显卡大幅降价了但是还可以再等等,新的40系列显卡也要发售了,所以我们先看看目前上市的显卡的性能对比,这样也可以估算下40显卡的性能,在以后购买时作为参考。
但是在本文之前一定要说下的是:本文并不推荐现在就买显卡,除非必须,现在一定不要买显卡,谁买谁吃亏,目前的情况是,“等” 就对了

回到正题,在这篇文章中我整理了几个在 NVIDIA GeForce RTX 3090 GPU 进行的深度学习性能基准测试。
一般的情况下我们都会使用 TensorFlow github 中的“tf_cnn_benchmarks.py”脚本来进行深度学习的评测。因为大多数的测试都是基于这个脚本,代码在这里( https://github.com/tensorflow... ),如果你是pytorch也可以参考,显卡的基准测试与使用的框架无关,差别不会超过5%。
首先使用 1、2 和 4 个 GPU 配置(针对 2x RTX 3090 与 4x 2080Ti 部分)运行了相同的测试。确定的批量大小是可以容纳可用 GPU 内存的最大批量。
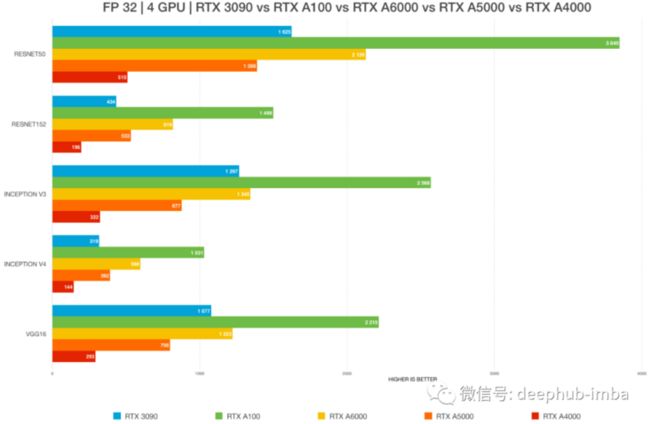
然后还会比较 2022 年最流行的深度学习 GPU 的性能:除NVIDIA 的 RTX 3090以外还包括了、A100、A6000、A5000 和 A4000等产品。
3090对比其他消费级的产品
首先说结果:NVIDIA RTX 3090 在所有型号上均优于所有 GPU(图像/秒)。2x RTX 3090 > 4x RTX 2080 Ti 。对于深度学习,RTX 3090 是市场上性价比最高的 GPU,可大幅降低 AI 工作站的成本。
RTX 3090 ResNet 50 TensorFlow Benchmark
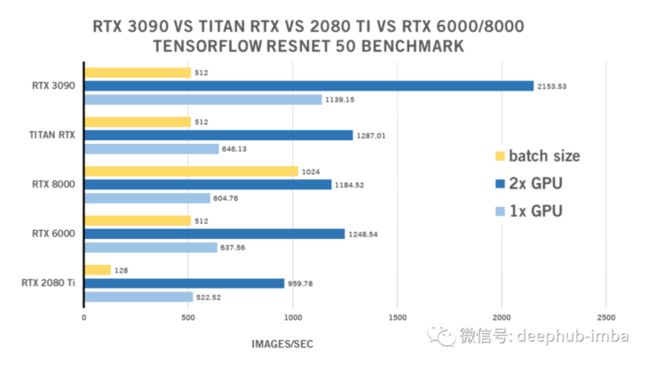
| 1x GPU | 2x GPU | batch size | |
|---|---|---|---|
| RTX 2080 Ti | 522.52 | 959.78 | 128 |
| RTX 6000 | 637.56 | 1248.54 | 512 |
| RTX 8000 | 604.76 | 1184.52 | 1024 |
| TITAN RTX | 646.13 | 1287.01 | 512 |
| RTX 3090 | 1139.15 | 2153.53 | 512 |
RTX 3090 ResNet 152 TensorFlow Benchmark
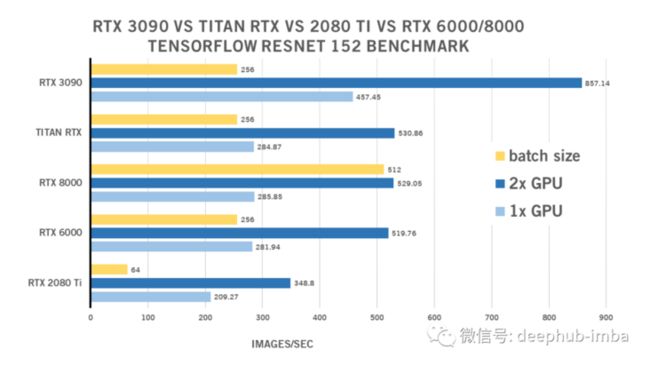
| 1x GPU | 2x GPU | batch size | |
|---|---|---|---|
| RTX 2080 Ti | 209.27 | 348.8 | 64 |
