create stable device_meter_record\G;
create table device_meter_record (receive_time TIMESTAMP,meter_readnum DOUBLE,meter_balance INT,meter_volume DOUBLE,meter_time TIMESTAMP,meter_temperature DOUBLE,meter_pressure DOUBLE,meter_instantflow DOUBLE,cust_num BINARY(50),cust_name BINARY(255),company_id BINARY(32),subcompany_id BINARY(32),readingteam_id BINARY(32),subreadingteam_id BINARY(32),area_id BINARY(32),community_id BINARY(32),building_id BINARY(32),user_type BINARY(20),is_holiday BOOL,supplier_id BINARY(32),supplier_device_code BINARY(20),platform_balance INT,platform_last_reading DOUBLE,platform_last_balance INT,platform_price BINARY(15)) TAGS (device_id BINARY(32),device_no BINARY(32),sno BINARY(32),model_id BINARY(32),type_id BINARY(100))
效果展示
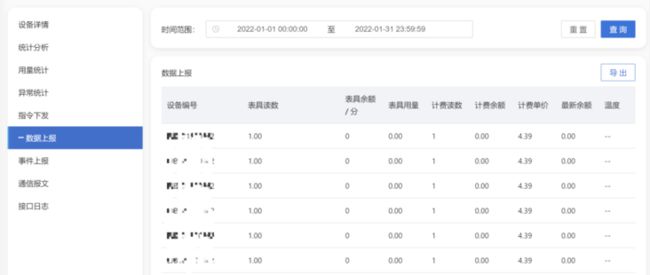
最终我们采用了 3 节点 8 核 16 G 满足整体业务需求,系统可以根据时间段范围、针对单个设备进行数据上报的查询功能,且支持按照小时用量、日用量、月用量、年用量四个维度进行统计分析。目前单个超级表的压缩率为 2.5%。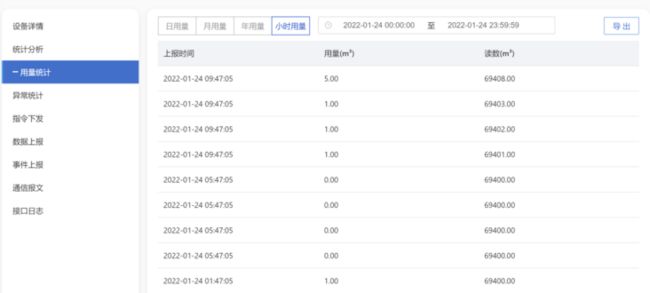
三、经验分享与未来规划
在我们使用 TDengine 的过程中,也遇到了一些小问题,在本文中总结出了一些经验,分享如下:
查询结果字段名的特殊写法
TDengine 的此前版本的设计当中,在查询返回的字段名时使用的是特殊写法:例如SELECT last_row(ts) FROM stb GROUP BY tbname,这样的设计会导致 MyBatis 等 ORM 框架在映射时无法直接对上。这种情况下只需要将 keepColumnName 设置为 1,就可以避免。
及时更新版本
在前期使用过程中,我们曾经遇到过 DROP TABLE 就崩溃的 BUG。和官方沟通后发现,已经在很早的版本上修复了,建议各位遇到 TDengine 的新版本也及时更新。
USING 语法
在使用 INSERT INTO table USING stable TAGS() 的语法时,一直以为这里会对 tag 进行重新赋值。到了使用的时候才发现,原来 table 已经存在的情况下,是不会对 tag 发生修改的。细思一下绝对的也是合理的,因为毕竟多一次修改就会多一次性能消耗,如果跟着 insert 来修改,就会多了 1 : 1 的修改操作。
调整分片策略
在前期写入过程中,发现 CPU 占用只能到 1 核,CPU 资源上不去。和官方沟通后发现,原来默认的分片策略,在小规模设备上只会创建几个 Vnode,因此并不能很好地把全部核数利用起来。官方告知可以通过这两个参数来调整分片策略: tableIncStepPerVnode 50minTablesPerVnode 50 前者决定的是何时采用下一个 Vnode 来存放新的 table,后者决定的是何时创建下一个 Vnode 来存放新的 table。
写入内存 blocks 很重要
在写入过程中,官方的巡检发现数据写入的“碎片化”很严重。经过排查发现,分配给写入过程的内存太小(block 默认 6,意味着 1 个 Vnode 只有 96 MB 用于写入)。由于 TDengine 在写入原理上是依赖于内存来做局部排序的,因此内存小了就会频频触发落盘,从而导致数据的落盘区块的平均条数很小,需要频繁 IO 来读取数据。基于此,各位尽量设置较大的 block 来避免这个问题。
未来规划
物联网、车联网等涉及时序数据存储、分析的场景,使用 TDengine 可以大大降低系统架构复杂度,在提升性能和开发效率的同时还能够降低学习和运维成本。之后我们也会结合业务需求在项目中充分发挥 TDengine 的优势,利用其来长期存储设备上报的有效读数数据,以及进行计费、抄表、用量统计分析。
想了解更多TDengine的具体细节,欢迎大家在GitHub上查看相关源代码。