Meta Faster R-CNN:基于注意力特征对齐的小样本目标检测
论文标题:
Meta Faster R-CNN: Towards Accurate Few-Shot Object Detection with Attentive Feature Alignment
论文链接:
https://arxiv.org/abs/2104.07719
1 出发点 & 创新点
1.1 出发点
以往的方法使用基于base类数据训练得到的 RPN 去生成 novel 类的候选框,这样做会错过一些新类的高 IoU 框,因为在 RPN 训练中,novel 类框被视为 base 类的背景区域。在 novel 类数据上进行微调确实能提高效果,但它对未知类的泛化能力是受限的。
RPN 中简单的前景/背景线性分类在检测 FSOD 所需的高质量方案时往往缺乏鲁棒性。忽略了空间错位问题,类似的语义区域不会出现在噪声和小样本的支持图像之间的相同空间位置。
1.2 创新点
本文提出粗粒度原型匹配网络(Meta-RPN),使用基于度量学习的非线性分类器代替传统的线性目标分类器,去处理查询图片中的锚框和 novel 类之间的相似性,从而提高对少量 novel 类候选框的召回率。作者还提出细粒度原型匹配网络(Meta-Classifier),该网络具有空间特征对齐和前景注意模块,去处理噪声和少量 novel 类之间的相似性,以解决候选框特征和类原型之间的空间错位问题,从而提高整体检测精度。
论文综合考量了 softmax 分类器和他们设计的小样本分类器,在他们各自发挥优势的地方使用,而不是像以往的方法一样只用 softmax 分类器。

Meta-RPN 和普通 RPN 的比较:普通 RPN 主要区分出前景和背景,在 base 类数据上进行训练;Meta-RPN 将提取出来的特征和 novel 类的原型进行比较,看它们之间的相似性。二者作用都是筛选出候选框。
Meta-Classifier 和普通 Classifier 的比较:普通的分类器会将候选框和类原型进行直接比较(直接对应位置比较,左上角对左上角);Meta-Classifier 则会进行空间特征对齐(如候选框中机尾的地方,也会对应上类原型的机尾特征),来解决空间错位的问题。
23模型结构

2.1 Feature Extractor
该模型使用孪生神经网络去提取支持图像和查询图像的特征:
1. 对于查询图像,作者用一个 CNN 来提取,如 ResNet50/101。
2. 对于支持图像,首先使用周围上下文区域将候选框扩张,然后裁剪出目标区域,再将裁剪后的图像调整为相同大小,再将其输入共享特征的 backbone,从而提取出支持图像的特征。
2.2 Object Detection for Base Classes
在特征提取网络的基础上,RPN 用于生成图像中所有 base 类的类不可知的候选框。之后,对于每个候选框,使用 R-CNN 分类器生成所有 base 类加上“背景”类的 softmax 概率和 bbox 回归。
2.3 Proposal Generation for Novel Classes
对查询图像特征做一个 3x3 的卷积层和 ReLu 层处理,用于提取以每个空间位置为中心的多尺度锚的特征。
对于每个 novel 类,作者将 K-shot 支持图像的平均 CNN 特征作为类原型:
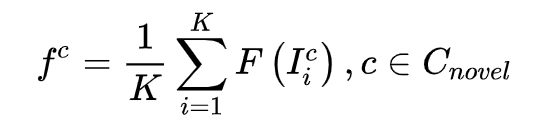
然后,为了得到与锚框相同的特征大小,进行空间平均池化,得到全局池化原型。

接着,使用新设计非线性轻量级分类模块来计算了类原型和锚框特征之间的相似性。作者提出了一个具有乘法(Mult)、减法(Sub)和拼接(Cat)子网络的更强的特征融合网络。Mult 可以突出显示相关和常见的特征,Sub 可以直接测量两个输入之间的距离。Cat 可以被看作是一种可以学习的操作。形式为:
![]()
其中,、 和 都有卷积层和 ReLu 层组成, 代表 channel-wise concatenation。然后将 输入二元分类和 bbox 回归层,以预测候选框。所提出的特征融合网络可以自然地用卷积层实现,并且计算效率高,可以提高对 novel 类候选框的召回率。
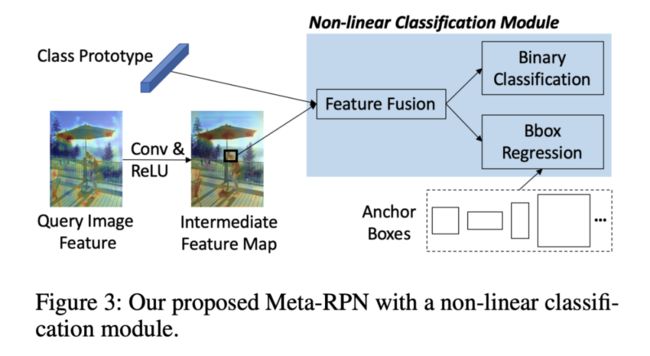
2.4 Proposal Classification and Refinement for Novel Classes
作者首先通过计算相似度矩阵,在两个输入特征之间建立软对应关系,也就是孪生神经网络。然后,使用相似度矩阵计算与候选框一致的原型,并定位前景区域。最后再用非线性分类器去计算相似性分数。建议每个模块都对应下面的结构图看,理解公式。
a. Spatial Alignment Module
之后再做个 softmax normalization ,分母为与所有类原型的空间位置进行比较的总和,求出它与这个类原型的不同空间位置的相似程度,作为一个权重系数。
最后通过聚合归一化相似性来算出候选框空间位置 i 对应的类原型:
b. Foreground Attention Module
前景关注掩码 M 用来突出显示对应的目标区域:
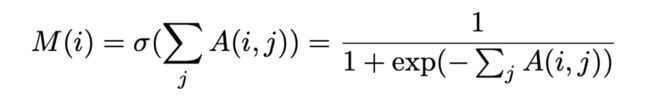
M 值越大,表示 中的相应位置更类似于对齐原型 的位置,并且更有可能是相同的语义部分。另一方面,候选框中的背景区域很难在具有高度相似性的类原型中找到相应的位置,所以 M 值较低。
因此,作者将注意力掩码 M 与 和 相乘,以关注相应的前景区域:
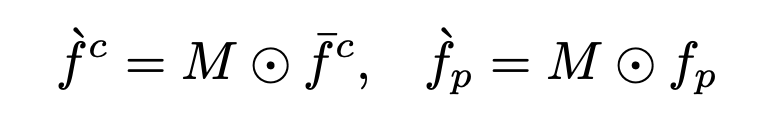
作者还加了两个可学习参数(初始化均为 0),将其与输入特征进行相加,使训练更加平稳(残差的思想):