| RTX 6000 | 281.94 | 519.76 | 256 |
| RTX 8000 | 285.85 | 529.05 | 512 |
| TITAN RTX | 284.87 | 530.86 | 256 |
| RTX 3090 | 457.45 | 857.14 | 25 |
RTX 3090 Inception V3 TensorFlow Benchmark
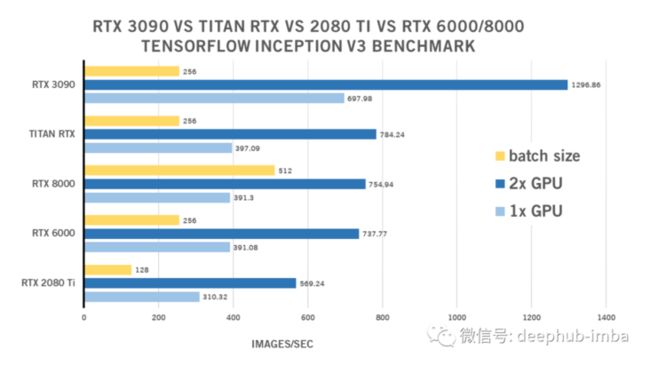
| 1x GPU | 2x GPU | batch size | |
|---|---|---|---|
| RTX 2080 Ti | 310.32 | 569.24 | 128 |
| RTX 6000 | 391.08 | 737.77 | 256 |
| RTX 8000 | 391.3 | 754.94 | 512 |
| TITAN RTX | 397.09 | 784.24 | 256 |
| RTX 3090 | 697.98 | 1296.86 | 256 |
RTX 3090 Inception V4 TensorFlow Benchmark
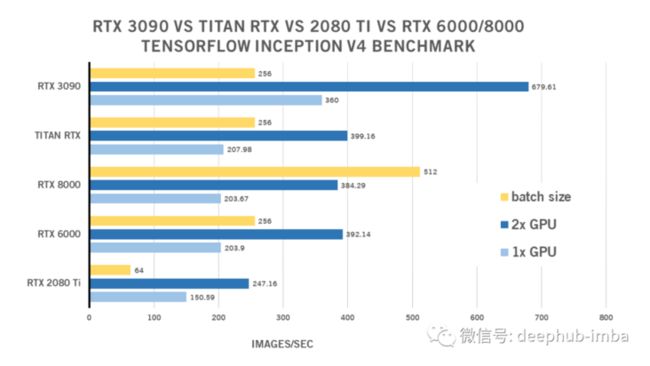
| 1x GPU | 2x GPU | batch size | |
|---|---|---|---|
| RTX 2080 Ti | 150.59 | 247.16 | 64 |
| RTX 6000 | 203.9 | 392.14 | 256 |
| RTX 8000 | 203.67 | 384.29 | 512 |
| TITAN RTX | 207.98 | 399.16 | 256 |
| RTX 3090 | 360 | 679.61 | 256 |
2x NVIDIA RTX 3090 Vs 4x RTX 2080 Ti
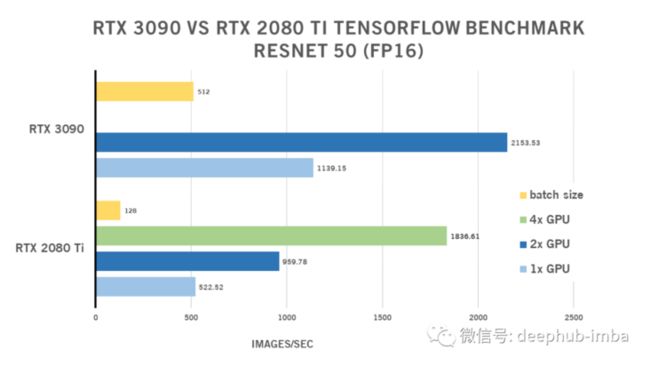
| 1x GPU | 2x GPU | 4x GPU | batch size | |
|---|---|---|---|---|
| RTX 2080 Ti | 522.52 | 959.78 | 1836.61 | 128 |
| RTX 3090 | 1139.15 | 2153.53 | N/A | 512 |
与 RTX 2080 Ti 的 4352 个 CUDA 核心相比,RTX 3090 的 10496 个 CUDA 核心是其CUDA的两倍多, CUDA 核心是 CPU 核心的 GPU 等价物,并针对同时运行大量计算(并行处理)进行了优化。更多 CUDA 内核通常意味着更好的性能和更快的图形密集型处理。3090 拥有 24GB GDDR6X 内存,也是2080 Ti 11G的2倍多,所以取得这样的结果也是情理之中的。
