ECCV 2018最佳论文解读:基于解剖结构的面部表情生成


在碎片化阅读充斥眼球的时代,越来越少的人会去关注每篇论文背后的探索和思考。
在这个栏目里,你会快速 get 每篇精选论文的亮点和痛点,时刻紧跟 AI 前沿成果。
点击本文底部的「阅读原文」即刻加入社区,查看更多最新论文推荐。
这是 PaperDaily 的第 103 篇文章本期推荐的论文笔记来自 PaperWeekly 社区用户 @TwistedW。本文获得 ECCV 2018 最佳论文荣誉提名。GANimation 将 Action Units 和 GAN 结合,实现了人面部表情变化的过程展示效果。Action Units 的大小控制着人面部表情的幅度,从而对单个图像可以实现表情生成的渐进过程,采用无监督训练,并将 Attention 辅助矫正图像的背景和照明带来的问题。
如果你对本文工作感兴趣,点击底部阅读原文即可查看原论文。
关于作者:武广,合肥工业大学硕士生,研究方向为图像生成。
■ 论文 | GANimation: Anatomically-aware Facial Animation from a Single Image
■ 链接 | www.paperweekly.site/papers/2171
■ 源码 | github.com/albertpumarola/GANimation
GAN 在面部生成上已经取得了很大的成果,StarGAN [1] 已经可以实现人脸面部的高清和多属性的生成,但是这类生成是基于数据集的,往往在两幅属性不一的图像上做插值生成是实现不了的。当然,将 VAE 或 AE 和 GAN 结合可以实现较好的插值生成,但是如何合理的插值仍然是一个困难的过程。
GANimation 介绍了一种基于动作单元(Action Units)为条件的新型 GAN 模型,可以根据 Action Units(简称 AC)的大小调节面部表情生成的幅度,从而实现面部表情不同幅度过程的生成。
论文引入
从单张人脸面部图像生成出表情变化的多幅图像将为不同领域带来不一样的灵感,比如可以根据单幅照片做不同人物表情变化的图像,这可以用在电影电视的创作中。想象一下让特别严肃的人设做滑稽的表情变化是不是很有意思的一件事。
GAN 已经可以在人脸面部属性上做很多变换的生成,StarGAN 是属性生成上比较好的模型,可以同时生成多属性的人脸图像。但是 StarGAN 受限于数据集,因为 StarGAN 的生成是在属性标签的基础上完成的,所以 StarGAN 不能做插值的渐进生成。
虽然 VAE 和 GAN 的结合可以实现插值生成,但是合理的插值仍然是一个待解决和优化的过程。GANimation 将 Action Units(AU)和 GAN 结合,利用动作单元(AU)来描述面部表情,这些动作单元在解剖学上与特定面部肌肉的收缩相关。
尽管动作单元的数量相对较少(发现 30 个 AU 在解剖学上与特定面部肌肉的收缩相关),但已观察到超过 7,000 种不同的 AU 组合。例如,恐惧的面部表情通常通过激活产生:Inner Brow Raiser(AU1),Outer Brow Raiser(AU2),Brow Lowerer(AU4),Upper Lid Raiser(AU5),Lid Tightener(AU7),Lip Stretcher( AU20)和 Jaw Drop(AU26)。 根据每个 AU 的大小,将在表情程度上传递情绪幅度。
为了说明 AU 的作用,我们一起来看看通过调节特定 AU 的大小实现的面部表情渐变的效果:

由上图我们可以看出来,在 AU 设置为微笑表情的动作时,随着 AU 的大小逐渐增大途中人物微笑表情的力度也越来越大,对比度最强的是 AU=0 和 AU=1 的情况下,可以清楚的看到人物面部嘴角和笑脸的变化,当然中间随着 AU 的增大,微笑也是越来越灿烂。
总结一下 GANimation 的贡献:
将动作单元(AU)引入到 GAN 中实现了人物面部表情渐变生成;
将 Attention 引入到模型中用于克服生成中背景和光照的影响;
模型可应用于非数据集中人物面部表情的生成。
GANimation模型
我们一起来看看实现 GANimation 的模型结构:

先把图中的变量交代一下,真实图像记为![]() ,与它对应的生成的图像记为
,与它对应的生成的图像记为![]() ,
,![]() 是动作信息它是属于 N 种动作单元
是动作信息它是属于 N 种动作单元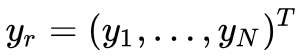 ,由于存在两组生成器(另一组为了让生成的图像还原为原始图像,做循环误差优化网络),将生成器的输入统一记为
,由于存在两组生成器(另一组为了让生成的图像还原为原始图像,做循环误差优化网络),将生成器的输入统一记为![]() ,动作单元记为
,动作单元记为![]() ,输出记为
,输出记为![]() 。
。
![]() 为 Attention 生成器,
为 Attention 生成器,![]() 生成的是一维的图像包含了图像中 Attention 的位置。
生成的是一维的图像包含了图像中 Attention 的位置。![]() 则是像素图像生成器,
则是像素图像生成器,![]() 用于生成包含图像像素的三维图像。最后将
用于生成包含图像像素的三维图像。最后将![]() 的输出和
的输出和![]() 的输出结合形成完整的图像输出,其中
的输出结合形成完整的图像输出,其中![]() 的输出是为了指示像素图像的每个像素在哪个范围内对最终的输出作用力度。对应的判别器也由两部分组成,
的输出是为了指示像素图像的每个像素在哪个范围内对最终的输出作用力度。对应的判别器也由两部分组成,![]() 用于区分真实图像和生成图像,而
用于区分真实图像和生成图像,而![]() 则是用来区分图像的条件信息也就是图像的 AU 信息用来让生成的图像的 AU 特性更加的好。
则是用来区分图像的条件信息也就是图像的 AU 信息用来让生成的图像的 AU 特性更加的好。
![]() 和
和![]() 的结合方式由下图所示:
的结合方式由下图所示:

最终生成器的输出就是:
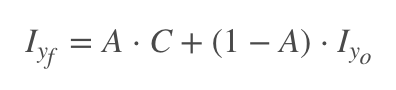
有了以上的分析,我们再来捋一遍模型框架。将真实图像![]() 输入到生成器和动作单元
输入到生成器和动作单元![]() 结合生成具有动作单元信息的图像
结合生成具有动作单元信息的图像![]() ,为了区分真实图像和生成图像将生成图像和真是图像送入判别器去判别,
,为了区分真实图像和生成图像将生成图像和真是图像送入判别器去判别,![]() 区分真假图像,
区分真假图像,![]() 区分 AU 信息,不断优化生成器和判别器达到共同进步。为了实现循环优化网络,做了一个重构的循环生成,将生成的图像进一步根据原始图像的 AU 还原回去生成
区分 AU 信息,不断优化生成器和判别器达到共同进步。为了实现循环优化网络,做了一个重构的循环生成,将生成的图像进一步根据原始图像的 AU 还原回去生成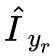 。
。
整个模型框架就是这样,接下来就是损失函数的设计了。
GANimation损失函数
GANimation 采用的 GAN 模型是 WGAN-GP [2](利用 Earth Mover Distance 代替 GAN 中的 Jensen-Shannon divergence),其优点是训练会更加的稳定。所以接下来的分析是在 WGAN-GP 的基础上展开的。
GANimation 模型的损失函数细分的话有 4 个,分别为 Image Adversarial Loss,Attention Loss,Condition Expression Loss 和 Identity Loss。
Image Adversarial Loss
这就是传统的图像对抗损失,用于优化生成器和判别器,需要考虑 Earth Mover Distance 中的梯度惩罚:

这部分的损失函数没必要细说,就是比较传统概念上的 GAN 的损失。
Attention Loss
这部分是 Attention 的损失函数,主要是 Attention 的知识,考虑图像的前后对应关系。由于 Attention 优化后得到的 A 很容易饱和到 1,对应上面的公式 中的
中的![]() 则没了意义,所以为了防止这种情况,将 A 做 l2 损失。得到损失函数:
则没了意义,所以为了防止这种情况,将 A 做 l2 损失。得到损失函数:
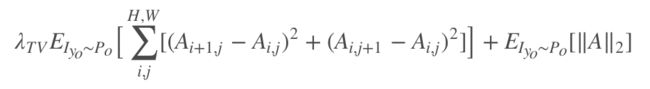
Condition Expression Loss
这部分损失还是蛮重要的,它的作用是让 AU 作用下生成的图像更具有 AU 的动作特性,整体的思路是优化生成器和判别器,通过对抗实现共进步。
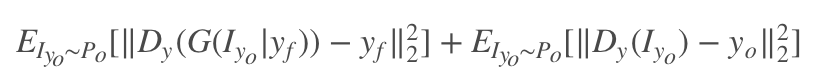
Identity Loss
最后一个损失就是循环损失了,也可以说为重构损失,这一块也没什么说的:

最后将损失函数统一一下:
![]()
GANimation实验
实验先对单 AU 进行编辑,在不同强度下激活 AU 的能力,同时保留人的身份。下图显示了用四个强度级别(0,0.33,0.66,1)单独转换的 9 个 AU 的子集。对于 0 强度的情况,不改变相应的 AU。

对于非零情况,可以观察每个 AU 如何逐渐加强,注意强度为 0 和 1 的生成图像之间的差异。相对于眼睛和面部的半上部(AU1,2,4,5,45)的 AU 不会影响口腔的肌肉。同样地,口腔相关的变形(AU10,12,15,25)不会影响眼睛和眉毛肌肉。
对于相同的实验,下图显示了产生最终结果的注意力 A 和颜色 C 掩模。注意模型是如何学会将其注意力(较暗区域)以无人监督的方式聚焦到相应的AU上的。

多 AU 编辑的实验结果就是正文的第一张图,非真实世界的数据上也显示了出了较好的结果(阿凡达的那张)。
实验还将 GANimation 与基线 DIAT,CycleGAN,IcGAN 和 StarGAN 进行比较。

最后,实验展示了在非数据集上的实验效果,图片选自加勒比海盗影片。

当然,实验也展示了不足的地方。

总结
GANimation 提出了一种新颖的 GAN 模型,用于脸部表情渐进生成,可以实现无监督训练。模型通过 AU 参数化与解剖学面部变形是一致的,在这些 AU 上调整 GAN 模型允许生成器通过简单插值来渲染各种表情幅度。此外,作者在网络中嵌入了一个注意模型,对背景和光照有一定的补充。
参考文献
[1]. Choi, Y., Choi, M., Kim, M., Ha, J.W., Kim, S., Choo, J.: Stargan: Unified gen- erative adversarial networks for multi-domain image-to-image translation. CVPR (2018)
[2]. Gulrajani, I., Ahmed, F., Arjovsky, M., Dumoulin, V., Courville, A.C.: Improved training of wasserstein GANs. In: NIPS (2017)
本文由 AI 学术社区 PaperWeekly 精选推荐,社区目前已覆盖自然语言处理、计算机视觉、人工智能、机器学习、数据挖掘和信息检索等研究方向,点击「阅读原文」即刻加入社区!

点击标题查看更多论文解读:
网络表示学习综述:一文理解Network Embedding
神经网络架构搜索(NAS)综述
从傅里叶分析角度解读深度学习的泛化能力
ECCV 2018 | 从单帧RGB图像生成三维网格模型
ECCV 2018 | 基于三维重建的全新相机姿态估计方法
ECCV 2018 | 腾讯AI Lab提出视频再定位任务
KDD 18 | 斯坦福大学提出全新网络嵌入方法
 #投 稿 通 道#
#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢? 答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
? 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
? 投稿邮箱:
• 投稿邮箱:[email protected]
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
?
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
▽ 点击 | 阅读原文 | 下载论文 & 源码