c. Non-linear Classification Module
特征融合网络:
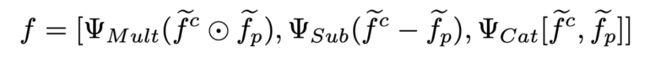
其中,、 和 都是拥有的三个卷积层和一个 ReLu 层的非线性卷积神经网络,之后送到二元分类和 bbox 回归进行最终检测。

3 模型训练
分为三个阶段:
1. Meta-learning with base classes:从 base 类中标记一些类,这些类的支持图像为 K-shot,去模拟 FSOD 中 novel 类的学习情况。此外,作者还使用真实边界框对一些查询图像进行采样,并使用二元交叉熵损失和平滑 L1 损失进行模型训练。
2. Learning the separate detection head for base classes:作者调整主干特征提取器的参数,并学习 base 类的 RPN 和 R-CNN 模块。
3. Fine-tuning with both base and novel classes:在前两个步骤中只采用 base 类数据,而在微调这一步中,会采用一个小型的平衡数据集,base 类和 novel 类都有。元学习和微调的关键区别在于,没有针对元学习 novel 类的训练。在元测试期间,我们只使用 novel 类的支持集来计算原型。支持图像是使用真实边界框注释从原始图像中裁剪出来的。在优化过程中,我们使用原始的 novel 类图像作为查询图像来优化我们的少数镜头检测器,包括 Meta-RPN 和 Meta 分类器。当我们逐渐使用更多图像进行微调时,novel 类的模型性能将得到改善。
4 实验部分
4.1 部分消融实验

RPN、Attention-RPN 和 Meta-RPN 之间的比较,还有非线性分类器、对齐、前景注意力模块的使用,以及 backbone 为 101 层和 50 层,对实验结果的影响。

三种方法使用两种训练对 novel 类的检测效果。
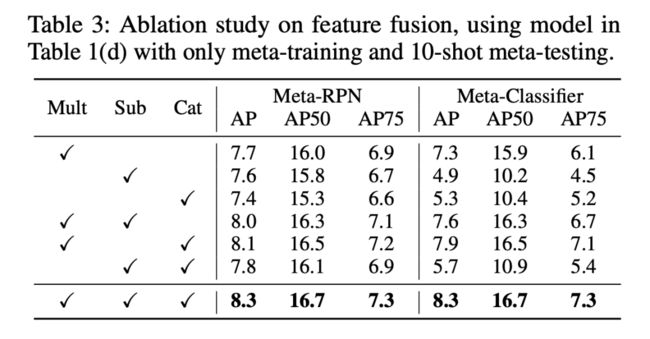
特征聚合模块的三项子网络做消融实验。直接使用 Cat 子网络并不能在元 RPN 和元分类器中获得良好的效果。这是因为 Cat 子网络试图直接学习两个特征之间的复杂融合,这不容易训练和泛化。
4.2 和以往SOTA的对比

在PASCAL VOC数据集上的表现

在MS COCO数据集上的比较
5 混合对抗训练
这篇文章在模型设计方面确实做了很多思考和创新工作。首先提出了一个轻量级粗粒度原型匹配网络(Meta-RPN),以高效的方式为小样本目标生成候选框。然后,提出了一个细粒度的原型匹配网络(Meta-Classifier),该网络具有细致的特征对齐,以解决噪声和 novel 类之间的空间错位问题。而且,考虑到分类器的特性差异,还专门为 base 类和 novel 类的检测做了两个检测器。
但即使做了这么多工作,讲的故事也让我觉得很有道理,实验效果的提升却依然很有限,给我的感觉还没有之前模型改动不大的文章提升的效果多,至于其中的原因是什么,确实引人深思。