RTX 3090 vs. RTX 3080 Ti vs A6000 vs A5000 vs A100
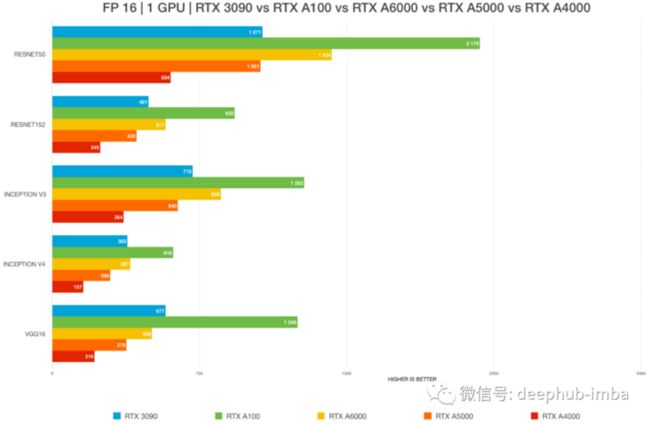
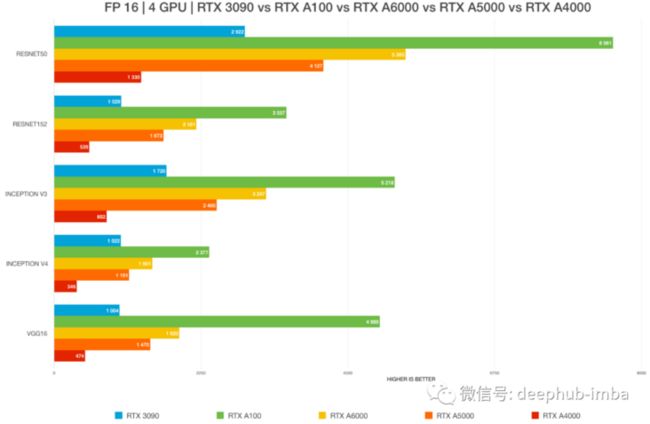
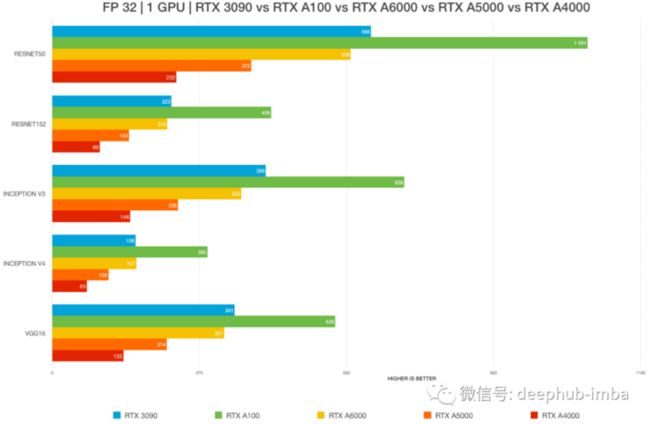
RTX 3090 GPU的2.5 插槽设计,只能在风冷时在 2-GPU 配置中进行测试。4-GPU 配置需要水冷。所以这也限制了他的测试,如果我们需要购买多块3090一定要注意机箱的大小。
3090一定要上水冷
RTX 3090 可能遇到的一个问题是散热,主要是在多 GPU 配置中。4 x RTX 3090 配置需要水冷。不仅是散热问题,还因为大小问题。
过热导致性能下降高达 60% ,所以水冷是最好的解决方案;提供 24/7 稳定性、低噪音和更长的硬件寿命。此外,任何水冷式 GPU 都可以保证以最大可能的性能运行。水冷 RTX 3090 将保持在 50-60°C 与风冷时 90°C 的安全范围内(90°C 是 GPU 将停止工作和关闭设定值)。2x 或 4x 风冷 GPU 噪音非常大,尤其是鼓风机式风扇。将工作站放在实验室或办公室是不可能的——更不用说服务器了。水冷解决了台式机和服务器中的这种噪音问题。与风扇相比,噪音降低了 20%(水冷却为 49 dB,最大负载时风扇为 62 dB)。
最后总结
对于大多数用户而言,NVIDIA RTX 3090 或 NVIDIA A5000 将为他们提供物超所值的服务。使用大批量可以让模型训练得更快、更准确,从而节省大量时间。RTX 3090 上 24 GB 的 VRAM 对于大多数用例来说绰绰有余,几乎可以为任何型号和大批量提供空间。
NVIDIA 的 RTX 3090 是目前深度学习和 AI 的最佳 GPU。它具有卓越的性能,非常适合为神经网络提供动力。RTX 3090 是 30 系列中唯一能够通过 NVLink 桥接器进行扩展的 GPU 型号。当与 NVLink 网桥配对使用时,可以将显存扩充为 48 GB 来训练大型模型。
40系列
AMD的7000系列据说要比NV的40系列性能的高,但是目前深度学习框架支持的不好,所以对于深度学习来说还只能用 NV的卡,这个目前来说没有办法。
新的40系列的显卡已经公布了上市的时间今年的第三季度,虽然功率高了(600W),但是相应的算力也高了,18432个CUDA核心、96MB缓存。据说4080就能达到 目前3090的水平,根据上面的测试,1万8的CUDA的表现至少要比 1万出头的3090提高60-70%,所以就像我们最上面说的:不是必要的话现在不要买,买了就吃亏,买了就上当。
https://www.overfit.cn/post/9ef4a9a4728f4fb69412abe267f634e4